분류 모델: FC Layer → 활성화 함수 (Sigmoid/Softmax)
회귀 모델: FC Layer → 활성화 함수 없음
이를 통해 분류에서는 확률을, 회귀에서는 연속적인 값을 얻음
Convolutional Networks
0. Background
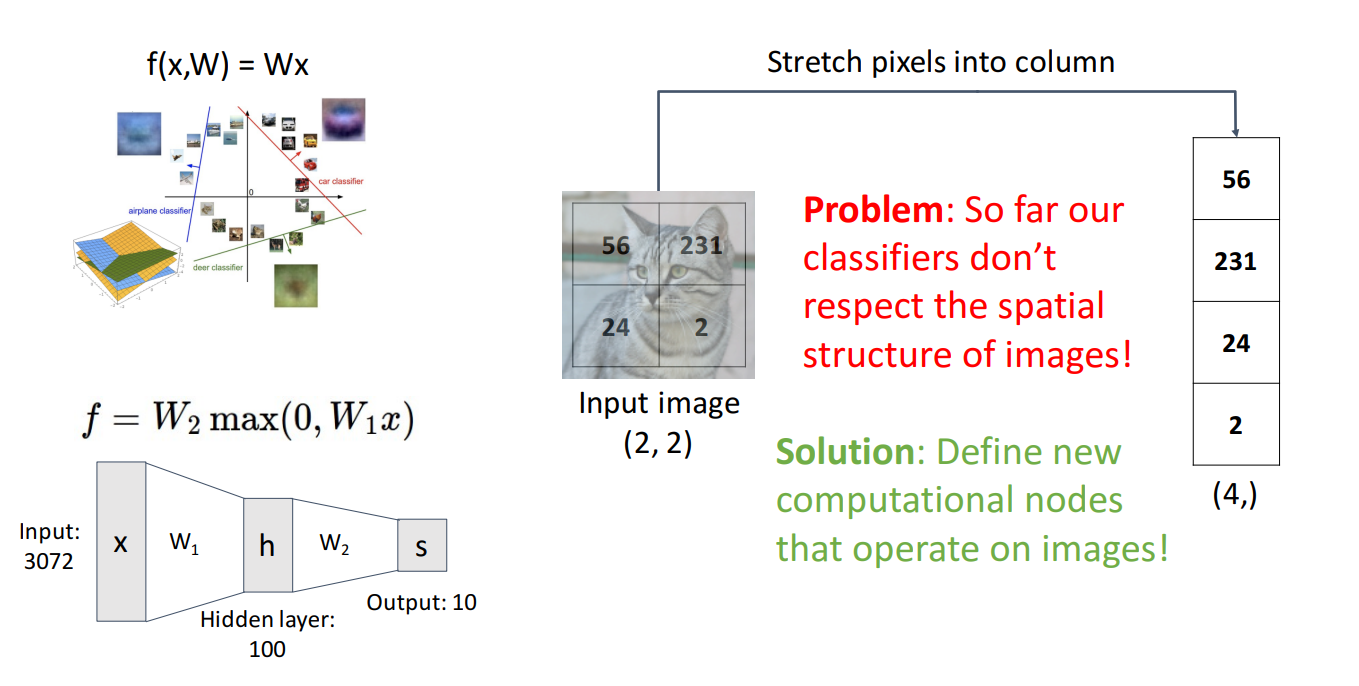
- Linear Classifier, MLP 문제 :
- Spatial 한 구조를 flatten한 column을 신경망에 넣음
- 이미지의 Spatial 구조를 무시한채 분류 수행
- Convolution Layers : 이미지의 Spatial 구조를 유지하도록 하는 새로운 Operator를 도입
1. Convolutional Neural Networks (CNN)
- 이미지와 같은 데이터의 공간적 구조를 보존하며 학습하는 신경망 구조
- 선형 분류기는 이미지의 공간적 구조( spatial structure of images ) 고려 X
- 해결책: 이미지에서 작동하는 새로운 계산 노드를 정의 ⇒ Fully-Connected Network 필요
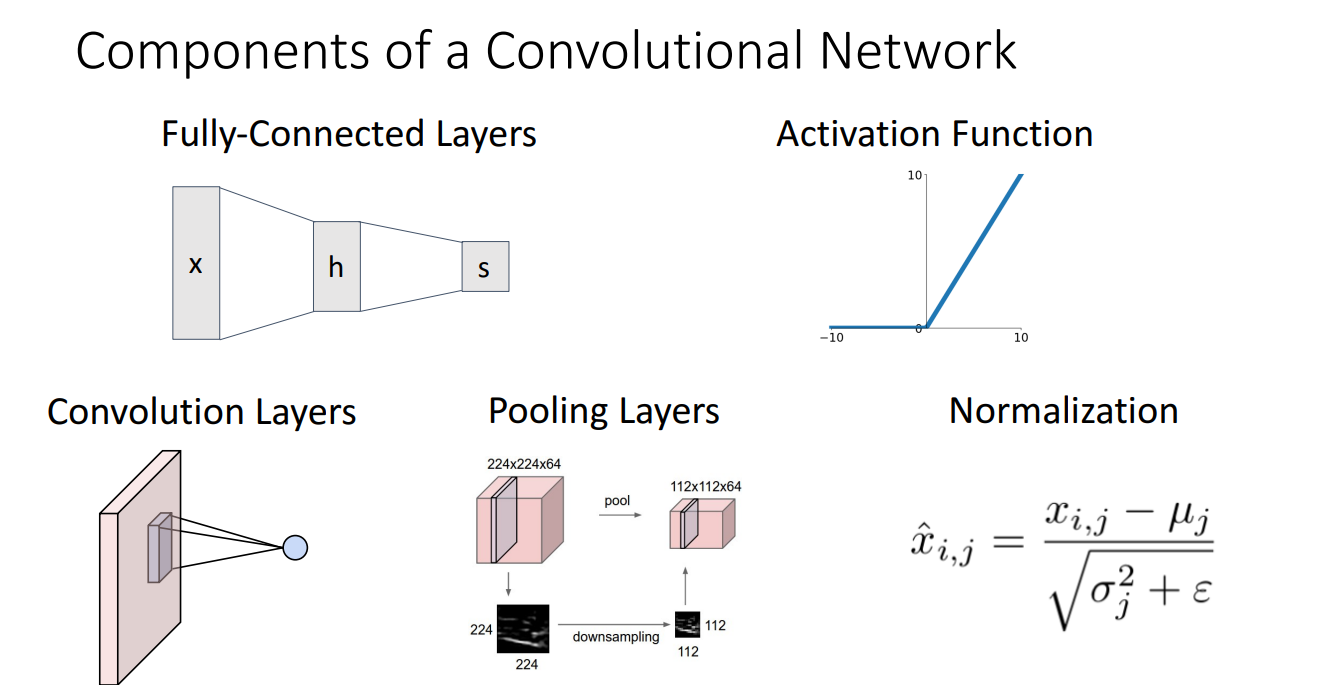
- 주요 구성 요소: 합성곱 층, 풀링 층, 완전 연결 층, 활성화 함수, 정규화.
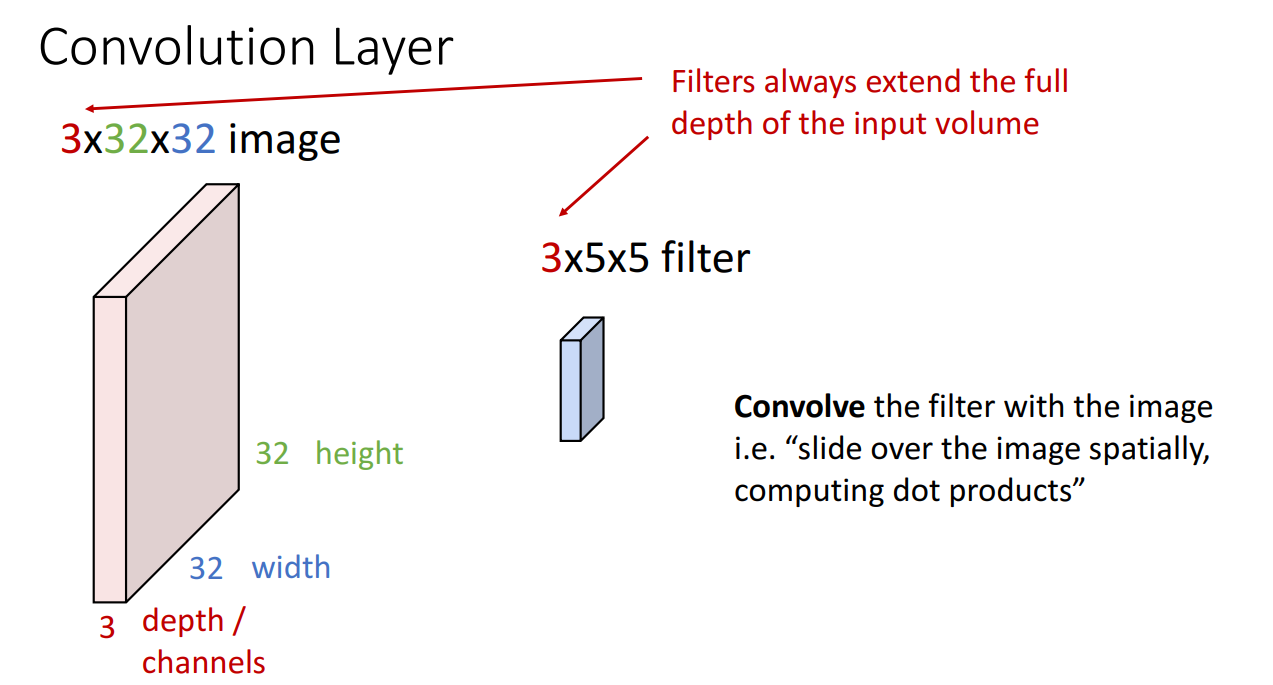
2. 합성곱 층 (Convolution Layer)
-
합성곱 연산:
-
필터가 한 번 거칠때 필터의 크기만큼 dot product 연산을 거치게 되고 1개의 숫자가 계산
-
각 필터는 입력 데이터의 특정 패턴을 학습
-
필터(커널)를 이미지에 슬라이딩하여 activation map 맵 생성
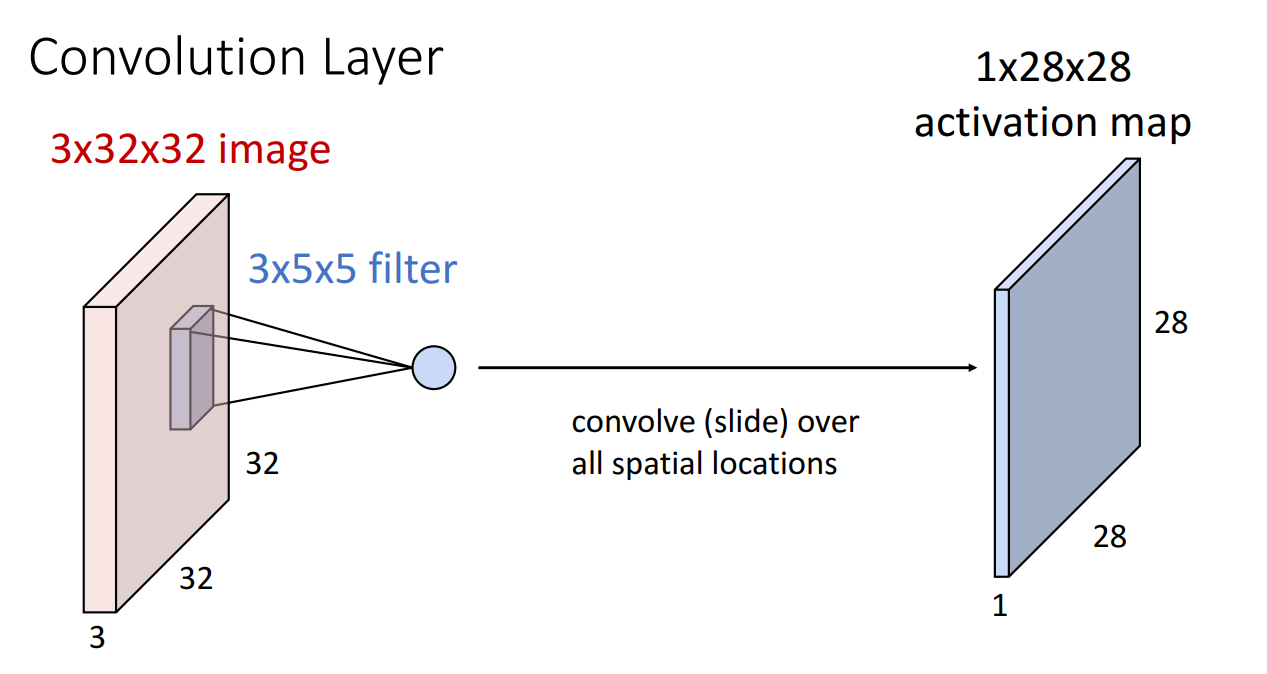
-
N 크기 배치의 이미지들이 Cout개의 필터들을 거쳐서서 총 Cout개의 activation map이 N배치만큼 생성되는걸 볼 수 있음
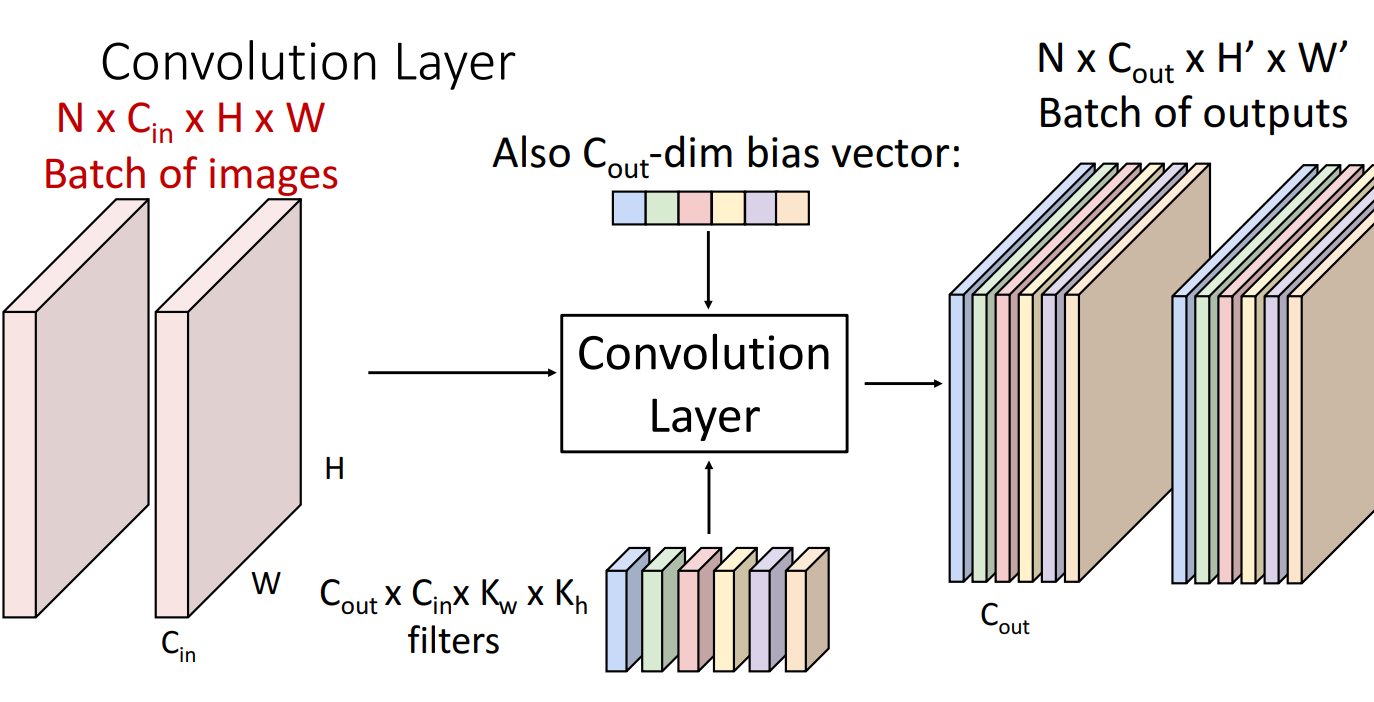
-
Convolution layer를 쌓을 시 중간중간에 Nonlinear 한 activation function 삽입하기 ( 활성화 함수를 삽입 안하면 linear classifier 때 살펴봤던 것 처럼 여러개를 쌓은 효과를 볼 수 없음 )
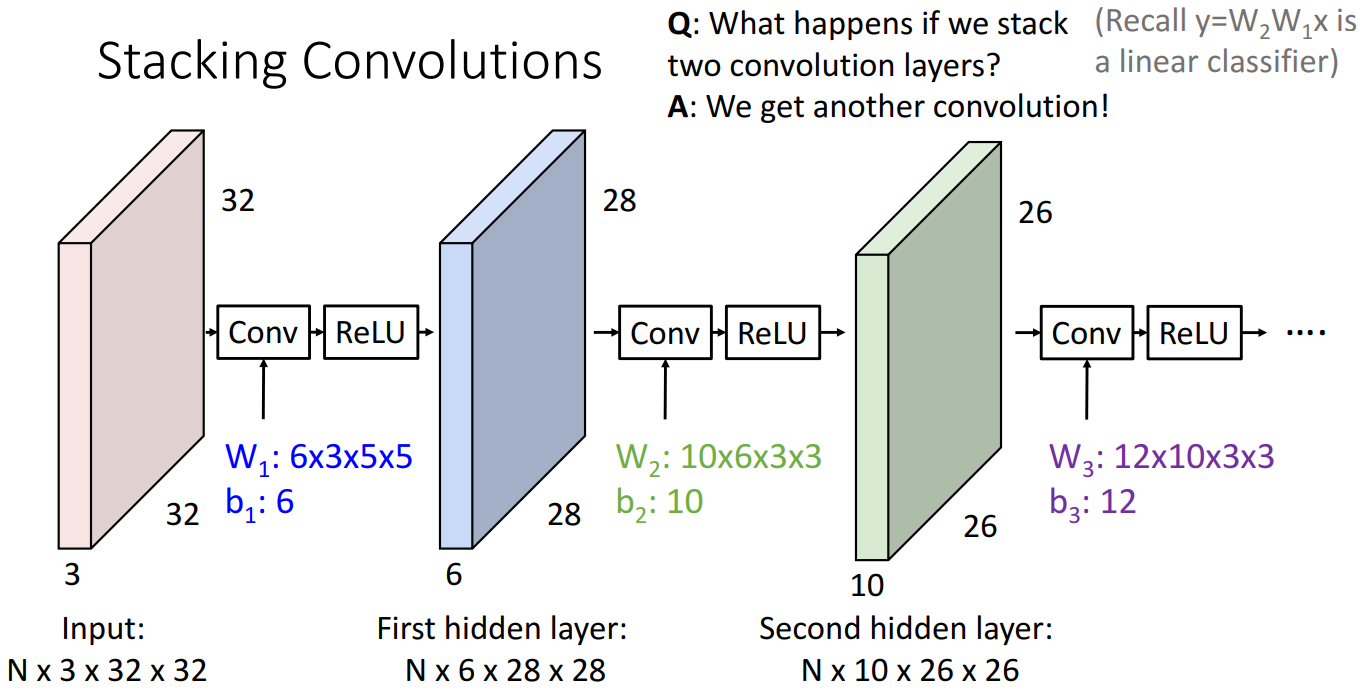
-
-
왜 Conv filter을 사용해야 하는가?
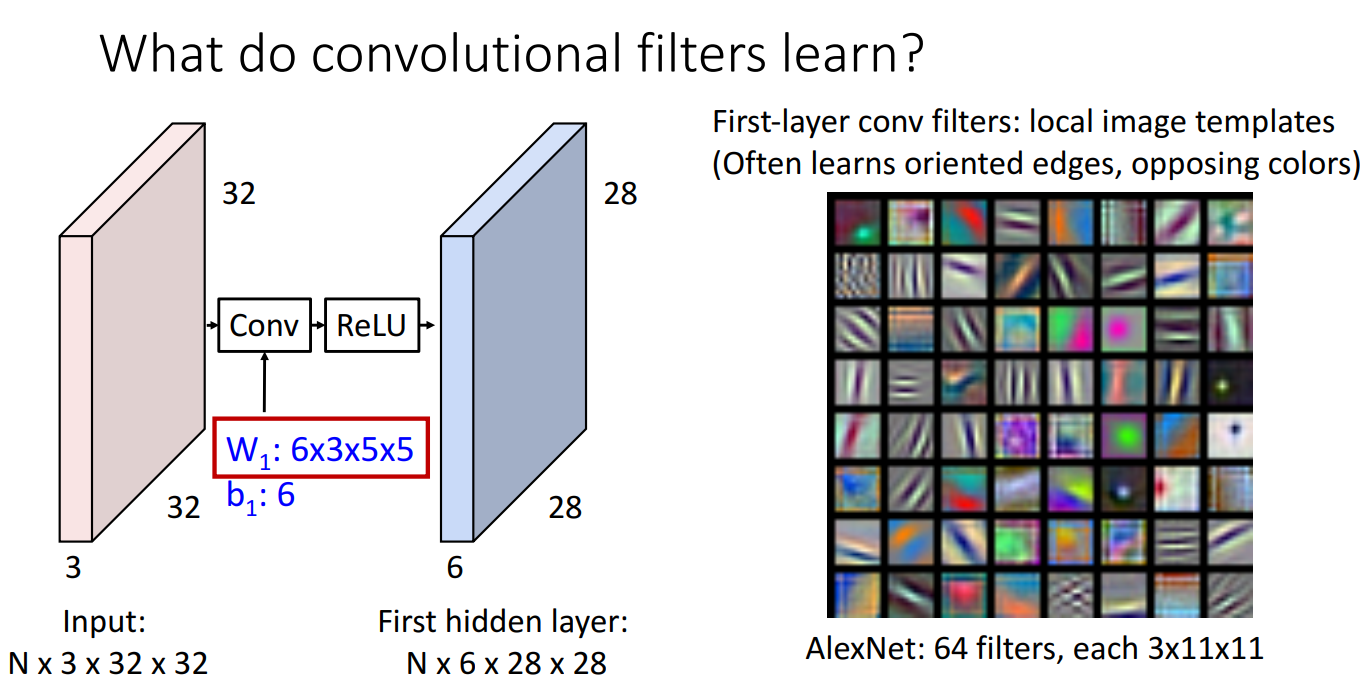
- 시작 단계의 Conv filter가 이미지 opposing color 와 같은 local image template을 잘 포착하는 것을 알 수 있음
- 기존의 Linear Classifier나 MLP는 Class를 구분하는 template을 학습하는데에 반해 Conv Filter는 Spatial 한 정보를 학습하는 장점이 있음
-
Feature Map이 줄어드는 문제:
- Conv filter가 원본 이미지를 지나가면서 Dot product 연산을 거치고 Output activation map을 산출할 때 => Feature map이 Shrink 된다는 문제 존재
- 여러 개의 Conv filter를 거친다면 Feature map은 작아짐
- 해결방법 : 패딩 추가
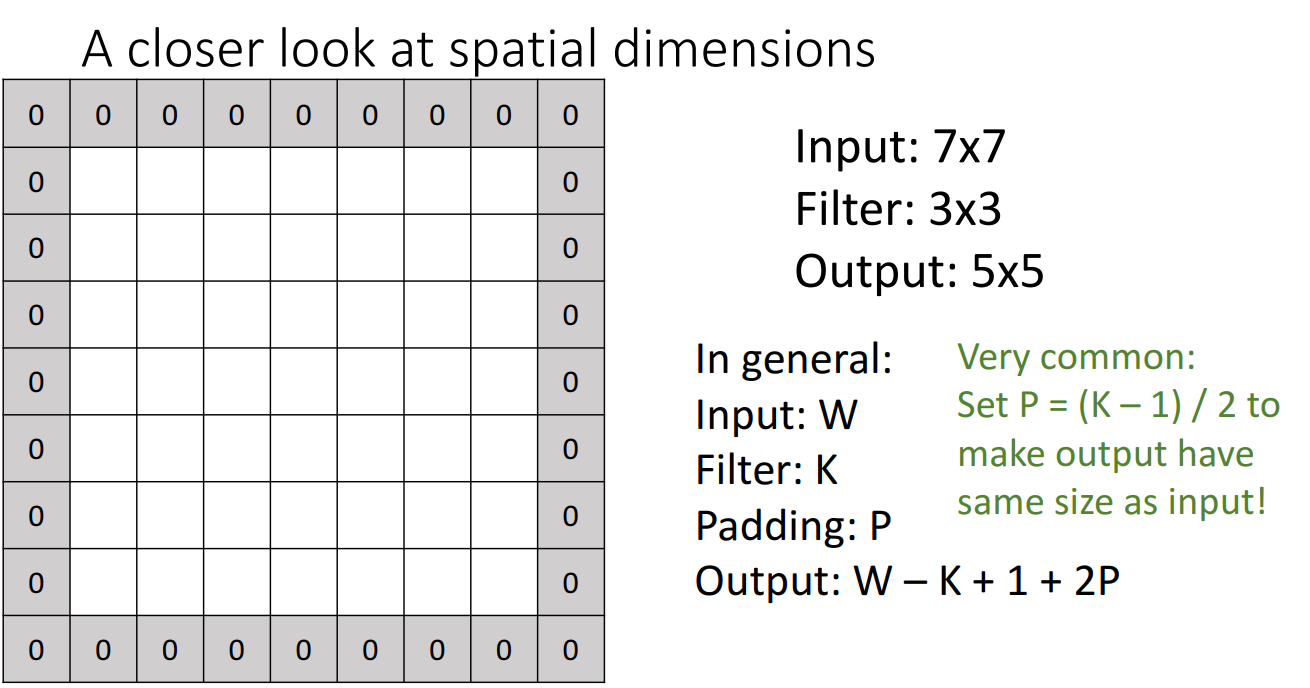
- 원본 이미지의 겉에 특정 숫자들을 둘러싼 뒤 필터가 해당 테두리들도 연산에 포함하도록 하여 Feature map의 크기를 줄어들지 않도록 하는 방법
- 일반적으로 0을 테두리에 두르는 Zero-Padding 사용
- 몇 겹으로 쌓는가 ?
- input 이미지와 같은 크기의 output activation map을 얻을 수 있도록 p = (k-1)/2 로 설정함
-
Receptive Fields이 줄어드는 문제:
- 입력 kernel size가 KxK 일때, 아웃풋인 activation map의 특정 하나의 픽셀은 input 이미지의 KxK receptive field에 의존
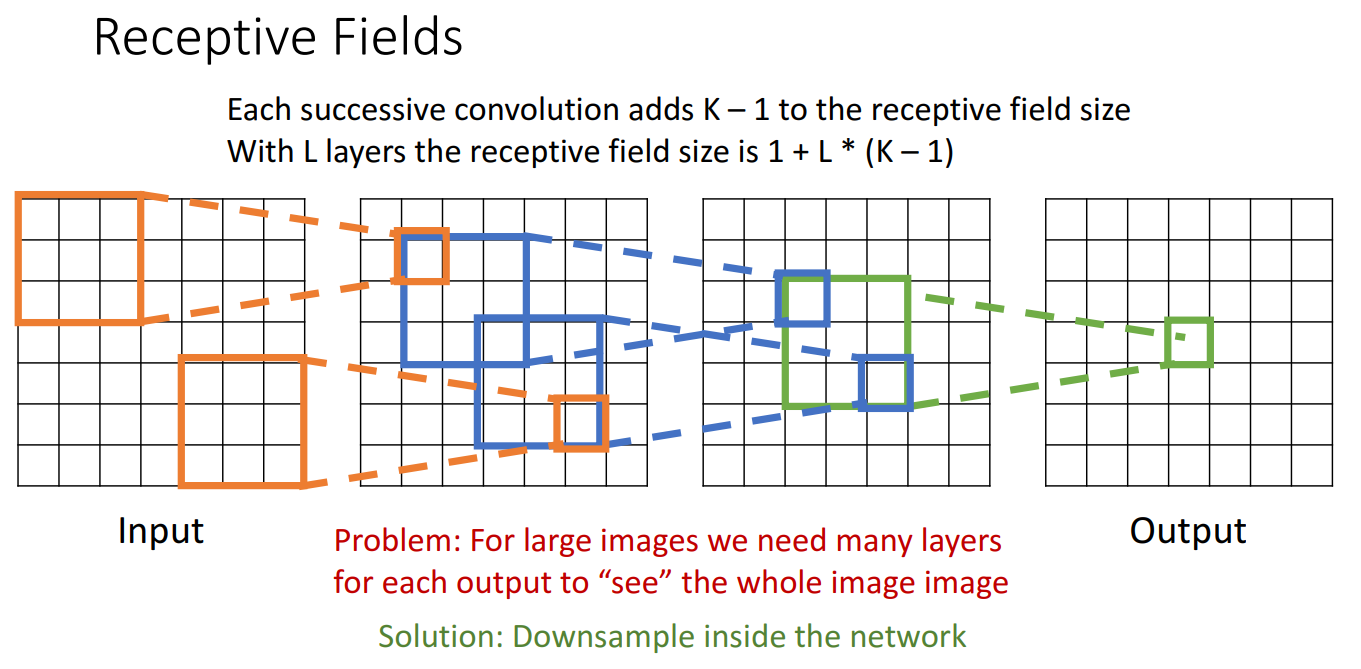
- 문제점: Output에서 global context 정보를 담기 위해서는 너무 많은 layers가 필요함. 특히 고해상도 이미지 상황
- 이를 해결하기 위해 Downsample 하는 방법이 고안 => 스트라이드 적용
- 입력 kernel size가 KxK 일때, 아웃풋인 activation map의 특정 하나의 픽셀은 input 이미지의 KxK receptive field에 의존
-
Stride ( 스트라이드 )
- 기존의 Conv filter는 한칸씩 이동하면서 activation map을 산출해냈지만, 두세칸씩 뛰어넘으면서 Conv filter를 거치면 Downsample 된다는 아이디어
-
계산 과정:
- 입력: Cin×H×W
- 출력: Cout×H'×W′
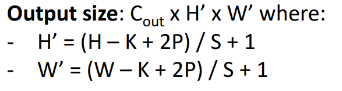
-
필터 크기, 패딩, 스트라이드에 따라 출력 크기 결정.
- Activation map 크기 결정하는 방법 : ( W - K + 2P ) / S + 1

- 추가로 학습해야할 파라미터의 개수:
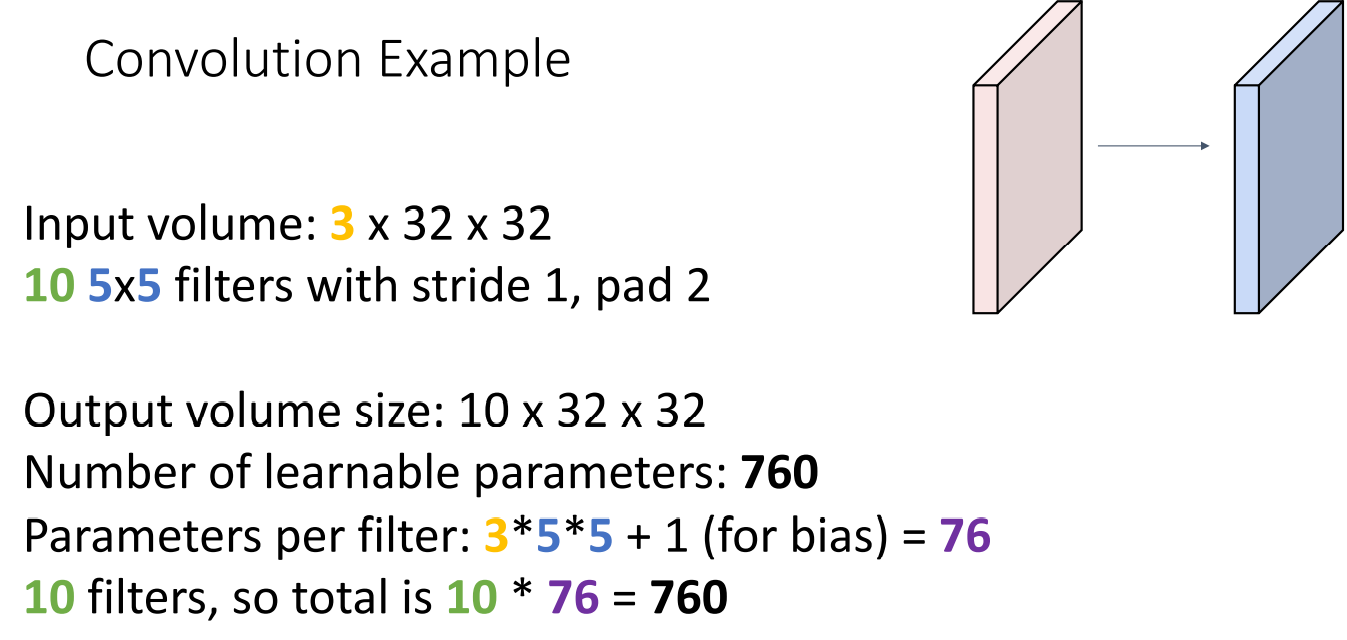
- 3∗5∗5+1 의 Dot product와 합 연산을 거쳐야 하고
필터의 개수는 10개 이므로 10∗76=760 의 파라미터를 학습
-
-
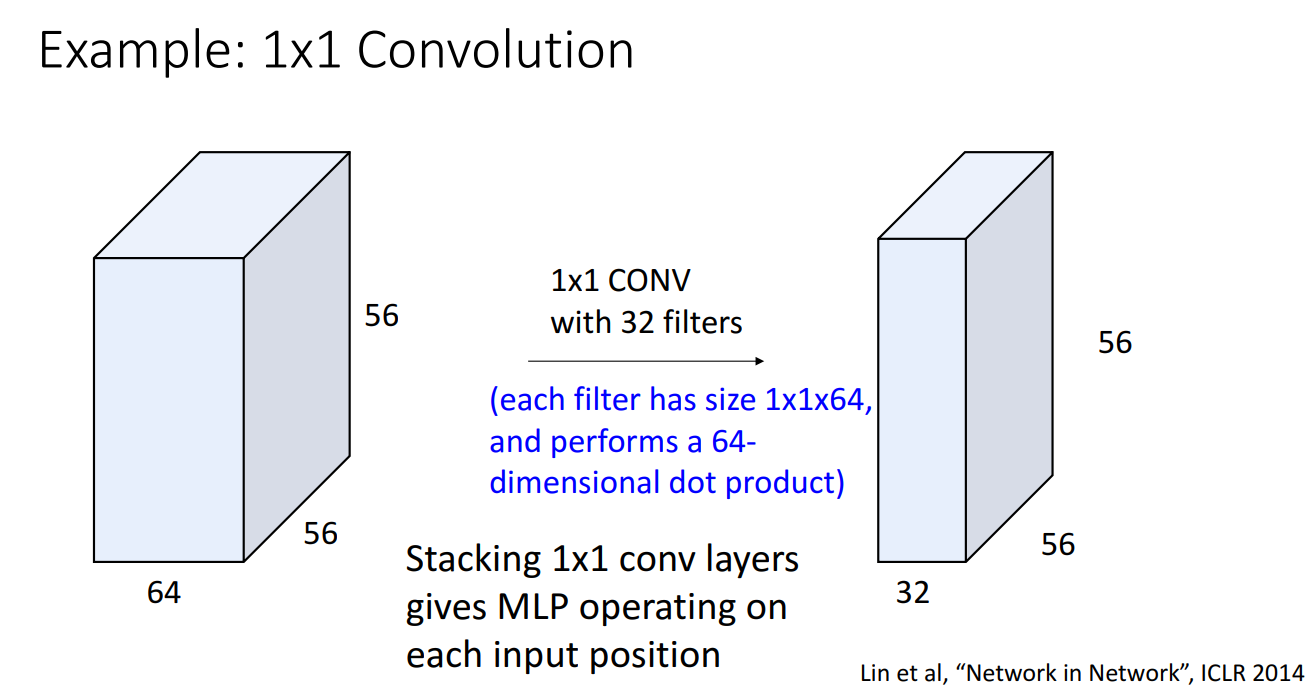
1x1 Convolution Filter
-
1x1 filter를 거치면 지역적 정보를 보는데 무슨 소용 ?
- 이는 MLP 와 유사한 역할을 수행하면서도 input 의 위치 정보를 해치지 않는다는 장점 => 여러 유명한 CNN 구조에서 잘 사용
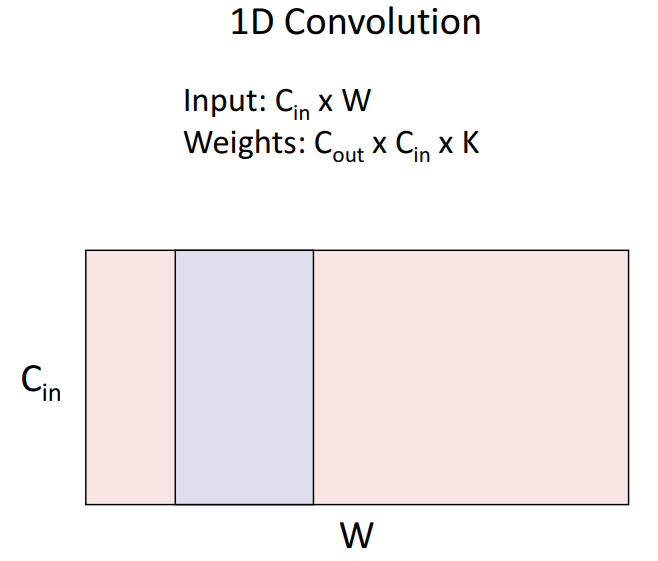
- Sequence 구조를 갖는 시계열 데이터, 오디오 데이터에서 큰 장점
- 이는 MLP 와 유사한 역할을 수행하면서도 input 의 위치 정보를 해치지 않는다는 장점 => 여러 유명한 CNN 구조에서 잘 사용
3. 풀링 층 (Pooling Layer)
-
Convolution Layer외 down sampling을 할 수 있는 다른 방법
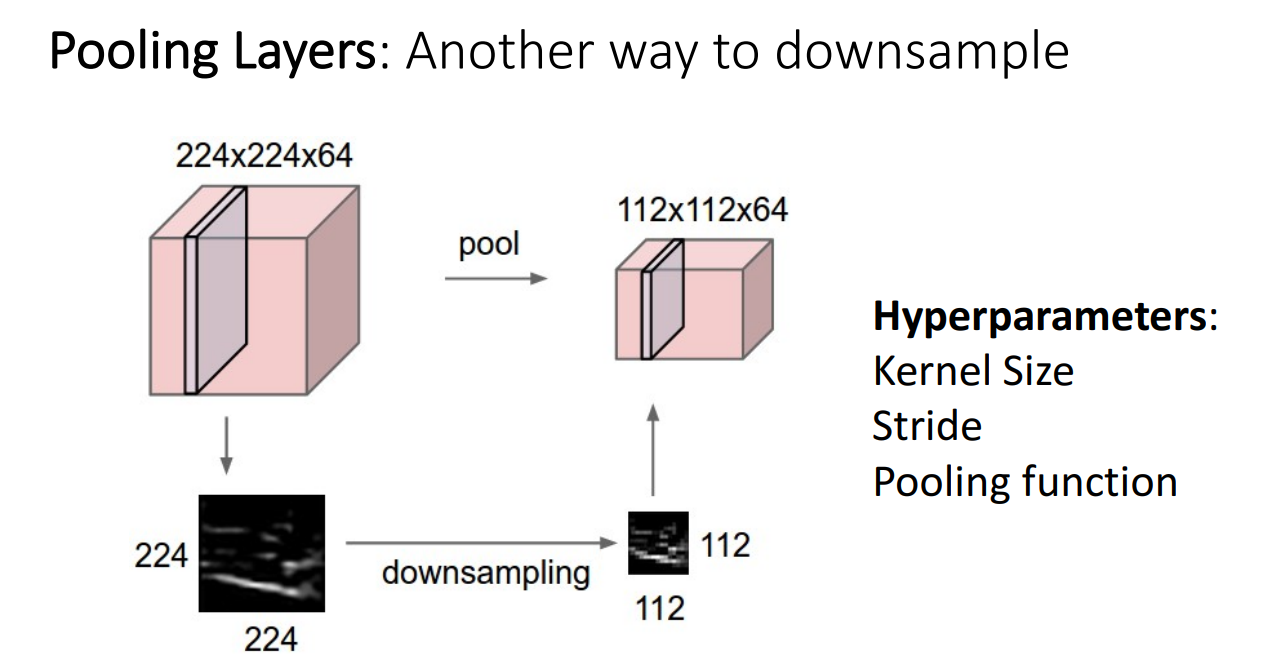
-
풀링 연산:
-
데이터의 차원을 축소하여 계산량 감소 및 특성의 위치 불변성 유지.
-
하이퍼파라미터: Kernel size, stride, pooling function
-
주로 사용되는 방식: Max Pooling, Average Pooling
-
Max Pooling : kernel size 크기에 맞춰서 해당 크기 안에 가장 큰 값만을 다음 층으로 보내는 함수
- 계산 방법 :
- 입력: C×H×W
- 출력: C×H'×W'
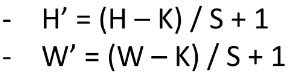
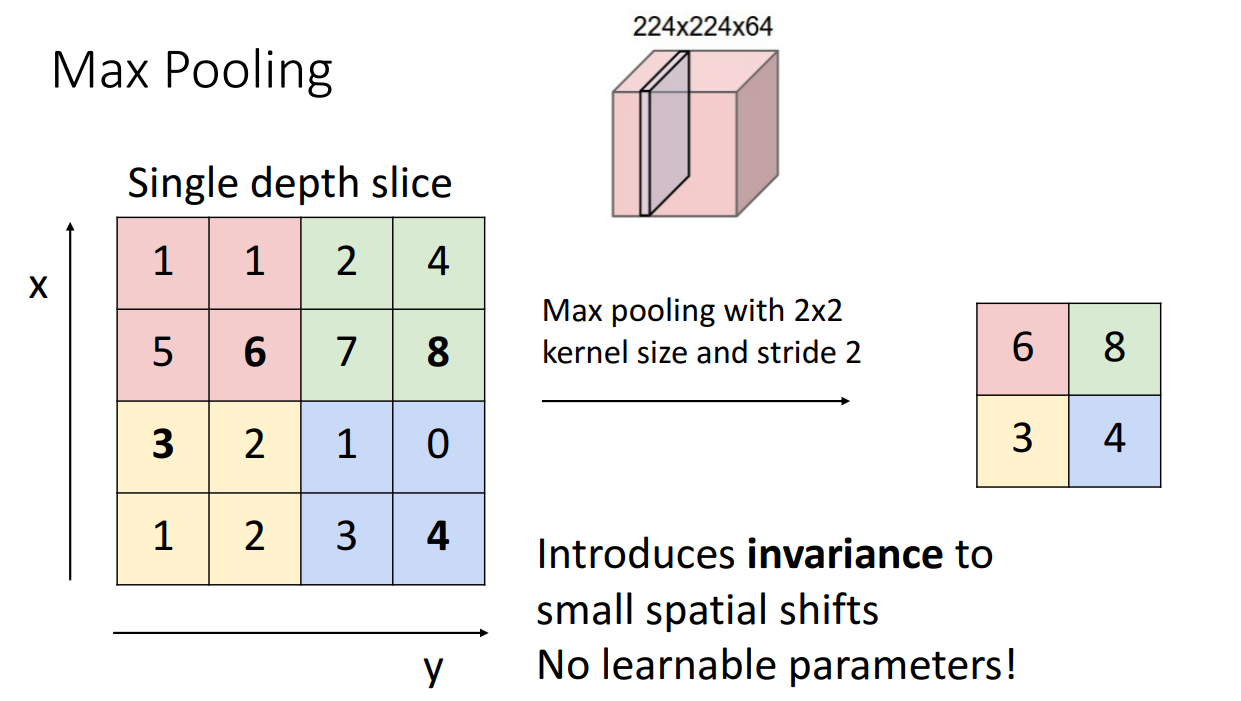
- 계산 방법 :
-
-
ex) 1998년에 제안된 CNN 구조인 LeNet-5
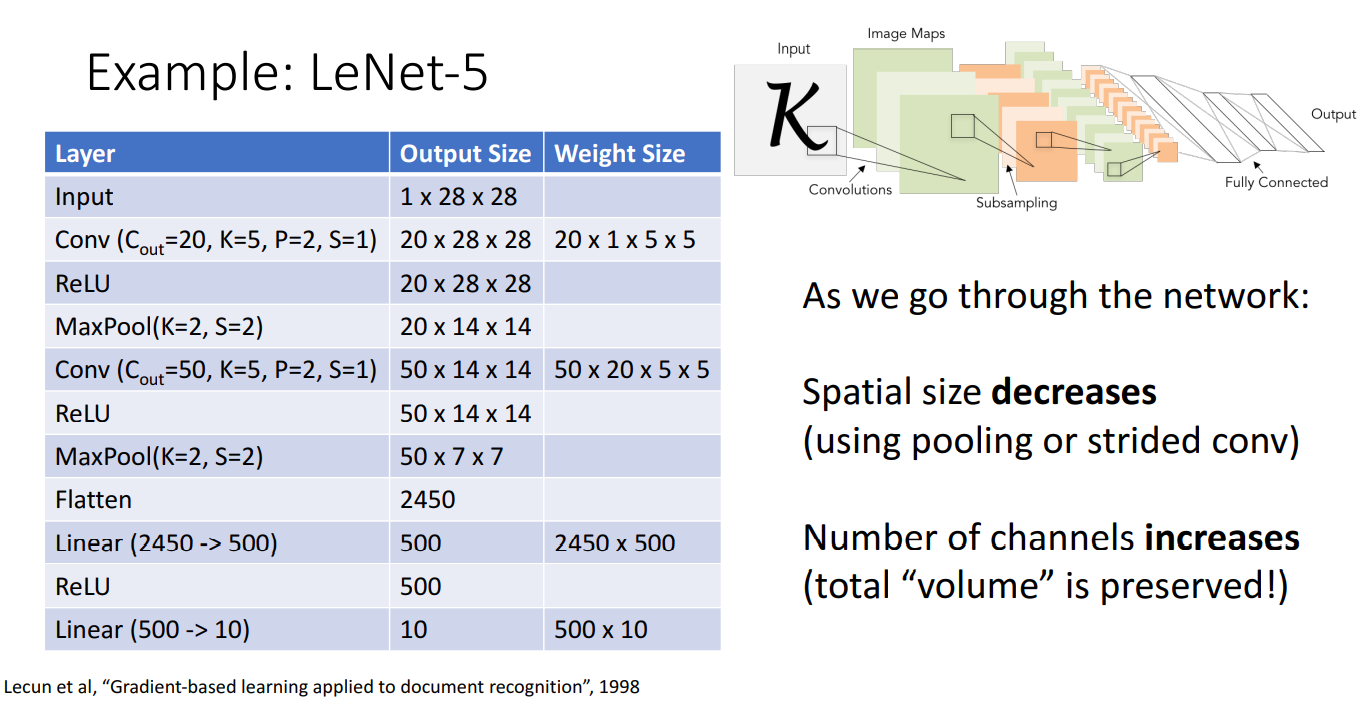
- 문제점 :
- Pooling Layer와 Strided Conv layer 를 거치면서 Spatial Size가 너무 작아지게 됨
- 처음에 Grayscale이었던 Channel이 엄청나게 늘어나게 됨
- 이렇게 될 경우 네트워크가 학습되기 어렵
4. 정규화 (Normalization)
- 아이디어: Layer의 output을 평균이 0, 분산이 1이 되도록 정규화
- 효과: internal covariate shift( 신경망의 각 층에서 입력 데이터의 분포가 계속해서 변하는 현상 )를 줄여서 최적화가 잘되도록 함
- 정규화 시키는 함수는 미분가능한 함수 => 네트워크 학습시 역전파시켜서 연산할 수 있음 ( 손실함수의 기울기를 각 층에 전달, 모델의 가중치가 업데이트 될 수 있도록 함 )

- 배치 정규화 (Batch Normalization):
- 학습 과정에서 각 층의 출력을 정규화하여 학습 속도 향상 및 안정화
- 문제점 1) : 평균을 0, 분산을 1로 정규화하는 과정이 어렵
- 해결 ) : Learnable scale, shift parameters를 도입해서 이를 학습하도록 함

- 문제점 2) : 미니배치별로 정규화를 수행하기 때문에 Train 과정에서나 학습되지 Test 과정에서는 미니배치별로 예측을 수행하지 않기 때문에 사용할 수 없음
- 해결 ) : 학습하는 대신 Fixed Scalar 값을 사용

- 채널을 건드리지 않고 배치별로 하나씩 정규화 됨을 확인
- 보통 가중치가 적용되는 층 ( FC layer나 Conv layer ) 다음에, 활성화 함수 적용하기 전에 적용
- 장점: 학습시키기 쉬워지고, 높은 학습률도 커버 가능하며, 더 빠르게 수렴
- 단점: 아직 이론적으로 완벽하게 왜 좋은지 증명 안됨, 학습과 추론시에 다르게 작동해서 버그가 자주 일어남
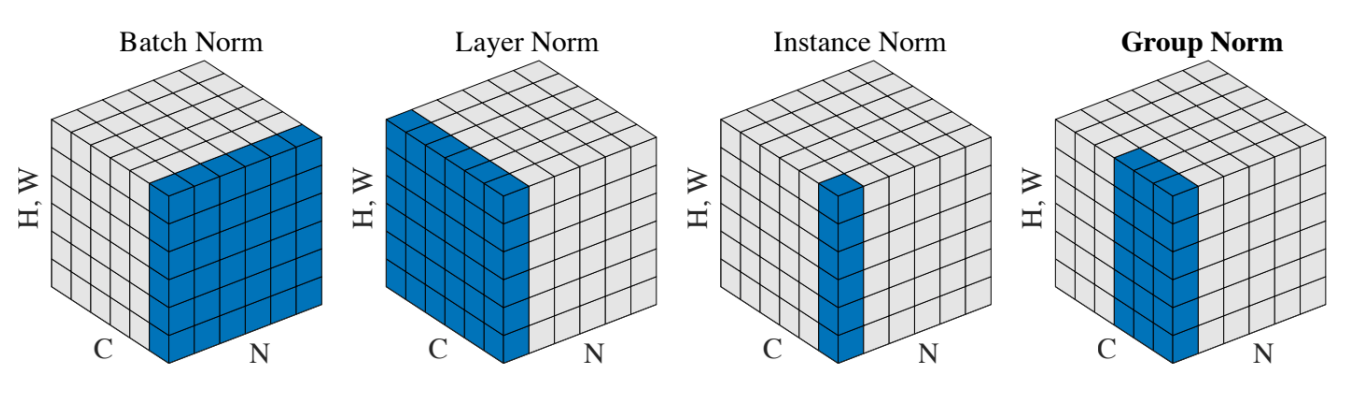
- 레이어 정규화 (Layer Normalization):
- 레이어 전체를 정규화. 즉, 각 샘플의 모든 뉴런들에 대해 평균과 분산을 계산하여 정규화
- 인스턴스 정규화
- 인스턴스(샘플) 내의 각 채널을 정규화 - 그룹 정규화
- 인스턴스(샘플) 내의 채널을 그룹으로 나누어 정규화
CNN Architectures
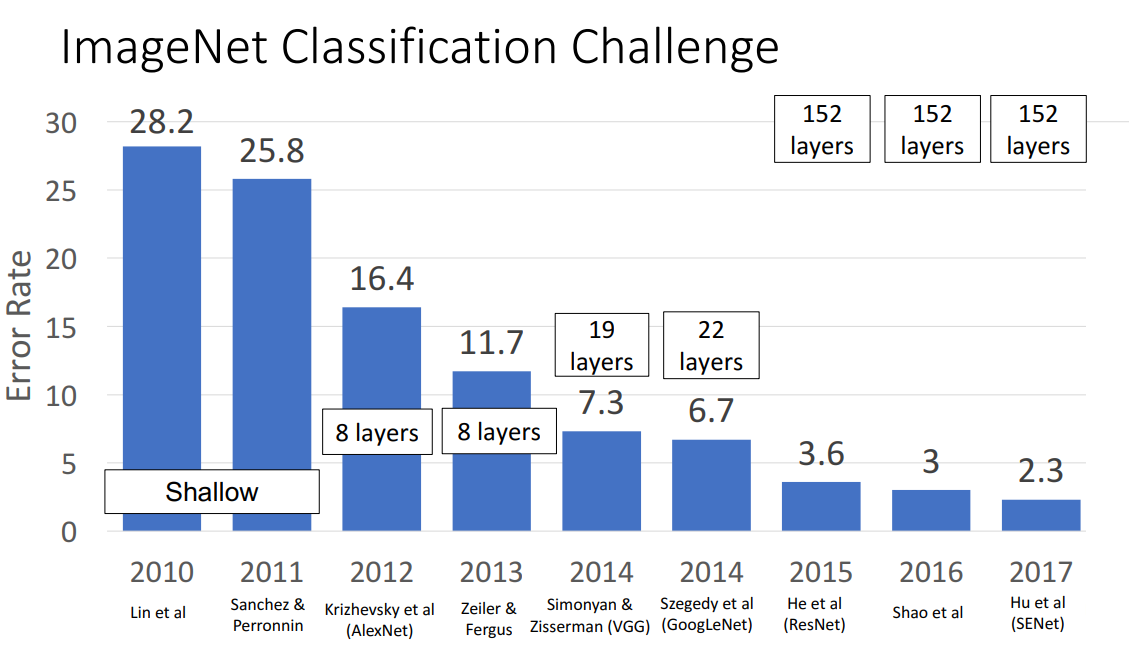
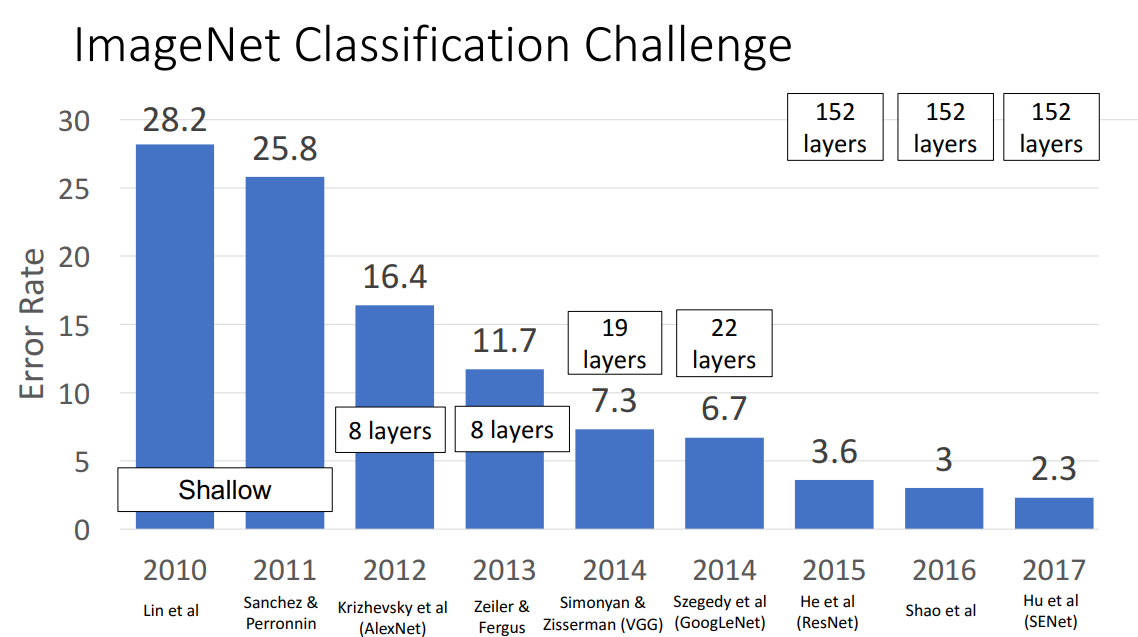
ImageNet Classification Challenge
- CNN 구조의 모델들이 얼마나 이미지 분류를 잘해왔는지 살펴보기 위해 2010년부터 매년 열려왔던 ImageNet Classification Challenge 확인
- ImageNet Dataset: 1.2 million 정도의 이미지와 1000개의 Class를 지닌 거대한 데이터셋
AlexNet
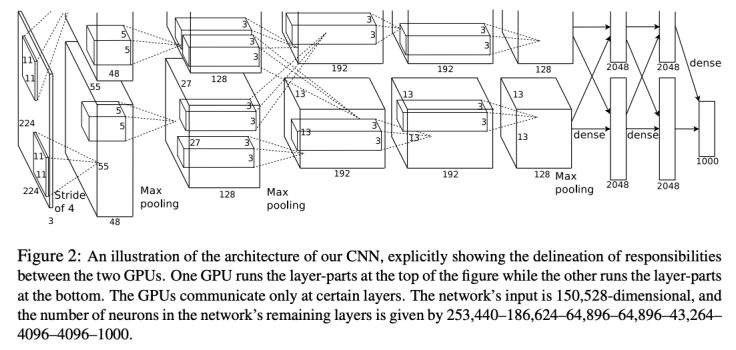
AlexNet은 2012년 ImageNet 대회에서 혁신적인 성과를 거둔 모델로, CNN의 대중화를 이끌었음.ReLU 비선형 함수를 처음 사용한 CNN 구조가 특징
- 구성요소: 5개의 Convolutional Layer와 3개의 Fully-Connected Layer로 구성됨. 각 층 사이에 ReLU 활성화 함수가 사용
-
특징:
- 필터 크기(11x11)와 높은 스트라이드(4)를 통해 연산 효율성을 높임. 두 개의 GTX 580 GPU를 사용해 병렬 학습을 수행함.
- Local response normlization 이라는 정규화 기법을 사용했지만 현재는 Batch Normalization 주로 사용
- 2019년 기준 약 46000 정도의 인용 ( 찰스 다윈의 '종의 기원'이 50000 정도의 인용 )
- AlexNet의 위와 같은 구조는 Trial-and-error 방식으로 찾은것임
- "trial-and-error 방식": 최적의 신경망 구조와 하이퍼파라미터를 찾기 위해 반복적으로 설정을 조정하며 실험
-
연산량:
- 앞으로 나오는 CNN 모델들이 Floating point operations(연산량)을 얼마나 효율적으로 줄였는지에 대해 Contribution으로 내세우기 때문에 중요
- CONV Layer 연산량 :


- Pooling Layer 연산량 :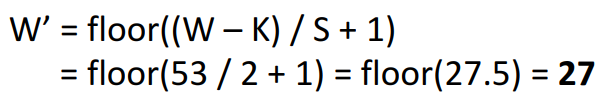
이러한 이유로 풀링 레이어의 아웃풋 H/W 값이 27이 됨


-
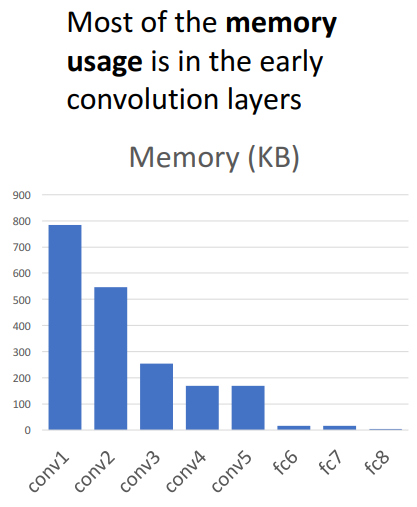
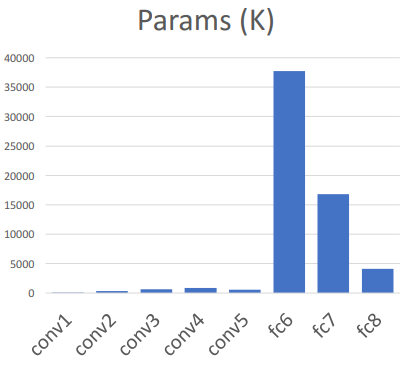
AlexNet 구조의 모습과 Memory 사용량, 학습해야할 Parameter 수, 연산량에 대한 표:
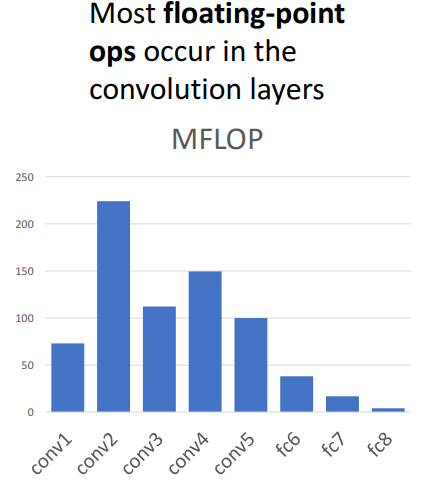
-
메모리 사용량: Conv layer가 가장 많고 그리고 초반 Conv layer가 가장 많음
- 초반 Conv layer가 다루는 이미지가 고해상도이기 때문
-
학습해야할 파라미터 수: FC layer가 가장 많음
- FC layer는 Weight matrix를 학습해야하는데 이미지를 Flatten 시켰기 때문에 가중치 행렬이 커서 학습 파라미터의 수가 많음 -
연산량: Conv layer가 많음
- 고화질 상황에서 여러 개의 필터를 사용하다보니 연산량이 커짐 -
성과: 당시 최신 기술보다 현저히 낮은 오류율을 기록하여 CNN의 가능성을 입증함.
ZFNet
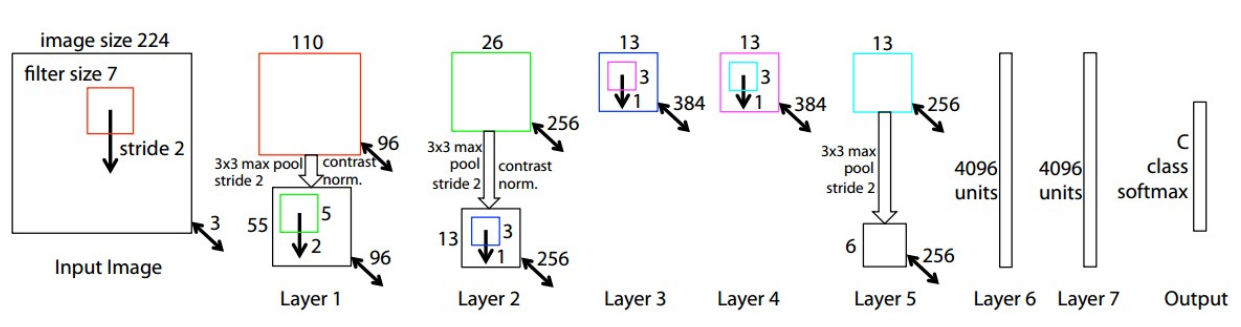
- ImageNet Classification Challenge의 2013년 우승자
- Imagenet top 5 error : 16.4% => 11.7%
- AlexNet의 구조를 개선하여 첫 번째 합성곱 층에서 필터 크기와 스트라이드를 줄이고, 3~5번째 합성곱 층에서 필터 수를 늘린 신경망
VGG
ImageNet Classification Challenge 2014년 우승자는 아니었지만, 우승자보다 더 많은 관심을 받은 모델
- Alexnet과 Vgg와의 비교


- 특징: 수작업 trial-and-error 방식에서 벗어나 일관된 설계 원칙 정립
- VGG 모델의 연산량은 AlexNet보다 19배 더 많아, 훨씬 거대한 네트워크 구조를 형성
- 일정한 크기의 필터를 사용하지만 Stage가 증가할 때마다 필터의 개수를 2배로 증가 - 구조 : conv-conv-pool 구조를 반복하는 Stage로 구성
- 풀링 레이어: Pool layer는 2x2 stride 2의 max pooling을 사용.
- Conv Layer 사용 방식: Nonlinear function 없이 Conv layer를 겹쳐서 사용하며, 작은 필터(3x3)를 여러 개 겹쳐 사용하여 연산량 최적화
- 채널 수 증가: Max pooling 이후 채널 수를 2배로 증가시켜 연산량 균형 유지
GoogLeNet
GoogLeNet은 "효율적인 컴퓨팅"을 목표로 설계된 네트워크임.
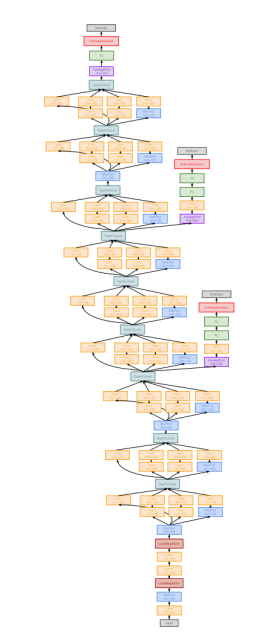
-
특징: Inception 모듈을 도입하여 여러 크기의 필터를 동시에 사용, 1x1 "Bottleneck" 레이어를 사용해 파라미터 수와 연산량을 줄임.
-
구조 :
- Aggressive Stem: 네트워크 초반에 원본 이미지 크기를 downsample하여 연산량 감소
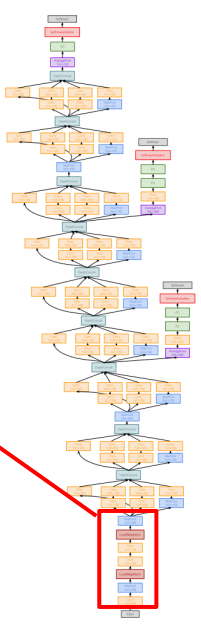
- Inception Module: 병렬적으로 다양한 크기의 필터를 사용하고, 1x1 Bottleneck Conv 계층을 연산량이 많은 Conv 계층 전에 삽입해 연산량 감소.( 발표때 박스치기 )
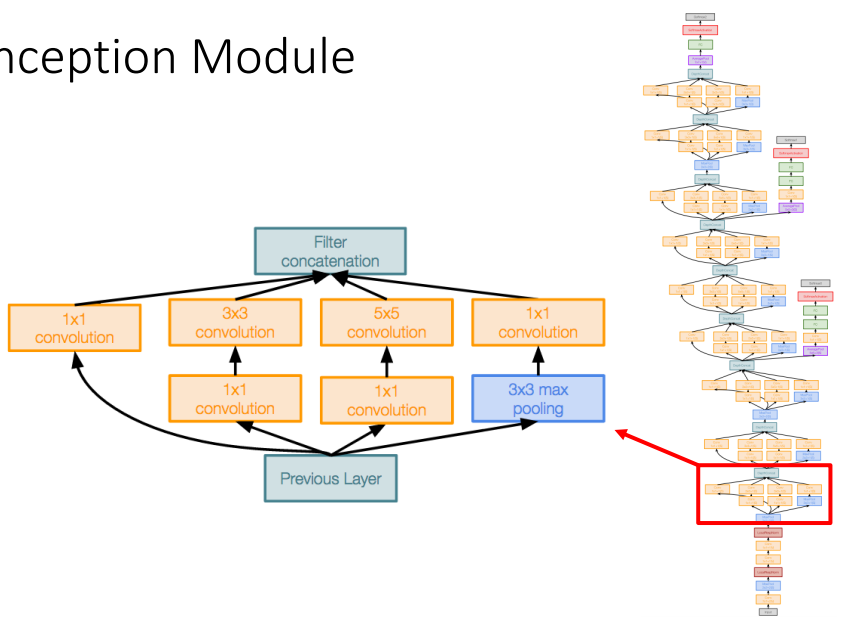
- 1x1 "Bottleneck" 레이어 역할:
- 입력 데이터의 채널 수(깊이)를 줄여서 전체 연산량을 줄이면서 필요한 정보 유지
- 예를 들어, 입력이 256개의 채널을 가지고 있다면, 64개의 1x1 Conv 레이어를 사용하여 이를 64개 채널로 줄일 수 있음

- Global Average Pooling: FC Layer 대신 Global Average Pooling을 사용하여 연산량 감소
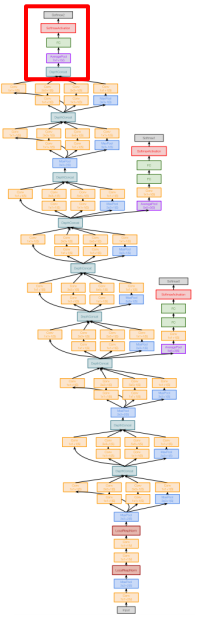
- Auxiliary Classifiers: 중간중간 분류 작업을 수행해 학습 속도와 정확도 개선.
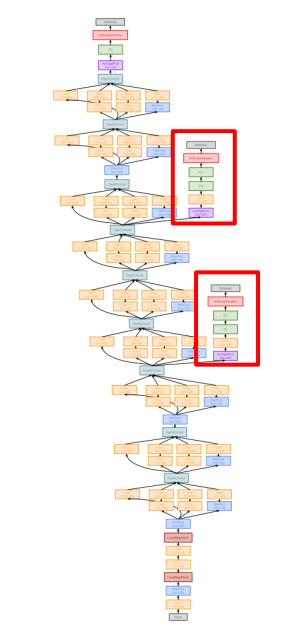
- 기존 문제점 : 깊은 모델에서는 파라미터들을 학습하기 위해 Gradient를 순전파, 역전파하는 과정이 어렵 => 해결법 : 네트워크의 중간 출력값을 사용하여 예측을 수행
- 주의점 : Auxiliary Classifiers를 사용하려면 BatchNorm 피하기
- BatchNorm 적용된 층에서는 이 중간 출력값들이 정규화 과정을 거치기 때문에, Auxiliary Classifier가 참조하는 값이 원래 의도된 값과 크게 달라짐
- WHY ? : BatchNorm이 입력 데이터를 정규화하여 각 층의 활성화값이 일정한 분포를 따르도록 만들기 때문
- BatchNorm은 각 미니배치에서 활성화값의 평균과 분산을 계산해 활성화값의 분포를 표준화(평균 0, 분산 1)
- 주의점 : Auxiliary Classifiers를 사용하려면 BatchNorm 피하기
- Aggressive Stem: 네트워크 초반에 원본 이미지 크기를 downsample하여 연산량 감소
ResNet
-
특징: ImageNet Classification Challenge 2015년 우승 모델로, ILSVRC, COCO 등 다양한 이미지 분류 대회에서 최고 성적을 기록
-
Deep 모델의 문제점 해결: 깊은 네트워크 구조의 학습 어려움을 해결하기 위해 Residual Learning 도입, 깊은 모델임에도 불구하고 효율적인 학습이 가능
- Batch Normalization 발견 후 사람들은 그동안의 네트워크 구조보다 훨씬훨씬 깊은 네트워크를 쌓으려고 노력
- 하지만 성능 안좋음. 더 많은 레이어를 쌓았는데 성능이 안좋다는 것은 오버피팅아닐까? 라고 생각함
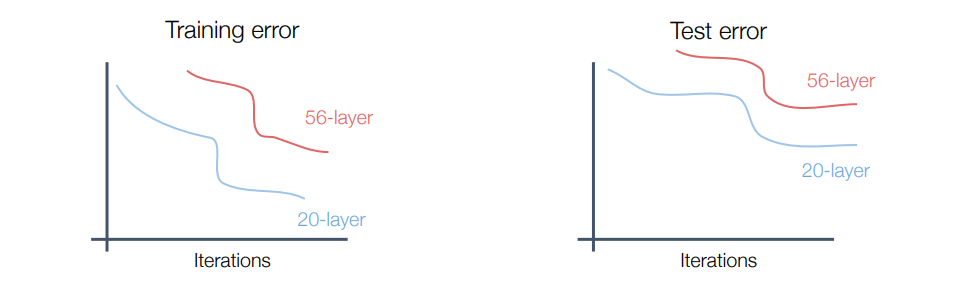
- 하지만 확인해보니 애초에 학습이 잘 안되는 언더피팅임을 확인
- Deep한 모델이 Shallow한 모델을 모방해보는 것은 어떨까라는 아이디어에서 시작
-
구조: Residual Block을 반복하여 깊이 있는 네트워크 구조 형성.
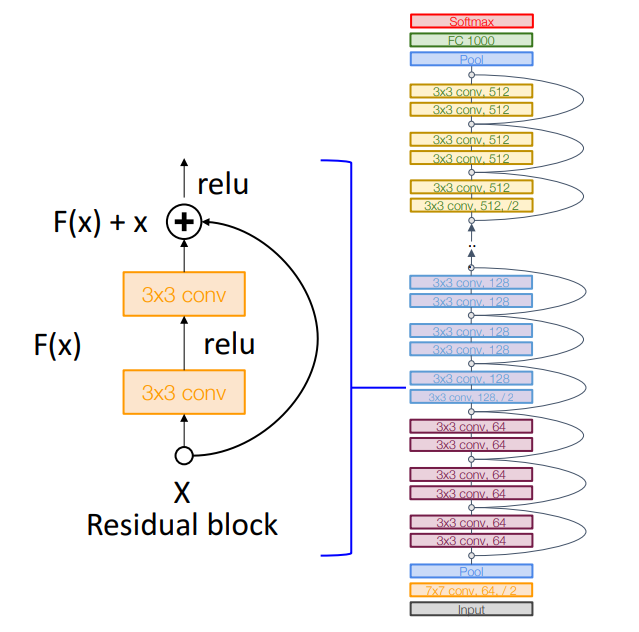
-
Additive Shortcut: 기존 Conv Block에 Additive "shortcut"을 추가하여, Identity Function 학습이 가능하도록 구성.
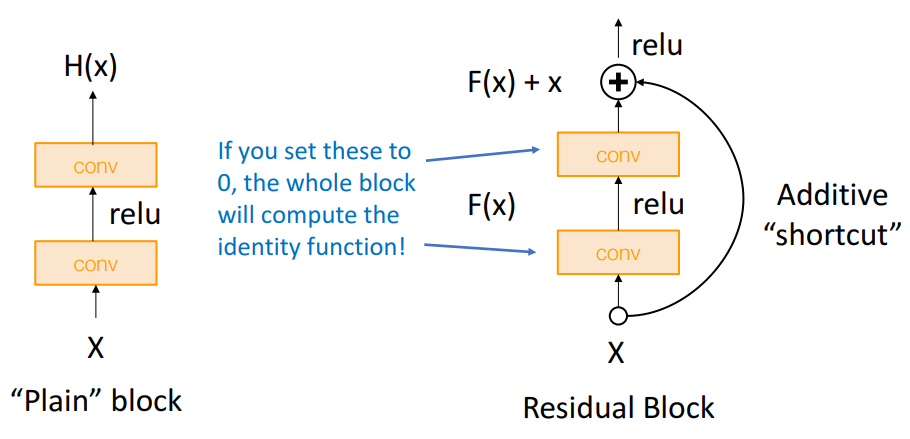
-
Global Average Pooling: GoogLeNet처럼 Global Average Pooling을 사용하여 연산량을 줄임.
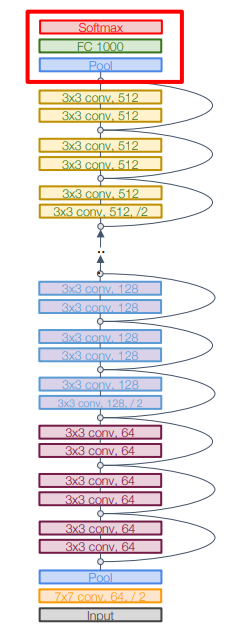
-
aggressive stem : GoogLeNet처럼 네트워크 초반에 이미지를 다운샘플링하여 연산량 감소
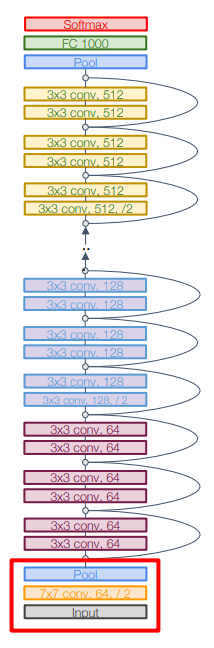
-
모델 제안: 다양한 깊이의 모델(ResNet-50, ResNet-101, ResNet-152) 제안, 깊이에 따라 성능과 연산량의 Trade-off 존재 (1개의 Residual Block은 2개의 Conv Layer으로 이루어짐)
-
Bottleneck Residual Block: 1x1 Conv를 사용해 채널 수를 조정하고 연산량을 줄이며, 비선형성을 증가시킴.


-
Resnet-50은 Basic blocks을 Bottleneck Blocks으로 변경한 형태이며 지금까지도 baseline 아키텍쳐로 사용중

-
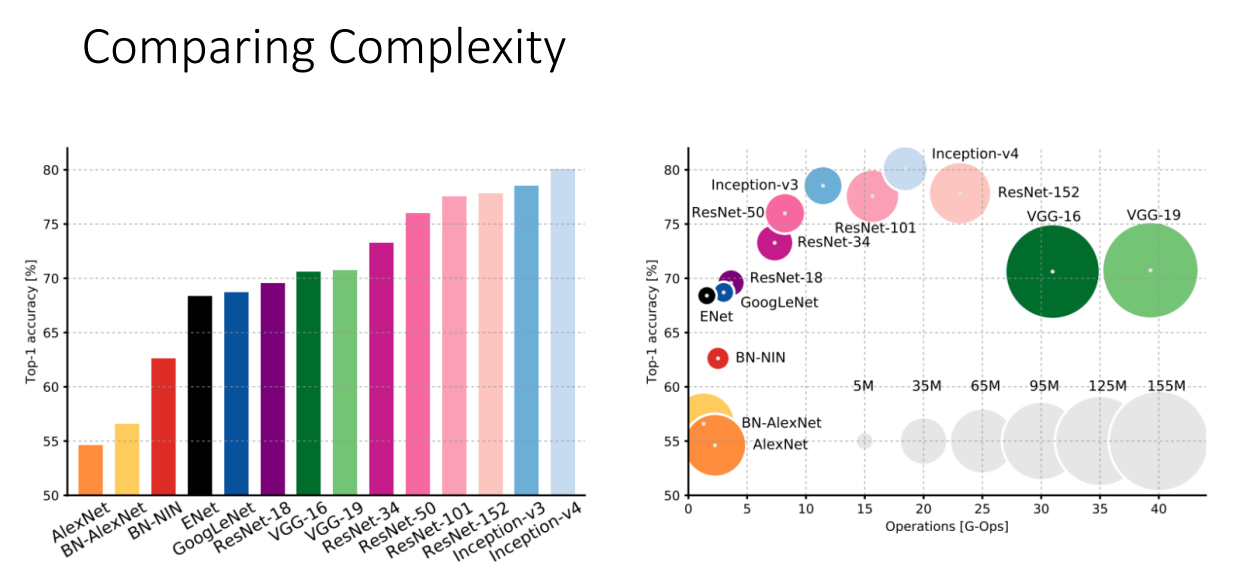
지금까지 살펴본 모델들의 성능과 복잡성
ResNet이 확실히 상대적으료 효율적이면서 가장 좋은 성능
ResNeXt
- 특징: ResNet의 성공을 기반으로 G개의 병렬적인 Residual Block을 사용한 모델.
- Grouped Convolution을 사용하여 연산량을 유지하면서도 더 나은 성능 달성.
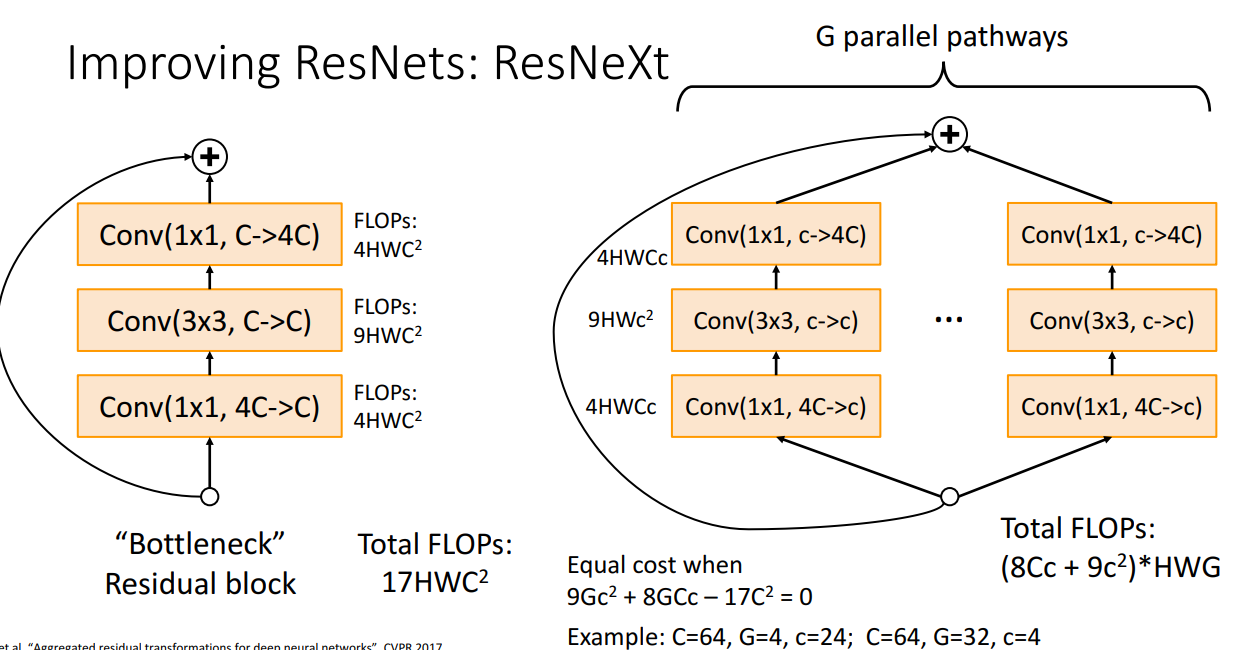
![]
- Grouped Convolution을 사용하여 연산량을 유지하면서도 더 나은 성능 달성.
- Grouped Convolution: 입력 채널을 여러 그룹으로 나누어 각각 독립적으로 합성곱 연산을 수행 => 전체 연산량 줄어듬
- 예) groups=2 일때 2개의 병렬적인 레이어
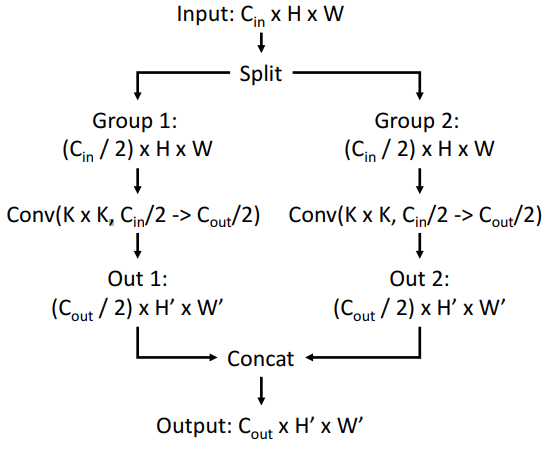
K는 필터의 크기

그룹을 추가 할수록 연산량 유지하면서 성능 올림 확인 가능
- 예) groups=2 일때 2개의 병렬적인 레이어
Squeeze-and-Excitation Networks (SE Networks)
-
SE Networks는 기존의 ResNet 같은 네트워크 구조에 Squeeze-and-Excitation(SE) 모듈을 추가하여 성능을 향상시킨 모델
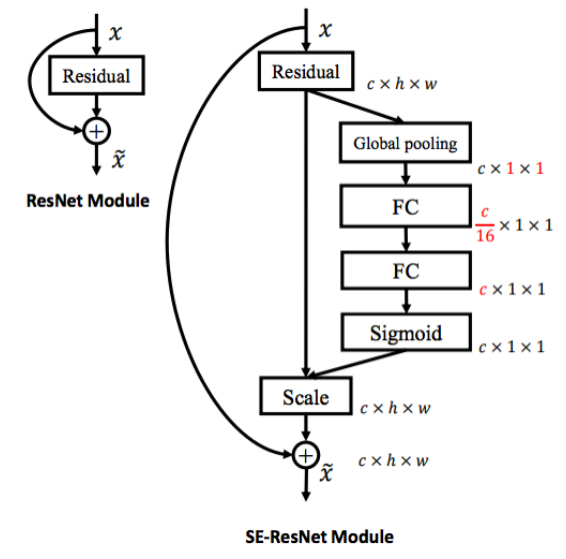
이 이미지의 왼쪽에는 일반적인 Residual Block -
SE 모듈의 주요 개념과 동작:
- Residual Block:
- 입력과 출력의 합을 취해 잔차를 학습하는 블록으로, 출력은 SE 모듈로 전달
- Global Pooling:
- Global Average Pooling을 수행 : 입력 특징 맵 X는 C H W 크기에서 C 1 1 크기로 축소
- Squeeze 단계:
- 축소된 C×1×1 벡터는 Fully Connected 레이어를 통과하며, 이때 채널 수를 축소함.
- 그림에서 C / 16 로 채널 수를 줄임. 이는 채널 간의 중요한 관계를 압축해 표현하는 역할
- Excitation 단계:
- 또 다른 Fully Connected (FC) 레이어를 통해 채널 수를 다시 원래 크기 C×1×1로 확장
- 이때 Sigmoid 활성화 함수가 적용되어, 각 채널에 대한 중요도(가중치)를 계산
- 채널 중요도 반영(Scale 단계):
- Sigmoid 함수를 거쳐 계산된 가중치는 원래의 특징 맵에 곱해져서, 각 채널별로 중요도가 반영된 특징 맵이 생성
- 특정 채널이 더 중요하게 강조될 수 있으며, 덜 중요한 채널은 억제
- Residual 연결:
- SE 모듈에서 나온 출력은 다시 Residual Block의 원래 출력과 더해져 최종 출력 생성
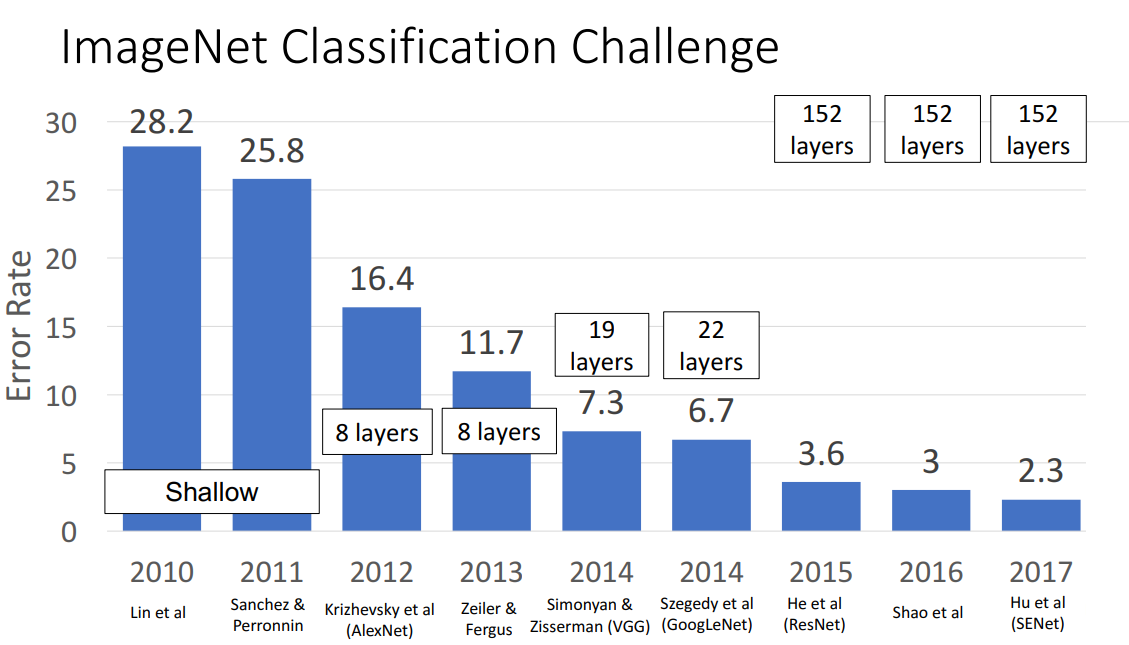
이후에는 ImageNet Classification Challenge가 중단됨
- Residual Block:
MobileNets & ShuffleNet
- 경량화 모델: 성능보다 효율성에 중점을 둔 경량화 모델.
- Depthwise Separable Convolution: MobileNets에서 사용되는 주요 기법으로, 연산량을 크게 감소시킴.
- 효율적 설계: 성능을 유지하면서도 가벼운 모델을 목표로 함
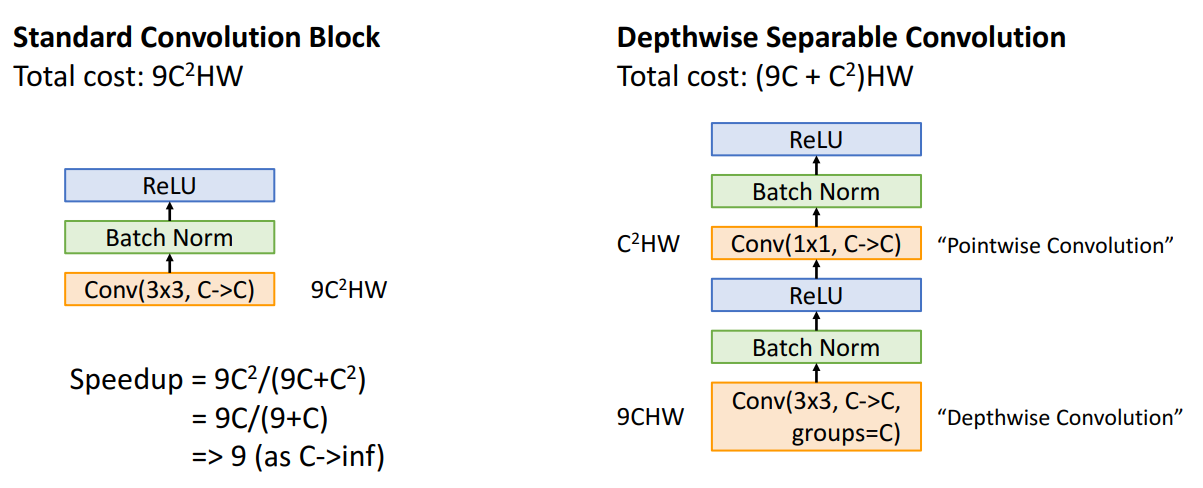
- Depthwise Convolution: 각 입력 채널에 대해 개별적으로 합성곱을 수행하며, 그룹의 수는 입력 채널 수(C)와 동일이 과정에서는 채널 간의 상호작용 X
- Pointwise Convolution: 1x1 크기의 필터를 사용하여 1x1 필터는 입력 텐서의 한 위치에서 모든 채널에 대해 가중합을 계산을 해 새로운 출력 채널을 생성 => 채널 간의 상호작용 만듬. 이는 입력 채널을 C에서 C로 변환
- 채널 간의 정보 결합을 통해 새로운 특징을 생성하는게 목적
- 질문 : 1x1 필터는 입력 텐서의 한 위치에서 모든 채널에 대해 가중합을 계산하는 것인데 어떻게 채널 차원에서의 복잡성을 처리할 수 있는거야?- 연산량 측 출력은 H×W×Cout 크기의 텐서.
- 1x1 Convolution은 각 입력 위치에서 모든 채널에 대해 가중합을 계산하여 출력 채널 수(Cout)를 만듬. Cout은 1x1 필터의 개수에 비례
- 1x1 Convolution을 사용하면 Cout(출력 채널 수)를 줄일 수 있기 때문에, 결과적으로 연산량도 줄어듬
Neural Architecture Search (NAS)
- 구조 자동화: 네트워크 구조 설계 과정을 자동화하는 방법론으로, 연산 자원이 많이 필요하지만 새로운 구조를 탐색 가능.
CNN 아키텍쳐 발전 총정리
- 초기 연구 (AlexNet -> ZFNet -> VGG): 초기 연구들은 더 큰 네트워크가 더 좋은 성능을 보인다는 것을 보여줌
- GoogLeNet: GoogLeNet은 효율성에 집중한 최초의 모델 aggressive stem, 1x1 bottleneck convolutions, FC 레이어 대신 global avg pool등을 특징으로 함
- ResNet: ResNet은 매우 깊은 네트워크를 훈련할 수 있는 방법, 네트워크가 커질수록 성능 향상이 줄어드는 현상 보임
- ResNet 이후: 효율적인 네트워크가 중심이 되었으며, 복잡성을 증가시키지 않고 어떻게 정확도를 향상시킬 수 있을지에 대한 연구가 이어짐
- 작은 네트워크: 모바일 장치를 겨냥한 작은 네트워크들이 등장함.대표적으로 MobileNet, ShuffleNet
- Neural Architecture Search (NAS): NAS는 아키텍처 설계를 자동화할 수 있는 가능성을 제시
아키텍쳐 선택 가이드
성능이 필요하다면 ResNet, 속도가 필요하다면 MobileNet, ShuffleNet
[PT Lecture Review] 발표한 자료는 아래와 같습니다

발표자료 :
참고 강의:
