
group by
- 간단한 집계를 넘어서서 조건부로 집계하고 싶은 경우
df = pd.DataFrame({
'data1' : range(6),
'data2' : [4,4,6,0,6,1],
'key':['A','B','C','A','B','C']
})
df.groupby('key').sum() #1번
df.groupby(['key','data1']).sum() #2번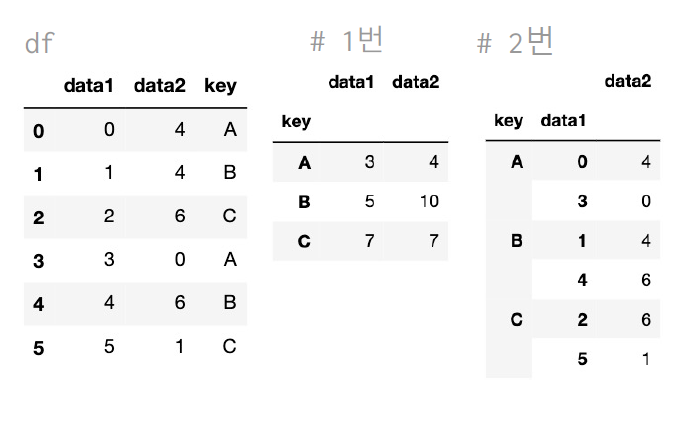
aggregate
- groupby를 통해서 집계를 한번에 계산하는 방법
df.groupby('key').aggregate([min, np.median, max]) #1번 | 집계함수는 ''로 묶임. np.median은 numpy에 들어있는 함수이므로 양식 지키키. max는 padas에 들어있는 더 큰 함수이므로 '' 안 써도 됨.
df.groupby('key').aggregate({'data1': 'min', 'data2': np.sum}) #2번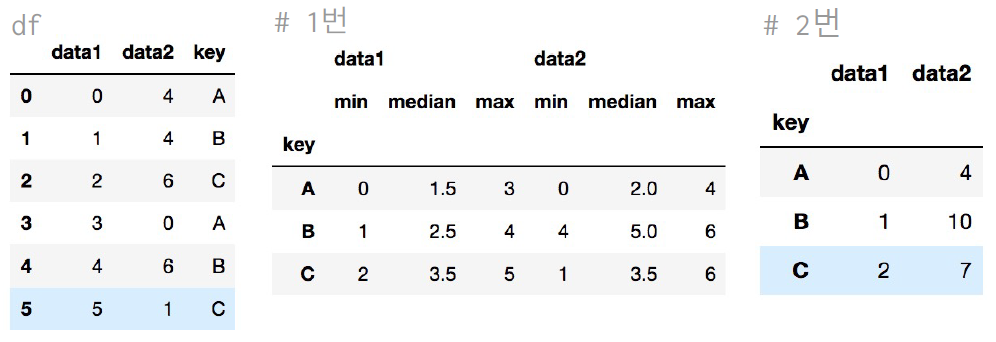
filter
- groupby를 통해서 그룹 속성을 기준으로 데이터 필터링
def filter_by_mean(x):
return x['data2'].mean() > 3
df.groupby('key').mean() #1번
df.groupby('key').filter(filter_by_mean) #2번 | 앞쪽에 필터링 하는 함수 정해주고 사용하기!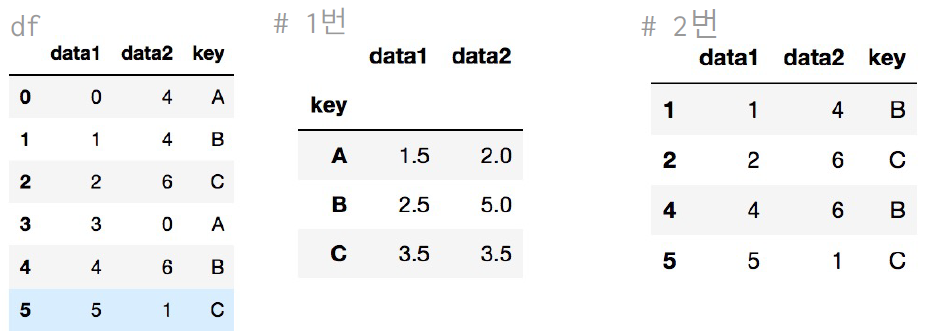
apply.lambda
- groupby를 통해서 묶인 데이터에 함수 적용
df.groupby('key').apply(lambda x: x.max() - x.min())

get_group
- groupby로 묶인 데이터에서 key값으로 데이터를 가져올 수 있다.
df = pd.read_csv("./univ.csv")
# 상위 5개 데이터
df.head()
# 데이터 추출
df.groupby("시도").get_group("충남")
len(df.groupby("시도").get_group("충남"))
# 94
[실습 3] 그룹으로 묶기(1)
문제
데이터 프레임의
key칼럼을groupby함수로 묶고,key별로 data1
data2과 data1
data2 합계를 출력해보세요.데이터 프레임의
key와data1칼럼을groupby함수로 묶고,key와data1별로 data2의 합계를 출력해보세요.import numpy as np import pandas as pd df = pd.DataFrame({ 'key': ['A', 'B', 'C', 'A', 'B', 'C'], 'data1': [1, 2, 3, 1, 2, 3], 'data2': [4, 4, 6, 0, 6, 1] }) print("DataFrame:") print(df, "\n")
code
# groupby 함수를 이용해봅시다.
# key를 기준으로 묶어 합계를 구해 출력해보세요.
print(df.groupby('key').sum())
# key와 data1을 기준으로 묶어 합계를 구해 출력해보세요.
print(df.groupby(['key', 'data1']).sum())실행 결과
DataFrame:
key data1 data2
0 A 1 4
1 B 2 4
2 C 3 6
3 A 1 0
4 B 2 6
5 C 3 1
data1 data2
key
A 2 4
B 4 10
C 6 7
data2
key data1
A 1 4
B 2 10
C 3 7[실습 4] 그룹으로 묶기(2)
문제
데이터 프레임을
key를 기준으로 묶고,key별data1과data2각각의 최솟값과 중앙값, 최댓값을 출력해봅시다.데이터 프레임을
key를 기준으로 묶고,key별data1의 최솟값과data2의 합계를 출력해봅시다.import numpy as np import pandas as pd df = pd.DataFrame({ 'key': ['A', 'B', 'C', 'A', 'B', 'C'], 'data1': [0, 1, 2, 3, 4, 5], 'data2': [4, 4, 6, 0, 6, 1] }) print("DataFrame:") print(df, "\n")
code
# aggregate를 이용하여 요약 통계량을 산출해봅시다.
# 데이터 프레임을 'key' 칼럼으로 묶고, data1과 data2 각각의 최솟값, 중앙값, 최댓값을 출력하세요.
print(df.groupby('key').aggregate([min,np.median,max]))
# 데이터 프레임을 'key' 칼럼으로 묶고, data1의 최솟값, data2의 합계를 출력하세요.
print(df.groupby('key').aggregate({'data1':min, 'data2':sum}))실행 결과
DataFrame:
key data1 data2
0 A 0 4
1 B 1 4
2 C 2 6
3 A 3 0
4 B 4 6
5 C 5 1
data1 data2
min median max min median max
key
A 0 1.5 3 0 2.0 4
B 1 2.5 4 4 5.0 6
C 2 3.5 5 1 3.5 6
data1 data2
key
A 0 4
B 1 10
C 2 7
개발자로 시작| 공부한 것을 기록합니다.