requests 라이브러리
requests : 서버에게 데이터를 요청해 응답받기 위한 라이브러리
- 요청하고 응답받으면 역할이 끝난다.
- 브라우저 역할을 대신한다.
import requests as req.get() 함수
.get('url') : 페이지 정보를 알아오는 함수
req.get('http://www.naver.com')
#<Response [200]>
응답코드
Response[200] : 데이터 통신 성공
Response[400] : 클라이언트(요청) 에러코드
Response[500] : 서버(응답) 에러코드
Response[406]
브라우저가 아닌 코드라고 인식하여 접근이 불가능할 때 발생하는 에러코드
브라우저인척 속이는 작업 필수!
req.get('http://www.melon.com')
해당 페이지에서 개발자도구(F12)에서 확인가능하다
User Agent부분을 복사하여딕셔너리로 활용한다.
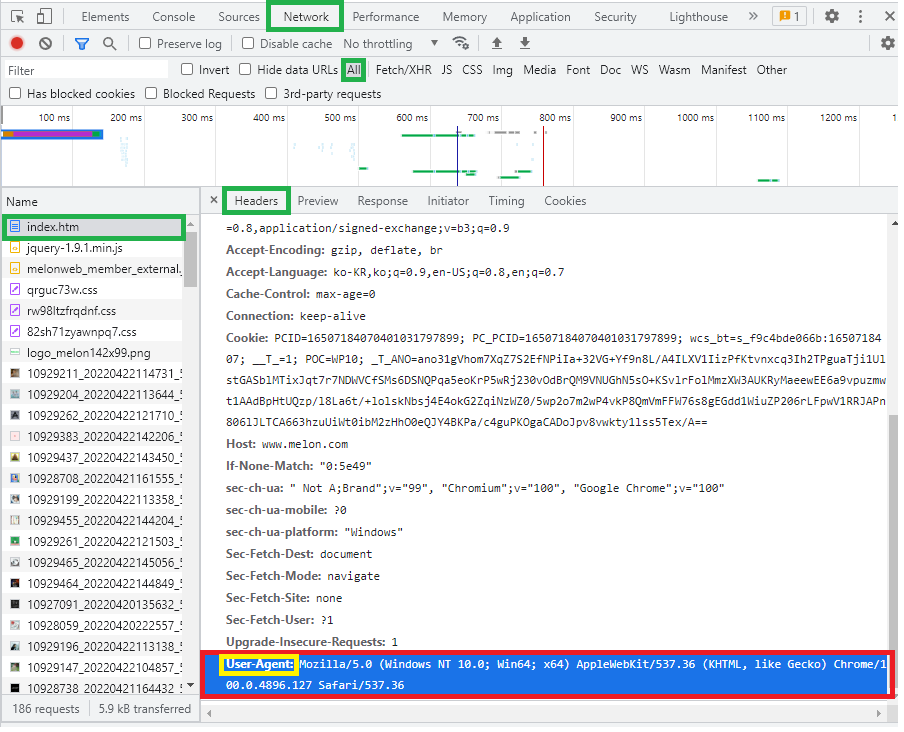
h = {"key":"value"}h = {"User-Agent": "Mozilla/5.0..."}
req.get('http://www.melon.com', headers = h}
#<Response [200]>.text 기능
.text : 응답객체 response안에서 html코드만 추출
String형태로 반환
res = req.get('http://www.naver.com')
res.text()
BeautifulSoup 라이브러리
BeautifulSoup : 컴퓨터가 이해할 수 있는 html 언어로 변경
from bs4 import BeautifulSoup as bs
# bs4 폴더 안에서 꺼내온 BeautifulSoup 라이브러리를 bs라는 이름으로 사용bs 객체화
bs : .text로 얻어온 String형식을 가진 html 정보를 html 언어로 변형
html형태로 반환
bs(res.text, 'html')
.select() 함수
.select('선택자') : 필요한 요소를 검색해서 수집하는 명령어
.select_one('선택자') : 반환받은 리스트 데이터 중 첫번째 데이터만 수집
리스트형태로 반환
soup = bs(res.text, 'html')
soup.select('a.nav')
#<a>태그를 가진 요소중 클래스 이름이 nav인 요소를 수집
