들어가며
오늘도 또 코드리뷰로 좋은 내용을 주셨다. 정말 배울게 많은 것 같다. 너무 아는게 부족한데 많은 도움을 주시는 것 같다. 최근 블로그 글 3개가 다 이분이 리뷰를 주셔서 공부하게 되었다.
코드리뷰 과정에서 굉장히 많은 의견이 오고갔다. 처음에는 커버링 인덱스에 대한 이야기로 시작했지만 내가 잘못이해한덕분에(?) 이상한 것에 관심이 생겼다.
전체 코드리뷰 내용을 보려면 이곳을 가면된다.
코드리뷰 내용
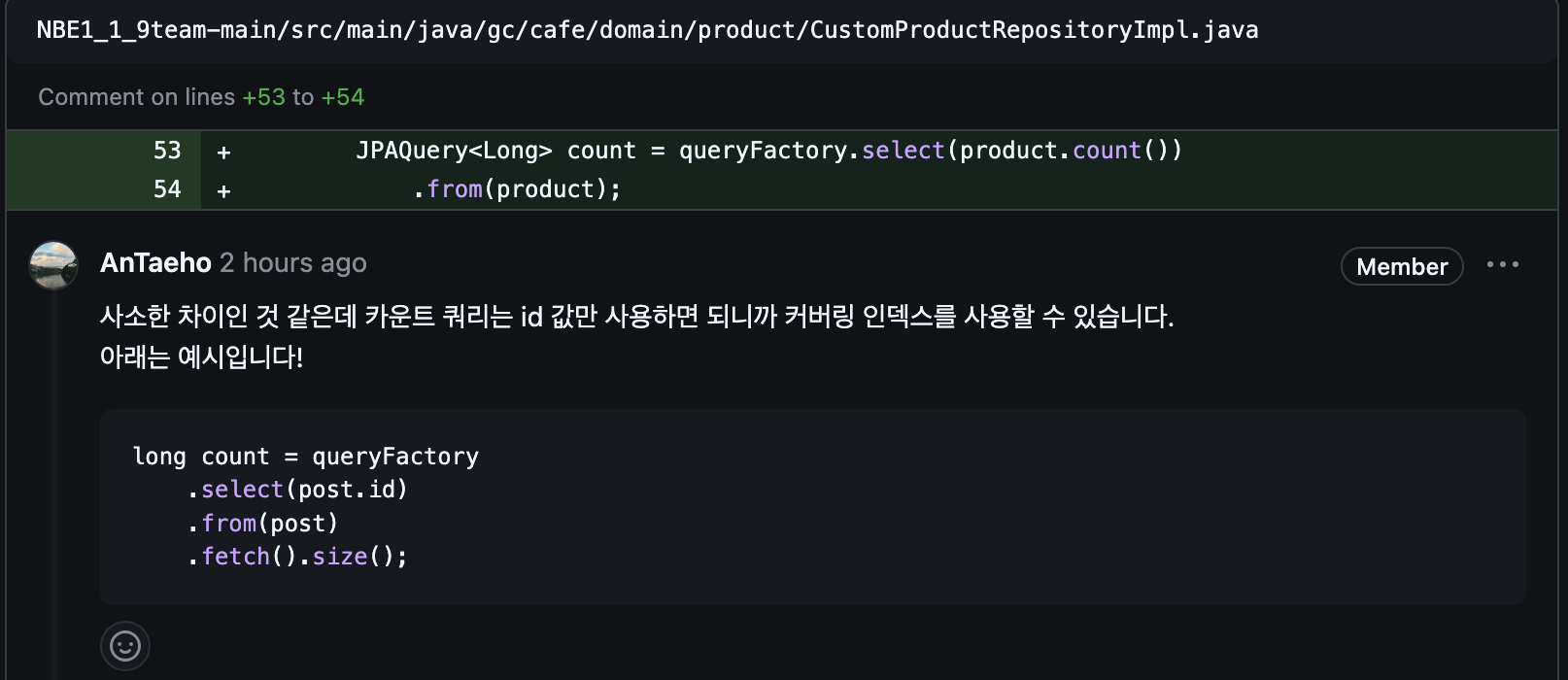
분명히 제시해준 코드는 id를 조회해서 size를 세는 것이었는데 난 이상한데 꽂혀서 count라고 생각했다... 얼마나 멍청한가......
하여튼 잘못이해하는게 좋은건 아니지만? 나는 모르는게 너무많아서 잘못이해한 덕택을 좀 봤다. mysql의 count()에 관한 이야기다.
커버링 인덱스
커버링 인덱스란, 쿼리를 충족시키는데 필요한 모든 데이터를 갖고 있는 인덱스를 말합니다.
쿼리를 충족시킨다라는 뜻은 SELECT, WHERE, ORDER BY, LIMIT, GROUP BY 등에서 사용되는 모든 컬럼이 인덱스 컬럼 안에 다 포함되는 경우이다.
하하 하지만 갖가지 문제로 실제 실습을 해보고싶었지만 실습을 포기하고 넘어갔습니다. 일단 개념이 이러하다 정도만 알아가고 나중에 다시 글 수정해서 채워보는걸로 ㅠㅠ 아래에 포기하게 된? 이유가 나오긴합니다.
하여튼 결과론적으로 커버링인덱스는 쿼리문에 사용되는 컬럼이 다 인덱스면 된다. 라고 이해해보겠습니다.
그리고 group by에서 인덱스 사용법 등이 있지만.. 따로 채워보도록 하겠습니다.
count(*) from 테이블명 vs count(pk) from 테이블명
내가 잘못이해한 것에서 부터 시작해서 나는 커버링 인덱스에 대한 정보를 찾던 중 어떤길로 빠졌는지 count(*) from 테이블명 이 굉장히 빠른 성능을 낸다는 것을 봤다.
내가 리뷰했던 내용이다
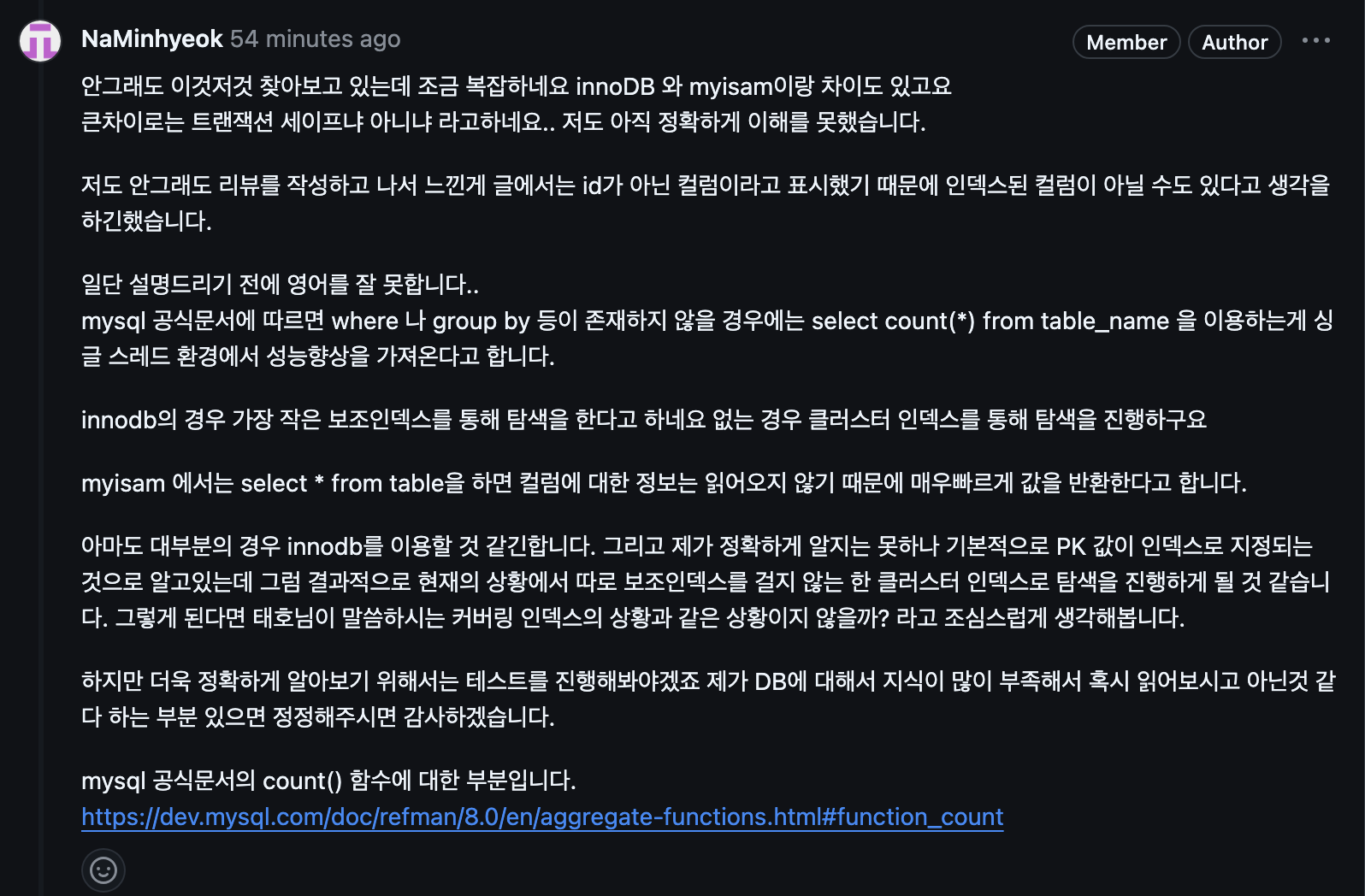
갑자기 뜬구름 잡는 얘기를 해서 사실은 답답하셨을수도? 있을 것 같다.
하여튼 갑자기 난 count() 에 꽂혔다 !
그래서 PK 가 일반적인 RDBMS에서는 index로 지정되기 때문에 그냥 한번 해보면 되는거 아닐까? 뭐 연관관계가 있는 것도 아니고 조인이나 서브쿼리를 쓸것도 없이 count(*) vs count(pk) 일뿐이니까
테스트 사전 준비
일단 그냥 JPA로 테이블 생성되는 sql을 이용해서 똑같이 테이블을 만들어주었다.
create table products (
product_id bigint not null,
created_at timestamp(6),
updated_at timestamp(6),
category varchar(50) not null,
description varchar(500) not null,
product_name varchar(20) not null,
price bigint not null,
primary key (product_id)
);그리고 나서 데이터를 최소 100만개는 넣어야지 확인해볼 수 있을 것 같아서 100만개를 넣는 프로시져를 만들었다. 이건 그냥 참고하고 만들어서 잘 모른다..
create procedure loop_insert()
begin
declare i int default 0;
while i < 1000000 do
insert into products (product_id, created_at, updated_at, category, description, product_name, price) values (i, now(), now(), 'category', 'description', 'product_name', 100);
set i = i + 1;
end while;
end;그리고 그냥 호출시켜주면 된다.
call loop_insert();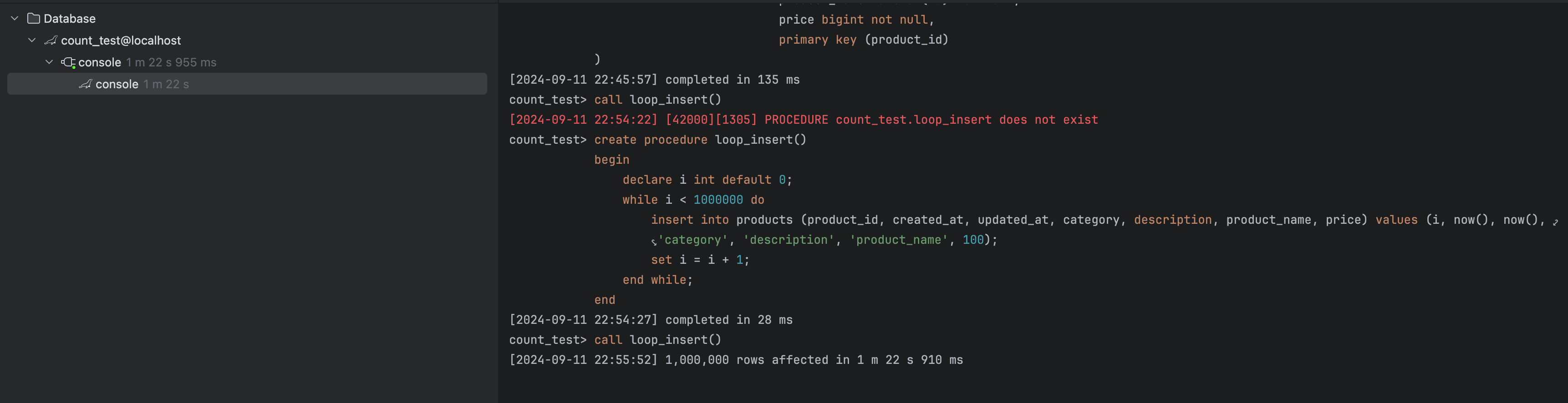
의외로(?) 빨리된다 1분 30초도 안걸렸다. 몇번 더 넣어도되지않을까 싶다. 한 500만개로 해봐야겠다. 만약 더 넣어도되고 일단 500만개로 시작해보겠다.
테스트 계획
그냥 explain을 붙여주면 된다고 한다.
총 3개 계획을 짜서 돌렸다.
explain format = json
select count(*) from products;
explain format = json
select count(product_id) from products;
explain format = json
select count(price) from products테스트 결과
내가 테스트 계획에 대해서 잘 몰라서 그런건지 아니면 내가 DB에 대한 이해가 부족한건지 결과가 내 예상과는 달랐다. 그냥 3 결과가 다 똑같이 나왔다.
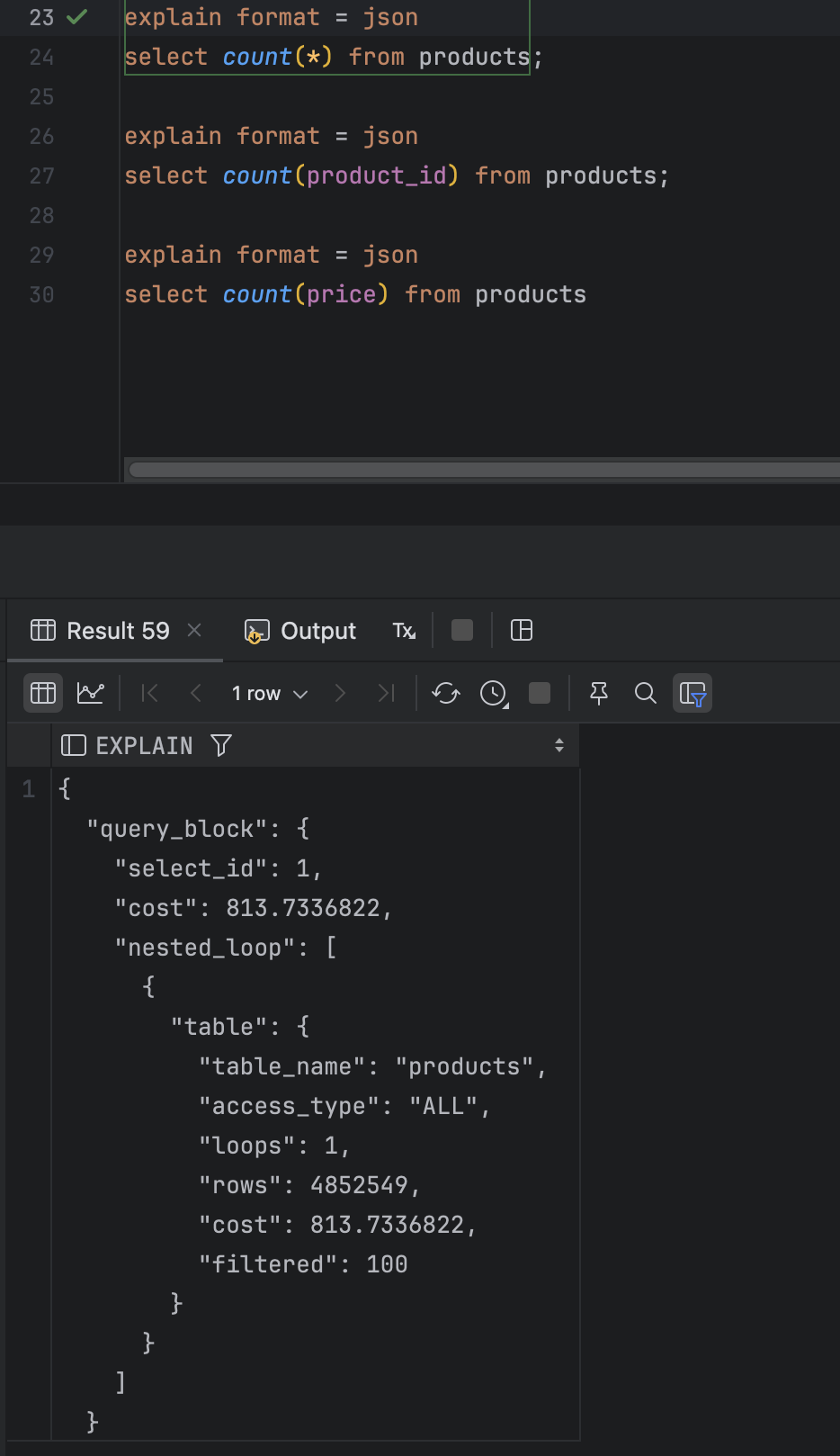
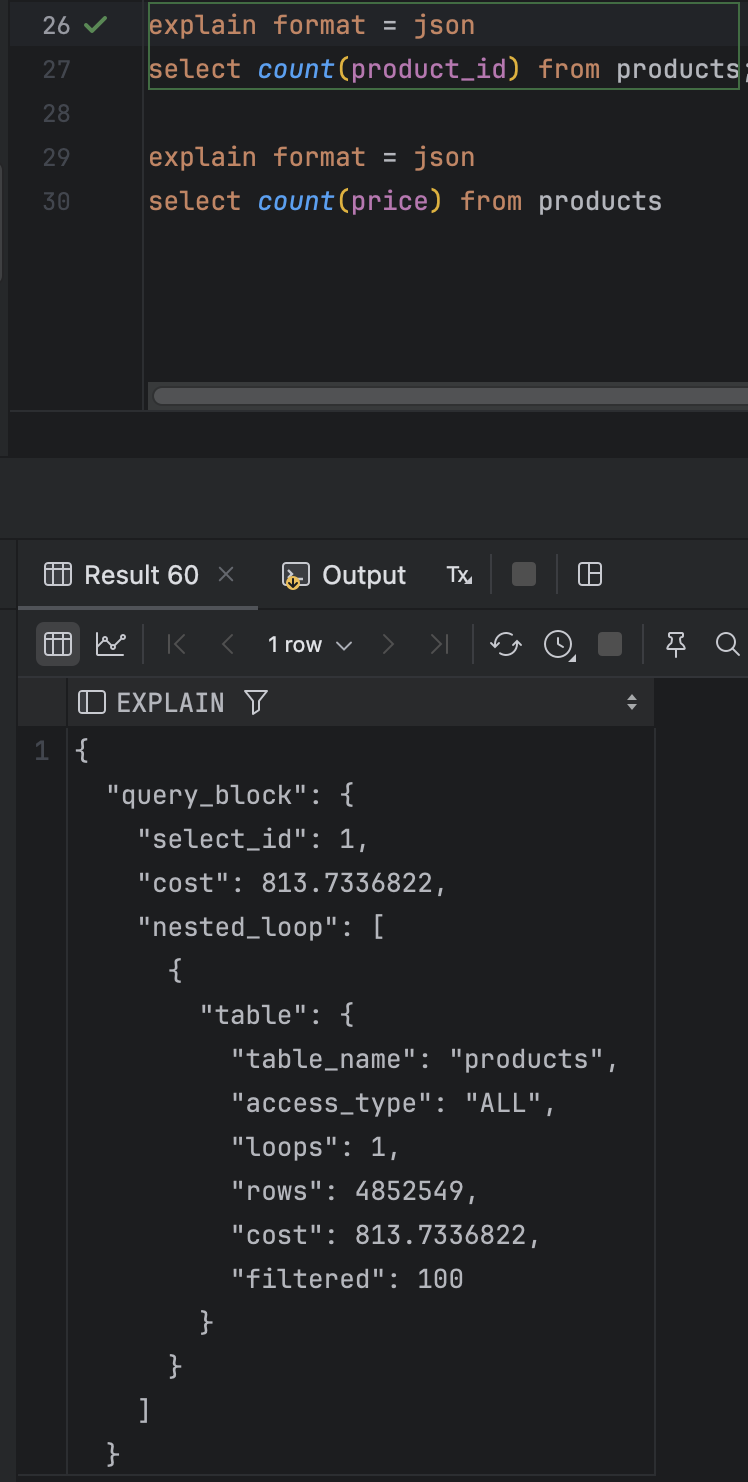
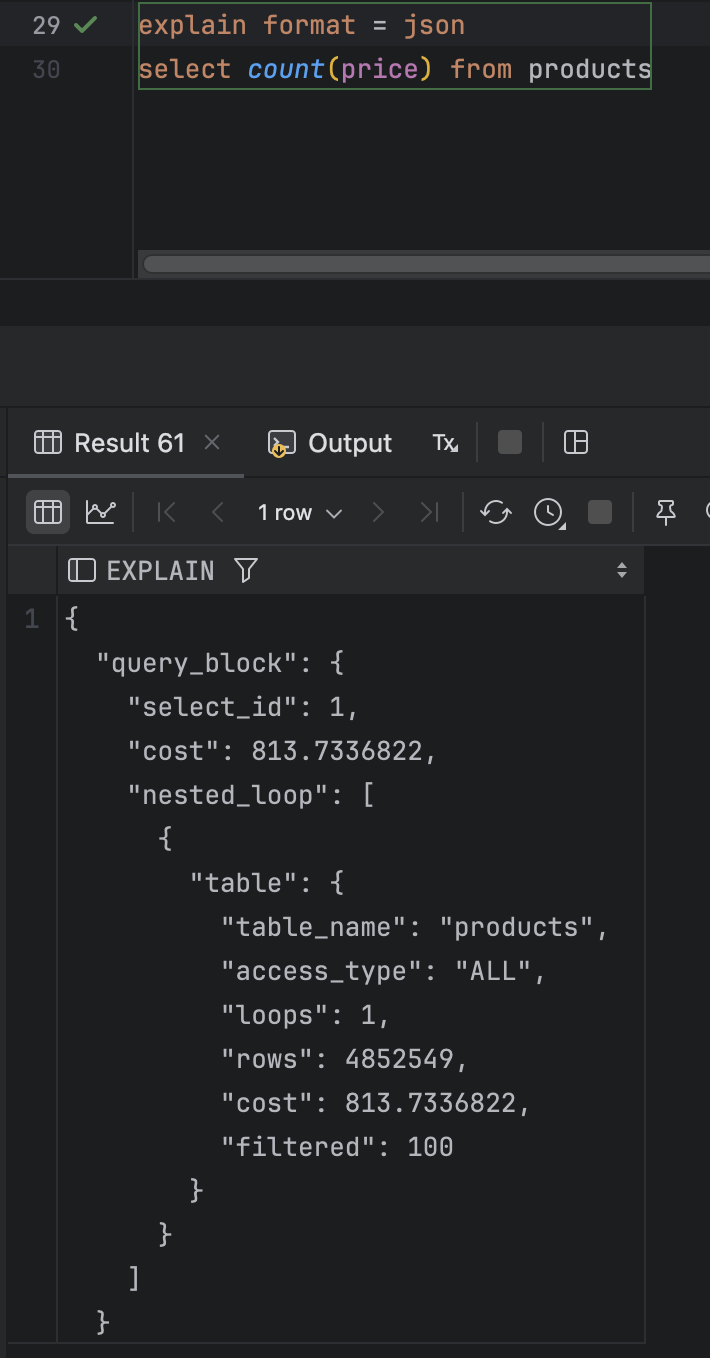
explain은 정확한 결과를 답해주는게 아니라 통계 정보를 기반으로 계산한 예측값이라고 한다. 근데 전체를 조회할 때도, id로 count 할 때도, price로 조회를 할 때도 달랐다.
내가 예상한 것은 count() 와 count(id)가 같을 순 있으나 count(price)는 달라야한다고 생각했다.
왜냐하면 count() 는 보조 인덱스가 없으면 클러스터 인덱스를 이용한다고 하는데 pk인 id는 클러스터 인덱스이다. 흐으으음.... 그냥 count()를 하는걸 짰기 때문에 결과론적으로 1,2,3번 모두 실제 컬럼의 내용을 알 필요가 없다고 판단해서 였을까? 모두 같은 결과를 냈다.
그러고 나서 정신을 차리고 코드리뷰를 다시 살펴보았을 때는 쿼리가 select 쿼리가 나가는 것이었다. count가 아닌 이것에 대해서도 테스트를 해보자.
count(*) from 테이블명 vs select(pk) from 테이블의 size
뭐에 씌였는지 리뷰에 답변을 다는 동안 count()에 잡혀있었다. 그런데 정신차리고 다시 코드를 보고 테스트를 돌려보니 당황스럽게도 추천해준 코드는 내가 생각한 count가 아닌 select가 나갔다.
추천해주신 코드의 count를 하는 쿼리
Hibernate:
select
p1_0.product_id
from
products p1_0이걸 보고 엥? 왜 select count가 아닌 일반 select가 나가? 했는데 코드를 다시보니까 select 하고 size()를 확인하는 것이었다.
그리고 내 코드는 어떻게 나갔을지 확인해보았다.
JPAQuery<Long> count = queryFactory.select(product.count())
.from(product);기존 코드이다 querydsl에 대해서는 이제야 걸음마를 떼어 학습을 진행하고 있기 때문에 나중에 더 자세히 알게되면 정리해보려고 한다.
그리고 결과를 보자
Hibernate:
select
count(p1_0.product_id)
from
products p1_0당연하게도 count가 나갔다. 그리고 내 생각과는 다르게 count(*)을 하는 것도 아닌 count(id)가 나갔다.
앞에서 db에서 본것처럼 성능상의 차이도 없고 count(*)은 보조 인덱스가 없으면 자동으로 클러스터인덱스를 찾아서 값을 넣는다고 하니까 어쩌면 당연한거일수도 있다.
하지만 세상에 마법은 없기 때문에 내가 querydsl 그리고 jpa에 대한 이해가 부족한 것일 수도 있다.
두가지 테스트를 진행 해볼 것이다. 먼저 DB에서 실행계획을 통해 확인하여 select id from product vs count(id) from product 두가지의 차이가 없다면 전자는 .size()를 하기 때문에 한번 더 과정을 거치는게 손해지 않을까? 라는 생각에 부하테스트도 진행해볼 예정이다.
DB 테스트
단순하게 아까와 같이 explain을 통해 확인해보자.
count(id) from product
당연히 아까와 동일한 결과이다.
explain format = json
select count(product_id) from products;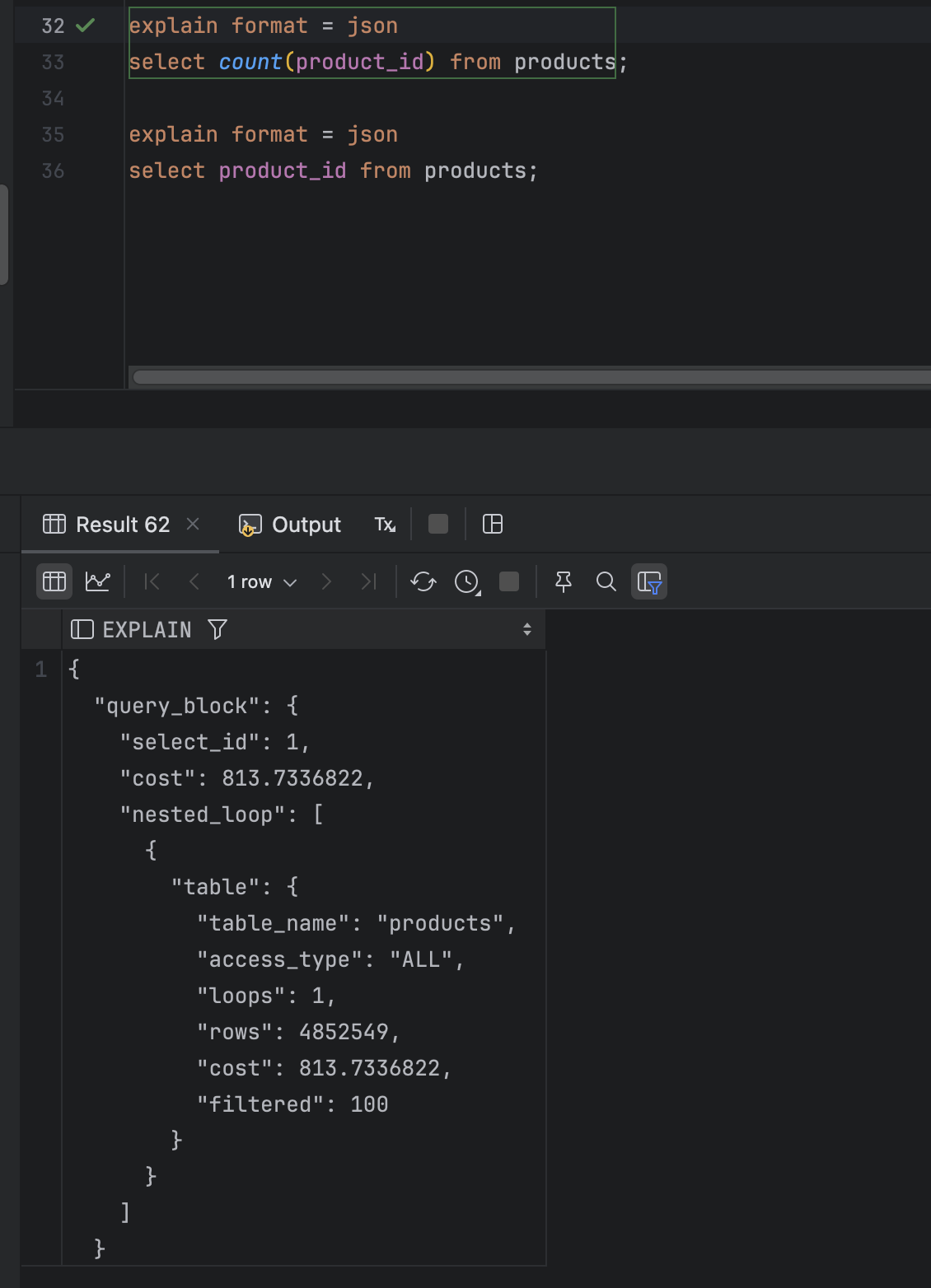
select id from product
explain format = json
select product_id from products;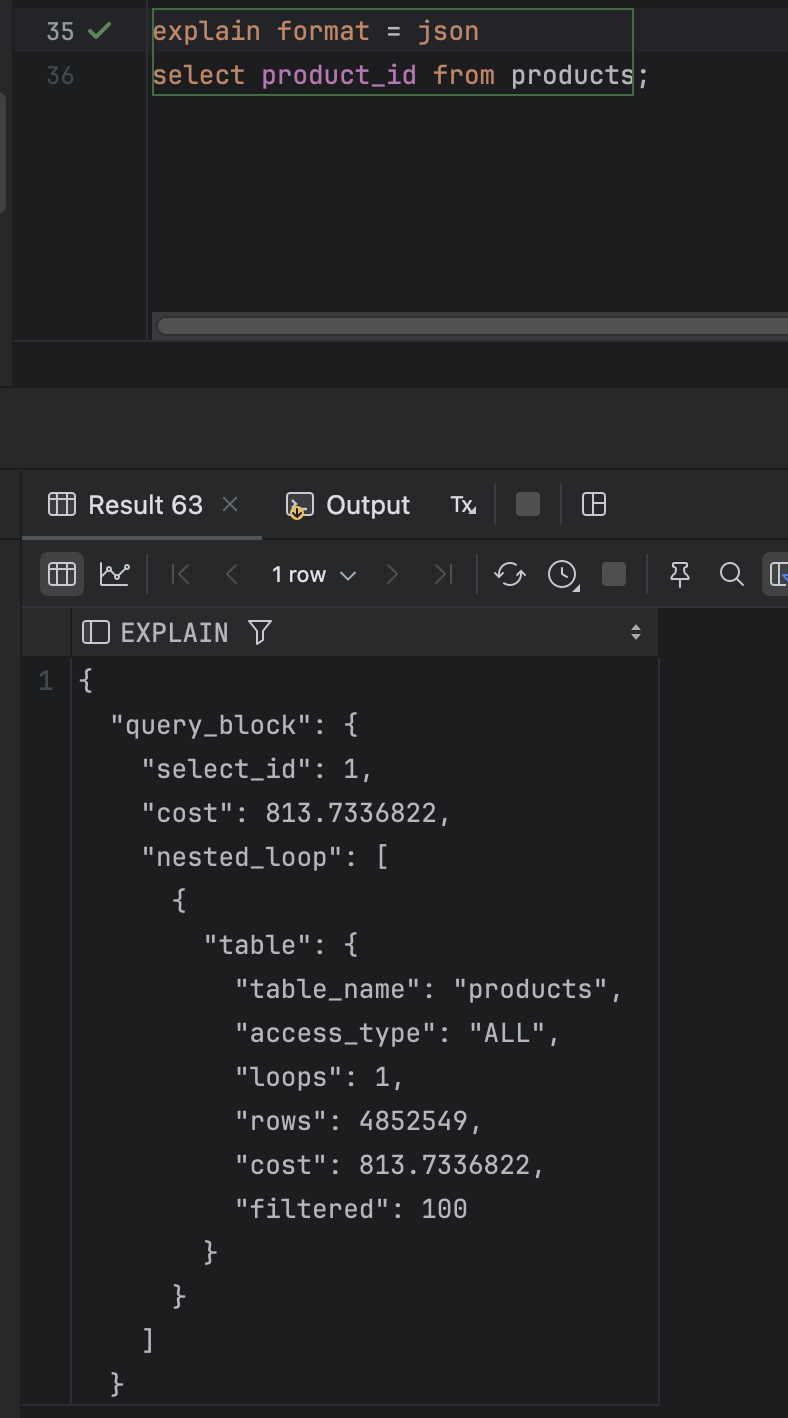
그냥 전부 다 똑같다 select id from product나 price나 count(*)을 하나 그게그거다
그냥 전부 다 1번부터 500만번까지 다 확인하는걸까 ? 아무리봐도 뭔가 문제가 있는거 같다..
그래서 여기까지 정리하고 커버링 인덱스를 보면서 한번 해보았다.
향로님의 글을 보고 따라해보았는데 난 using index가 안나온다..?
1. 커버링 인덱스 (기본 지식 / WHERE / GROUP BY)
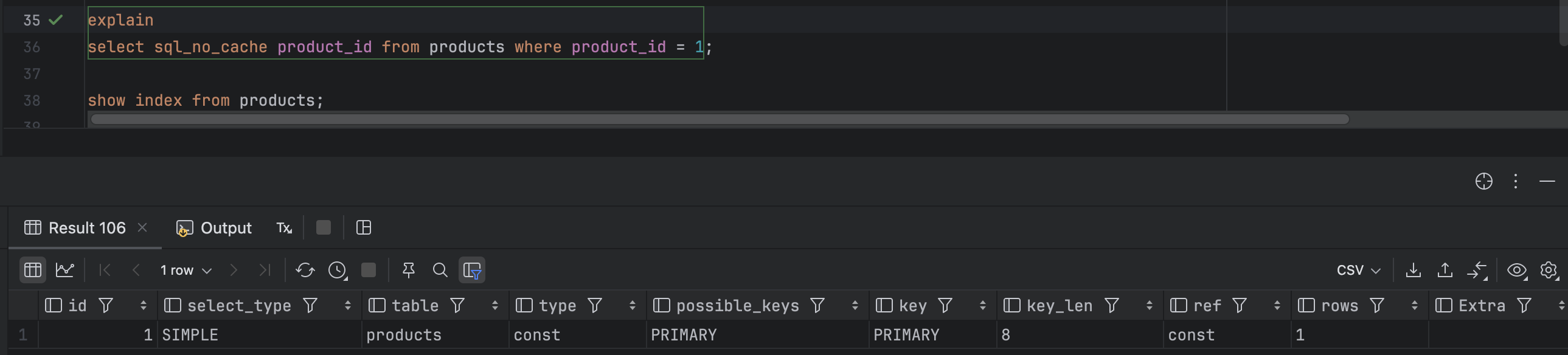
너무 의심스러워서 캐싱하고있나도 의심해서 노캐시로 만들었다. 그래도 안나온다.
그래서 인덱스가 없나 ? 아니면 Intellij에서 하는게 문제인가 하고 workbench로 옮겼다.
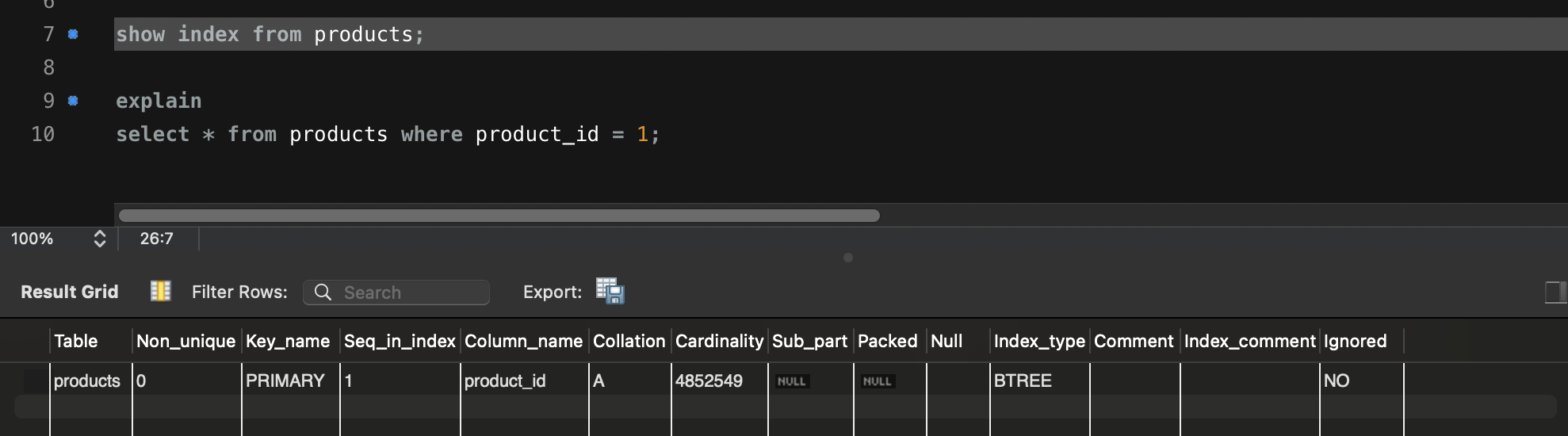
확실한건 인덱스는 있다. 그리고 workbench에서 실행했을 때도 첨부하겠다.
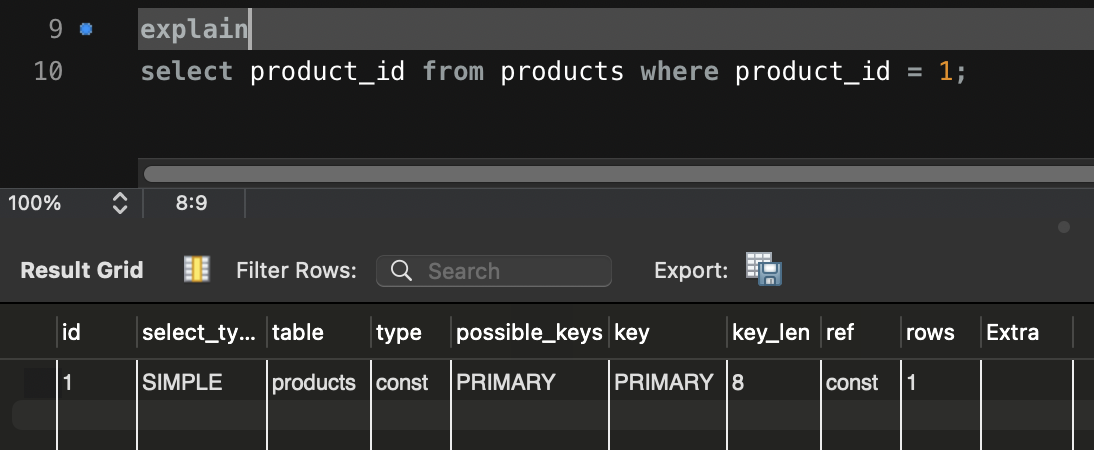
아쉽게도 안나온다........... 하 뭔가 문제가있는거 같긴한데 일단 DB에서는 누군가 찾아줬으면 좋겠다.
부하 테스트
부하테스트를 한번 진행해보자
부하 테스트를 진행하기 전 리팩토링 전과 리팩토링 후의 코드를 보고 가도록 하자
@Override
public Page<Product> findAllUsingQueryDsl(Pageable pageable) {
List<Product> products = queryFactory
.selectFrom(product)
.orderBy(product.id.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
long count = queryFactory
.select(product.id)
.from(product)
.fetch().size();
return new PageImpl<>(products, pageable, count);
}
@Override
public Page<Product> findAllUsingQueryDsl2(Pageable pageable) {
List<Product> products = queryFactory
.selectFrom(product)
.orderBy(product.id.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
JPAQuery<Long> count = queryFactory.select(product.count())
.from(product);
return PageableExecutionUtils.getPage(products, pageable, count::fetchOne);
}딱 querydsl을 쓴 부분만 차이가 있다. 2라고 쓴 것은 컨트롤러도 서비스도 2개 컨트롤러도 2개 만들어서 한 어플리케이션에서 jmeter로 둘 다 동시에 테스트해보려고 했다. 잘 안되긴했지만..
위의 코드는 리팩토링 후의 코드로 커버링 인덱스를 이용하는 방법(근데 난 지금 explain에서 인덱스를 사용하는건지 안나와서 모르겠는데 개념상으론 쿼리상에 index 컬럼밖에없으니 맞지않을까 생각한다)
select id from product 를 한 이후 size()를 이용해 갯수를 세는 방법
아래 코드는 리팩토링 전의 코드로 count(id) from product를 하는 코드이다.
일단 가볍게 Jmeter 세팅을 해둔 뒤 실행 시켜서 확인해본다.
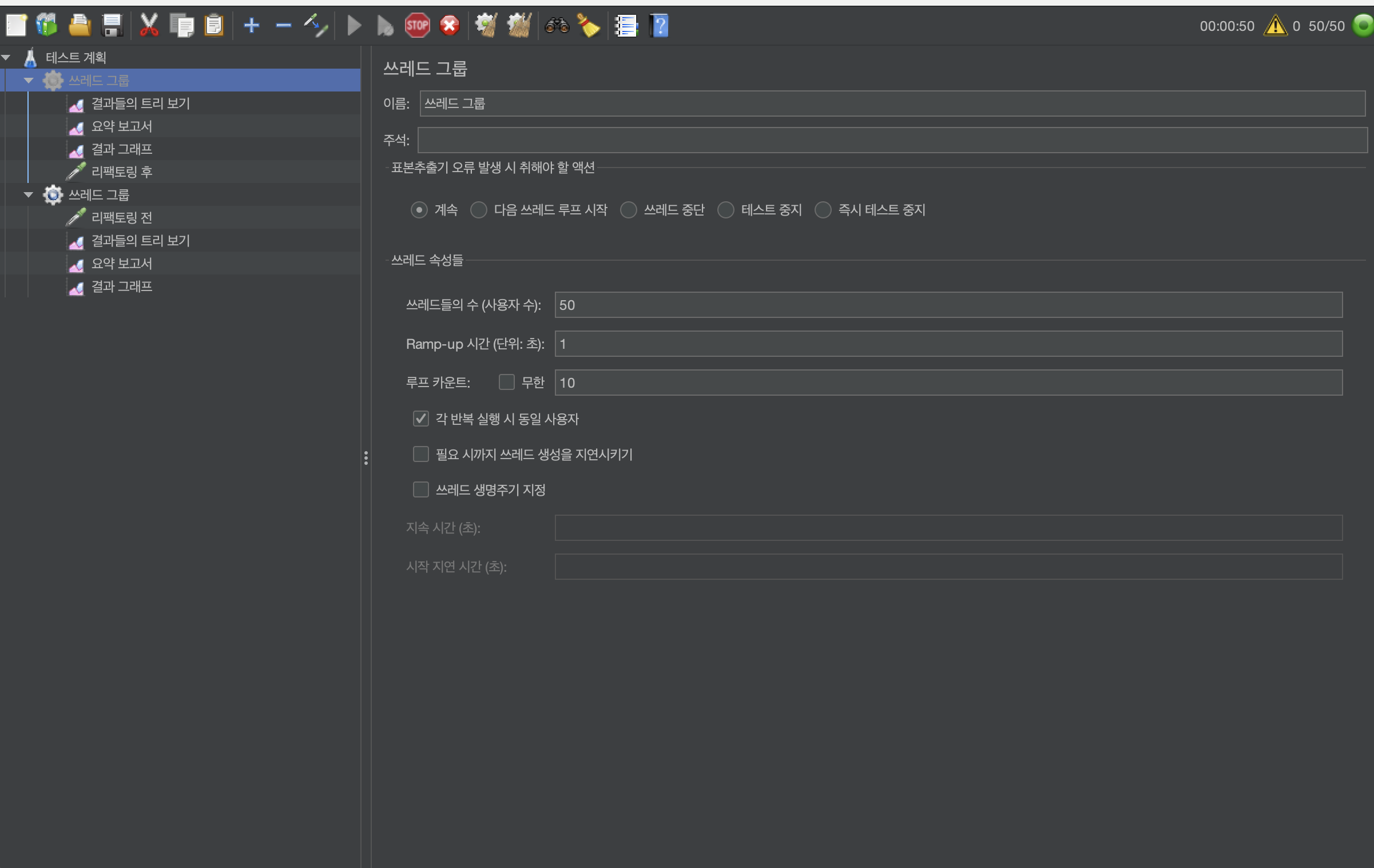
두 그룹을 똑같이 잡고 리팩토링 전이 size를 사용하지 않는 코드 그리고 리팩토링 후가 size를 사용하는 코드리뷰 받은 코드이다.
그런데 자꾸 두개 같이 돌리면 못견뎌서 하나씩 돌리려고 한다.

우선 리팩토링 전은 결과가 이렇게 평균 평균 응답속도가 7500ms 정도이다.
그리고 가장 문제는 리팩토링 후인데 얘가 자꾸 오류가 난다.
타임아웃이 계속 나면서 제대로 된 테스트를 진행 할 수 없었다.



하도 터져서 제대로 된 측정이 불가능했다.. 데이터를 전부 다 읽어오는것도 문제고 size를 잴 때 500만개다 보니까 size()로 하기가 감당이 안되는걸까?
일단 최대한 사용자를 줄여서 요청을 보내보았다. 너무 터져서 한시간내내 이거만 한거같다..

사용자 수 5명에 카운트를 10개 줘서 확인했는데도 평균 응답시간이 7922ms이 나왔다. 원래 /sec 단위로 나와야하는거아닌가? tps로 본다면..? TPS로 대충 환산하면 0.48쯤 나오지않을까 ? 2초에 1개정도 처리할 거 같다 처리량을 보면 1분에 37개는..

하지만 사용자 수 10명에 카운트 10개 줘서 확인했을 때 리팩토링 전은 평균응답시간 2966ms TPS는 3.2가 나왔다.
TPS 란 Transaction per Second로 초당 처리 할 수 있는 트랜잭션을 의미한다.
결론
하여튼 이게 내가 한 날려본 쿼리가 커버링 인덱스일까?는 모르겠다.. 그리고 커버링 인덱스 아직 감이 제대로 오지 않는다. 왜냐하면 난 using index가 안뜬다 ㅠㅠ 뭔일일까
하지만 얻게 된 결과는 있다. 리팩토링 전의 코드가 좀 더 낫다 ! 라는 사실이다. 사실 저 쿼리만이 달라지는게 아니라 리팩토링 후에는 new 로 pageImpl 객체를 새롭게 또 생성해서 반환하고 있기 때문에 이부분도 차이가 있나 싶기도 하다 가끔 Java Heap 이라면서 에러를 띄웠었다.
아직은 너무 실력이 부족하다.. 로그를 어떻게 잘찍었더라면 어떤 과정에서 오래걸리는지 알 수 있지 않았을까?
내가 느끼기에는 일단 쿼리는 동일하게 날라가지만 size()를 하는데서 오는 문제도 존재하는 것 같고 PagebleExcutionUtils을 이용해서 반환하는 것과 new PageImpl을 해서 반환하는 것의 차이도 존재 할 것 같다. 내가 mysql 의 explain 을 통해 확인해본 것으론 두 쿼리의 차이는 없어보인다.
아마도 어디서부턴가 문제가 있어서 이러한 결과를 가져온 걸수도 있다고 생각이 든다. 하지만 일단 리팩토링 후 코드는 계속 서버가 죽는다. 그러니까 그냥 리팩토링 전 코드를 쓰는게 낫겠다. 리팩토링 후 코드는 생각보다 잘 버틴다.
그리고 과거에는 jmeter로 테스트했을 때 이정도가 아니였던 것 같은데 데이터를 500만개나 넣어서 그런가 계속 서버가 터져서 시간을 엄청썼따.... 이래서 부하분산이 중요하구나 싶다. 솔직히 정확하게 이해한건 아니다 그래도 하나씩 공부해나가면서 채우면되겠지...😂 언젠가 이 경험이 빛을 볼 때가 오면 좋겠다.
참조
[Querydsl] Pagination 성능 개선 part1.PageableExecutionUtils
[DBMS] [MySQL] COUNT의 잘못된 인식과 속도차이
추가
[우아콘2020] 수십억건에서 QUERYDSL 사용하기
querydsl과 커버링인덱스에 대해 공부하다가 영상을 찾게 되었다.
커버링인덱스를 다루는 곳은 이러한 단순 전체컬럼의 수를 세는 곳이 아닌 where 조건절 안의 서브쿼리의 성능을 개선하기 위해서 사용되는 것 같다. 아직 조금 더 공부해야겠지만 영상에 나오는 단어들 중 적용해보면 좋을 부분이 많이 존재한다.
