[논문 분석] CFLOW-AD: Real-Time Unsupervised Anomaly Detection with Localization via Conditional Normalizing Flows (WACV 2022)
[ 논문 분석 ]
요약
-
Normalizing flow란 생성모델에 있어 일종의 역함수를 거듭해서 학습하여 확률 분포를 직접 모델링하는 방법론
- (1)역계산과 (2)Jacobian(지역적인 함수의 변화를 선형 근사 시킴)의 Determinant(행렬을 선형변환 시 변화되는 크기) 계산을 수행하고 그를 Coupling Layer를 통해 연결하는 것으로 데이터의 분포를 Latent Space z에 Mapping하는 모델.
- 이때 x의 likelihood를 최대화하는 것을 목적 함수로 사용( x의 분포가 latent space로 잘 mapping 되어 있다.)
-
Normalizing Flow 모델을 사용한 비지도 학습 방식 Anomaly Detection
-
Image & Pixel 단위 Anomaly Detection 수행
-
Real-Time에 적용할 수 있는 빠른 추론 속도를 가진 모델
기초 개념정리
🔹 Likelihood : 가능도(likelihood)는 주어진 관측값이 해당 확률분포에서 나왔을 가능성을 의미함
- 이와 달리 확률(probability)은 주어진 확률분포에서 해당 관측값이 나올 가능성을 의미함
🔹 Feature extraction with Gaussian prior:
- CNN의 파라미터 𝜆는 KL divergence를 최소화하여 학습됨
- 파라미터 𝜆는 초기값으로 가우시안 분포(예: 정규분포)에서 샘플링된 값들을 사용하며, 최적화 과정에 L2 weight decay 정규화
- 이 정규화로 인해 모델의 파라미터뿐 아니라, 중간 계층에서 추출된 특징 벡터
𝑧도 다변량 가우시안(MVG) 사전 분포를 띠게 됨 - 이 가우시안 사전 분포 가정은 이후 anomaly detection에서 이상이 없는 데이터의 분포를 모델링할 때 중요한 역할을 하며, feature extraction 단계에서 얻은 𝑧가 “정상(normal)”의 특징을 잘 대표하도록 도와줌
🔹 MVG
Multivariate Gaussian의 약자로, 다변량 정규 분포를 의미함. 다변량 정규 분포는 평균 벡터와 공분산 행렬로 정의되며, 여러 변수 간의 관계와 분포를 동시에 나타낼 수 있음
🔹 Normalizing Flow란?
- Normalizing Flow는 역변환 가능한 연속 변환 함수들의 조합을 이용하여 단순한 분포(Simple Distribution, 예: 정규 분포)에서 시작해 복잡한 분포(Complex Distribution, 예: 실제 데이터 분포)로 변환하는 방법
- 핵심 아이디어는 변환 함수 f가 invertible 하도록 설계해 변화-변환 관계를 정확히 계산하도록 하는것
- 데이터 분포를 단순한 분포로 맵핑하는 방향으로 Normalizing Flow를 적용하는 것도 동일한 원리를 사용한 것이라고 볼 수 있음
=> 강력한 확률 모델링 기법
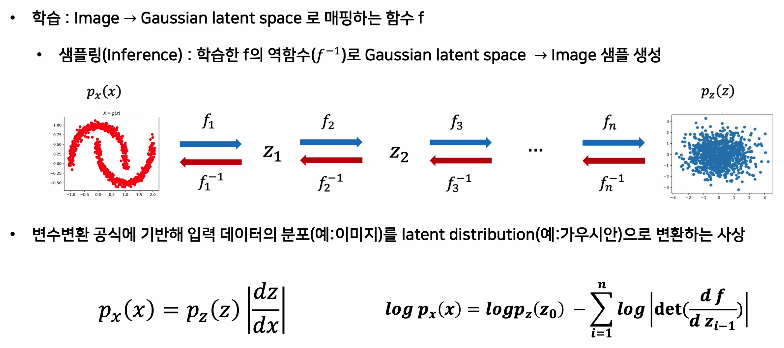
✔ 핵심 아이디어
✅ 기본 분포(예: 정규 분포)에서 샘플을 생성한 후, 여러 개의 변환을 거쳐 복잡한 분포를 학습
✅ 변환이 역변환 가능(Invertible)해야 함 → 즉, 데이터를 원래 분포로 되돌릴 수 있어야 함
✅ Log-likelihood를 정확하게 계산할 수 있음 → 확률 밀도 함수(PDF)를 직접 학습 가능
🔹 Normalizing Flow의 장점과 단점
✅ 장점
- 확률 분포를 직접 모델링 가능 (Log-likelihood 최적화)
- 역변환이 가능하므로 샘플링이 쉬움
- VAE나 GAN보다 더 강력한 확률 모델링 가능
❌ 단점
- 변환이 가역적(Invertible)이어야 하므로 모델 설계가 제한적
- Jacobian Determinant 계산이 필요하여 계산량이 많음
- 깊은 Flow 구조를 사용할 경우 학습이 어려울 수 있음
[Background]
✅ 본 논문은 unsupervised anomaly detection with localization 분야에서, 라벨 없는 anomaly-free 데이터를 기반으로 anomaly를 탐지하고 위치를 추출하는 기존 접근 방식들을 배경으로 하고 있음.
✅ 기존 방법들은 CNN을 통한 feature extraction과, 이후 post-processing 단계에서 Mahalanobis distance나 clustering, generative models (예: GANs, VAEs) 등을 이용하여 anomaly score를 산출함.
- 그러나 이러한 fully-generative models는 정확한 data likelihood를 추정하기 어렵고, 추가적으로 clustering이나 복잡한 후처리로 인해 real-time processing에 한계가 있음.
✅ 최근에는 Normalizing Flows를 활용하여 단순한 base distribution (예: Gaussian)에서 복잡한 실제 데이터 분포로의 변환을 시도하며, conditional normalizing flows와 같이 spatial information을 함께 고려하는 방법들이 등장하고 있음.
✅ 이러한 배경 하에, 본 연구에서는 기존의 복잡한 모델들을 대체할 수 있는, computationally and memory-efficient한 접근법을 제안하고자 함
[Motivation]
✅ 실제 산업 현장이나 의료, 교통 모니터링 등 다양한 application에서는 anomaly labeling이 어렵거나, 이상 사례 자체가 매우 희소하여 train data에 존재하지 않는 경우가 많음. 이에 따라 supervised AD는 실용성이 떨어지며, unsupervised anomaly detection, 즉 OOD detection으로 문제를 재정의할 필요가 있음.
✅ 또한, 기존 방법들은 높은 accuracy를 보이지만, test-time clustering이나 복잡한 generative model 구조로 인해 real-time processing에 어려움을 겪음. 따라서, 실시간 처리가 가능한 모델이 필요하며, 동시에 feature extraction과 likelihood estimation의 효율성을 극대화할 수 있는 방법이 요구됨.
✅ 기존의 Normalizing flow 모델은 Anomaly Detection에서 바로 적용하면 입력한 이미지가 Local 영역에서 픽셀간 Correlation이 크다는 영향을 강하게 받게됨. 또한 Semantic Content를 반영할 수 없기 때문에 Likelihood를 최대화 하는 것에 한계가 존재함.
이러한 문제 인식과 함께, Conditional Normalizing Flows를 기반으로 한 경량화된 모델을 개발할 동기가 형성됨
[Contribution]
✅ Theoretical Analysis: 기존의 multivariate Gaussian prior 기반의 anomaly detection 방법과 더 일반적인 Normalizing Flow framework objective가 유사한 결과로 수렴하는 이유를 분석적으로 도출함.
✅ Proposed Model (CFLOW-AD): 사전 학습된 feature extractor를 활용하여, 이미지의 Semantic Content를 미리 반영한 feature embedding을 추출하고, 각 layer별 feature embedding에 대해 positional encoding을 추가한 후, 이를 독립적인 conditional normalizing flow model에 학습시킴으로써 정확한 data likelihood 추정 및 anomaly localization을 수행하는 모델을 제안함.
- 보통 positional encoding을 언어모델에서 활용한 방법인데 이를 이미지에서 픽셀 차원에 적용을 한 것. 이를 통해서 pixel 간 correlation에 영향을 크게 받는 것을 줄일 수 있게 함
✅ Efficiency: 제안된 CFLOW-AD는 동일한 입력 설정에서 기존 state-of-the-art 모델보다 10× 빠르고, 메모리 요구량이 현저히 낮아 real-time processing에 적합함.
✅ Performance Improvement: MVTec dataset 실험에서 detection task에서 0.36% AUROC, localization task에서는 1.12% AUROC와 2.5% AUPRO의 성능 향상을 달성함.
✅ Open-Source Reproducibility: 모든 코드를 공개하여, 연구의 reproducibility와 실제 응용에 기여함.
[Proposed Method]
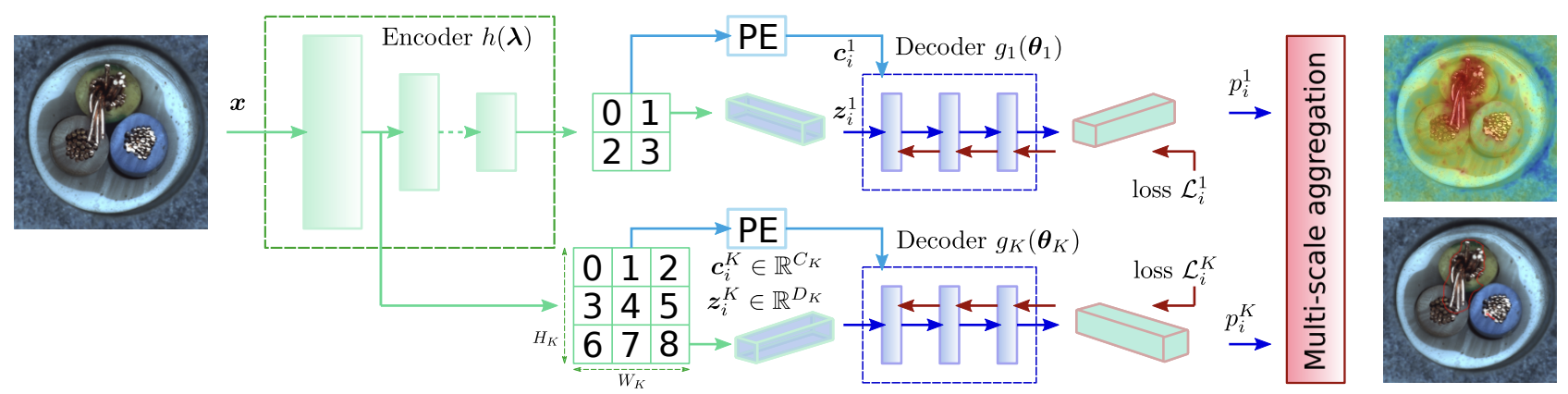
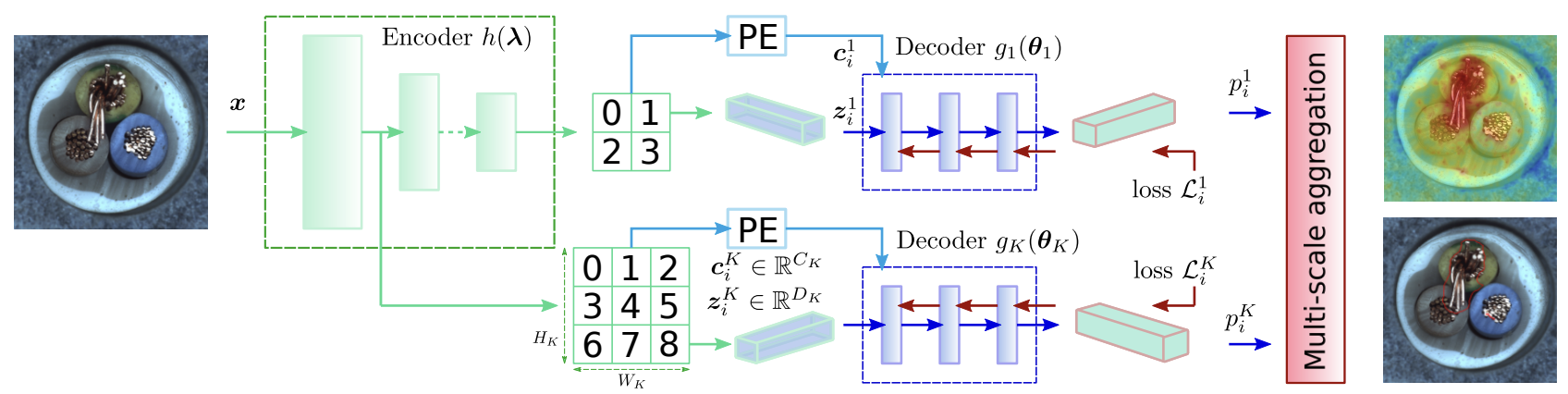
✅ CFLOW encoder for feature extraction
본 모델은 사전 학습된 CNN, 특히 ImageNet-pretrained encoder (예: ResNet-18, WideResNet-50 등)을 feature extractor로 사용함.
입력 이미지 patch x는 이 encoder를 통해 feature vector z로 매핑되며,
z는 이미지의 semantic content를 반영함.
Encoder는 multi-scale feature pyramid pooling을 채택하여, 서로 다른 scale의 정보를 동시에 캡처함.
- 이 과정에서 각 pooling layer는 서로 다른 receptive field (작은 receptive field는 local 정보를, 큰 receptive field는 global 정보를 반영)를 제공함.
이러한 구조 덕분에, anomaly는 다양한 크기와 형태로 존재하더라도 효과적으로 표현될 수 있음.
✅ CFLOW decoders for likelihood estimation
추출된 feature vector z에 대해, 본 모델은 conditional normalizing flow (CFLOW) 기반의 generative decoder를 사용하여 log-likelihood를 추정함.
- ✅ Conditional Normalizing Flow Framework:
일반적인 normalizing flow 모델은 단순한 base distribution (예: standard Gaussian)에서 시작해 복잡한 데이터 분포 𝑝(z)로 변환하는 가역적 변환 g를 사용함.
본 논문에서는 이 framework를 확장하여, spatial prior를 반영하기 위해 conditional input을 도입함. - ✅ Positional Encoding:
보통 language model에서 사용되는 positional encoding을 2D 형태로 변환하여, 각 feature embedding에 위치 정보를 추가함.
각 conditional vector 는 sin, cos harmonic을 포함하며, 해당 픽셀의 고유한 spatial 위치 정보를 제공함. - ✅ Decoder Architecture:
각 scale에 대해 독립적인 CFLOW decoder 가 학습됨.
Decoder는 여러 coupling layers로 구성되며, 각 coupling layer는 (Dk + Ck)×(Dk + Ck) fully-connected layer, softplus activation, 그리고 output vector permutation으로 이루어짐.
이 coupling layer 내부에서, intermediate vectors와 conditional vectors가 concatenation되어 결합되며, 이를 통해 spatial prior가 효과적으로 반영됨. - ✅ Translation-Equivariance:
Decoder는 fully-convolutional 구조로 설계되어, sliding window 방식의 처리와 kernel parameter sharing을 통해 translation equivariant 특성을 지님.
결과적으로 encoder와 decoders 모두 이미지의 spatial 구조를 보존하면서 feature들을 효율적으로 처리함
✅ Training and Inference
-
Training Objective:
CFLOW-AD는 최대 우도 (maximum likelihood) 목표함수를 사용하여 학습됨.
이는, 실제 feature density 𝑝(z)와 모델이 추정한 density
𝑝^_Z_(z,c,θ) 사이의 KL divergence를 최소화하는 것과 동등함.
식 에서 보듯, loss는 coupling layers의 Jacobian determinant와, 역변환된 sample u의 제곱 Euclidean distance를 포함하는 형태로 정의됨.
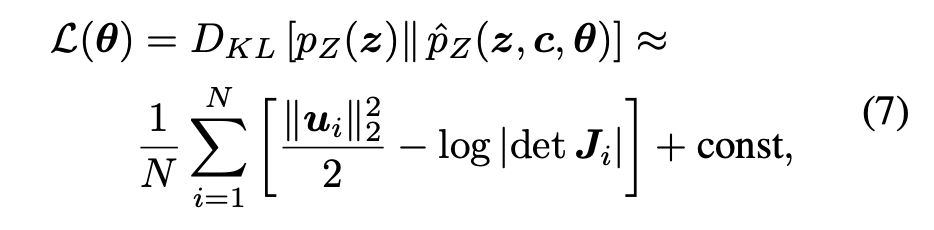
-
Inference:
테스트 단계에서는 학습된 CFLOW decoders를 사용하여, 각 feature vector의 log-likelihood를 계산함
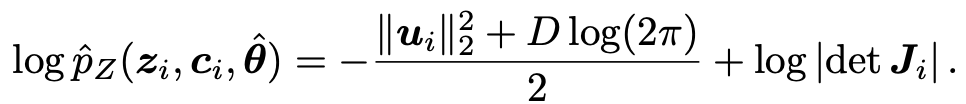
이후, log-likelihood 값을 probability로 변환한 뒤, bilinear interpolation을 통해 원래 입력 해상도로 upsampling하고, 각 scale의 결과를 aggregation하여 최종 anomaly score map을 산출함.
✅ Complexity analysis
CFLOW-AD는 기존의 SPADE, PaDiM 등과 비교하여, 계산량과 메모리 요구량이 훨씬 낮아 real-time processing이 가능함.
Multi-scale pyramid pooling과 conditional normalizing flow를 결합함으로써, 각 픽셀의 위치 정보를 효과적으로 반영하여 pixel 간의 강한 correlation에 의한 부정적 영향을 줄임.
최종적으로, CFLOW-AD는 동일한 입력 설정 하에서 기존 state-of-the-art 모델보다 10× 빠르며, 성능 면에서도 anomaly detection과 localization에서 우수한 결과를 보임
[Experiments]
✅ 데이터셋:
- MVTec Dataset:
총 15개 클래스, 3,629개의 anomaly-free 훈련 이미지와 1,725개의 테스트 이미지로 구성됨.
테스트 데이터는 다양한 결함이 포함된 이미지와 결함이 없는 이미지가 혼재함.
일부 클래스는 carpet, grid, leather, tile, wood와 같이 텍스처를, 나머지 클래스는 다양한 객체를 나타냄. - STC Dataset:
274,515개의 훈련 프레임과 42,883개의 테스트 프레임으로 구성되며, 13개의 대학 캠퍼스 장면으로 구분됨.
✅ 전처리 및 증강:
MVTec의 경우, 이미지를 지정된 해상도 (예: 256×256, 512×512 등)로 크기 조정하며, 훈련 단계에서 ±5° 회전 증강만 적용됨.
STC는 MVTec와 동일한 전처리 및 증강 파이프라인을 사용하되, 256×256 해상도만 사용함.
✅ 모델 학습:
모든 CFLOW-AD 모델은 각 MVTec 클래스 및 STC 장면마다 별도로 학습됨.
동일한 하이퍼파라미터 사용: Adam optimizer (learning rate 2e-4), 100 epochs, encoder mini-batch size 32, cosine learning rate annealing (2 warm-up epochs).
Decoder는 feature map의 차원에 독립적이며 메모리 요구량이 낮아, feature vector 처리 시 8,192 (32×256) mini-batch size로 학습 및 테스트함.
각 훈련(epoch)마다 8,192개의 feature vector가 무작위로, 그리고 테스트 시에는 순차적으로 샘플링됨.
✅ 평가 지표:
Localization: AUROC와 AUPRO (area under per-region-overlap curve)를 사용함. AUROC는 큰 영역 anomaly에 치우치는 반면, AUPRO는 anomaly 크기에 관계없이 균등하게 평가함.
Image-level AD: AUROC만 보고함.
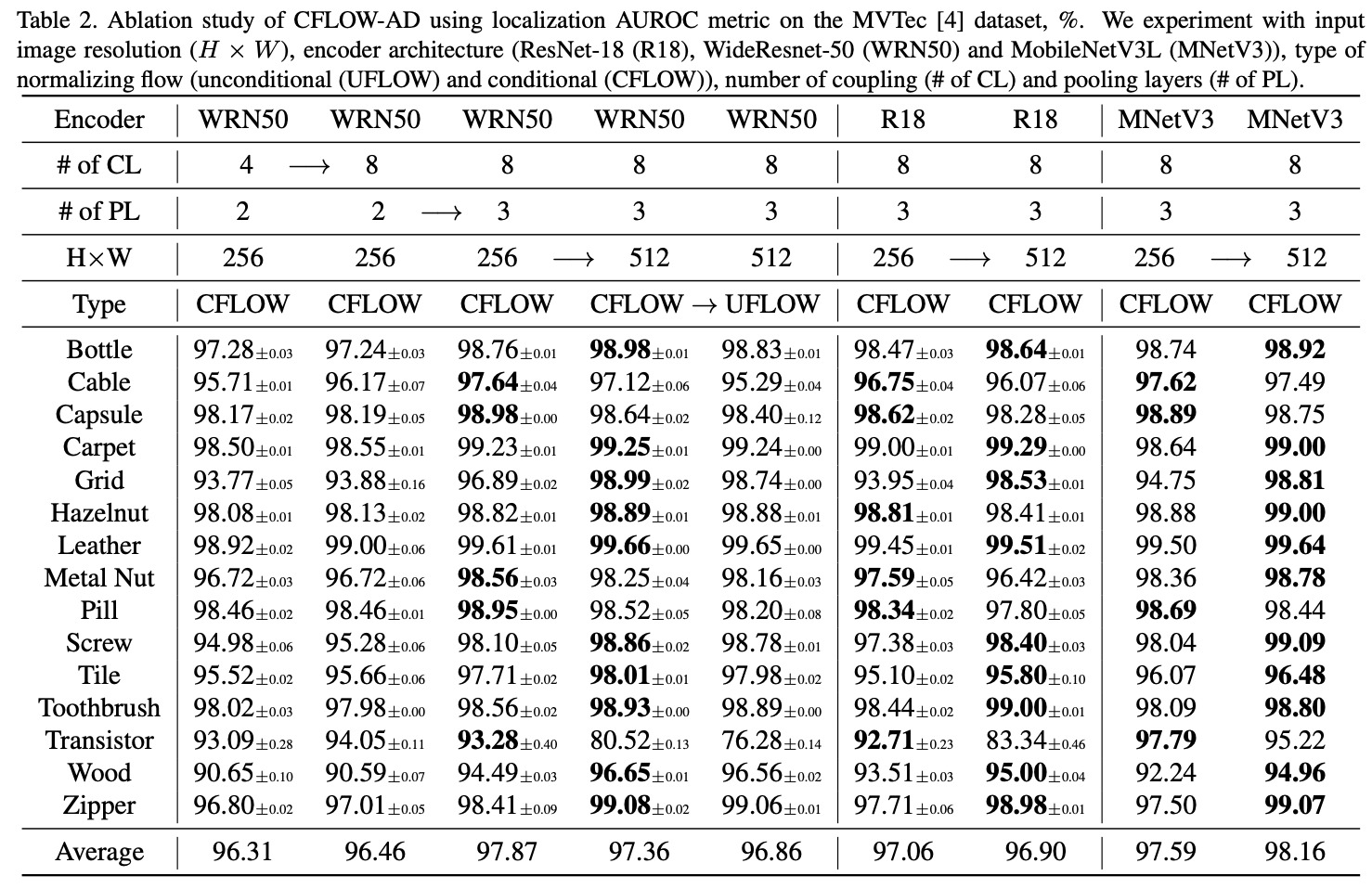
✅ Ablation Study (Table 2)
목적:
CFLOW-AD의 다양한 설계 선택(입력 해상도, encoder 아키텍처, normalizing flow 유형, coupling layer 수, pooling layer 수)이 성능에 미치는 영향을 체계적으로 분석함.
- 결과:
Coupling layer 수를 4에서 8로 늘리면 평균 0.15% AUROC 향상이 있었으며, 3-scale feature map 처리(첫 번째, 두 번째, 세 번째 layer 사용)는 2-scale 처리보다 1.4% AUROC 개선을 보임.
Conditional normalizing flow (CFLOW)가 unconditional (UFLOW) 방식보다 평균 0.5% 향상됨.
Encoder 아키텍처에 따라 성능 차이가 발생하며, WideResNet-50이 ResNet-18보다 0.81% 높은 성능을 보였음.
클래스마다 최적의 입력 해상도가 다름 (예: cable, pill과 같이 매크로 객체는 256×256, 대부분 클래스는 512×512, transistor는 128×128에서 최적 성능).
이 ablation study는 CFLOW-AD의 설계 선택이 실제 anomaly detection 및 localization 성능에 미치는 영향을 구체적으로 보여줌
✅ Quantitative Comparison (Tables 3, 4, 5)
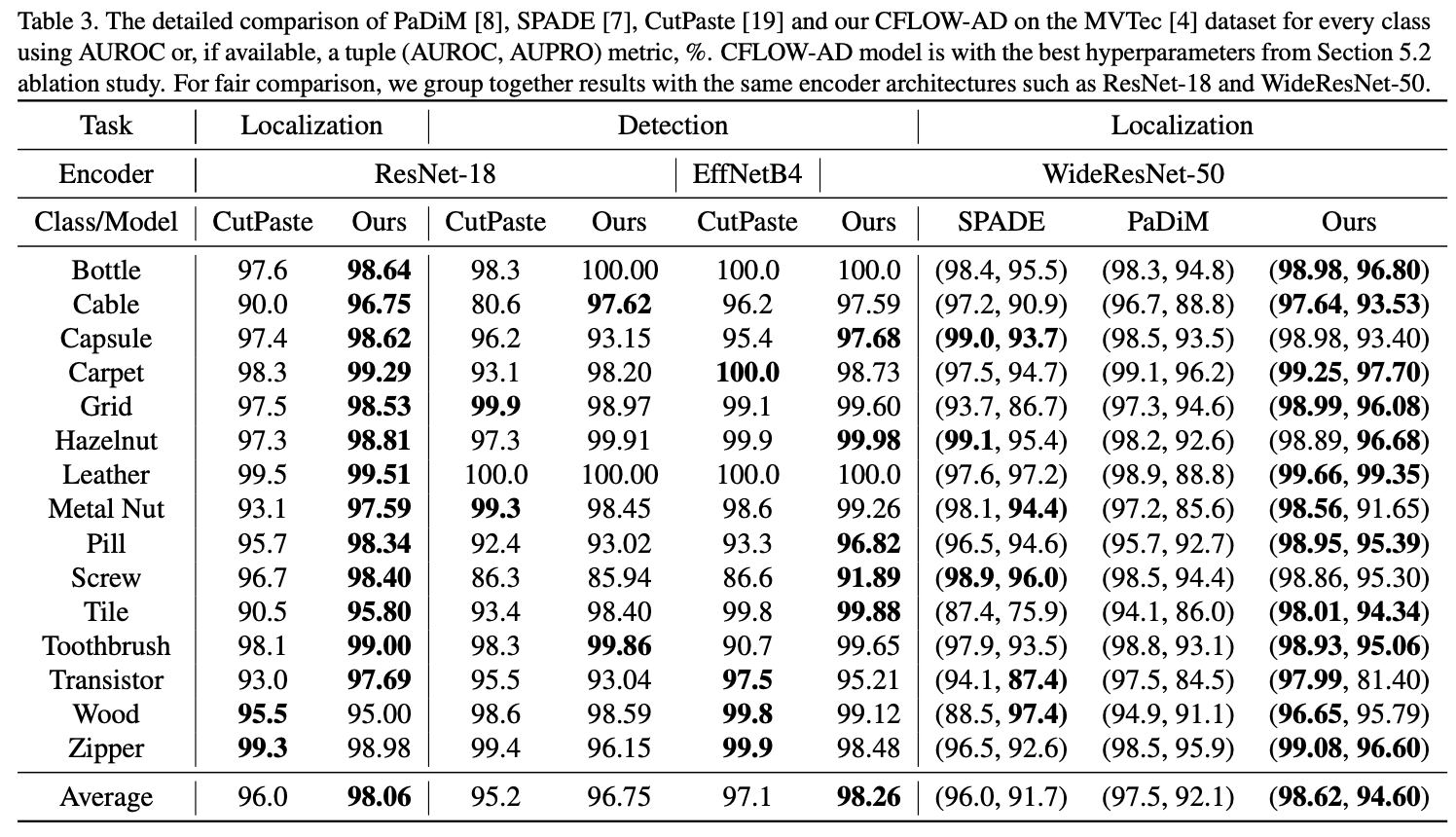
- Table 3 – Detailed Per-Class Comparison:
PaDiM, SPADE, CutPaste 및 CFLOW-AD의 각 클래스별 성능을 AUROC(및 localization의 경우 AUPRO)로 비교함.
CFLOW-AD는 동일한 encoder setup 하에서 각 클래스별로 최고의 성능 혹은 동등 이상의 성능을 기록함.
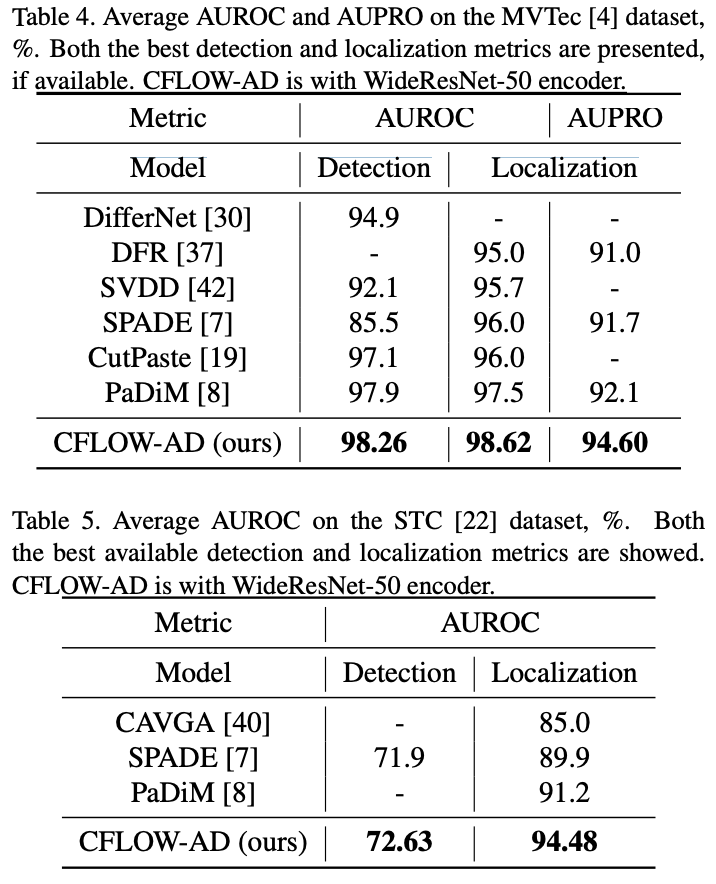
- Table 4 – Average Results on MVTec:
전체 MVTec 데이터셋에 대한 평균 AUROC (detection) 및 평균 AUROC, AUPRO (localization) 성능을 비교함.
CFLOW-AD (WideResNet-50 encoder 사용)는 detection에서 state-of-the-art 대비 0.36% AUROC, localization에서는 1.12% AUROC와 2.5% AUPRO 향상을 보임. - Table 5 – Average Results on STC:
STC 데이터셋에 대해 anomaly detection과 localization 성능을 비교함.
CFLOW-AD는 SPADE 보다 anomaly detection에서 0.73% AUROC, PaDiM 보다 anomaly localization에서 3.28% AUROC 향상됨.
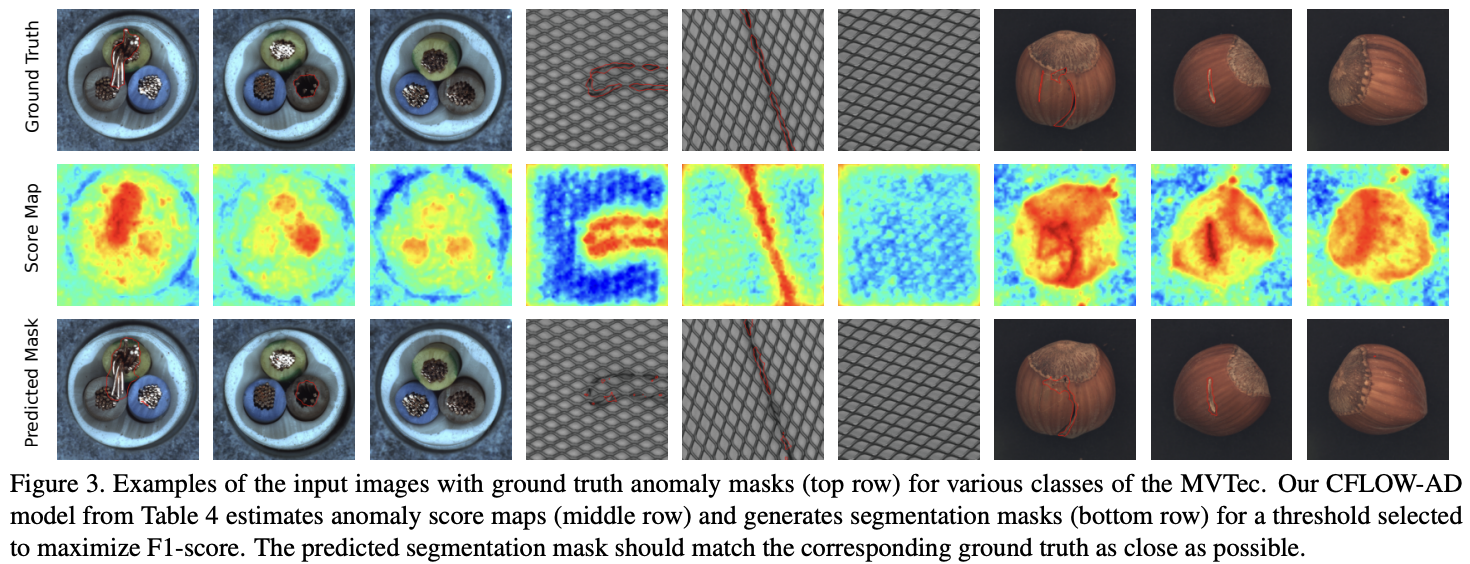
✅ Qualitative Results (Figure 3 & 4)
Figure 3:
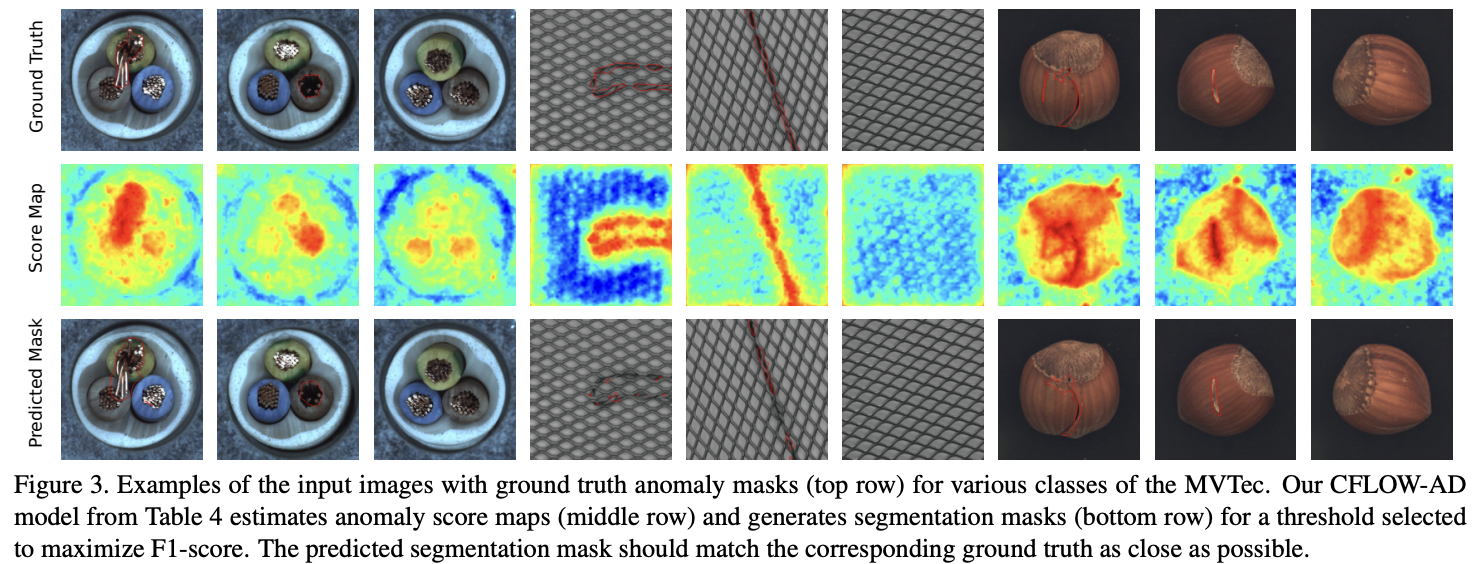
MVTec 데이터셋의 입력 이미지와 함께, ground truth anomaly mask, CFLOW-AD가 생성한 anomaly score map, 그리고 최적 F1-score를 위한 threshold를 적용한 예측 segmentation mask를 시각적으로 보여줌.
예측된 segmentation mask는 ground truth와 가깝게 일치함을 확인할 수 있음.
Figure 4:
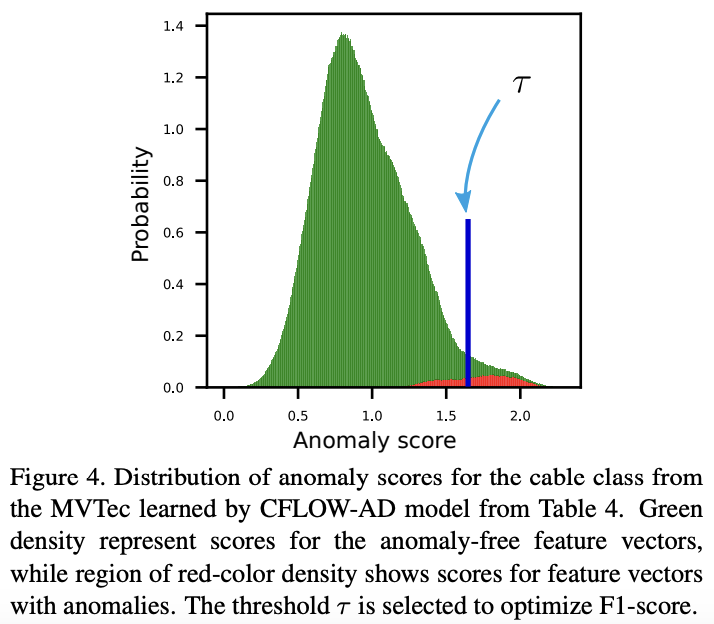
anomaly-free (green)와 anomalous (red) feature vector에 대해 CFLOW-AD가 출력한 anomaly score 분포를 보여줌.
이 분포를 통해 CFLOW-AD가 in-distribution과 out-of-distribution feature vector를 효과적으로 구분하고, 단일 scalar threshold τ를 통해 이를 분리할 수 있음을 시각적으로 입증함.
✅ Complexity Evaluations (Table 6)
목적:
CFLOW-AD와 기존 모델들의 추론 속도 및 모델 크기를 비교하여, 실시간 처리 가능성을 평가함.
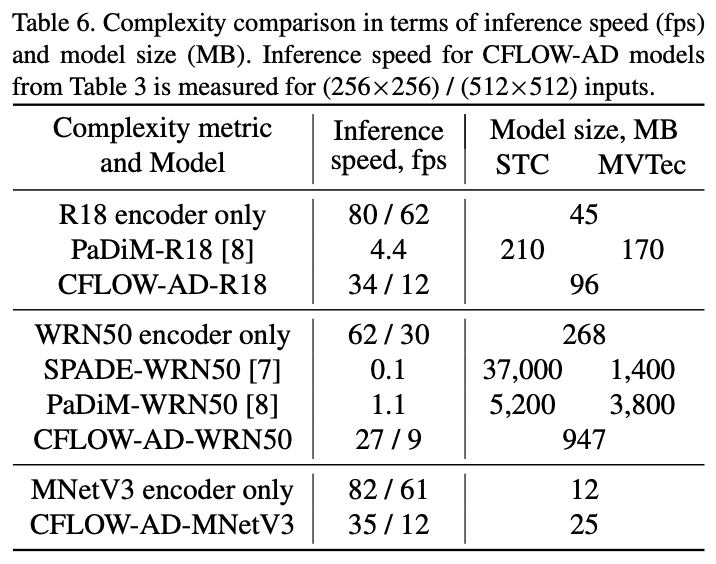
Inference Speed (fps): 각 모델의 추론 속도를 비교함. 예를 들어, CFLOW-AD는 동일한 입력 해상도에서 SPADE나 PaDiM에 비해 8×에서 25× 빠른 추론 속도를 보임.
Model Size (MB): 전체 모델(encoder + decoder)의 크기를 측정함.
CFLOW-AD의 decoder는 feature map 차원에 의존하지 않고, 파라미터 수가 상대적으로 작아 메모리 요구량이 매우 낮음.
비교 시, CFLOW-AD는 encoder 파라미터를 제외할 경우 SPADE보다 1.7×~50×, PaDiM보다 2×~7× 작은 크기를 보임.
이 복잡도 평가는 CFLOW-AD가 실시간 anomaly detection with localization 시스템에 적합함을 정량적으로 입증함
[Conclustion]
- 사전 학습 모델을 통해 Feature Layer별 embedding을 추출하여 Conditional Normalizing Flow를 적용한 모델 제안
- 성능과 추론 속도 모두 실시간 이상치 탐지를 위한 적용 가능한 성능
- 픽셀 단위로 이상점수를 계산하기 때문에 이상 부분에 대해 더 정확한 Localization 가능
실험을 통해 다양한 데이터셋 (MVTec, STC)에서 높은 anomaly detection 및 localization 성능을 달성하고,
ablation study를 통해 설계 선택(입력 해상도, encoder, coupling layer 수, pooling layer 수, conditional vs. unconditional NF)이 성능에 미치는 영향을 체계적으로 분석하였으며,
모델의 계산 복잡도와 메모리 요구량에서도 기존 state-of-the-art 방법들보다 현저히 우수함을 보여줌.
이러한 결과들은 CFLOW-AD가 실시간 처리에 적합한 효율적이고 성능 높은 anomaly detection 및 localization 모델임을 증명함
