[ 논문분석 ] Self- supervised autoregressive domain adaptation for time series data (IEEE 2022)
[ 논문 분석 ]
키워드 용어 : Self-supervised learning, autoregressive domain adaptation, ensemble teacher learning, time series data
[Introduction]
- 시계열 데이터는 의료 서비스, 스마트 제조 등 다양한 실제 응용 분야에서 중요한 문제임.
- 딥러닝 기반 접근법은 항상 훈련 데이터(즉, 소스 도메인)과 테스트 데이터(즉, 타겟 도메인)가 동일한 분포에서 추출된다고 가정함.
- 하지만 실제 응용에서는 동적인 환경에서 이러한 가정이 성립하지 않을 수 있으며, 이는 domain shift 문제를 발생시킴
- 시계열 데이터의 domain shift 문제를 해결하기 위해 Self-supervised Learning 기법과 Autoregressive Domain Adaptation 기법을 도입한 SLARDA(Self-supervised Autoregressive Domain Adaptation) 프레임워크를 제안
- 1) Self-supervised Learning을 통해 소스 도메인의 특성 학습향상
- 2) 시간적 의존성을 고려하여 도메인 간의 특성 정렬을 수행하는 Autoregressive Domain Discriminator 도입
- 3) 마지막으로, 신뢰도 있는 가상 레이블을 이용해 클래스별 정렬을 수행하는 Ensemble Teacher 모델 제안
- 시간적 정보 없이 global feature을 정렬해 시계열 데이터의 특성을 충분히 반영하지 못한 기존 연구를 보완
- 목표 설정: 라벨링이 되어 있지 않은 타겟 샘플의 라벨을 잘 예측하는 예측 모델을 만드는 것
[Related Works]
Background Overview on Unsupervised Domain Adaptation (UDA)
- Unsupervised Domain Adaptation (UDA) 개요
- 목적: Unsupervised Domain Adaptation(UDA)는 레이블링된 소스 도메인과 레이블링되지 않은 타겟 도메인 간의 domain shift 문제를 해결하기 위해 고안됨.
- 활용: 주로 이미지 데이터에서 도메인 이동 문제를 완화하기 위해 사용되며, 광범위한 데이터 라벨링을 피하면서 라벨이 지정된 데이터셋(소스 도메인)의 지식을 라벨이 없는 타겟 도메인으로 전이
- 주요 패러다임
1) 차이 기반 방법(Discrepancy-based Methods) vs 2) 적대적 학습 기반 방법(Adversarial Learning-based Methods)
-
1) Discrepancy-based Methods
- 목적: 통계적 거리를 최소화하여 소스와 타겟 도메인의 분포를 정렬.
- 주요 방법:
- Maximum Mean Discrepancy (MMD): 분포 모멘트의 가중합을 통해 두 도메인 간의 불변 특징을 찾음.두 분포의 모든 모멘트가 일치하는지 확인
- 고차원 MMD: 소스와 타겟 도메인 간의 고차원 모멘트를 맞춤.
모멘트를 고차원 공간에서 맞추는 것으로, 분포 간의 미세한 차이까지 고려하여 보다 정밀하게 두 도메인을 정렬 - 상관관계 정렬: 2차 통계( 분산( 퍼짐 정도 )과 공분산(변수 간의 상관 관계 ) )을 맞추어 domain shift 문제 완화.
- Central Moment Discrepancy (CMD): 고차원 중앙 모멘트( high-order central moments )를 정렬하여 전이 가능한 특징을 획득.
- 모멘트란 ? : 확률 분포의 특성을 수치적으로 요약하는 통계적 개념임. 분포의 중심 위치, 퍼짐 정도, 비대칭성, 뾰족함 등을 설명하는 데 사용함. ( 1차 모멘트 : 평균 및 기대값 / 2차 모멘트 : 분산 / 3차 모멘트 : 왜도(분포의 비대칭성) / 4차 모멘트 : 첨도( 분포의 뾰족함 ) )
-
2) Adversarial Learning-based Methods
- 목적: 생성적 적대 신경망(GAN)의 아이디어에 영감을 받아, 소스와 타겟 도메인의 불변 특징을 생성.
- 주요 방법:
- 역방향 그래디언트 레이어: 도메인 분류기와 특징 추출기를 적대적으로 훈련.
- ADDA (Adversarial Discriminative Domain Adaptation): 소스와 타겟 네트워크를 분리하고, GAN 기반 반전 레이블 손실사용.
- Wasserstein 거리 기반 표현 학습(WDGRL): GAN 기반 목표의 안정성 문제를 해결하기 위해 Wasserstein 거리를 활용.
- 조건부 적대적 도메인 적응(CDAN): 도메인 정렬 단계에서 task-knowledge를 feature와 결합.
- DIRT: 가상 적대적 학습과 조건부 엔트로피를 사용하여 소스와 타겟 도메인 정렬
- Domain Adaptation for Time Series Data
- 시계열에서 Domain invariant한 특징을 탐색하려는 다른 연구들:
- variational recurrent auto-encoder 사용: 특징을 추출하고, adversarial training을 통해 소스와 타겟 도메인을 정렬.
- multi-source 도메인 활용: 여러 소스 도메인으로부터의 정보를 활용하여 라벨이 없는 타겟 도메인에서 성능 향상.
- 문제점:
- 시간적 차원 무시: 대부분의 기존 시계열 domain adaptation 방법은 시간적 차원을 무시, 도메인 분류기가 쉽게 속아 정렬 상태에 도달하지 못할 수 있음.
- 세밀한 클래스 분포 무시: 기존 방법들은 도메인 간의 global한 분포만을 정렬, 세밀한 클래스 분포를 고려하지 않음.
- 우리의 접근법
feature learning 과 domain alignment 단계 모두에서 시간적 종속성을 명시적으로 고려해보자
[Motivation]
- 기존의 UDA 방법들은 주로 시각적 데이터에 대해 개발되었으며 시간적 의존성을 가지는 시계열 데이터에 적용하기에 적합하지 않음
- 기존 방법의 한계를 극복하기 위해 새로운 접근 필요
- 기존 방식 :
- 1) 대규모 데이터셋(예: ImageNet)에 의존하여 소스 도메인에서 사전 학습을 진행 => 시계열 데이터에는 적용할 수 없음
- 2) 도메인 정렬 단계 시 feature space 내 소스 도메인과 타겟 도메인의 시간적 종속성 무시
- 3) 대부분의 이전 UDA 방법은 타겟 도메인의 세밀한 클래스 분포를 고려하지 않고 전반적인 특징만을 정렬
[Contribution]
-
Self-supervised Pretraining: contrastive predictive loss를 사용하여 소스 도메인에서의 특징 학습과 학습 전이력 향상
-
Autoregressive Domain Adaptation: 시간적 의존성을 고려하여 도메인 간의 특징 추출 및 정렬 성능을 향상시킴
-
Class-conditional Alignment: ensemble teacher 모델을 사용하여 신뢰할 수 있는 pseudo 라벨을 생성하고, 클래스 간 분포 차이(class-conditional shift)를 줄임
[Proposed Method]
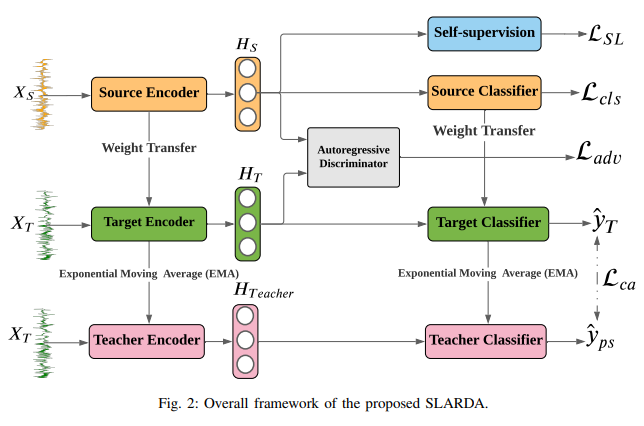
[Overview of SLARDA]
- SLARDA 프레임워크는 크게 세 가지 주요 구성 요소로 구성
- (1) 소스 도메인 특성 학습을 개선하기 위한 Self-supervised Pretraining 모듈
- (2) 시간적 의존성을 고려한 Autoregressive Discriminator 모델
- (3) 클래스 조건적 정렬을 수행하는 Teacher 모델
- 그림으로 확인
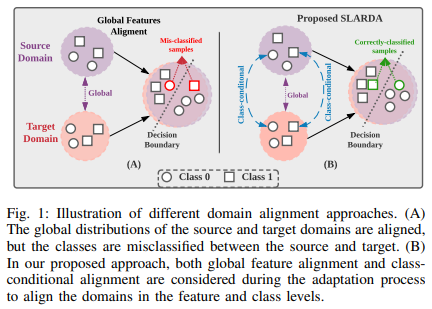
- (A)는 소스와 타겟 도메인 간의 전반적인 분포를 정렬하지만, 각 클래스 간의 일치가 부족하여 잘못된 분류가 발생가능
- 반면에 (B)는 제안된 방법으로, 도메인 적응 과정에서 전반적인 분포 정렬뿐만 아니라 클래스별 세밀한 정렬도 수행
- 제안된 방법에서는 글로벌 특징 정렬 + 클래스별 정렬을 통해 소스와 타겟 도메인 간의 세밀한 클래스 분포를 맞추어 오분류 줄이는 데 도움
- 전체적인 모델 아키텍쳐:
(1) feature extractor model + (2) Autoregressive discriminator model
-
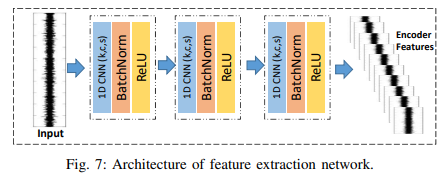
(1) feature extractor
- 1D-CNN architecture 사용
-
(2) Autoregressive discriminator
- Autoregressive Network (fAR,소스와 타겟 특징 모두에서 시간적 의존성을 벡터 표현으로 인코딩) + 이진 분류 네트워크(fD, 소스와 타겟 특징을 구별)
- 트랜스포머 모델을 사용하여 소스와 타겟 도메인 모두에서 시간 단계 간의 시간적 의존성을 모델링. self-attention을 사용
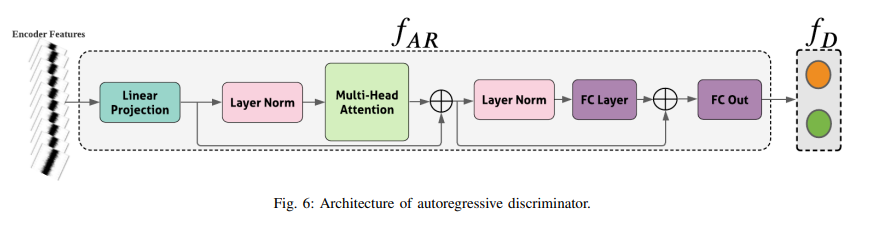
-
(3) Autoregressive Network (Pretraining)
- 사전 학습 단계에서 GRU를 활용해서 잠재 특징을 요약하고 컨텍스트 벡터를 생성하는 데 사용
- 제안한 FrameWork
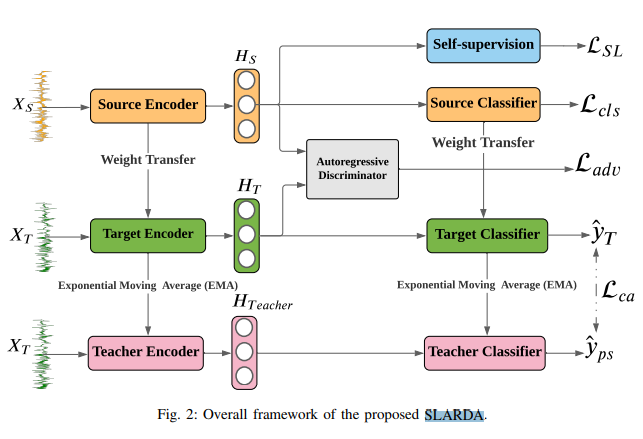
- Self-supervised Learning for Source Pretraining
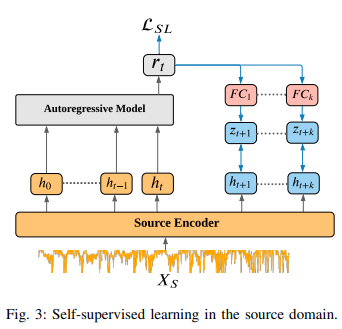
- (1-1) 1D-CNN 인코더로부터 출력되는 H≤t = {h0, . . . , ht} 라는 latent features가 context vector rt를 얻기 위해 Autoregressive model로 들어감
- (1-2) Fully connected layer를 통과해 미래의 latent feature인 zt+k를 예측함
- (1-3) 아래 그림의 좌측은 bi-linear model을 뜻함
- bi-linear model : 두 개의 입력 변수 간의 상호작용을 모델링하기 위해 각 입력에 대해 선형 변환을 적용하고, 이를 결합하여 결과를 생성 y=xT*Wx2
- 인코더 모델과 autoregressive model과 log bilinear model을 대조 목적 함수를 통해 공동으로 최적화 하여 예측한 zt+k과 진짜 미래 latent feature 인 ht+k의 similarity를 최대화 함
- 훈련 과정에서 실제 잠재 특징이 변화할 때, 예측된 벡터도 이에 맞춰 변동하여 이들 간의 관계를 유지하고 훈련 과정을 안정화 함.
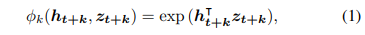
- 훈련 과정에서 실제 잠재 특징이 변화할 때, 예측된 벡터도 이에 맞춰 변동하여 이들 간의 관계를 유지하고 훈련 과정을 안정화 함.
- (2) 미래 시간 단계를 예측하는 보조 작업을 통해 self-supervised learning 수행
- 이 문제를 긍정 샘플과 부정 샘플 간의 이진 분류 문제로 설정
- 동일한 샘플의 미래 잠재 특징은 긍정 쌍으로 간주, 미니 배치 내의 다른 모든 샘플의 미래 잠재 특징은 부정 쌍으로 간주
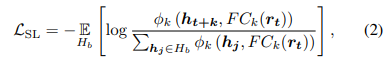
- 공식에서 Hb는 샘플들의 미니배치를 의미함
- (3) self-supervised loss를 설계해서 소스 도메인 데이터에서 소스 인코더 𝐸𝑆 최적화
- 라벨이 있는 소스 도메인 데이터를 이용해 cross-entropy loss를 통해 인코더 모델 𝐸𝑆가 주요 분류 작업에서 좋은 성능을 내도록 훈련
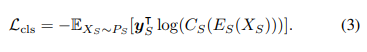
- (4) 소스 인코더 𝐸𝑆를 self-supervised 작업과 supervised 목표를 함께 사용하여 전이 가능한 특징을 생성하도록 공동으로 훈련함
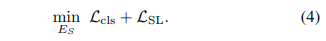
- feature extractor model 요약 :
- 소스 도메인에서 contrastive predictive loss를 사용하여 특징 학습
- 1D-CNN 인코더와 Autoregressive Model을 사용하여 시계열 데이터의 시간적 의존성을 학습
- contrastive predictive loss을 통해 모델이 미래의 시간 스텝을 예측하도록 함
- Autoregressive Domain Adaptation
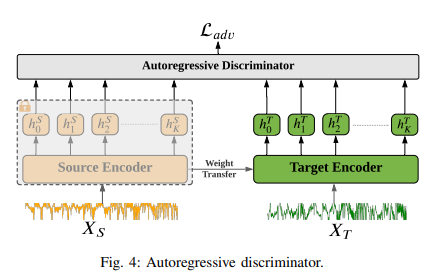
- autoregressive discriminator DAR를 사용하여 소스 및 타겟 도메인의 시간적 특징을 정렬
- DAR은 2개의 구성요소로 구성됨. autoregressive 네트워크 & 이진 분류 네트워크
- (1) autoregressive 네트워크
- fAR은 소스와 타겟 특징 모두에서 시간적 의존성을 벡터 표현으로 인코딩 함
- 아래 식의 우항은 순차적인 특징의 서로 다른 시간 단계 간의 조건부 분포를 나타냄(과거의 데이터가 주어졌을 때, 현재 또는 미래의 데이터가 어떻게 분포할지를 나타내는 확률적 관계)
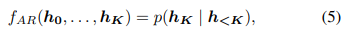
- (2) 이진 분류 네트워크
- fD는 요약된 특징 벡터에 적용되어 소스와 타겟 특징을 구별
- 소스와 타겟 특징을 구별하는 역할을 하며, 이를 통해 도메인 불변 특징을 학습
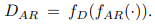
- 소스와 타겟 도메인 정렬 절차:
- self-supervised 로 사전 학습된 소스 모델을 고정하고, 그 가중치를 타겟 모델로 전이
- autoregressive 도메인 판별기를 적대적으로 훈련하여, 소스와 타겟 간의 구별이 어렵도록 만듬. 이 과정에서 도메인 불변 특징 생성
- 최적화 목표 :
-
autoregressive 판별기 DAR은 소스와 타겟 특징을 구별하도록 최적화
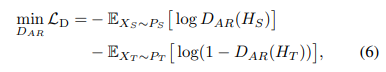
- 각각 소스와 타겟 특징의 시간적 출력은 아래로 표현
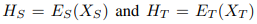
- 각각 소스와 타겟 특징의 시간적 출력은 아래로 표현
-
타겟 인코더 ET는 타겟 특징이 소스 특징과 유사하게 만들어 판별기를 혼란시키도록 훈련
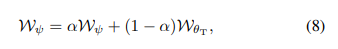
이런식으로 소스와 타겟 특징 간의 차이를 줄이고, 도메인 간의 차이를 최소화하여 도메인 불변 특징을 학습하는 것이 목표
- Class-conditional Alignment via Teacher Model
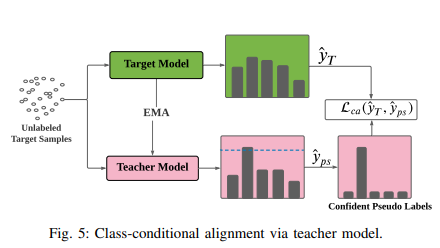
- Teacher Model은 Exponential Moving Average (EMA)를 통해 타겟 인코더의 가중치를 지속적으로 업데이트하며, 이를 통해 더 신뢰성 있는 가짜 레이블을 생성
- 생성된 가짜 레이블 중에서 신뢰할 수 있는 것만을 골라 학습에 사용, 이를 통해 타겟 도메인의 특징과 클래스 간의 분포를 정렬하여 도메인 적응 성능 향상
- Teacher Model:-
타겟 도메인에서 라벨이 없는 데이터에 대해 신뢰성 있는 가짜 레이블을 생성하는 역할
-
EMA(Exponential Moving Average)를 사용하여 Teacher Model의 가중치를 업데이트( 모멘텀 업데이트 방식 )
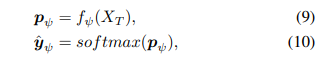
-
출력 예측값은 타겟 도메인의 데이터를 입력으로 받아 소프트맥스 함수를 통해 확률로 변환
- Confident Pseudo Labels
-
Teacher Model이 예측한 레이블을 더 정교하게 다듬기 위해, 사전에 정의된 신뢰 임계값(ζ) 이상인 레이블만 유지
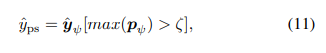
- 이러한 과정을 통해 신뢰할 수 있는 가짜 레이블을 얻음
- 신뢰도가 높은 라벨만을 사용하여 타겟 모델을 학습시키고, 소스 도메인과 타겟 도메인 간의 class-conditional distribution(클래스 조건부 분포)를 정렬
- Class-Conditional Alignment Loss
-
Class-Conditional Alignment Loss (클래스 조건부 정렬 손실) 𝐿𝑐𝑎는 타겟 분류기가 예측한 레이블과 신뢰할 수 있는 가짜 레이블 간의 cross entrophy loss로 정의
-
이 손실을 최소화함으로써, 타겟 모델이 class-conditional distribution(클래스 조건부 분포)를 정확하게 학습하도록 함
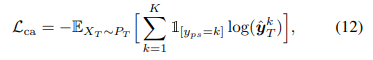

-
전체적인 알고리즘 정리

전체적인 목적 함수 정리
- autoregressive domain adaptation loss와 class-conditional alignment loss를 동시에 줄이는 방향으로 최적화가 이루어 짐.
- λ 는 class-conditional loss의 weight이다.
[EXPERIMENTS]
- 실험 설정: 소스 도메인의 라벨 데이터와 타겟 도메인의 라벨이 없는 데이터를 사용
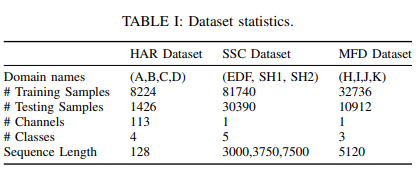
- 사용한 데이터: human activity recognition (HAR),
sleep stage classification (SSC), machine fault diagnosis(MFD).
- 모델 아키텍쳐:
- 평가 지표: 각 데이터셋의 도메인 간 정확도와 P-Value를 사용하여 성능 평가
[평가 결과]
-
비교 기법들 :DAN, WDGRL, Deep CORAL, MDDA, HoMM, DANN, CDAN, VADA
- 대부분의 최신 기법들은 이미지 관련 데이터셋에 맞춰 구현되었기 때문에, 이들 중 9개의 최신 기법들을 재구현
-
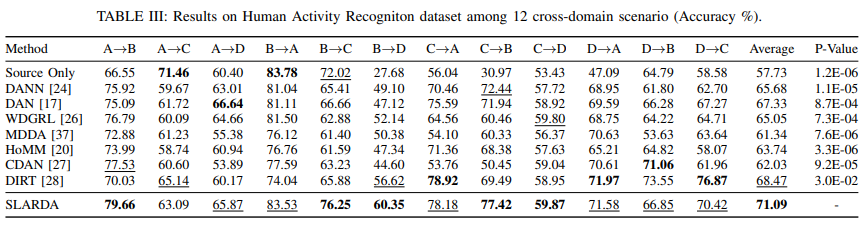
HAR 데이터셋 파트: A, B, C, D라는 4명의 피실험자로부터 수집된 데이터 즉 12개의 도메인 간 시나리오에서 평가. 평균 2.62% 성능 향상
- B→A 시나리오처럼 도메인 차이가 적을 때는 적응이 오히려 성능을 저하시킬 수 있다는 점 발견
-
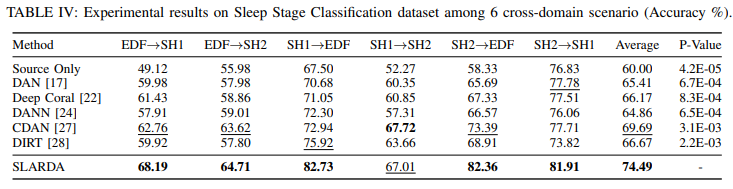
SSC 데이터셋 파트: 각각 100Hz, 125Hz, 250Hz의 샘플링 속도를 가진 EDF, SH1, SH2라는 세 개의 도메인을 포함한 6개의 도메인 간 시나리오에서 평가. 평균 5% 성능 향상
- EDF→SH1 및 EDF→SH2에서 최고의 성능을 보였고, SH1→SH2에서는 두 번째로 좋은 성능
- higher resolution 데이터셋에서 lower resolution 데이터셋으로의 매핑(i.e., SH2→SH1, SH2→EDF, SH1→EDF)에서 최고의 성능
- SLARDA가 다른 방법들에 비해 특징 공간에서 풍부한 시간 정보를 더 잘 활용하여 도메인 간의 정렬을 개선했기 때문
-
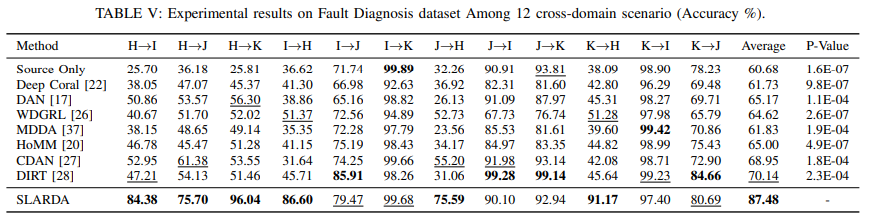
MFD 데이터셋 파트 : H, I, J, K라는 네 가지 다른 작업 조건을 가지고 있는 데이터 셋으로 12개의 도메인 간 시나리오에서 평가.
- 12개의 시나리오 중 6개에서 가장 좋은 성능을 보였으며, 두 번째로 좋은 방법인 VADA에 비해 평균 17.34%의 성능 향상
- H→I, H→J, H→K와 같은 큰 도메인 이동이 있는 전이 작업에서 벤치마크 방법들보다 뛰어난 성능
- H→I, H→J, H→K와 같은 큰 도메인 이동이 있는 전이 작업에서 벤치마크 방법들보다 뛰어난 성능
- 12개의 시나리오 중 6개에서 가장 좋은 성능을 보였으며, 두 번째로 좋은 방법인 VADA에 비해 평균 17.34%의 성능 향상
- 통계적 유의성 검증
- 모든 방법들에 대해, SLARDA는 P-값 <0.05를 달성했으며, 95% 신뢰 수준에서 모든 데이터셋에서 다른 접근법들보다 유의
- Abalation Study
- 모델 변형:
- SLARDA(w/o SL): self-supervised pretraining을 기존의 지도 학습으로 대체.
- SLARDA(w/o AR): autoregressive domain discriminator 를 기존의 GAN 손실로 훈련된 완전 연결 판별기 네트워크로 대체.
- SLARDA(w/o Teacher): SLARDA 모델에서 클래스 조건부 정렬(class-conditional alignment) 구성 요소 제거.
- SLARDA(full): 모든 구성 요소를 포함한 완전한 모델.
- 결과:
- 자가 지도 사전 학습 제거로 인한 성능 저하 (8% 이상).
- 클래스 조건부 정렬(Tacher) 제거로 인한 성능 영향.
- 시간적 특징을 고려한 자기회귀 구성 요소 추가로 인한 성능 향상 (약 3%).
- Ablation Study를 통한 SLARDA 모델의 각 구성 요소의 효과 확인.
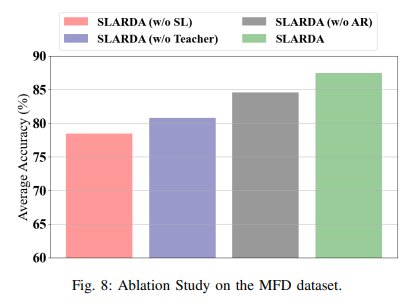
- 모델 변형:
-
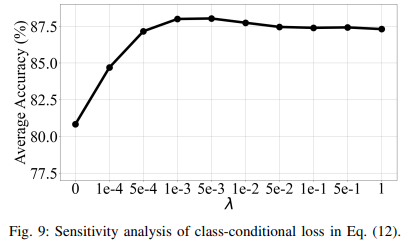
민감도 분석
- class conditional loss
- 목적: 제안된 방법에서 성능에 영향을 미치는 주요 파라미터 λ 분석.
- 결과:
- MFD 데이터셋에서 λ 값을 0.0001에서 1까지 변경하며 성능 관찰.
- λ 값 증가로 인한 SLARDA 성능 개선, 너무 높은 λ 값은 성능 저하를 초래할 가능성.
- SLARDA의 최적 성능을 보이는 λ 값 범위는 0.001에서 0.005 사이.
- 신뢰 임계값 파라미터 𝜁
- 결과:
- 낮은 신뢰 임계값이 노이즈 있는 가짜 레이블 사용으로 인한 성능 저하 초래.
- 높은 신뢰 임계값이 일관된 성능 향상 유도.
- 매우 높은 신뢰 임계값(예: 0.99)이 충분한 가짜 레이블 확보에 어려움을 주어 성능 저하를 초래할 가능성.
- 결과:
- class conditional loss
-
계산 복잡도
- 결함 진단(Fault Diagnosis) 데이터셋의 크로스 도메인 시나리오에서의 총 실행 시간 계산.
- 차이 기반 접근법(DAN, Deep Coral, HoMM, MMDA)은 적대적 학습 기반 접근법에 비해 낮은 계산 복잡도
- 적대적 학습 기반 접근법 중 SLARDA는 두 번째로 낮은 계산 비용(총 계산 시간: 1,765초).
[Summary]
- 본 연구는 시계열 데이터의 도메인 적응을 위해 시간적 의존성을 고려하면서도 feature learning 과 domain alignment를 할 수 있는 새로운 방법을 제안함
- self-supervised pretraining 을 통해 소스 도메인의 특징 학습을 향상
- autoregressive domain discriminator를 사용하여 도메인 간 특징 정렬 성능을 향상
- confident pseudo labels을 사용하여 클래스 간 분포 차이를 줄임으로써 성능을 더욱 향상시킴.
[Comment & Research Question]
-
한계 :
- 풍부한 라벨이 있는 소스 도메인 데이터를 필요
- 라벨링 작업이 번거로울 수 있다는 점에서 제약
- 저자의 향후 목표 :
- 도메인에서 적은 양의 라벨이 있는 데이터와 많은 양의 라벨이 없는 데이터를 사용하여 표현 학습을 수행할 수 있는 self-supervised learning을 설계하는 것을 목표
-
Research Question:
-
소스 도메인의 라벨 데이터가 제한된 경우, 본 연구에서 제안한 방법의 성능을 향상시킬 수 있는 방법은 무엇인가?
- self-supervised learning은 소스 도메인에서 이미 잘 학습된 특징 표현을 필요로 함. 이는 소스 도메인에서 풍부한 라벨이 있는 데이터를 통해 수행됨. 이러한 학습은 타겟 도메인에 대해 일반화될 수 있는 특징을 학습하기 위해 중요
-
타겟 도메인에서의 pseudo labels 생성 과정을 더욱 정밀하게 개선할 수 있는 방법은 무엇인가?
- pseudo label의 정확도를 높이면 타겟 도메인에서의 성능을 향상시키는 데 기여할 수 있음
- 현재 연구에서 사용된 EMA(Exponential Moving Average) 를 통한 pseudo label 생성외에 다른 것들을 고려할 수 있어보임
- Uncertainty Estimation 모델의 불확실성을 측정하여, 높은 신뢰도를 가지는 샘플에 대해 더 높은 가중치를 부여
- Pseudo Label Refinement 초기 단계에서는 비교적 보수적인 임계값을 설정하고, 점진적으로 신뢰 임계값을 높이는 방법
- Curriculum Learning 학습 과정에서 쉽게 예측할 수 있는 샘플부터 어려운 샘플 순으로 pseudo label을 생성하고 학습할 수 있도록. 이를 통해 모델이 점진적으로 더욱 어려운 샘플을 잘 예측할 수 있도록
-
본 연구의 방법을 다른 유형의 시계열 데이터나 다른 도메인에 적용할 때 발생할 수 있는 문제와 해결 방안은 무엇인가?
-
