
데이터 프레임, 시리즈 데이터에 대해 데이터 찾는 방법
데이터 선택
- .loc(locaton의 약자) : 명시적 인덱스 참조
country.loc['china'] # 인덱싱
country.loc['japan':'korea', :'population'] # 슬라이싱- .iloc: 암묵적 인덱싱 참조. 파이썬 스타일의 정수 인덱스를 참조함.
country.iloc[0] # 인덱싱
country.iloc[1:3, :2] # 슬라이싱인덱싱 결과에 1.409250e+09 이런식으로 표기되는데 여기서 e는 10의 n승(+이후 숫자)을 의미함. 이건 10의 9승.
- 컬럼선택: 컬럼명 활용하여 DataFrame에서 데이터 선택 가능
country
country['gdp'] # 시리즈
country[['gdp']] # 데이터프레임시리즈

데이터 프레임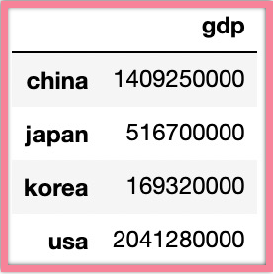
시리즈의 값이 모이면 데이터프레임이 됨!
- 조건 활용: 데이터 프레임의 column 뿐만 아니라 value 값을 정확히 안다면, Masking연산이나 query 함수를 이용해 조건 활용 가능.
country[country['population'] < 10000] # masking 연산 활용. population이라는 column 값 정확히 알 때 사용.
country.query("population > 100000") # query 함수 활용데이터 변경
- 컬럼 추가 : Series도 numpy array처럼 연산자 활용 가능
gdp_per_capita = country['gdp'] / country['population'] # 1인당 GDP
country['gdp per capita'] = gdp_per_capita # 아래 사진처럼 추가됨.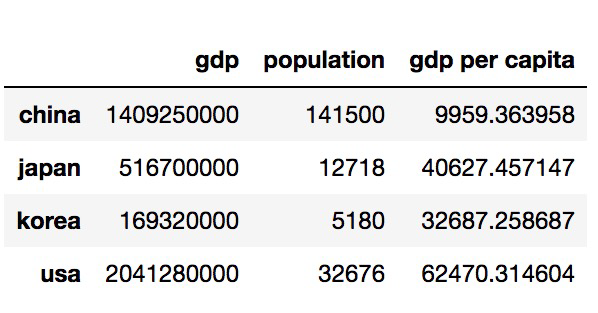
- 데이터 추가/수정: 리스트로 추가 or 딕셔너리로 추가
df = pd.DataFrame(columns = ['이름','나이','주소']) # 데이터프레임 생성
df.loc[0] = ['길동', '26', '서울'] # 리스트로 데이터 추가
df.loc[1] = {'이름':'철수', '나이':'25', '주소':'인천'} # 딕셔너리로 데이터 추가
df.loc[1, '이름'] = '영희' # 명시적 인덱스 활용하여 데이터 수정데이터 프레임 생성 
데이터 추가 결과 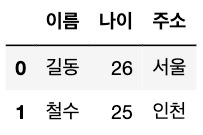
데이터 수정 결과 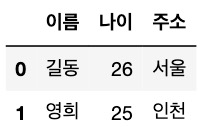
- NaN 컬럼 추가: NaN값으로 초기화 한 새로운 컬럼 추가
df['전화번호'] = np.nan # 새로운 컬럼 추가 후 초기화|nan = Not a Number. 즉, 숫자가 아니다. 이것은 비어있는 데이터다라는 뜻.
df.loc[0, '전화번호'] = '01012341234' # 명시적 인덱스 활용하여 데이터 수정컬럼추가 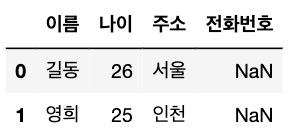
데이터 수정 결과 
- 컬럼 삭제: DataFrame에서 컬럼 삭제 후 원본변경
df.drop('전화번호', axis = 1, inplace = True) # 컬럼 삭제
# axis = 1 : 열 방향 / axis = 0 : 행 방향
# inplace = True : 원본 변경. 요거 사용할 땐 꼭 원본을 따로 저장한 후 사용하기. / inplace = False : 원본 변경 X[실습 3] 조건을 충족하는 값 추출
문제
주어진 값에서,
1. A컬럼 값이 0.5보다 작고 B컬럼 값이 0.3보다 큰 값들을 마스킹 연산을 활용하여 출력해보세요.
2. 위와 같은 조건의 값들을 query 함수를 활용하여 출력해보세요.import numpy as np import pandas as pd print("Masking & query") df = pd.DataFrame(np.random.rand(5, 2), columns=["A", "B"]) print(df, "\n") # 데이터 프레임에서 A컬럼값이 0.5보다 작고 B컬럼 값이 0.3보다 큰값들을 구해봅시다.
code
# 마스킹 연산을 활용하여 출력해보세요!
print(df[(df['A']<0.5)&(df['B']>0.3)])
# query 함수를 활용하여 출력해보세요!
print(df.query("A < 0.5" and "B > 0.3"))실행 결과
Masking & query
A B
0 0.385740 0.313716
1 0.346635 0.461108
2 0.565224 0.937440
3 0.878549 0.139105
4 0.662327 0.309578
A B
0 0.385740 0.313716
1 0.346635 0.461108
A B
0 0.385740 0.313716
1 0.346635 0.461108[실습 4] 새로운 컬럼 추가하기
문제
국가별 GDP시리즈 데이터와국가별 인구시리즈 데이터를 이용해 만든country데이터프레임이 준비되어 있습니다. 1인당 GDP 를 나타내는 새로운 컬럼인gdp per capita를 데이터 프레임에 추가해봅시다.
1.country의 두 컬럼을 이용하여 새로운 컬럼을 만들고자 합니다. 1인당 GDP 를 나타내는 새로운 컬럼인gdp per capita를 데이터 프레임에 추가해보세요.
1인당 GDP는gdp를population으로 나누어 얻을 수 있습니다.
2. 완성한 데이터 프레임을 출력해보세요!import numpy as np import pandas as pd
GDP와 인구수 시리즈 값이 들어간 데이터프레임을 생성합니다.
population = pd.Series({'korea': 5180,'japan': 12718,'china': 141500,'usa': 32676})
gdp = pd.Series({'korea': 169320000,'japan': 516700000,'china': 1409250000,'usa': 2041280000})
print("Country DataFrame")
country = pd.DataFrame({"population" : population,"gdp" : gdp})
print(country)
## code
```python
# 데이터프레임에 gdp per capita 칼럼을 추가하고 출력합니다.
gdp_per_capita = country['gdp'] / country['population']
country['gdp per capita'] = gdp_per_capita
print(country)실행 결과
Country DataFrame
population gdp
korea 5180 169320000
japan 12718 516700000
china 141500 1409250000
usa 32676 2041280000
population gdp gdp per capita
korea 5180 169320000 32687.258687
japan 12718 516700000 40627.457147
china 141500 1409250000 9959.363958
usa 32676 2041280000 62470.314604