5장 그룹 함수를 사용한 데이터 집계
📌 그룹 함수란?
- upper라는 함수가 있다고 하자. 데이터 하나가 들어가서 하나가 나왔다. 이것은 3장에서 배운 함수이다.
- 5장에서 배울 함수는, 함수 안으로 여러가지가 들어가, 바깥으로는 하나가 나오는 것이다. 예를 들면 max라는 함수는 여러가지가 함수안으로 들어가 가장 큰 한 건만 출력한다. 지금부터 그룹 함수를 배워보자.
📌 그룹함수 종류
- AVG
- COUNT
- MAX
- MIN
- STDDEV
- SUM
- VARIANCE
📌 AVG 및 SUM 함수
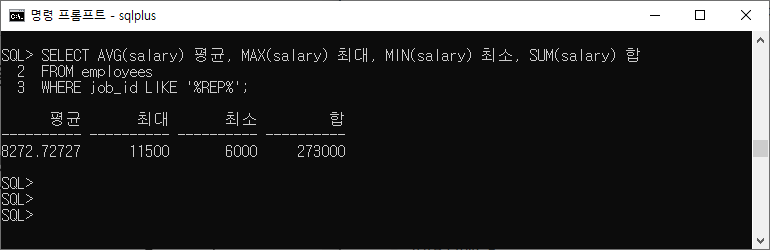
SELECT AVG(salary) 평균, MAX(salary) 최대, MIN(salary) 최소, SUM(salary) 합 FROM employees WHERE job_id LIKE '%REP%';
- 여러개의 데이터가 들어가서 한 개의 출력을 보여준다.
📌 MIN 및 MAX 함수
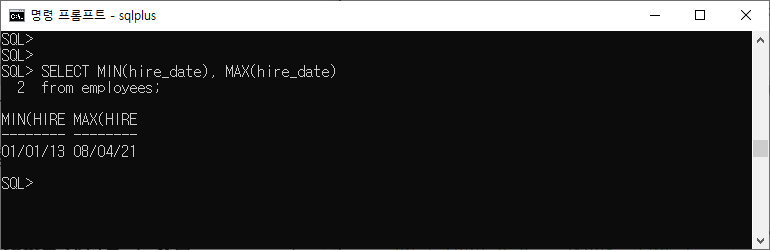
SELECT MIN(hire_date), MAX(hire_date) from employees;
위의 결과를 낸 사람은 누굴까? 가장 막내는 누구인가? 누가 기침 소리를 내었어?(ㅋㅋ)
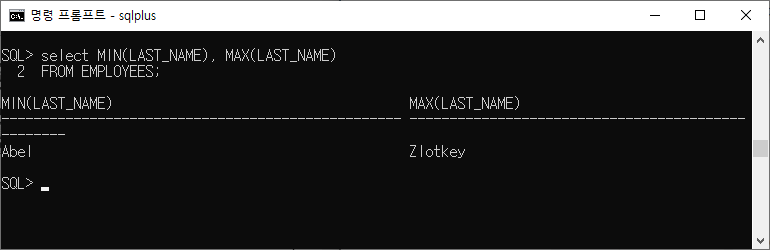
그걸 알기위한 것이 서브쿼리이다.select MIN(LAST_NAME), MAX(LAST_NAME) FROM EMPLOYEES;
📌 COUNT 함수
- 이 함수를 만족하는 건 수를 확인할 수 있다.
SELECT COUNT(*) FROM employees WHERE department_id = 50;
-예제) employees 테이블에서 부서 값의 수를 표시하라.
SELECT COUNT(department_id) from employees;
위와 같이 코드를 쓰면 틀렸다.
왜냐하면 중복으로 세었기 때문. (부서번호 50, 50, 50 을 3으로 센다. null이 아닌 것은 다 센다.)
- DISTINCT 키워드 사용를 사용해주자.


📌 그룹 함수 및 널 값
- 그룹 함수는 해당 열의 널 값을 무시한다.
select AVG(commission_pct) from employees;
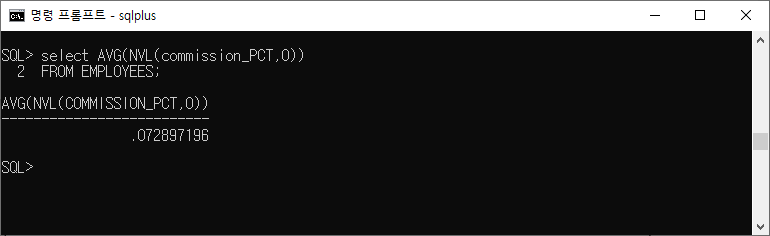
📌 그룹 함수에 NVL 함수 사용
select AVG(NVL(commission_PCT,0)) FROM EMPLOYEES;

📌 데이터 그룹 생성 : Group By절
※항상 마지막에 하는 것이 정렬이다. 그러므로 order by 앞에 작성한다.
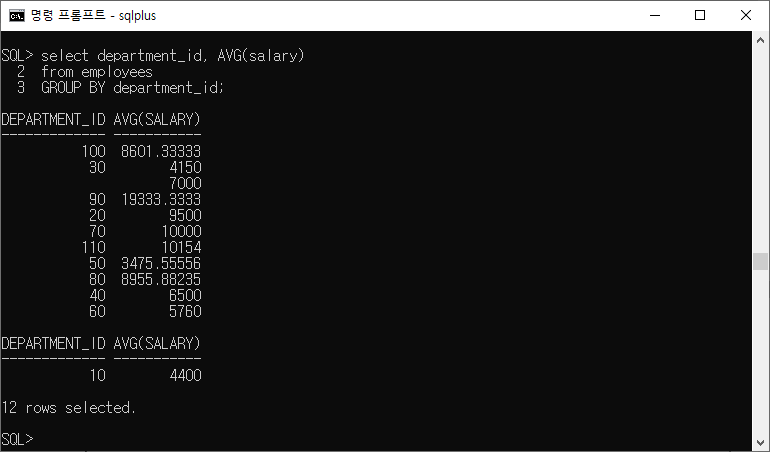
select department_id, AVG(salary) from employees GROUP BY department_id;
- 부서번호가 나오고 그 부서의 평균 월급을 출력한다.
📌 그룹 함수를 사용할 때 주의사항
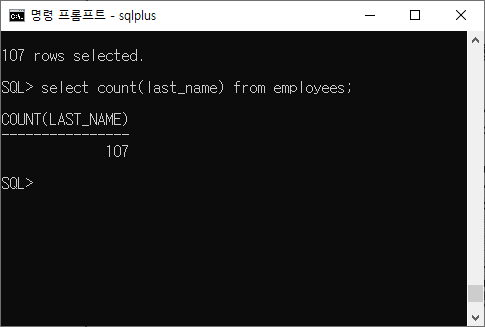
SQL> select department_id from employees 2 ;107 rows selected. -> 107건이 나온다
SQL> select count(last_name) from employees;
한 건이 나온다.
그룹함수는 기본적으로 한 건이 나오는 것이다. 주의하자!
- 따라서 그룹함수 사용할 때에는 건 수가 같은지 확인해봐야한다.
📌 그룹 결과 제외 : Having 절
- 행이 그룹화된다.
- 그룹 함수가 적용된다.
- Having 절과 일치하는 그룹이 표시된다.
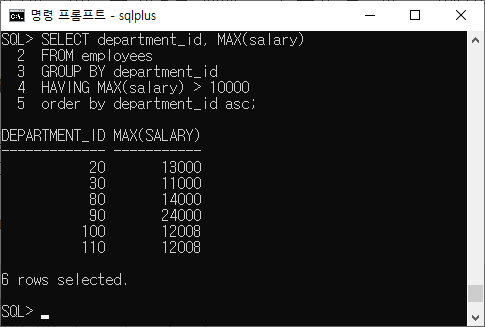
※group by 다음 order by 전에 쓴다.SELECT department_id, MAX(salary) FROM employees GROUP BY department_id HAVING MAX(salary) > 10000;
(보기좋게 정리하였다.)
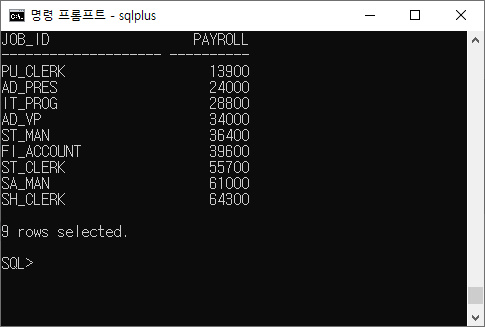
select job_id, sum(salary) PAYROLL from employees where job_id not like '%REP%' GROUP BY job_id HAVING SUM(salary) > 13000 ORDER BY SUM(salary);
- 월급 총액이 13000$를 넘는 각 업무에 대해 업무 id와 월급을 표시하는데, 영업 사원을 제외시킨 것을 총액에 따라 목록을 정렬한다.
📌 그룹 함수 중첩
최고 평균 급여를 표시하여라
select max(avg(salary)) from employees
group by department_id;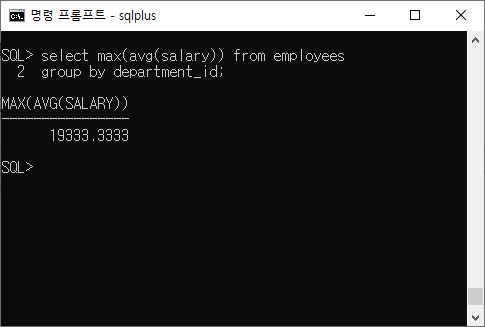
📌 연습문제
5-1) 다음 세 문장의 유효성을 판별하여 true or false로 답하시오.
코드를 입력하세요설명
(사진)
5-2) 그룹 함수는 계산에 널을 포함합니다. true/false
코드를 입력하세요설명
(사진)
5-3) WHERE 절은 그룹 계산에 행을 포함시키기 전에 행을 제한합니다.
코드를 입력하세요설명
(사진)
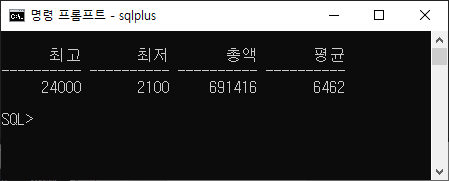
5-4) 모든 사원의 급여 최고액, 최저액, 총액 및 평균액을 표시하시오. 열 레이블을 각각 Maximum, Minimum, Sum 및 Average로 지정하고 결과를 정수로 반올림한 후 작성하시오.
select max(salary) 최고, min(salary) 최저, sum(salary) 총액, round(avg(salary),0) 평균 from employees;
- 모든 사원의 최고급여, 최저급여, 급여총액, 평균급여
- 결과를 정수로 반올림하라.
5-5) 4번 문제를 수정하여 각 업무 유형별로 급여 최고액, 최저액, 총액 및 평균액을 표시하시오.
SELECT job_id, max(salary), min(salary), sum(salary), avg(salary) FROM employees GROUP BY job_id;
- 업무유형(job_id)별로 최고, 최저, 총액, 평균 -> 업무유형으로 그룹으로 묶어라

5-6) 업무가 동일한 사원 수를 표시하는 질의를 작성하시오.
SELECT job_id, count(*) FROM employees GROUP BY job_id;-업무가 동일하니까 업무를 기준으로 묶고, count 하면 된다.

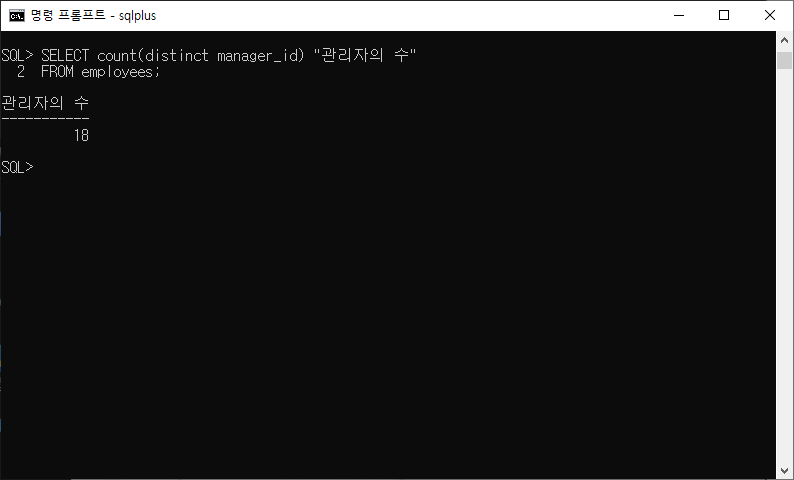
5-7) 관리자는 나열하지 말고 관리자 수를 확인하시오. 열 레이블은 number of managers로 지정하시오.
SELECT count(distinct manager_id) "관리자의 수" FROM employees;
- 관리자의 수 : 관리자 사번의 수
- 사원정보테이블 : 사원번호, 이름...,관리자 사번
- 중복을 제거하고 관리자 사번을 센다.
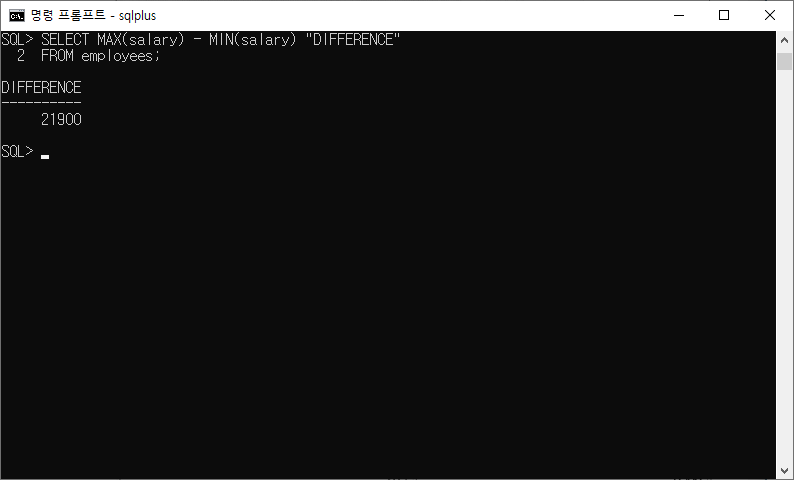
5-8) 최고 급여와 최저 급여의 차액을 표시하는 질의를 작성하고 열 레이블을 difference로 지정하시오.
SELECT MAX(salary) - MIN(salary) "DIFFERENCE" FROM employees
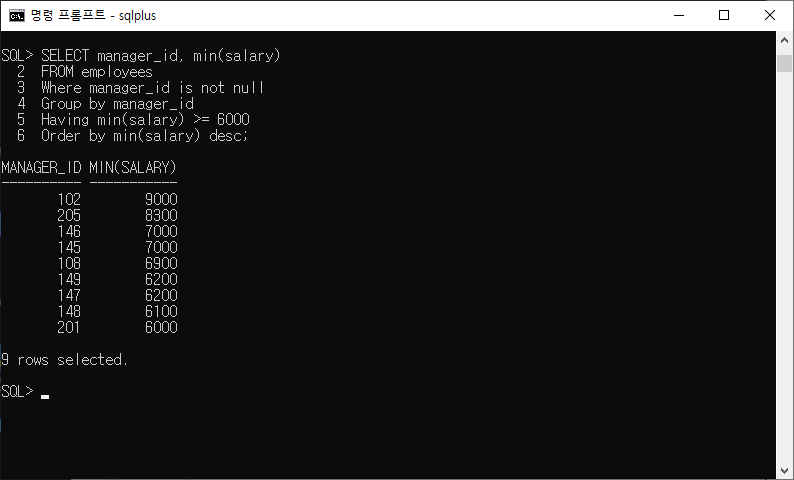
5-9) 관리자 번호 및 해당 관리자에 속한 사원의 최저 급여를 표시하시오. 관리자를 알 수 없는 사원 및 최저 급여가 $6000 미만인 그룹은 제외시키고 결과를 급여에 대한 내림차순으로 정렬하시오.
SELECT manager_id, min(salary) FROM employees Where manager_id is not null Group by manager_id Having min(salary) >= 6000 Order by min(salary) desc;
- 관리자 없는 사원 제외(조건) -> WHERE
- 최저 급여가 6000$ 미만인 그룹 제외(그룹 조건) -> Having
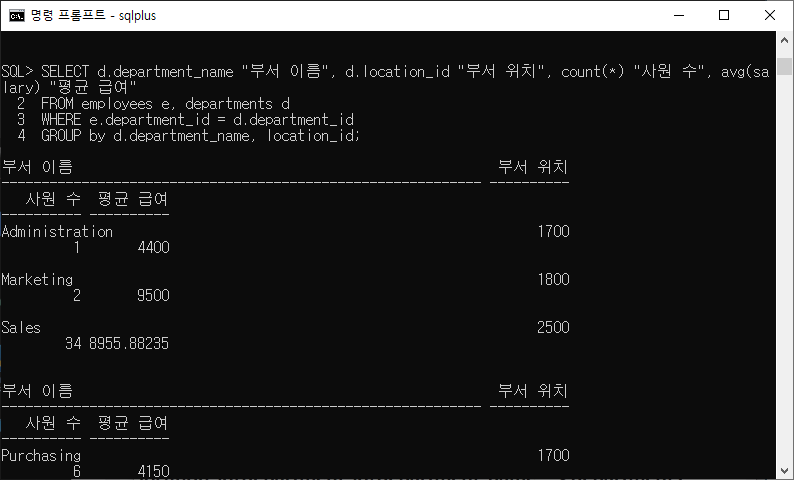
5-10) 각 부서에 대해 부서 이름, 위치, 사원 수, 부서 내 모든 사원의 평균 급열르 표시하는 질의를 작성하고, 열 레이블을 각각 name, location, number of people 및 salary로 지정하시오. 평균 급여는 소수점 둘재 자리로 반올림하시오.
SELECT d.department_name "부서 이름", d.location_id "부서 위치", count(*) "사원 수", avg(salary) "평균 급여" FROM employees e, departments d WHERE e.department_id = d.department_id GROUP by d.department_name, location_id;
- 각 부서에 대해 -> 부서번호(department_id)를 그룹으로
- 부서이름(department_name), 부서위치(location_id)
- 평균급여(avg(salary))
- salary/department_id ->employees
- location_id/department_id/department_name -> departments
- 이므로 무조건 조인을 써야한다.
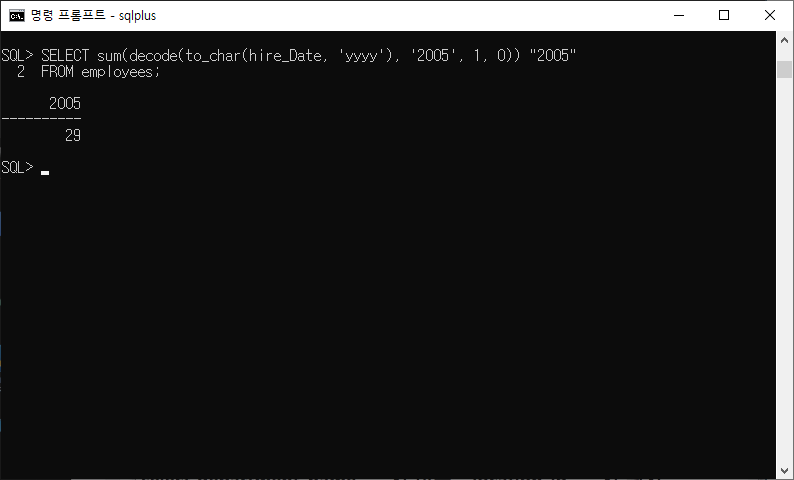
5-11) 총 사원 수 및 ,,, 년도에 입사한 사원 수를 표시하는 질의를 작성하고 적합한 열 머리글로 작성하시오.
SELECT sum(decode(to_char(hire_Date, 'yyyy'), '2005', 1, 0)) "2005" FROM employees;
- 2005년에 입사한 사원 수 -> to_char(hire_Date, 'yyyy')와 2005비교
- sum(decode(to_char(hire_Date, 'yyyy'), '2005', 1, 0))
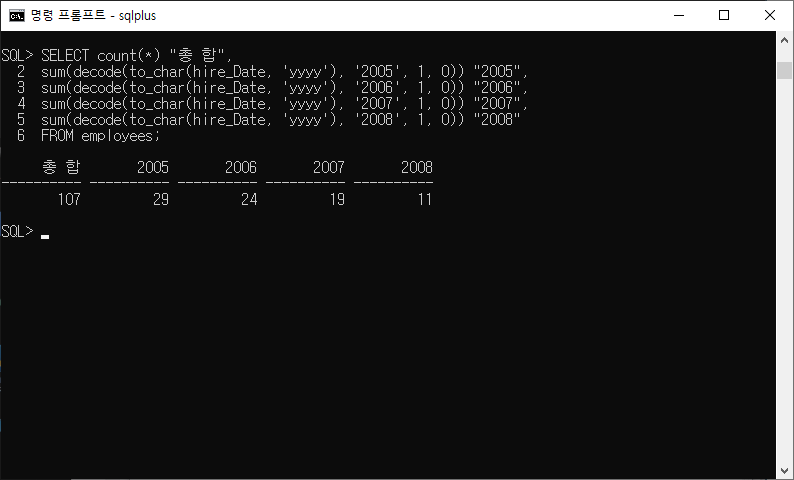
SELECT count(*) "총 합", sum(decode(to_char(hire_Date, 'yyyy'), '2005', 1, 0)) "2005", sum(decode(to_char(hire_Date, 'yyyy'), '2006', 1, 0)) "2006", sum(decode(to_char(hire_Date, 'yyyy'), '2007', 1, 0)) "2007", sum(decode(to_char(hire_Date, 'yyyy'), '2008', 1, 0)) "2008" FROM employees;
- 여기서 열 별칭에 큰따옴표를 달아준 이유는 숫자를 문자열로 인식시키기 위함이다.
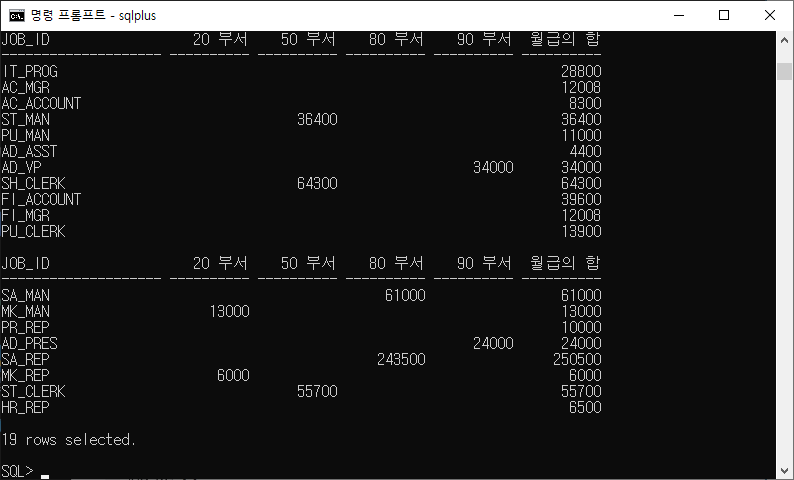
5-12) 업무를 표시한 다음 해당 업무에 대해 부서 번호별 급여 및 20, 50, 80 및 90의 급여 총액을 각각 표시하는 행렬 질의를 작성하고 각 열에 적합한 머리글로 지정하여 작성하시오.
SELECT job_id, sum(decode(department_id, 20, salary)) "20 부서", sum(decode(department_id, 50, salary)) "50 부서", sum(decode(department_id, 80, salary)) "80 부서", sum(decode(department_id, 90, salary)) "90 부서", sum(salary) "월급의 합" from employees group by job_id;*decode를 사용하는 문제
- 부서번화와 20비교, 50비교, 80비교, 90비교. 비교는 decode가 필요하다.
- decode(departmentid, 비교할부서번호, salary)
🍐오늘의 한마디
M사 버티컬 마우스 너무 가벼워서(좋으면서도) 자꾸 지 혼자 날라가는거 너무 거슬린당...😅 (tmi지만 나는 배가 특산물인 마을의 촌장이었다.😉)
