빅데이터란?
빅데이터는 우리 주변의 모든 것에 의해 항상 생성되고 있다.
모든 디지털 프로세스와 소셜 미디어 간의 교환에 의해 생성되고 있으며,
시스템, 센서, 모바일 디바이스들이 생성된 데이터들을 전송하고 있다.
 이미지 출처
이미지 출처
비즈니스 프로세스 내의 DB로 구성되어 있는 데이터의 생성 속도가 1배라고 한다면 그 이후 인간에 의해 문서, 이메일, 소셜미디어 등으로 데이터가 생성되는 속도는 10배이고, IoT 기기들이 데이터를 관리하기 시작하면서 센서, 비디오, M2M LOG FILES 등으로 데이터는 100배의 속도로 생성된다.
이렇게나 굉장히 빠른 속도로 생성되고 있는 상당한 규모의 데이터, 즉 빅데이터는 결코 한 컴퓨터에 담을 수 없다. 이러한 빅데이터는 3V라고도 불리는 세가지의 특징이 있다.
- Velocity: 데이터의 발생이 굉장히 빠르다.
→ Batch/Stream, Near-time/Real-time(데드라인有) 등 데이터 처리 관련 특성
1. Volume
빅데이터는 이름에서부터도 당연하게도, 생성된 데이터의 양이 상당히 크다. IBM Big data Hub의 2020년 자료에 따르면 다음과 같다.
- 2005년의 300배인 40ZB(Zettabyte)의 데이터가 2020년에 생성될 예정이다.
- 매일 2.5 Quintillion Bytes의 데이터가 생성된다.
- 60억 사람들이 핸드폰을 가지고 있다.
- 대부분의 회사가 가지고 있는 데이터의 크기는 최고 100TB이다.
이렇게 데이터는 항상 생성되고 있고 데이터의 양은 방대해지고 있다.
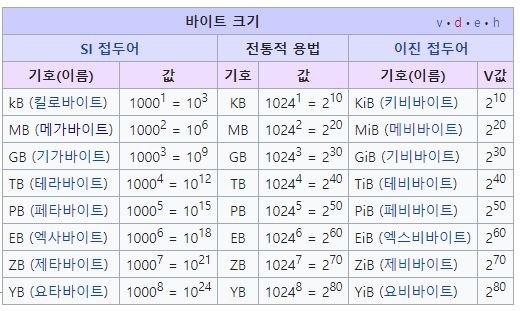
💡 Byte 단위
2. Variety
데이터들은 텍스트, 이미지, 오디오, 비디오, 소셜미디어 데이터 등 각자의 형식, 타입, 구조가 다양하다. 또한 한 어플리케이션에서 수집/생성하는 데이터들도 정적인 데이터와 동적인 데이터들로 구분되기도 한다.
IBM Big data Hub의 자료에 따르면 다음과 같다.
- 2011년 건강 관리에 대한 세계적인 데이터의 크기는 150 Exabyte로 추정된다.
- 매달 Facebook에서 300억 개의 컨텐츠가 공유되고 있다.
- 2014년에는 무선 웨어러블 건강 모니터 기기가 4억 2천만개가 있을 것으로 예상된다.
- 매일 트위터에서 4억 개의 트윗이 보내진다.
위처럼 생성되고 전송되는 데이터의 형식, 종류, 구조 등이 굉장히 다양하다.
3. Velocity
데이터는 빠르게 생성되고 있으므로 그에 대한 처리 또한 빨라져야한다. 데이터에 대한 처리 및 결정이 늦어진다면 이는 해당 데이터를 처리하고 인사이트를 발견할 기회를 놓친 것이다.
IBM Big data Hub의 자료에 따르면 다음과 같다.
- New York Stock Exchange에서는 매 무역 세션에 1TB의 무역 정보를 처리한다.
- 2016년 약 200억의 네트워크 연결이 계획될 것이라 예측했다.
- 현재 자동차들은 연료 혹은 타이어 압력 등을 모니터링하기 위한 100개에 가까운 센서를 달고 있다.
전통적 데이터와 빅데이터 간의 비교
| 전통적 데이터 | 빅데이터 | |
|---|---|---|
| Volume | GB | 지속적으로 업데이트중 (TB or PB or More) |
| 생성율 | 한시간, 혹은 하루 등 | 전통적 데이터보다 더욱 빠르게 |
| Structured | Structured | Semi-structured or un-structured |
| Data Source | 중앙집중화 | 완전분산화 |
| 데이터 통합 | 완전 쉬움 | 어려움 |
| 데이터 저장 | RDBMS | HDFS, NoSQL |
| 접근 | Interactive | Batch or near/real-time |
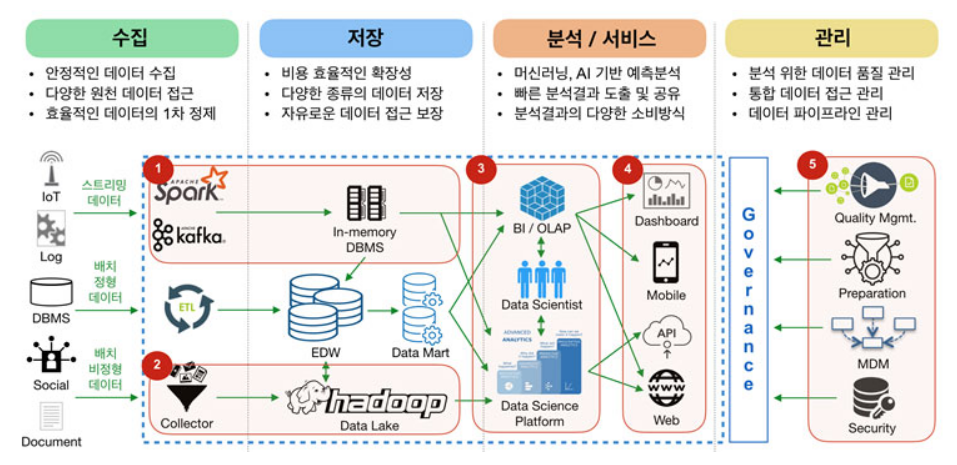
빅데이터 프로세싱
기업의 입장에서, 데이터 수집은 그리 어려운 일이 아니다.
하지만 수집된 빅데이터를 시기적절하고 확장가능한 방식으로 어떻게 관리, 분석, 요약, 시각화하고 그 안에서의 인사이트를 발견할 것인가가 더욱 중요하다.
그에 대한 빅데이터 프로세싱 파이프라인은 다음과 같다.
1. 수집
2. 저장
3. 분석 및 변환
4. 모델링 및 추론
5. 예측, 추천, 시각화
 이미지 출처
이미지 출처
참고)
학교 전공 자료
