iframe
- ifame 을 통해 다른 사이트에서 따로 정보를 불러와 쓰기때문에 데이터 접근이 불가능하다
res = req.get('https://movie.naver.com/movie/bi/mi/point.naver?code=45290')
soup = bs(res.text, 'lxml')
soup.select('div.score_reple > p > span')
- 접근이 불가능하기때문에
.select의 결과가 비어있다.- 이때 개발자도구
F12에서Ctrl+F를 사용해서iframe을 검색해src를 찾아낸다.
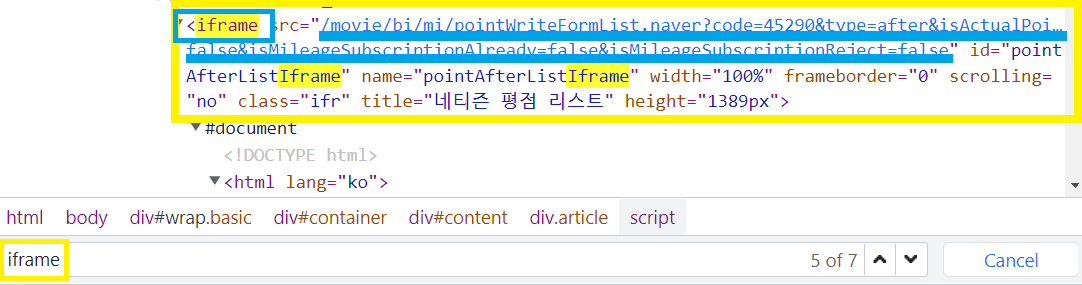
주의: 전체 url을 채워줘야함
https://movie.naver.com/movie/bi/mi/pointWriteFormList.naver?code=45290&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false로 요청
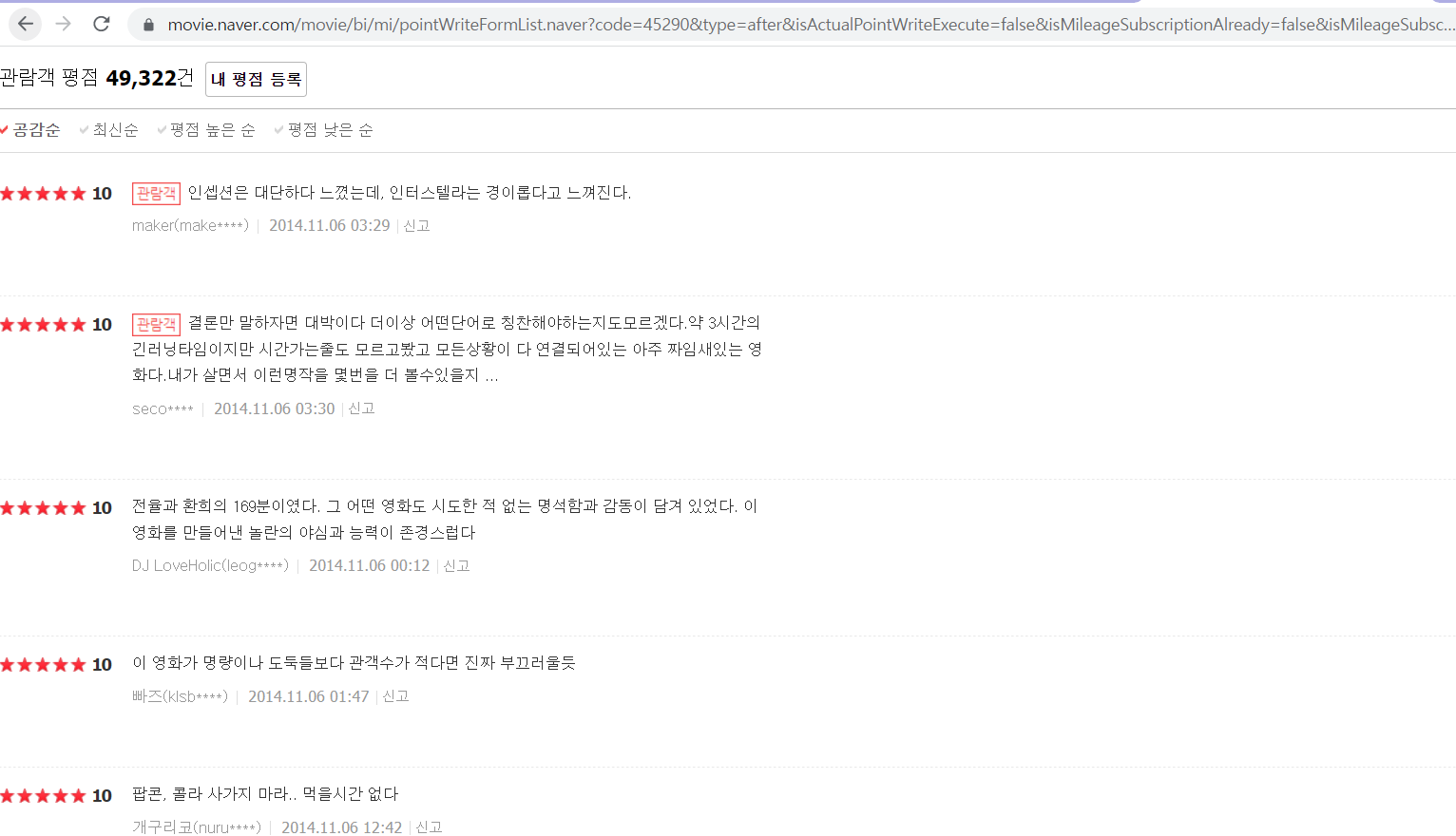
- 네이버 영화 평점들은 위의 사이트에서 가져오고 있는 것이다!
#1. 데이터 준비
1) 라이브러리 임포트
import requests as req
from bs4 import BeautifulSoup as bs2) 웹페이지 정보 요청
res = req.get('https://movie.naver.com/movie/bi/mi/pointWriteFormList.naver?code=45290&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false')3) html 형식으로 변환
soup = bs(res.text, 'lxml')#2. 데이터 수집
1) 요소 선택
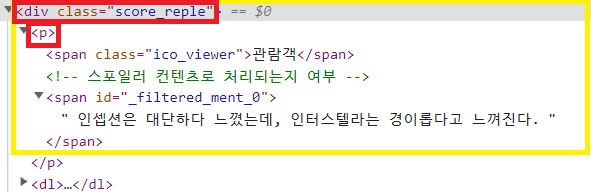
div.score_reple > p > span._filtered_men_0
id선택자는 여러 요소를 선택하기에는 부적절하다.
div.score_reple > p > span:nth=chile(2)선택자를 정확하게 쓰는 방법이 가장 좋지만,
span이 하나밖에 없는 요소도 있다면?
그래서 위와 같은 선택자로는 안된다.
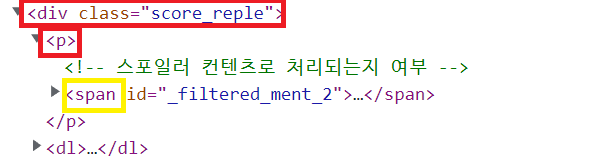
soup.select('div.score_reple > p')문제점: 관람객까지 함께 나온다
해결방법: 관람객 요소만 추출해서 지우자

(1) '관람객' 요소 선택
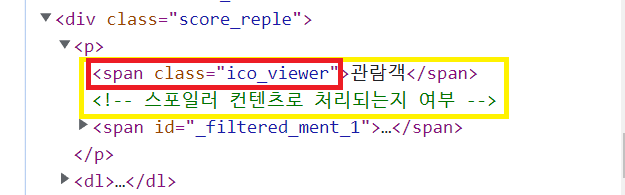
viewer = soup.select('span.ico_viewer')(2) '관람객' 요소 추출해서 삭제하기
extract(): 추출하다
for i in viewer:
i.extract()2) '관람객' 요소가 삭제된 해당 요소 선택 후 추출
review = soup.select('div.score_reple > p')
for i in review:
print(i.text)
개행이 많다...그래서 개행 삭제!!
3) 데이터 정제
.strip(): 개행(공백)문자 삭제
for i in review:
print(i.text.strip())
3. 1페이지부터 10페이지까지의 리뷰 수집

- 페이지 수가 넘어갈때마다
url맨 뒤의 숫자가 바뀐다. - 이 숫자를 이용해 반복문으로 1~10페이지의 리뷰를 수집해보자
for i in range(1,101):
res = req.get('https://movie.naver.com/movie/bi/mi/pointWriteFormList.naver?code=45290&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false&page=' + str(i))
soup = bs(res.text, 'lxml')
viewer = soup.select('span.ico_viewer')
for i in viewer:
i.extract()
review = soup.select("div.score_reple > p")
for i in review:
print(i.text.strip())
