이번 글에서는 빅데이터 처리를 위한 아키텍처에 어떤 것이 있는지, 그리고 그 중 Master-Slave, Layered 아키텍처에 대해 알아보도록 하겠다. 그리고 Hadoop 1.0과 2.0에 대해서도 알아보자.
Distributed Architecture Style
아키텍처 스타일, 또는 아키텍처 패턴은 널리 사용되는 시스템 구성 방법이다. 분산 시스템을 설계할 때는 성능, 보안, 신뢰성 및 시스템의 관리를 고려하여 적절한 아키텍쳐 스타일을 선택해야 한다.
아키텍처 스타일에는 여러 종류가 있다.
📌 Modifiable ASs
- Hierarchical
- Virtual Machine
- Micro kernel
- Layered
- Plug-in
📌 Distributed ASs
- Distributed
- Vertical Distribution
- Client-server
- Multi-Tier
- Broker (Proxy)
- Horizontal Distribution
- Dispatcher (Load Balancer)
- Master-Slave
- P2P
- Vertical Distribution
이 Architecture Style들 중 Master-Slave 아키텍처와 Layered 아키텍처에 대해 더 알아보자.
Master-Slave Architecture
정의
실시간 시스템에서 많이 사용되는 아키텍쳐로, 서로 다른 프로세서에서 실행되는 복수 개의 프로세스들로 구성되어 있다. Fault Tolerance와 system reliabiliy를 지원하는 아키텍처 스타일이다.
구조
📌 Slave
Slave는 Master에게 다음을 제공한다.
- replicated services
- the same functional task by different algorithms and methods, or a totally different functionality.
📌 Master
Master는 다음과 같은 일을 수행한다.
- configure the invocations of the replicated services
- 모든 slave들로부터 결과값을 받는다.
- Certain selection strategy를 통해 slave들 중 특정 결과를 고른다.
특징
📌 안정성이 필수인 소프트웨어 시스템에서 주로 쓰인다.
서버의 복제 때문이다.
📌 병렬 컴퓨팅과 연산의 정확성
모든 slave들은 병렬로 실행될 수 있다.
동일한 작업이 여러 다른 실행들에게 위임됨에 따라, 부정확한 결과들은 쉽게 배제될 수 있다 → By a majority vote strategy or other algorithms
Layered Architecture
정의
계층적인 구조로, 몇몇의 높은 레이어들과 낮은 레이어들로 구성되어 있다.
- 각 레이어는 관련된 클래스들의 집합으로 이루어져있다.
- 각 레이어는 각자의 책임을 갖는다.
- 각 레이어는 추상화를 형성한다.
- 각 레이어는 독립적이라서, 한 레이어에서의 변경이 다른 레이어의 요소들에 영향을 미치지 않는다.
구조
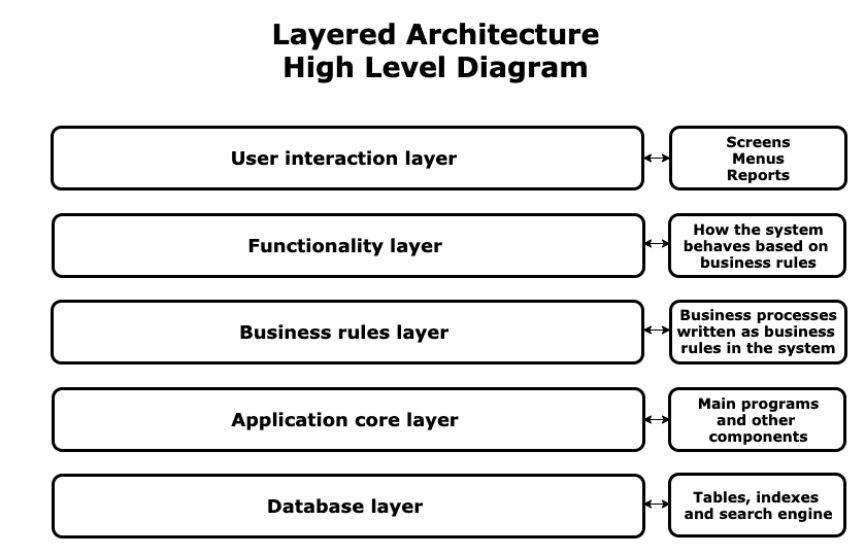
- (i+1)번째 레이어에게 요청이 들어오면 i번째 레이어의 인터페이스에서 제공되는 서비스를 호출한다.
- 각 레이어의 인터페이스는 현재 레이어의 모든 디테일한 서비스 implementation들과 하위의 인터페이스들을 모두 캡슐화한다.
- 상위 레이어에서 하위 레이어로의 요청은 메서드 호출을 통해 생성되고, 응답은 메서드 리턴을 통해 다시 상위 레이어로 전달된다.
특징
- 추상화 수준 증가에 기반한 소프트웨어 개발 증가
- 상위 레이어에서 하위 레이어의 향상된 독립성으로, 하위 레이어의 서비스에 변경이 발생해도 인터페이스만 변경되지 않는다면 상위 레이어는 영향이 없다.
- 향상된 유연성
- standard interface와 이에 대한 실행의 분리로 재사용성과 호환성 향상
Solution: Layered Architecture
- Fast Processing → Parallel Processing
- Unreliable Cheep PCs → Fault Tolerant Distributed System
- Big data in Unreliable Cheep Distributed Storage → Fault Tolerant Distributed Storage & Single File System for Easy to Handle
Hadoop 1.0 Architecture
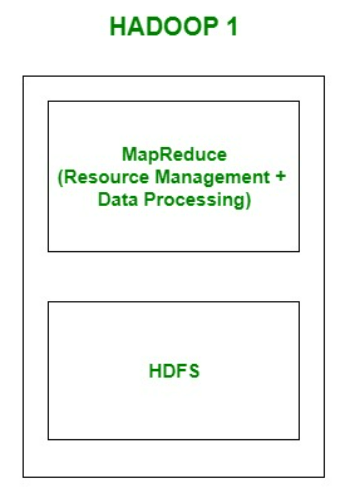
위 Solution 중 Parallel Processing과 Fault Tolerant Distributed System은 Hadoop 내의 MapReduce 안에 포함되어 있지만, 하위의 HDFS는 Distributed File System이다.
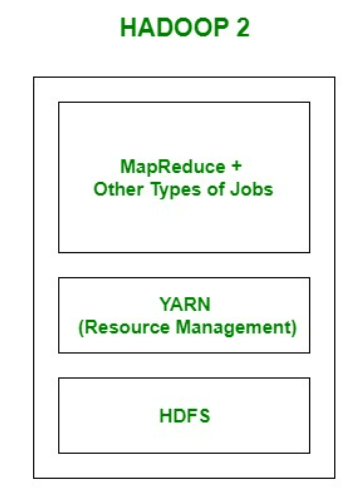
Hadoop 2.0 Architecture
 이미지 출처
이미지 출처
위 Solution 중 첫번째는 MapReduce에서, 두번째는 YARN에서 포함하고 있고 마지막 세번째는 HDFS에서 포함하고 있다. Hadoop 2.0에서는 MapReduce 내의 Resource Management를 YARN으로 분리시켰다. YARN을 사용함으로써 재사용이 가능하며 확장가능성도 증가하였다.
Hadoop 1.0 vs Hadoop 2.0
1. Component
Hadoop 1.0에서는 MapReduce와 HDFS를 가지지만, Hadoop 2.0에서는 HDFS와 MapReduce ver.2와 YARN으로 구성되어있다.
2. Daemons

💡 용어 정리
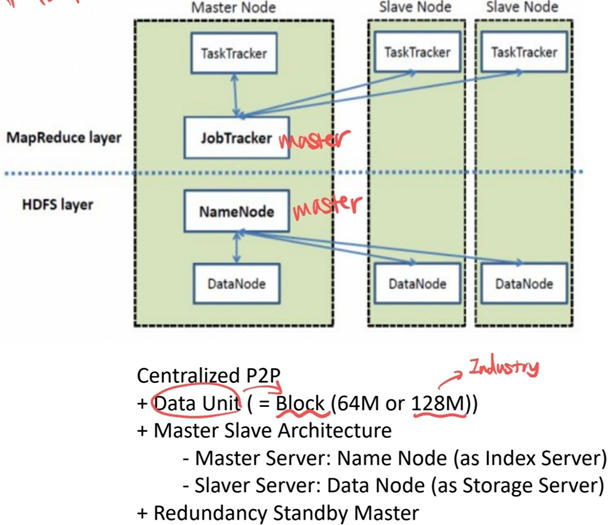
- NameNode: 데이터 블럭이 어느 DataNode에 있는지 관리하고 분산 파일 시스템의 전반적인 상태를 알고 있다. Master에 속한다.
- Secondary NameNode: HDFS의 상태를 모니터링하는 보조 성격을 가진 데몬으로, 주기적으로 HDFS의 메타데이터의 스냅샷을 찍으며 이 스냅샷은 시스템의 복구를 위해 사용된다.
- DataNode: 파일 블럭을 저장하고 제공하고 NameNode에게 자신의 정보를 전달한다. Slave에 속한다.
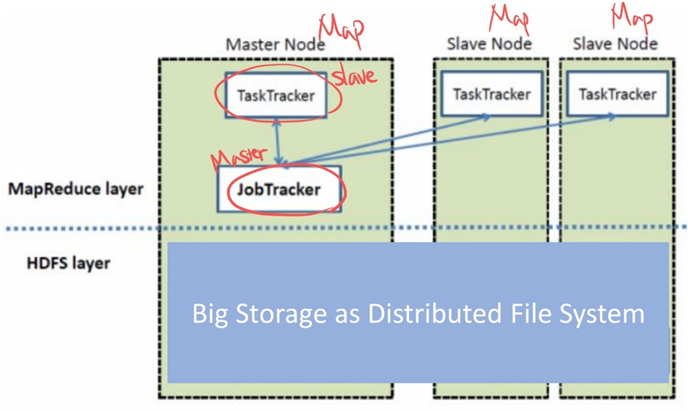
- JobTracker: 일반적으로 NameNode에서 실행시키는 하나의 프로세스로, 사용자 애플리케이션을 관리한다. TaskTracker의 할당과 모니터링을 하는데, 만약 어느 노드에서 TaskTracker가 실패하면 다른 TaskTracker에 재할당한다. Master에 속한다.
- TaskTracker: 실제로 Task를 처리하는 프로세스로 연산작업을 실행한다. DataNode에는 하나의 TaskTracker만 존재하며 여러 개의 Map과 REduce를 실행한다. Slave에 속한다.
클라이언트가 HDFS 파일에 대한 작업을 요청하면 JobTracker는 해당 데이터 블럭을 가지고 있는 노드에게 작업을 요청한다. 데이터 블럭에 대한 정보는 NameNode가 가지고 있다. 그러면 TaskTracker는 해당 파일에 대한 작업을 진행하고 JobTracker에게 메세지를 전달하면서 파일에 대한 변경사항은 DataNode와 통신한다. DataNode는 다시 NameNode에게 파일 블럭에 대한 정보를 전달한다.
3. Working
- Hadoop 1.0
- HDFS used for storage
- Map Reduce which works as Resource Management as well as Data Processing.
MapReduce에 작업이 몰리면서, 성능에 영향을 줄 수 있다.
- Hadoop 2.0
- HDFS again used for storage
- YARN which works as Resource Management.
- 리소스들을 할당해주고 모든 것들이 잘 돌아가게끔 한다.
4. Limitations
Hadoop 1.0과 2.0 모두 Master-Slave Architecture이다.
- Hadoop 1.0
- Single master, multiple slaves
- Master에서 crash 발생 시 system halt. (single point of failure)
- Hadoop 2.0
- Multiple masters, multiple slaves
- 한 master에서 crush가 발생해도, 다른 standby master가 있기 때문에 시스템은 잘 돌아간다 → single point of failure 해결!
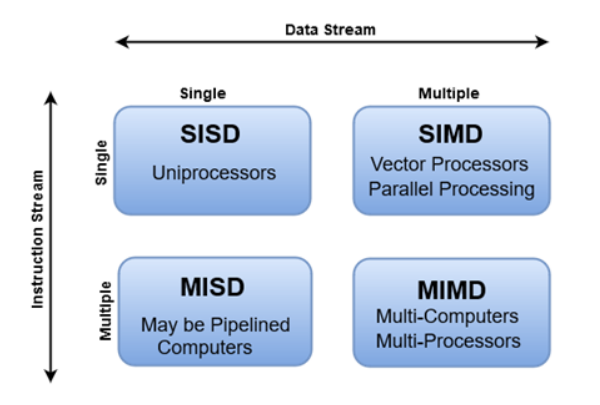
Flynn's Classification
병렬 프로세싱 아키텍처를 Instruction Stream과 Data Stream의 기준에 따라 4가지로 분류하였다.
 이미지 출처
이미지 출처
SISD (Single Instruction Single Data)
하나의 명령이 하나의 데이터 처리
- 직렬 컴퓨터 구조
- Deterministic execution
SIMD (Single Instruction Multiple Data)
하나의 명령이 다수의 데이터 처리
- 병렬 컴퓨터 구조
- Synchronous (lockstep) and deterministic execution
- 그래픽 혹은 이미지 프로세싱과 같이 높은 수준의 규칙성을 요구하는 특정 문제에 적합하다.
- GPU에서 사용하는 방식
MISD (Mulitple Instruction Single Data)
다수의 명령이 하나의 데이터 처리
- 각 프로세싱 유닛은 독립적으로 데이터를 기반으로 작동한다.
- 현실적으로 잘 사용하지 않는다.
MIMD (Multiple Instruction Multiple Data)
다수의 명령이 다수의 데이터 처리
- 멀티프로세서, networked parallel computer cluster and grids 등에 사용된다.
- 병렬 연산의 가장 일반적인 타입이다.
- SIMD식의 execution들을 포함하고 있다.
💡 병렬화의 레벨
- Program
- Process
- Task
- Thread
- Instruction
Sub Problem 1) Parallel Processing Architecture
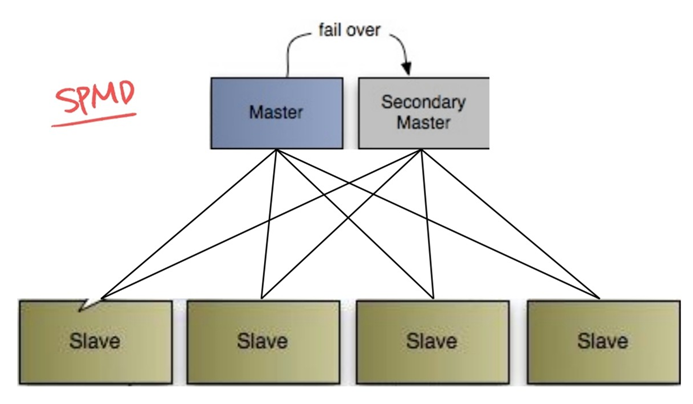
Solution) SPMD Master-Slave Architecture
💡 SPMD
Single Program Multiple Data
SPMD에는 Master-Slave 아키텍처가 적합하다. 따라서 SPMD를 적용한 Master-Slave 아키텍처는 다음과 같다. 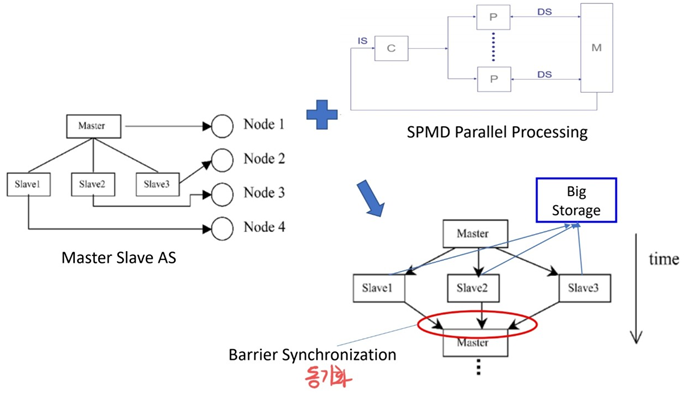
Hadoop MapReduce/HDFS Architecture
Sub Problem 2) Fault Tolerant Distributed System
Solution) Redundancy Standby Master
Redundant spare tactic에 기반한 Availability Patterns을 적용하여,
- Active redundancy (hot spare)
- Passive redundancy (warm spare)
- Spare (cold spare)
를 둔다.
Sub Problem 3) Distributed File System
Solution) Hadoop DFS Architecture