
집계함수
count
- count메서드 활용하여 데이터 개수 확인 가능
(Default : NaN값 제외)
data = {
'korean': [50, 60, 70],
'math': [10, np.nan, 40]
}
df = pd.DataFrame(data, index = ['a','b','c'])
df.count(axis = 0) # 열 기준
df.count(axis = 1) # 행 기준
데이터 타입 정수형임을 유의해서 살피자!
max, min
- max, min메서드 활용하여 최대, 최소값 확인 가능
(Default : 열 기준, NaN값 제외)
data = {
'korean': [50, 60, 70],
'math': [10, np.nan, 40]
}
df = pd.DataFrame(data, index = ['a','b','c'])
df.max() # 최댓값
df.min() # 최솟값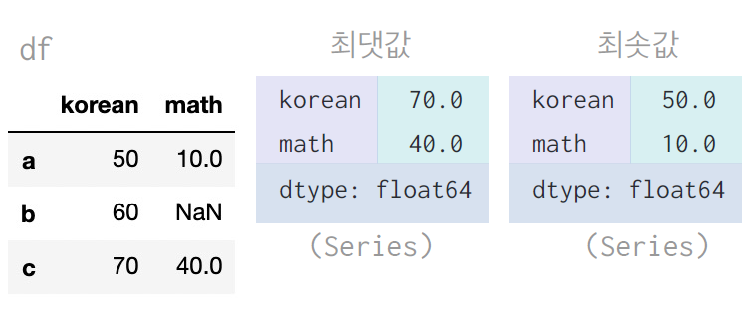
데이터 타입 실수형임을 유의해서 살피자!
sum, mean
- sum, mean메서드 활용하여 합계 및 평균 계산
(Default : 열 기준, NaN값 제외)
data = {
'korean': [50, 60, 70],
'math': [10, np.nan, 40]
}
df = pd.DataFrame(data, index = ['a','b','c'])
df.sum() # 합계
df.mean() # 평균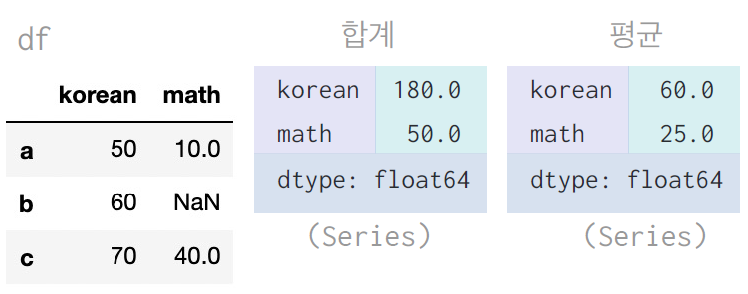
데이터 타입 실수형!
- axis, skipna 인자 활용하여 합계 및 평균 계산
(행 기준, NaN값 포함 시)axis = 1이면 행 기준으로 계산skipna = True이면 na 값을 무시skipna = False이면 na 값 포함
data = {
'korean': [50, 60, 70],
'math': [10, np.nan, 40]
}
df = pd.DataFrame(data, index = ['a','b','c'])
df.sum(axis = 1) # 합계
df.mean(axis = 1, skipna = False) # 평균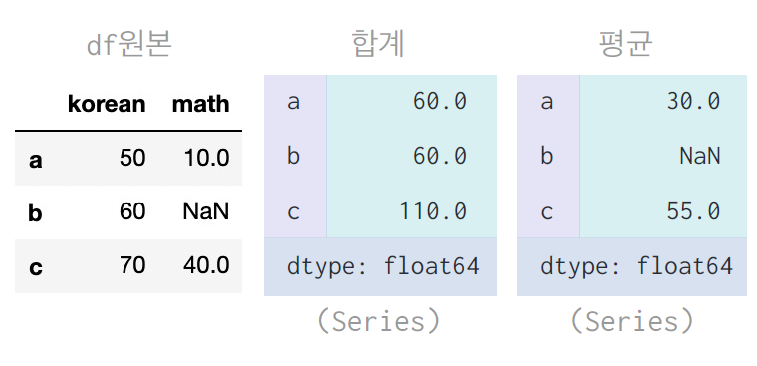
- NaN값에 숫자를 대신 집어넣는 방법
- NaN값이 존재하는 column의 평균 구하여 NaN값 대체
…
B_avg = df['math'].mean()
print(B_avg) # 25.0
# NaN값 대체
df['math'] = df['math'].fillna(B_avg)
# 평균
df.mean(axis = 1, skipna = False)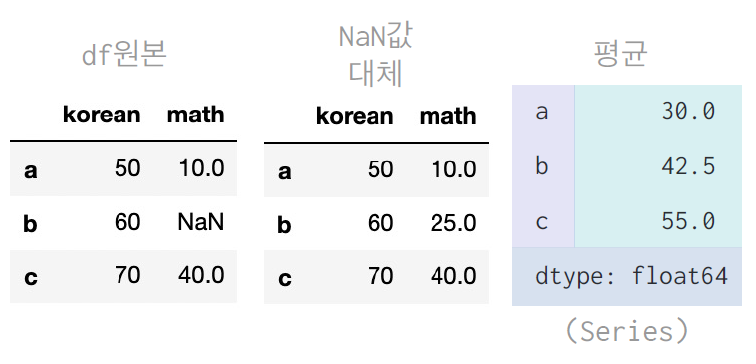
이 때의 데이터 타입도 float! 실수형.
[실습 2] 집계함수
문제
데이터 프레임
df에는korean,math컬럼이 각 과목의 성적을 담고있습니다.
df 데이터 프레임에 함수를 이용하여 아래 미션을 수행해봅시다.
- 각 컬럼별 데이터 개수를
col_num변수에 저장하고 출력해보세요.- 각 행별 데이터 개수를
row_num변수에 저장하고 출력해보세요.- 각 컬럼별 최댓값을 구하여
col_max변수에 저장하고 출력해보세요.- 각 컬럼별 최솟값을 구하여
col_min변수에 저장하고 출력해보세요.- 각 컬럼별 합계를 구하여
col_sum변수에 저장하고 출력해보세요.math컬럼의 결측값을 해당 컬럼의 최솟값으로 대체하고df를 출력해보세요.- 각 컬럼별 평균을 구하여
col_avg변수에 저장하고 출력해보세요.mport numpy as np import pandas as pd data = { 'korean' : [50, 60, 70], 'math' : [10, np.nan, 40] } df = pd.DataFrame(data, index = ['a','b','c']) print(df, "\n")
code
# 각 컬럼별 데이터 개수
col_num = df.count(axis = 0)
print(col_num, "\n")
# 각 행별 데이터 개수
row_num = df.count(axis = 1)
print(row_num, "\n")
# 각 컬럼별 최댓값
col_max = df.max()
print(col_max, "\n")
# 각 컬럼별 최솟값
col_min = df.min()
print(col_min, "\n")
# 각 컬럼별 합계
col_sum = df.sum()
print(col_sum, "\n")
# 컬럼의 최솟값으로 NaN값 대체
math_min = df['math'].min()
df['math'] = df['math'].fillna(math_min)
print(df, "\n")
# 각 컬럼별 평균
col_avg = df.mean()
print(col_avg, "\n")실행 결과
korean math
a 50 10.0
b 60 NaN
c 70 40.0
korean 3
math 2
dtype: int64
a 2
b 1
c 2
dtype: int64
korean 70.0
math 40.0
dtype: float64
korean 50.0
math 10.0
dtype: float64
korean 180.0
math 50.0
dtype: float64
korean math
a 50 10.0
b 60 10.0
c 70 40.0 
개발자로 시작| 공부한 것을 기록합니다.