주요 내용 :
- Neural Networks를 학습하기 위한 기법들
- Activation Functions
- Data Preprocessing
- Weight Initialization
- Regularization
Overview

- 이번 강의는 신경망을 학습할 때 더욱 잘 학습하기 위해서 사용하는 추가적인 기법들에 대한 내용을 포함하고 있음
Activation Functions
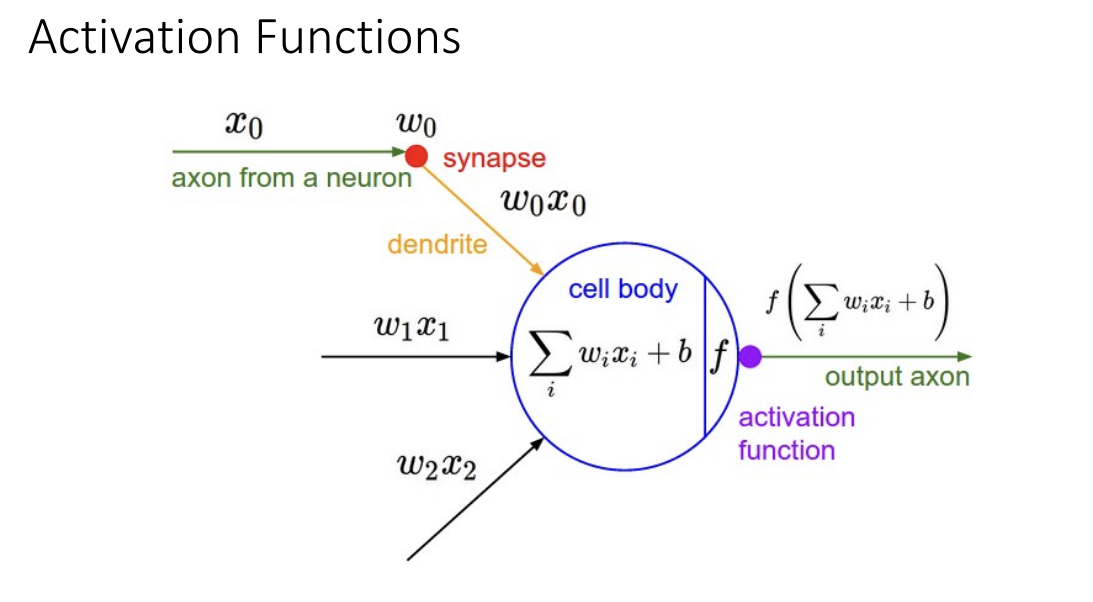
- 비선형 활성화 함수를 추가하는 것이 일반적
활성화 함수의 주요 목적: 뉴런이 활성화되거나(발화) 비활성화되지 않도록 결정하는 것
- 활성화 함수의 종류

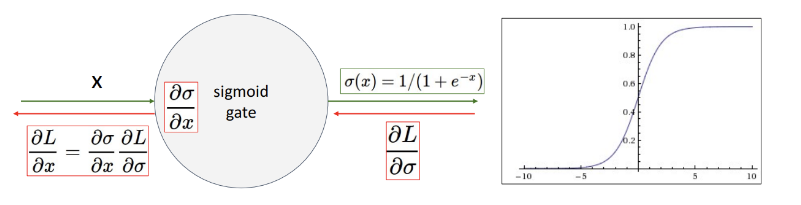
시그모이드 함수
-
시그모이드는 함수는 input 값을 0과 1 사이의 값으로 바꿔주는 역할(뉴런의 활성화를 결정 = 뉴런이 발화(firing)할 확률)

-
문제점 3가지 존재
-
1) Gradient Vanishing 문제
- 시그모이드 함수는 입력이 매우 크거나 매우 작은 값일 때(즉, 0 또는 1에 가까울 때) 함수의 기울기가 매우 작아짐
- 기울기가 매우 작다는 것은 역전파 과정에서 기울기 소실이 발생할 수 있음을 의미
- 역전파는 모델의 가중치를 업데이트하는데 기울기를 사용하므로, 기울기가 작아지면 가중치 업데이트가 거의 이루어지지 않음 => 네트워크 학습이 멈추는 문제가 발생 가능
-
2) Zero-Centered 문제
-
시그모이드 함수의 출력은 항상 0에서 1 사이에 있으므로, 결과적으로 출력이 0이 아닌 0.5를 중심으로 집중
-
뉴런의 출력이 0이 아닌 0.5를 중심으로 하면 기울기 업데이트가 양수 또는 음수로만 이루어짐( Downstream gradient가 항상 Positive 혹은 Negative 값만 같도록 최적화가 이뤄진다는 점 )
-
시각적으로 표현해보면 아래 그림처럼 지그재그
-

-
기울기 업데이트가 비효율적으로 작동하며 학습 과정이 비효율적으로 진행
-
Minibatch를 사용해서 어느 정도는 완화
-
-
3) 계산 비용 문제
- 시그모이드 함수는 지수 함수(exponential function)를 사용하기 때문에 계산 비용이 상대적으로 큼
- 신경망 학습에서 매번 지수 함수를 계산하는 것은 계산량이 많아 학습 속도가 느려질 수 있음
-
tanh 함수
- Zero-Centered 문제 해결
- 출력 범위는 -1에서 1 사이이므로 Zero-Centered
- Gradient Vanishing 문제 존재
- 입력 값이 매우 크거나 매우 작을 때 기울기가 0에 가까워짐
ReLU 함수

-
양수 부분에서는 saturate 되지 않음. 즉 gradient가 0이 되어 학습이 안되는 현상은 없음
-
계산적으로도 효율적임
음수는 0, 양수는 그대로 내보내면 되기 때문에 구현도 쉽고 계산도 쉬움. 실제로도 시그모이드/tanh 함수보다 훨씬훨씬 빠르게 수렴 -
단점:
- zero-centered 가 되지 않음 (항상 positive 또는 negative 하게 gradient가 학습 ) => Minibatch를 사용해서 어느 정도는 완화 가능
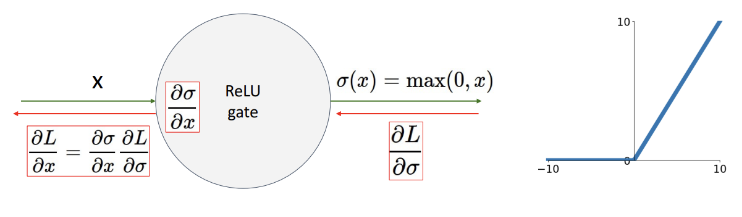
- Dead ReLU 문제
위 예시를 보면 x=-10, x=0 일 때 모두 gradient가 0이 됨.
양수 일때만 gradient가 1이고 나머지일때는 항상 0이 되어서 학습이 전혀 이루어지지 않게됨
- zero-centered 가 되지 않음 (항상 positive 또는 negative 하게 gradient가 학습 ) => Minibatch를 사용해서 어느 정도는 완화 가능
=> 따라서 ReLU를 음수일 때 0이 아니라 아주 작은 양수 bias로 초기화하는 방법에 대해서도 고민
LeakyReLU 함수

- 해당 아이디어를 구현한 것이 Leaky ReLU
- 음수 일 때 0이 아니라, 0.01x 값이 나오도록 식을 구성
- ReLU의 장점이었던 saturate 되지 않는다는 점을 유지, 효율성도 그대로 유지 / 학습이 죽어버리는 현상도 극복
- 고민해봐야할 점은 0.01 값만 곱해줘야하나? 임
- 이는 사실 하이퍼파라미터 즉 사용자가 정해주는 값인데 이걸 정해주는 게 스트레스
- 2015년에는 PReLU 활성화 함수가 제시, 이는 곱해지는 작은 양수 값을 학습의 대상으로 보는 방법
ELU
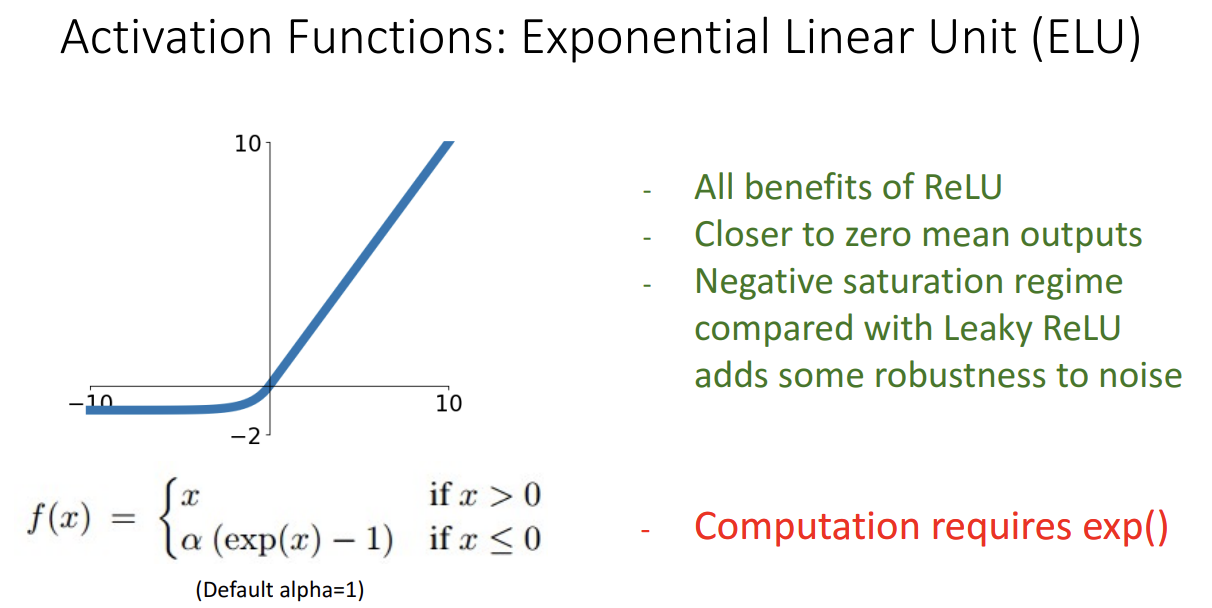
- 해당 활성화 함수가 나오게된 이유: ReLU의 경우 input 값이 0 쪽일 때는 미분이 불가능하다는 문제가 있었기 때문
- ELU는 ReLU를 smooth 시켜서 해당 문제점을 극복
- ReLU의 장점들은 모두 챙기고 noise에도 더 Robust해진다는 장점
- 단점:Exponential 함수는 계산이 복잡
SELU

- ELU의 Scaled 버전
- SELU는 ELU와 유사하지만 곱해지는 파라미터 값을 수학적으로 규정
- 위에 보이는 복잡한 해당 숫자들을 사용한다면 Self-Normalizing 되어서 BatchNorm이 필요가 없어지게 됨
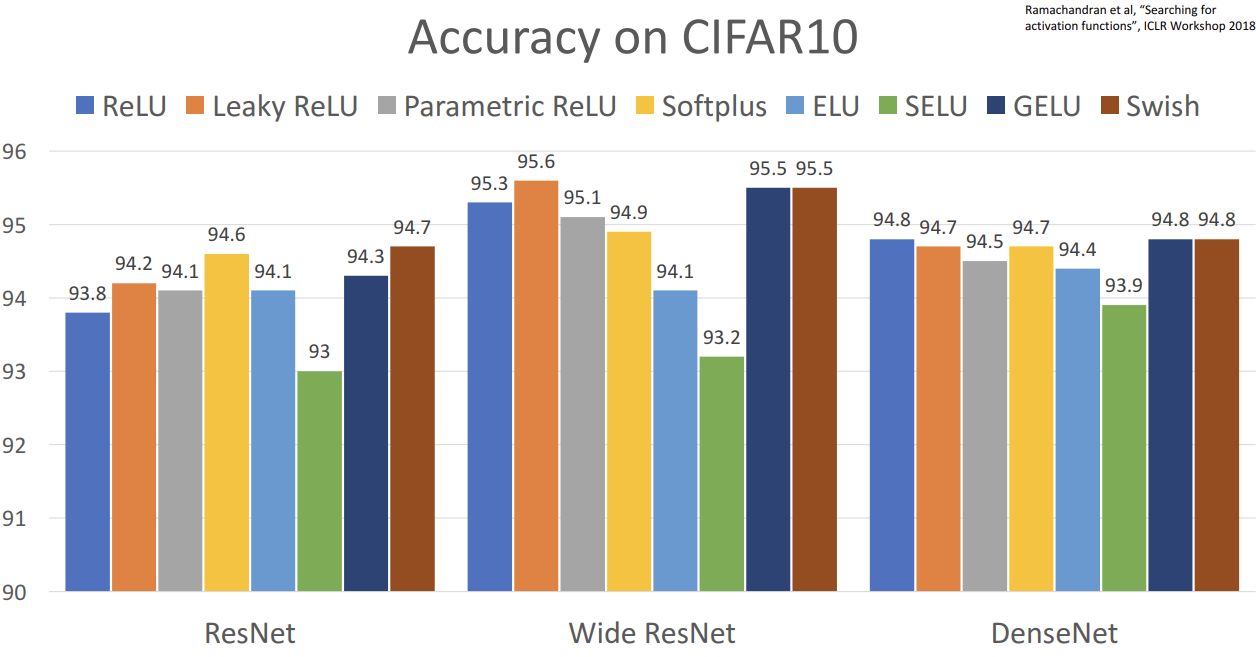

- 교수님께서는 어렵게 생각할 필요없다. 그냥 ReLU 써라 라고 조언해주심, 성능을 0.1% 까지 짜내고 싶으면 변형본 사용
- 하지만 시그모이드/tanh 는 절대 중간에 넣지 말기(네트워크가 수렴하지 못함)
Data Preprocessing
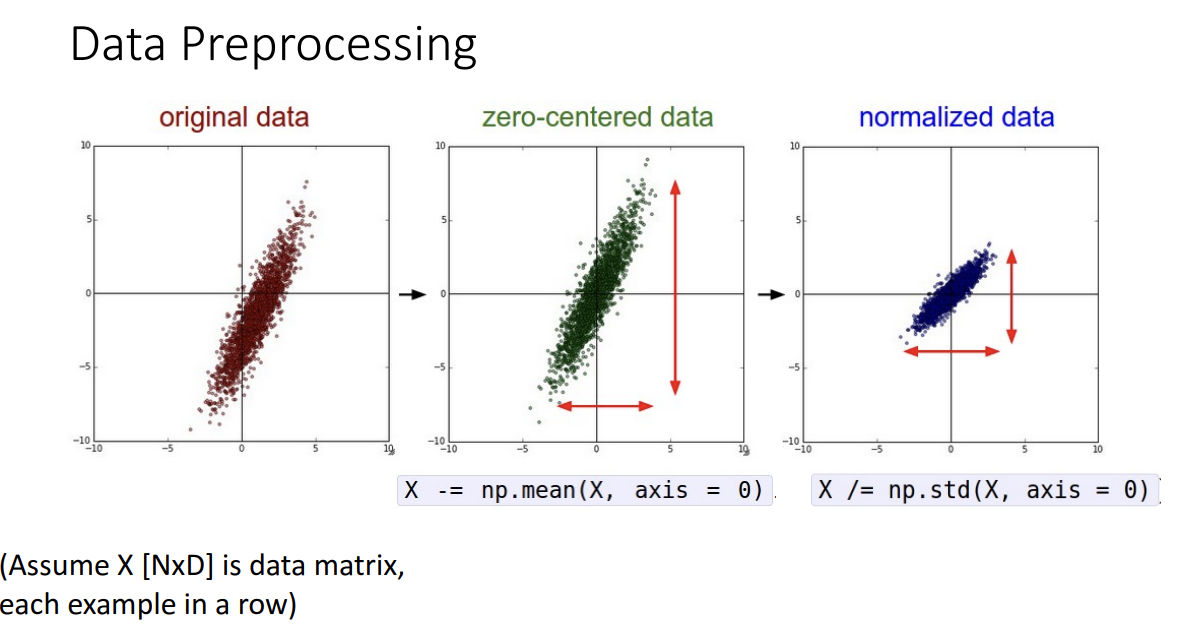
- 원본 데이터를 zero-centered 시키고 정규화하는 방법
- PCA를 통해 Decorrelated 시키는 방법
- 원본 데이터셋을 rotate 시키는 방식(축끼리 uncorrelated 될 수 있도록, 즉 데이터가 diagonal covariance 행렬을 가질 수 있도록 하는 것)
- Whitening 시키는 전처리 방법: PCA, whitening는 이미지에서 잘 사용 안함

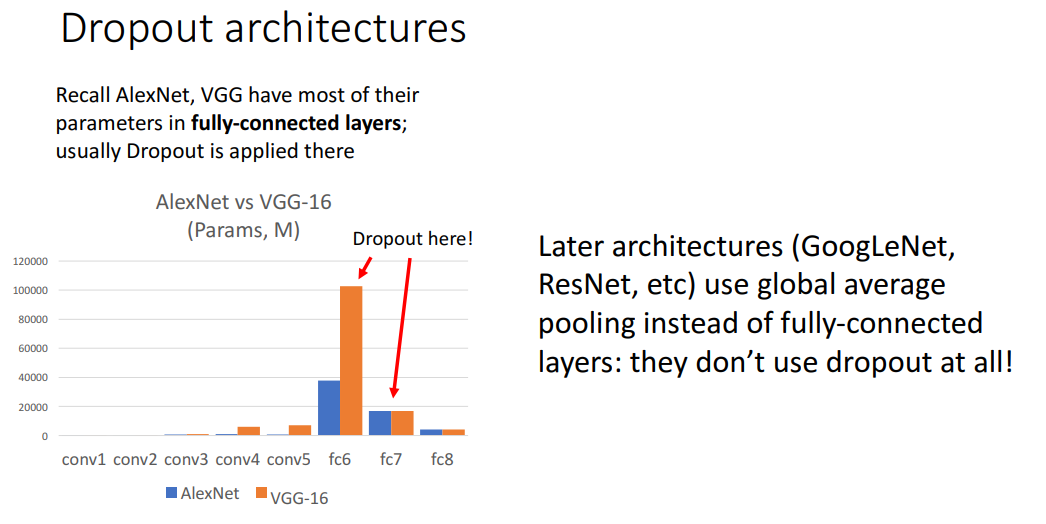
- 이미지에서 데이터전처리가 이뤄진 사례:
- AlexNet: 32x32x3 각 픽셀별 평균 값을 빼기
- VGGNet: channel별 평균 이미지를 빼줘서 총 3개의 이미지를 빼기
- ResNet의 경우 VGGNet의 경우에서 더 나아가 채널별 표준편차로 나눠주는 정규화 과정도 거침
Weight initialization
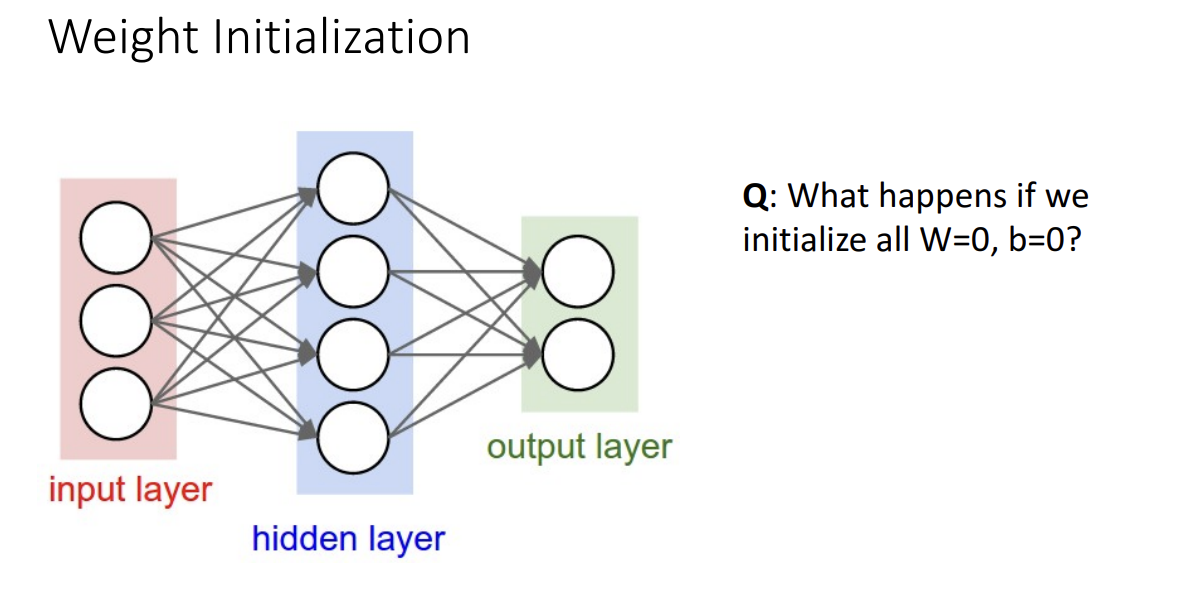
- 가중치랑 편향을 0으로 두고 시작해도 될까요?
- 결과 안좋음. Output이 0이 되어서 gradient가 늘 똑같게 되어서 학습이 전혀 안 이루어지게 되기 때문
- 아이디어 1 ) 아주 작은 랜덤한 값으로 초기화 시켜서 시작하는 방식
- 층을 거칠수록 gradient 값이 점점 0에 가깝게만 산출되기 때문에 학습이 전혀 이뤄지지 않음
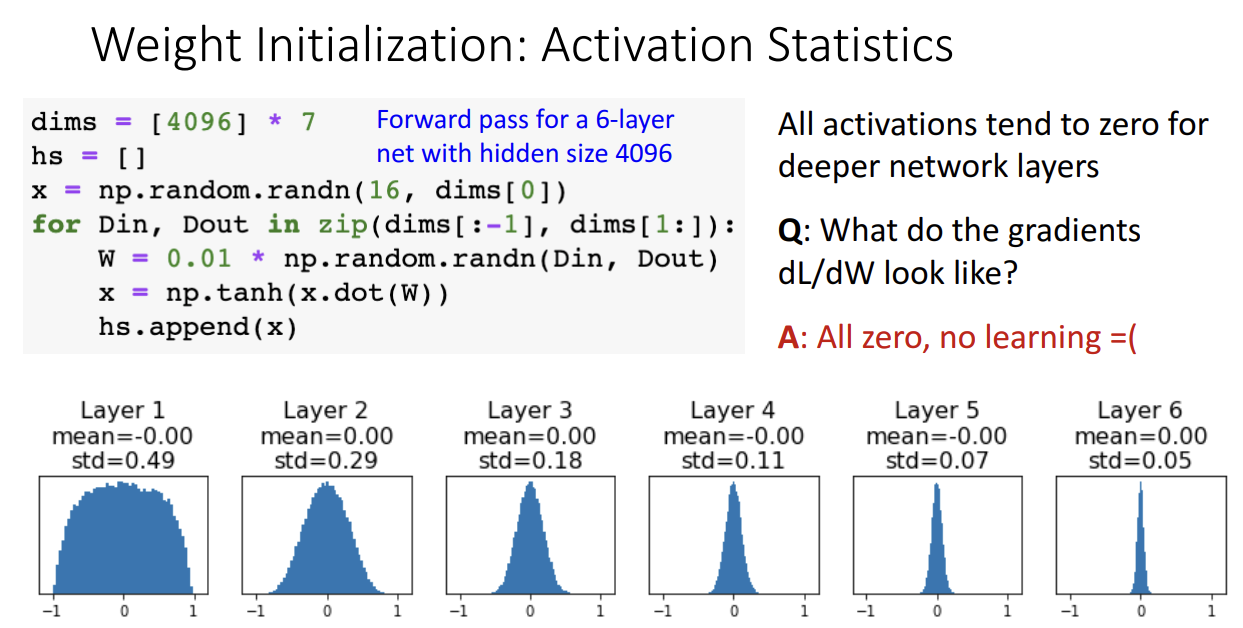
- 층을 거칠수록 gradient 값이 점점 0에 가깝게만 산출되기 때문에 학습이 전혀 이뤄지지 않음
- 아이디어 2) 요슈아 벤지오 교수님의 제자인 자비에 박사님의 자비에 초기화
- 해당 초기화를 사용하면 모든 층에서 gradient가 적절하게 계산되어 학습이 잘 이루어짐

- Output의 분산을 Input의 분산과 동일하게 만들고 싶은게 자비에 초기화 아이디어의 시작
- 초기화 값으로 가중치의 분산은 1/D 가 되야 한다는 식이 도출되어서 이를 초기화 값으로 사용
- 문제점 : 자비에 초기화는 zero-centered된 활성화 함수에 적용하는 걸 전제
- 따라서 tanh 활성화 함수는 오케이 지만 ReLU 함수에 사용하면 gradient가 0으로 수렴해서 학습이 이루어지지 않음
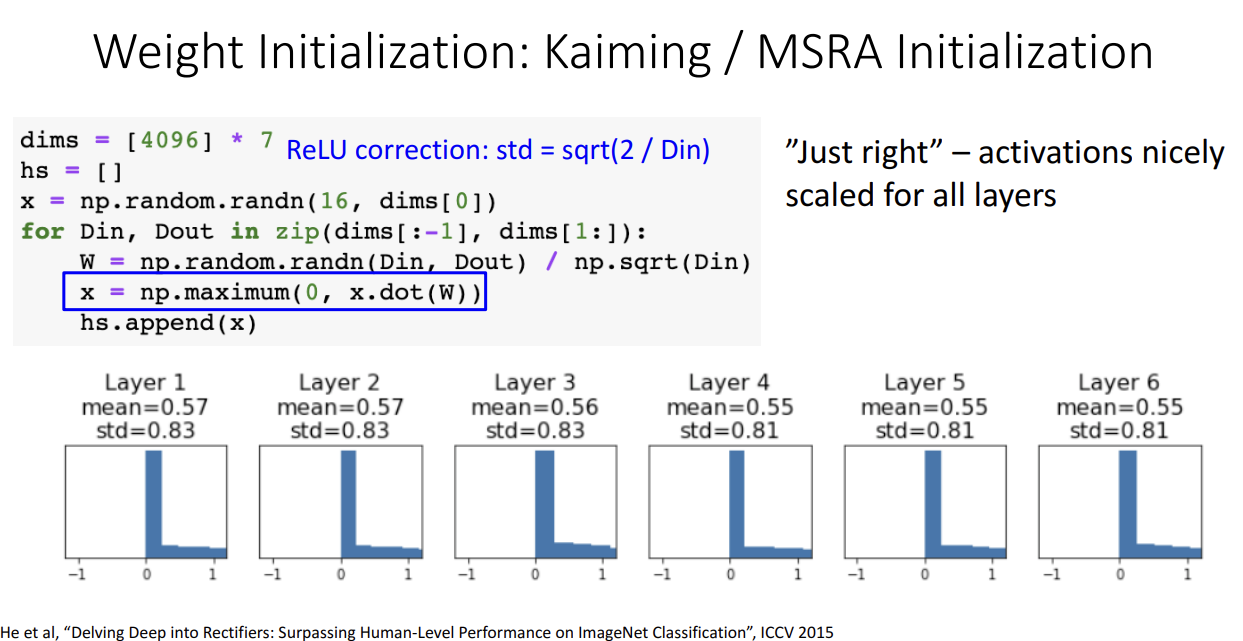
- ReLU 활성화 함수에 적합한 초기화 방법: ResNet을 만드신 Kaiming He 박사님의 Kaiming 초기화 / He 초기화 / MSRA 초기화 방법

- ResNet에서 He 초깃값을 사용해서 학습할 때 문제점: He 초깃값은 Var(F(x))=Var(x)가 되도록 동작하는데 ResNet은 Additive Shortcut을 더해서 출력값을 보내기 때문에 gradient가 exploding 하는 문제
- 해결책: 첫번째 Conv를 초기화할 때 He 초깃값 사용, 두번째 Conv를 초기화할 때는 0으로 초기화 하면 Var(x+F(x))=Var(x)
- 따라서 tanh 활성화 함수는 오케이 지만 ReLU 함수에 사용하면 gradient가 0으로 수렴해서 학습이 이루어지지 않음
- 해당 초기화를 사용하면 모든 층에서 gradient가 적절하게 계산되어 학습이 잘 이루어짐
Regularization
-
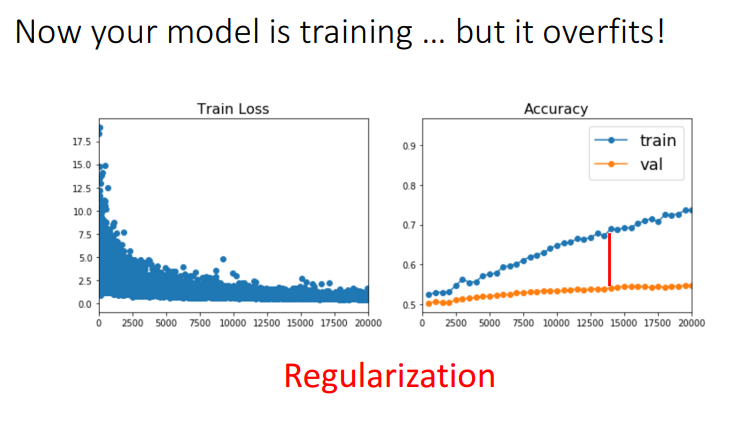
모델이 Overfitting되는 문제: Regularization 기법으로 해결 가능
- 방식 1) Loss 함수에 Regularization term을 추가해주는 것( L2, L1 regularization term )
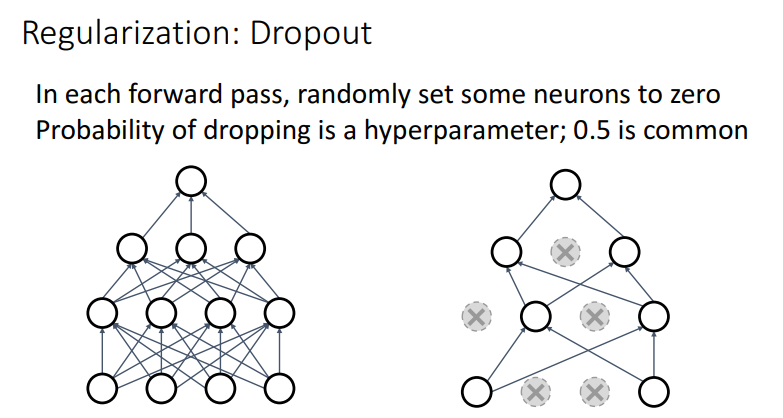
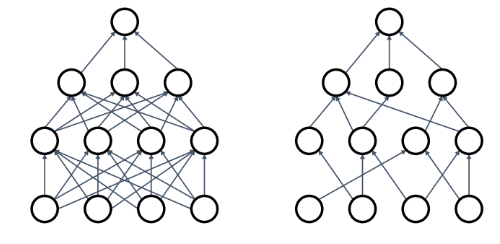
- 방식 2) 네트워크의 뉴런을 끊어버리는 방식
- 특정 확률에 따라 뉴런을 끊어버리는 방식인 Dropout, 일반적으로 0.5를 많이 사용 ( 학습 과정에서 일부 뉴런을 "임시로" 무작위로 제거하는 방식 )
- 방식 3) Augmentation ( CV 에서 )
- 방식 4) DropConnect, Stochastic Depth 등
-
Dropout이 좋은 이유 :
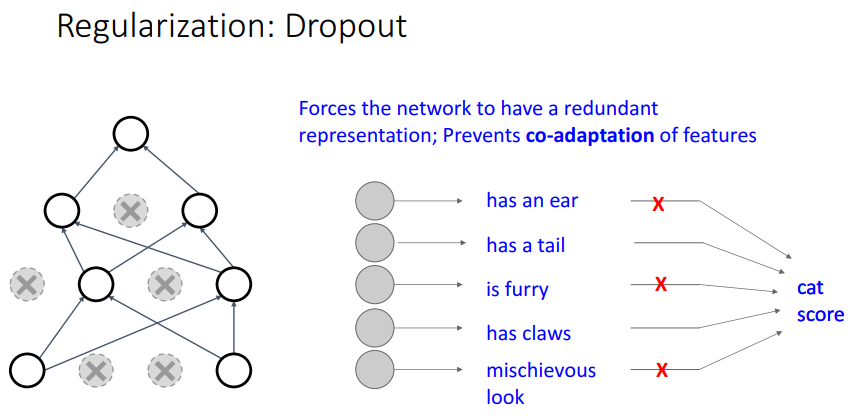
- 뉴런은 분류 Task를 수행하는데 있어서 꼭 필요한 정보들만을 담고 있지는 않음
- 예를 들어 고양이로 분류하기 위해서 꼬리, 발톱과 같은 정보는 중요하지만, 귀가 있다, 털이 있다 이런건 크게 중요하지 않을 수 음 => 이렇게 다른 클래스 이미지와 중복되는 표현은 제거해서 모델의 성능을 높일 수 있음
- 그 외에도 Dropout은 어떤 뉴런을 끊을지에 따라서 다른 모델이 됨
- 따라서 학습을 여러번 진행할 때마다 끊기는 뉴런이 다름. 이를 종합해서 학습하는 방법은 결국 앙상블 효과
-
일반적으로 네트워크에 Dropout을 사용하는 것은 Overfitting을 방지하여 학습을 잘하기 위함
-
Test 시에는 Dropout을 구조에서 빼버려서 랜덤한 결과보다는 Deterministic 한 결과를 얻도록 함

- Dropout은 깊은 구조의 네트워크에서 Overfitting을 줄이기 위해서 필수이긴 하지만,
- GoogLeNet이나 ResNet의 경우 global average pooling을 FC Layer 대신 사용하기 때문에 굳이 dropout을 사용하지 않음
- Augmentation
- 여러가지 방식으로 데이터 증강을 하는 것도,
모델이 너무 특정 데이터셋에만 맞춰서 학습되는 현상을 방지함



- 여러가지 방식으로 데이터 증강을 하는 것도,
- 다양한 정규화 방법들
- DropConnect : 뉴런을 지우는 것이 아니라 뉴런간의 연결을 0으로 두어서 연결을 끊는 방식
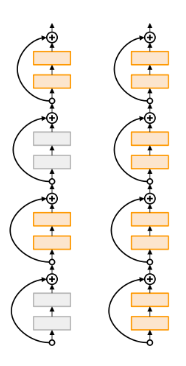
- Stochastic Depth : ResNet 블록에서 특정 블록을 지우는 방식
- Cutout : 이미지를 Cutout 해서 일부 이미지는 날려버린 상태로 학습 / 많이 사용됨

- Mixup : 하나의 클래스만을 예측하는게 아니라, 두개 이상의 클래스 이미지를 합친 상태로 학습하여 합쳐진 이미지의 비율을 예측 / 많이 사용됨

- DropConnect : 뉴런을 지우는 것이 아니라 뉴런간의 연결을 0으로 두어서 연결을 끊는 방식
질문 :
시그모이드 함수는 0과 1 사이의 값만을 출력하기 때문에, 그 출력이 항상 양수라는 것은 알겠음. 근데 왜 이 때문에 기울기(Gradient)가 언제나 양수 혹은 음수로 고정되는 문제가 발생한다는 것인지 이해가 잘 안됨. 입력이 음수여도 시그모이드 함수의 출력은 여전히 양수 아님? 근대 왜 역전파의 기울기가 음수 또는 양수로 고정될 수 있다고 하는지
Activation function
- linear classifier등으로 나온 수치 값 자체가 중요하다기 보다는활성화 됬는가 / 아닌가 가 중요하다는 아이디어
- 활성화가 되는 뉴런이 중요
- 즉 마이너스를 다 없애버리는게 맞는가?라는 생각이 나옴
- 실제로 ReLU는 음수 영역에서 출력을 0으로 만들기 때문에, 일부 뉴런이 비활성화되더라도 전체 네트워크의 학습 성능을 저하시키지 않도록 설계됩니다
- 다운스트림 그래디언트 = 현재 레이어 로컬 그래디언트 * 업스트림 그라디언트

