네이버에서 해당 요소만 가져오기

1) requests 라이브러리 임포트
import requests as req2) 네이버 웹페이지 정보를 요청
res = req.get('http://naver.com')2) 네이버 html 가져오기
res.text3) 결과 형식을 변형하기 위한 BeautifulSoup 라이브러리 임포트
from bs4 import BeautifulSoup as bs4) html 형식으로 변환
soup = bs(res.text, 'lxml')5) 해당 요소 검색
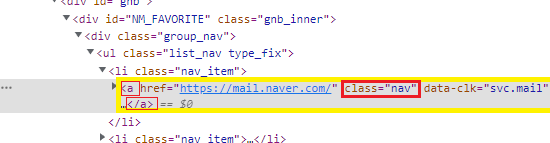
6) 해당 요소 가져오기
txt = soup.select('a.nav')7) 해당 요소의 컨텐츠 가져오기 (인덱싱)
for i in txt:
print(i.text)
멜론에서 TOP100 가져오기
1. 데이터 준비단계
1) requests 라이브러리 임포트
import requests as req2) User-Agent 정보 가져오기
h = {"User-Agent": "Mozilla/5.0..."}3) 멜론차트 웹페이지 정보를 요청
res = req.get('https://www.melon.com/chart/', headers = h)4) 멜론차트 html 가져오기
res.text5) 결과 형식을 변형하기 위한 BeautifulSoup 라이브러리 임포트
from bs4 import BeautifulSoup as bs6) html 형식으로 변환
soup = bs(res.text, 'lxml')2. 데이터 수집단계
(1) 내가 수집하고자 하는 요소가 구분(id.class) 없는 경우에는
그 요소를 포함하고 있는 바로 위의 부모요소로 접근
(2) 부모요소 또한 구분자가 없는 경우에는 구분자가 있는 부모까지 검사
(3) 클래스값 중간에 공백이 있는경우 -> 공백을 자손으로 인식하기 때문에 문제발생
공백을 .으로 바꾼다.1) 해당 요소 검색

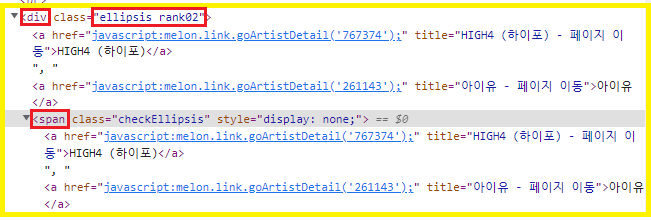
2) 해당 요소 가져오기
노래제목
song = soup.select('div.ellipsis.rank01 >span >a')
노래가수
singer = soup.select('div.ellipsis.rank02 >span')3) 해당 요소의 컨텐츠 가져오기 (인덱싱)
데이터 정제
(1) 순수한 글자정보만 추출해서 저장
(2) 순수한 글자정보만 저장시킬 리스트 생성
songList = []
singerList = []
rankList = []
둘다 100개이고 index가 0~99이기 때문에 인덱스 활용
for i in range(len(singer)):
songList.append(song[i].text)
singerList.append(singer[i].text)
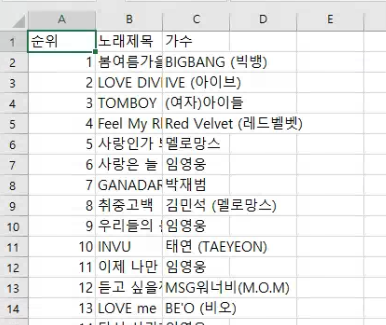
rankList.append(i+1)3. 데이터 활용단계
1) 수집한 데이터로 데이터프레임 제작
import pandas as pd
dic = {'제목': songList, '가수':singerList, '순위':rankList}
melon = pd.DataFrame(dic)2) 데이터프레임의 index 변경
melon.set_index('순위', inplace=True)3) 해당 데이터프레임을 csv형식의 파일로 저장
melon.to_csv('멜론차트.csv', encoding="euc-kr")
한글이 깨지기 때문에 encoding 필수!
1. euc-kr
2. utf-8
3. ""
4. utf-i-sig