생성 모델 part 1
Auto Encoder Model
- 딥러닝 기반의 이상치 탐지 방법으로 Encoder를 통하여 데이터를 Latent Vector(잠재 벡터)로 축약하고 Decoder를 통해 복원을 진행할 때 입력값과 출력값의 오차가 적게 설계
Supervised vs Unsupervised Learning
-
Supervised Learning(지도학습): 입력데이터 x가 주어지고 라벨 y가 주어짐
이 때 목표는 입력데이터 x가 주어졌을 때 라벨 y로 매핑하는 함수를 학습하는 것
대표적인 예시는 분류, 회귀, Object detection, Semantic segmentation, 이미지 캡셔닝 -
Unsupervised Learning(비지도학습): 입력데이터 x는 주어지지만 라벨 y가 주어지지 않음
이 때 목표는 데이터 x 자체가 내포하고 있는 어떠한 구조 자체를 학습하는 것
예시로는 군집화, 차원축소, Feature Learning, Density estimation -
왜 생성 모델에 이 개념 ? : 데이터를 잘 분류하기 위해서는 데이터가 내포한 어떠한 특징들을 학습해야하고 이를 가장 잘 학습했다고 볼 수 있는 것은 데이터를 직접 만들어낼 수 있도록 학습시키는 것이기 때문
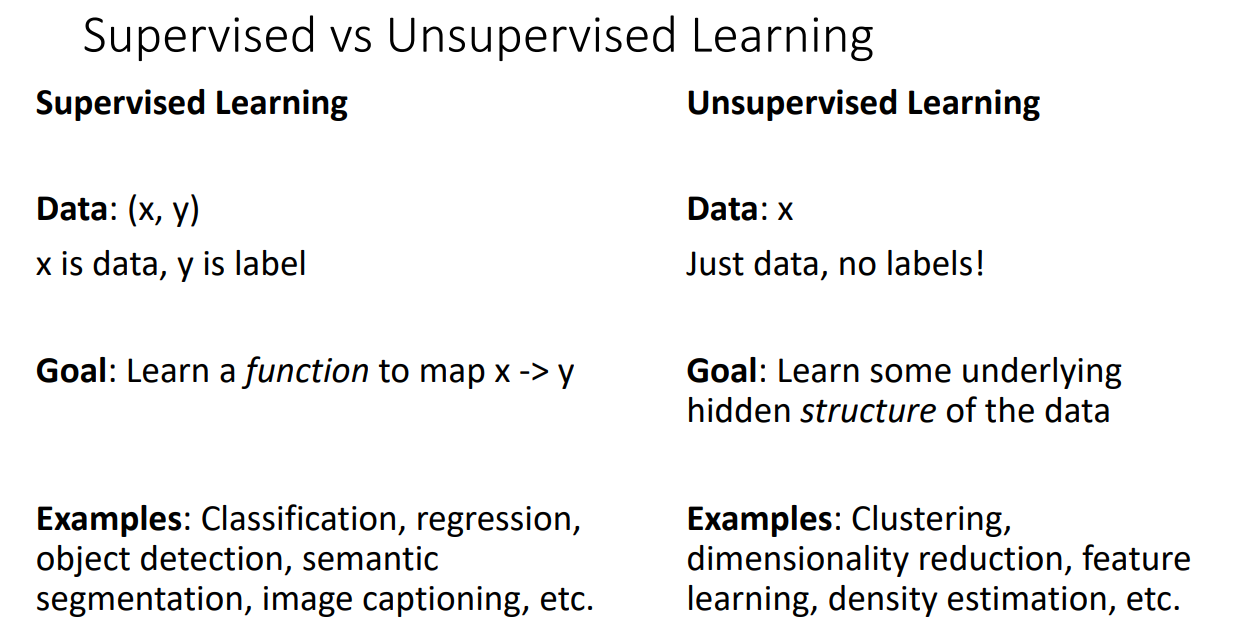
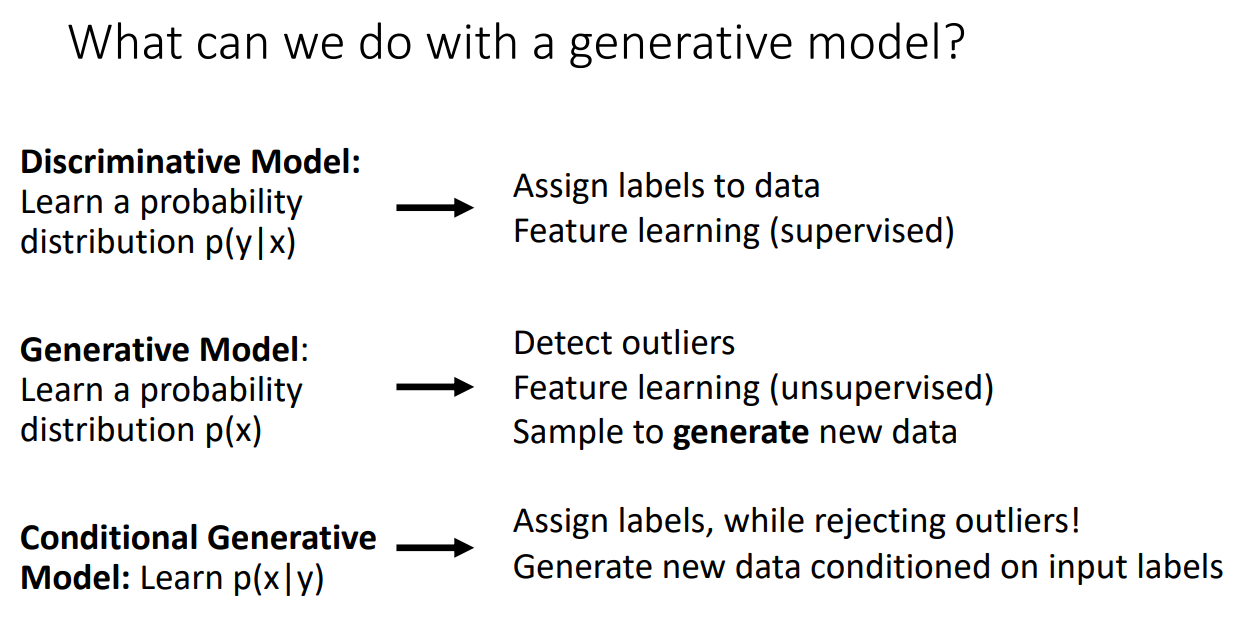
Discriminative vs Generative Models
Discriminative Model :
p(y∣x) : 입력데이터 x가 주어졌을 때 라벨 y를 매핑하는 학습을 하는 것
여기서 확률 분포는 밀도함수로 값이 높게 나올 수록 x가 더 나오기 쉽다는 것을 의미
그림에서 고양이가 입력데이터 x로 주어졌고, 그러한 상황에서는 cat이라는 라벨로 매핑
각 입력데이터 x마다 모든 라벨들에 일정하게 매핑될 확률이 나오며 다 더하면 1
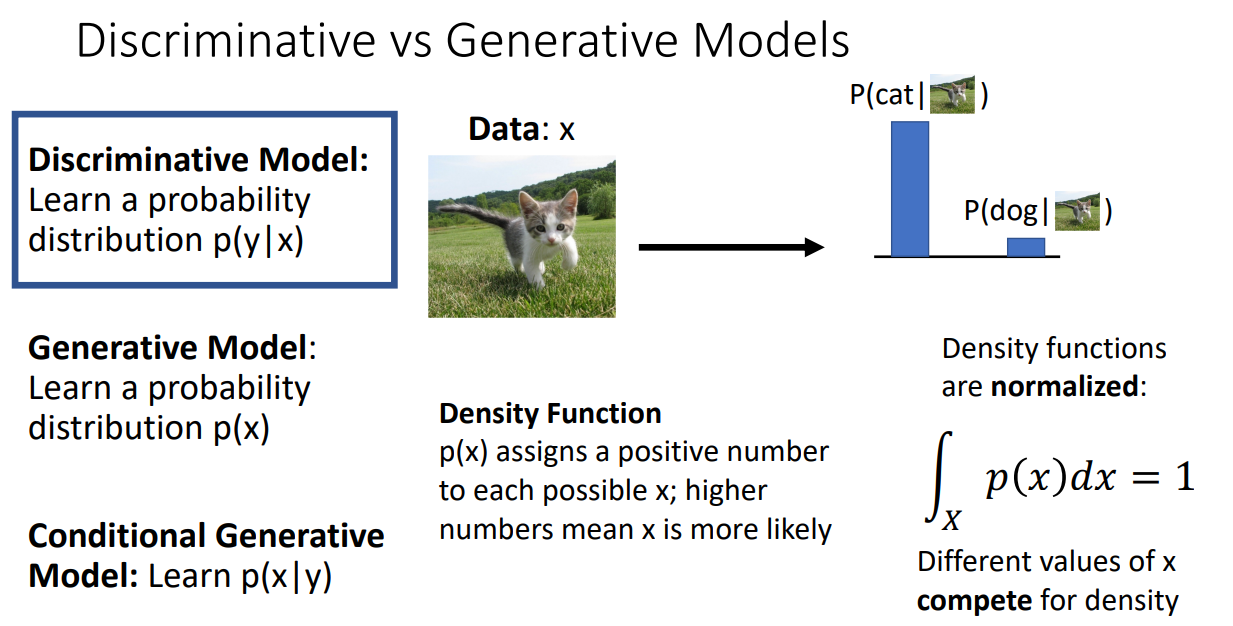
입력데이터 x가 달라지면 어떠한 밀도로 라벨이 매핑될지 경쟁하게 됨
=> 이미지들 간에 얼마나 차이가 있는지를 보는게 아니라 각각의 이미지들이 어떤 라벨을 갖게 될지를 보는 것
Discriminative Model 단점 :
Unreasonable한 input 이미지에 대해서도 사전에 정의된 라벨을 부여하도록 모델이 학습하게 되고 이는 모델이 왜곡된 정보를 판단하도록 강제

Generative Model :
p(x) : 모든 가능한 이미지들에 대해서 likelihood 혹은 density을 계산하도록 학습
앞서 Discriminative model이 unreasonable한 input 이미지 또한 학습한다는 단점 극복
어떻게 ? : Generative model의 경우 unreasonable한 input 이미지에 대해서는 낮은 likelihood 값을 부여하기 때문에 "reject" 할 수 있도록 학습

Conditional Generative model :
p(x∣y) : 모든 이미지들이 각각 어떤 class에 있을 때 likelihood가 높을 지를 계산하여, 분석가가 원하는 라벨로 이미지를 생성해낼 때 사용
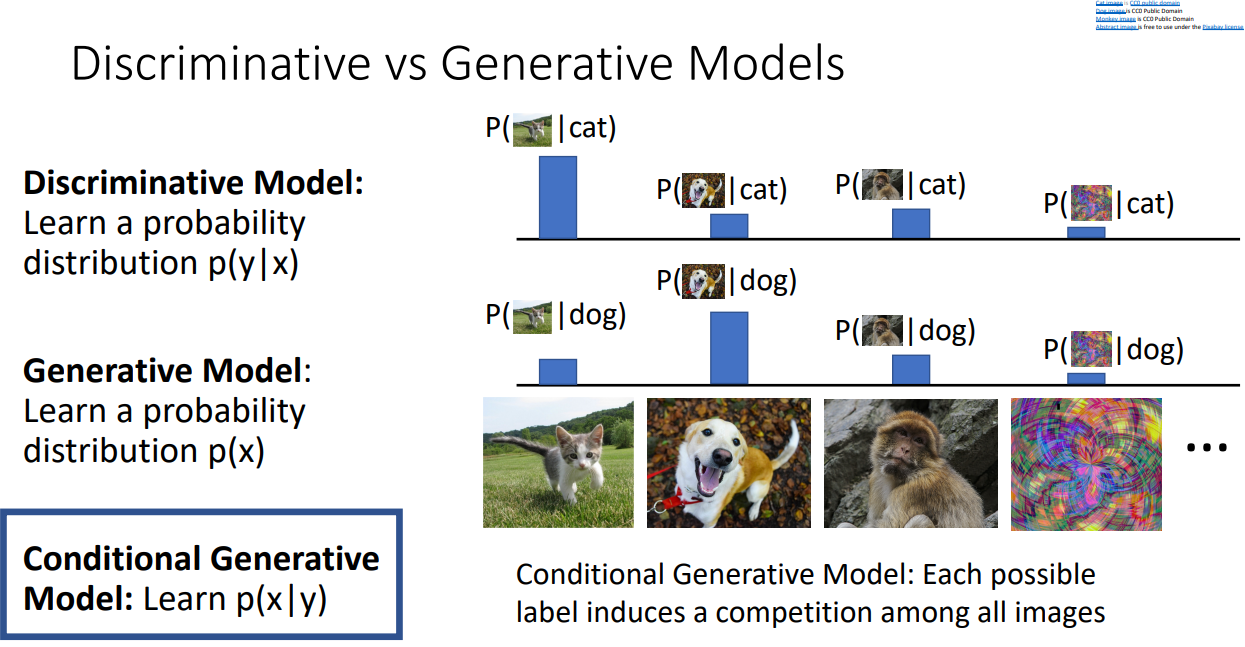
Bayes' Rule 로 설명
연두색 박스는 training set에서 직접 개수를 세서 확률을 계산
이후 Discriminative model, Generative model, Prior over labels 들을 조합하여 Conditional Generative Model을 계산
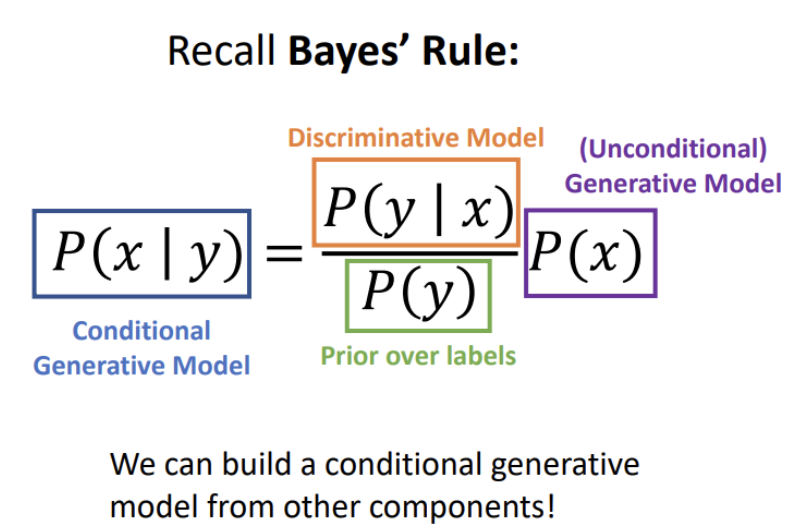
3개 모델 총정리
- Discriminative Model: 지도학습 상황에서 데이터에 라벨을 부여
- Generative Model: 비지도학습 상황에서 Feature Learning 가능, Outlier 탐지 가능, 새로운 데이터를 생성
- Conditional Generative Model: Outlier는 제거하면서 라벨을 부여할 수 있고, 라벨에 따라 새로운 데이터 생성
Taxonomy of Generative Models
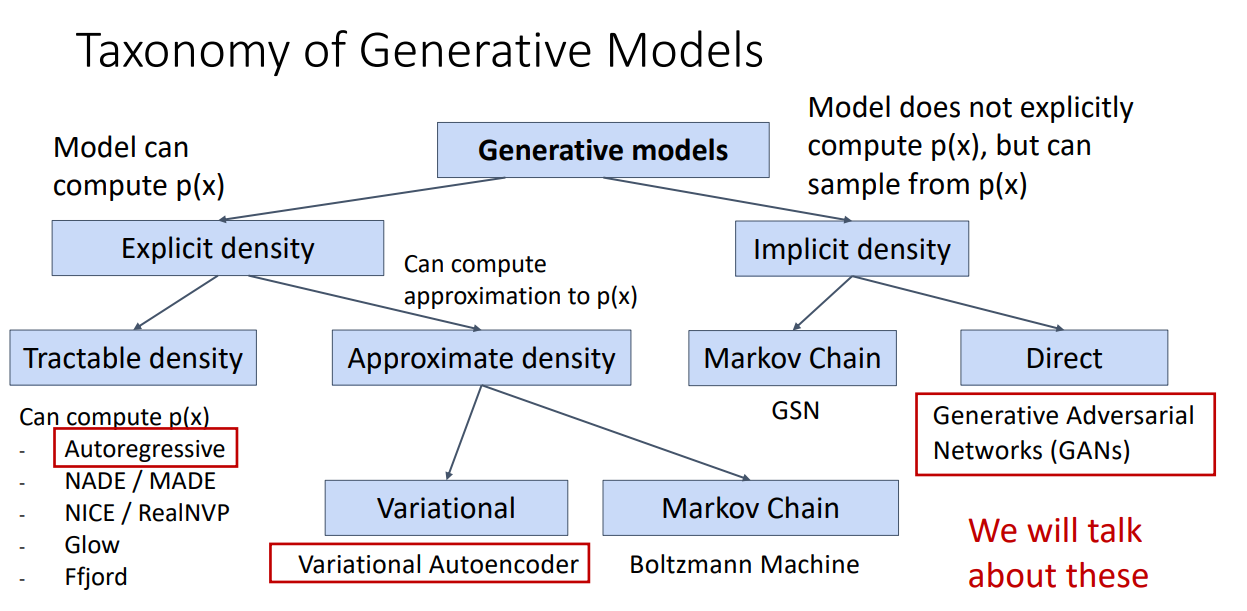
Autoregressive Models
Autoregressive Models:
목표 : input 데이터에 따른 직접적인 확률분포를 찾아내는 것
모든 explicit 밀도 추정 방식의 공식을 보면
- 데이터셋이 주어졌을 때, training data의 확률을 maximize하도록 하는 W를 규정
- 다음으로 log transform을 통해 product를 sum으로 바꿈
- 그렇게 만들어진 W를 최대화하는 loss function을 gradient descent를 통해 학습

p(x)=f(x,W)를 찾는게 목표가 됨
input data를 subparts로 쪼개고 x에 대한 확률은 chain rule을 통해서 계산
확률을 계산할 때 이전 모든 subparts로 다음 subpart의 확률을 계산하게 되는데 해당 과정은 Language Model을 RNN으로 학습시킬 때와 유사함

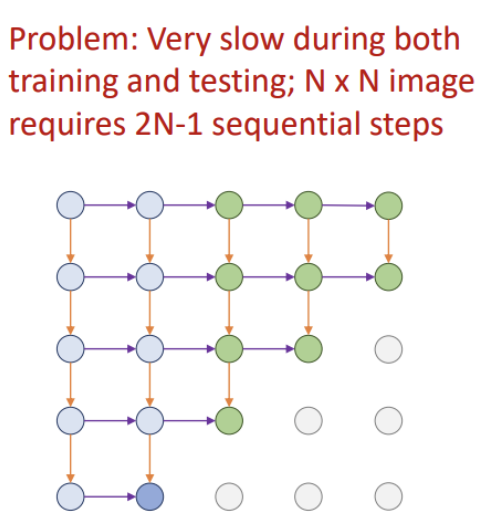
Pixel RNN:
왼쪽 위 모서리부터 시작해서 pixel을 하나씩 생성해내는 방법
왼쪽과 위로부터의 RGB 값과 hidden state에 따라서 각 픽셀의 hidden state를 계산
각 픽셀에서, red, blue, green 3 채널의 값을 0~255 값으로 예측
바로 직전 픽셀에 영향을 받게되면 explicit 하지만 이 경우 그 이전의 모든 픽셀에 의해서 영향을 받을 수 있기 때문에 implicit
단점: sequential하게 계산을 해나가야하기 때문에 학습과 추론 시에 느림
Pixel CNN:
코너에서부터 이미지 픽셀을 생성해내는 방식
이번에는 CNN을 통해 context region의 픽셀 정보에 따라 픽셀 값을 생성
PixelCNN은 PixelRNN보다는 학습이 빠르지만, 여전히 생성 작업이 Sequential 하게 진행되기 때문에 Test 시에는 느림
Autoregressive Models : PixelCNN PixelRNN 장단점
장점 : Explicit 하게 likelihood p(x)를 계산할 수 있고, 이에 따라 좋은 evaluation metric에 의해 성능을 보장받을 수 있음
단점 : generation 과정이 느림
Variational Autoencoders
AR 모델 : explicit하게 density function을 parameterize 할 수 있다는 장점 있음
VAE 모델 : intractable density를 규정하기 때문에 explicit 하게 계산하거나 최적화할 수는 없음
=> lower bound을 최적화하는 방식으로 학습 진행
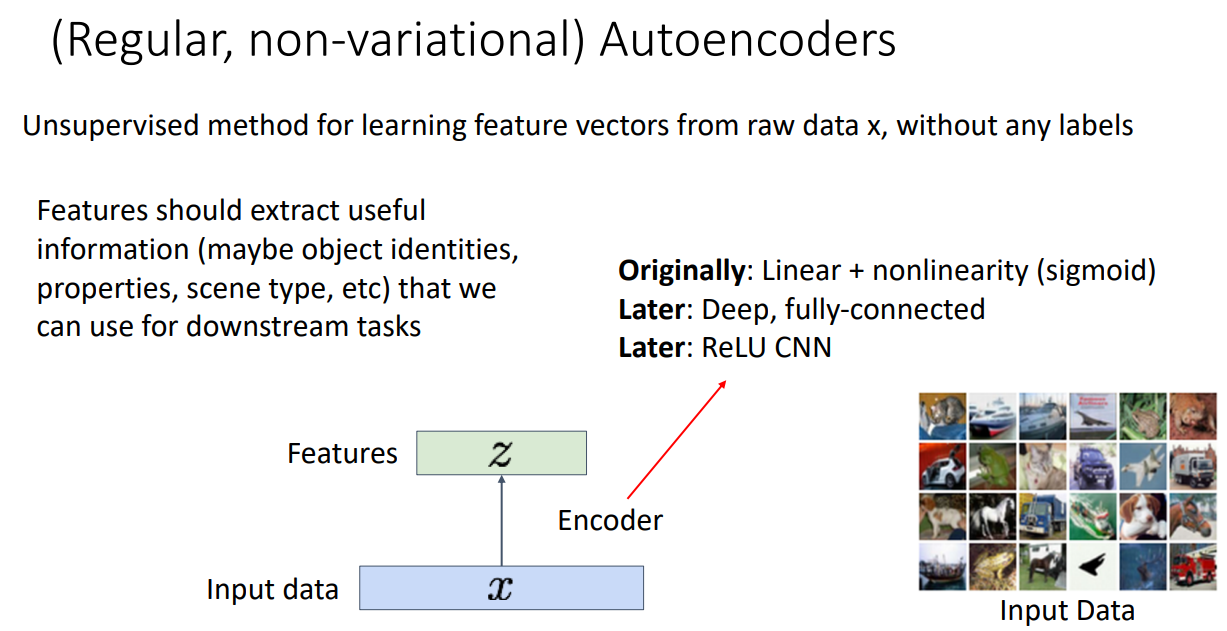
Autoencoder
어떠한 라벨 정보 없이 입력 데이터 x로부터 feature vectors를 학습하는 비지도 방법
Feature vectors는 Downstream task를 수행하는데 유용한 정보들을 추출해야함
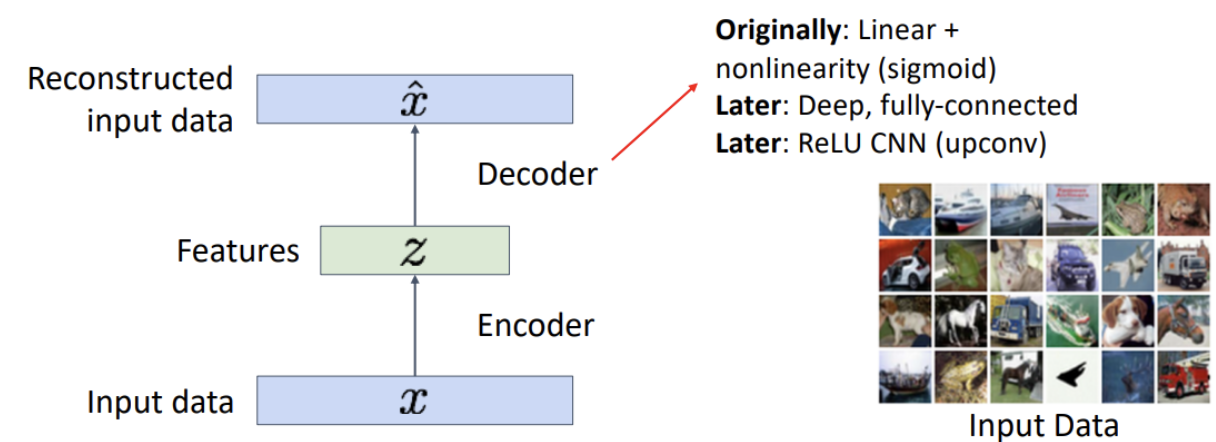
유용한 feature vectors를 추출해내기 위해서 오토인코더는 Decoder를 접목함
Decoder를 통해 input data x를 복원하는 과정 진행
복원된 x^와 원본 input x의 차이를 최소화하게 된다면 결국 feature vectors는 복원하는데 필요한 정보를 잘 담고 있도록 학습이 됨
따라서 Loss를 input과 reconstructed data의 L2 Distance인 로 설정하여 학습을 수행
Loss 함수를 보면 알 수 있듯, 라벨 정보는 전혀 필요하지 않음 & Feature vector의 차원은 원본 input의 차원보다 작음
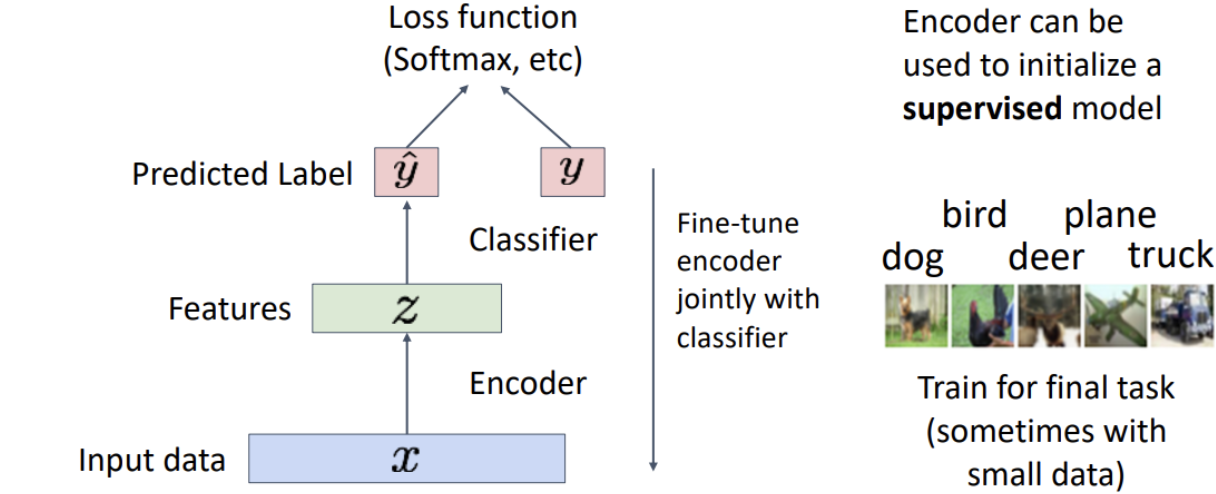
학습이 다 이뤄진다면 Decoder는 날리고 Encoder만을 feature extractor로 사용하여 Downstream task를 수행
Downstream task 데이터셋에 맞게 Fine-tune해서 지도 학습을 수행할 수도 있음
Autoencoders는 어떠한 라벨 정보 없이도 latent feature 학습 가능하기 때문에 지도학습 모델을 시작할때 feature로서 활용할 수 있음
Autoencoder 단점
raw data에서 어떻게 feature transform을 할 것인가?
encoder를 통해 latent feature를 뽑아내고, 이것을 decoder를 통해 reconstruct 함
Not probabilistic 함 : No way to sample new data from learned model
=> unsupervised기 때문에 labeled 샘플이 없어 새로운 sample을 generate 할 수 없음
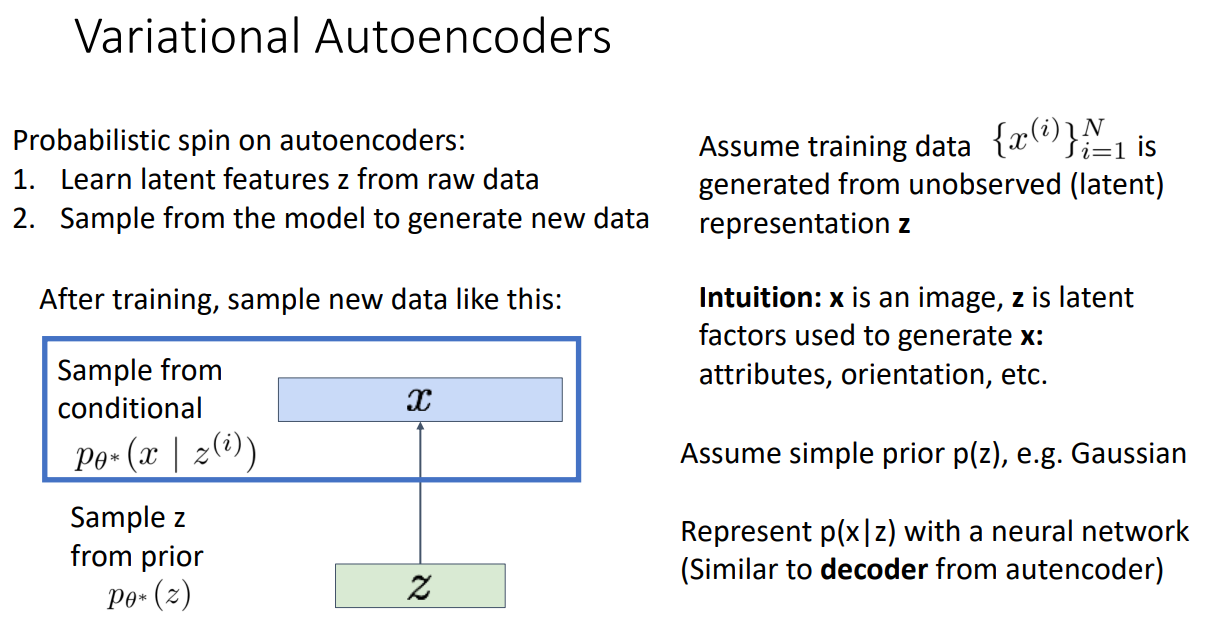
VAE 특징
latent features를 raw data에서 학습해야 함
모델을 통해 새로운 data를 generation을 해야 함
Unlabeld sameple을 많이 가지고 있다고 가정하고 각 샘플 x가 latent z 벡터로부터 생성되었다고 가정
p(x/z) output이 image가 아닌, 이미지의 neural network의 distribution 임
p(z) (prior distribution) : 가우시안이라고 가정하면,
p(x/z) : z가 given 일 때 x가 나올 조건부 확률에 대한 pmf
VAE에서는 AE와는 다르게, 가우시안 확률분포에 기반한 확률값으로 나타냄
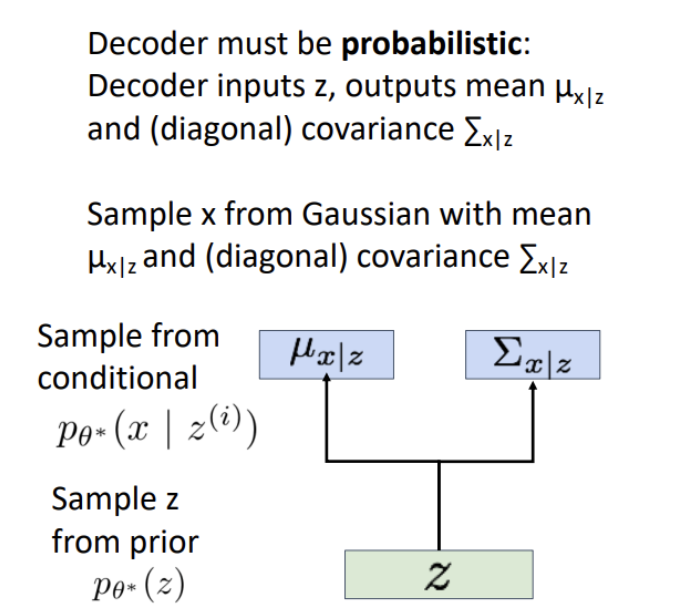
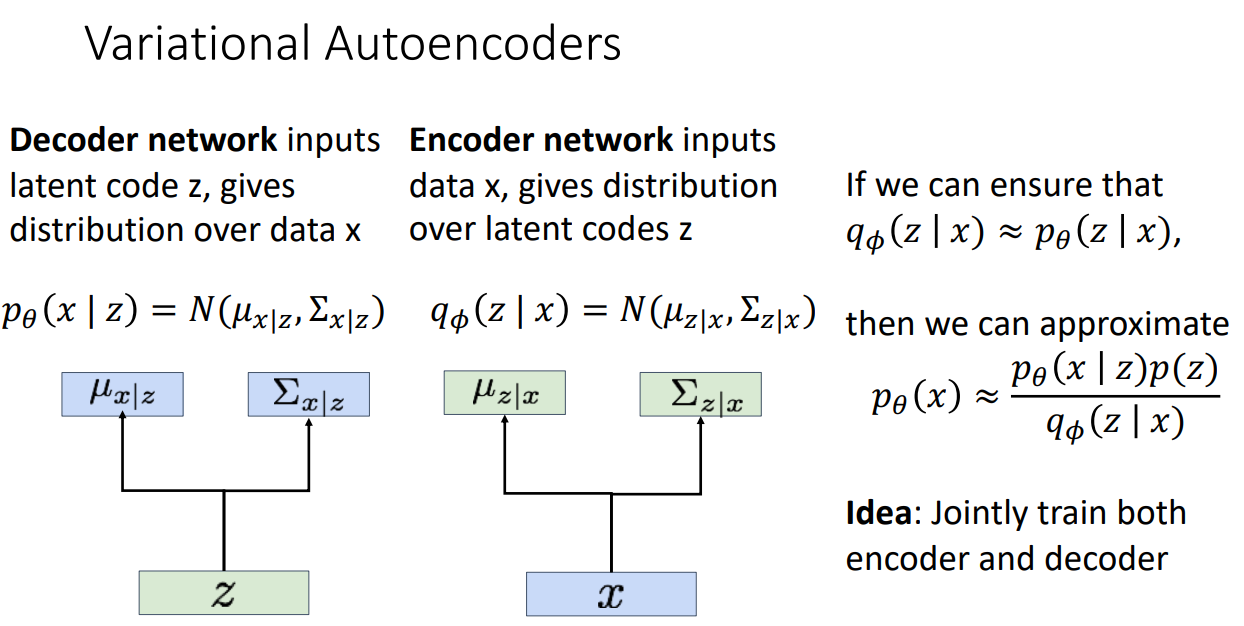
단점 대안책 => Decoder를 Probabilistic
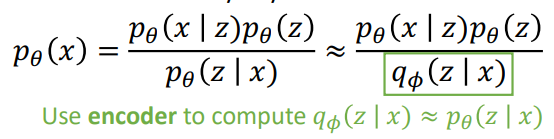
그림처럼 Encoder를 통해 학습된 Latent variable z에 따라 평균과 공분산을 Sampling하고 이를 통해 새로운 데이터를 생성
이러한 모델 학습 방법 : maximize likelihood of data
입력값 x로부터 z를 observe할 수 있다면, 곧바로 p(x∣z)를 학습할 수 있음
하지만 z는 observe할 수 있는 대상이 아니기 때문에 marginalize 과정이 필요
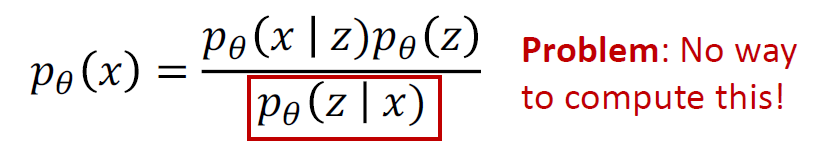
Bayes' Rule

Bayes' Rule도 pθ(z∣x)를 계산할 수 없기 때문에 x로부터 z를 만들어내도록 학습하는 Encoder를 대신 사용
Autoencoder와 VAE 차이
- Autoencoder: 원래 입력값을 잘 보존하는 Latent space를 만들어내기 위해, 혹은 차원축소를 하기 위해 나온 모델 => Encoder를 위해서 Decoder가 도입된 모델
- VAE: Decoder로 새로운 데이터를 잘 생성해내기 위해서 Encoder 도입한 모델
그림으로 다시 표현하면 아래와 같음
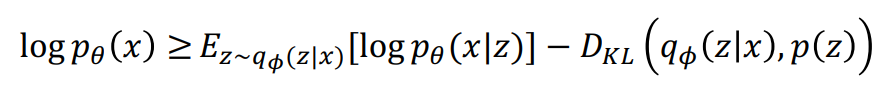
학습 : 인코더와 디코더를 jointly하게 학습함
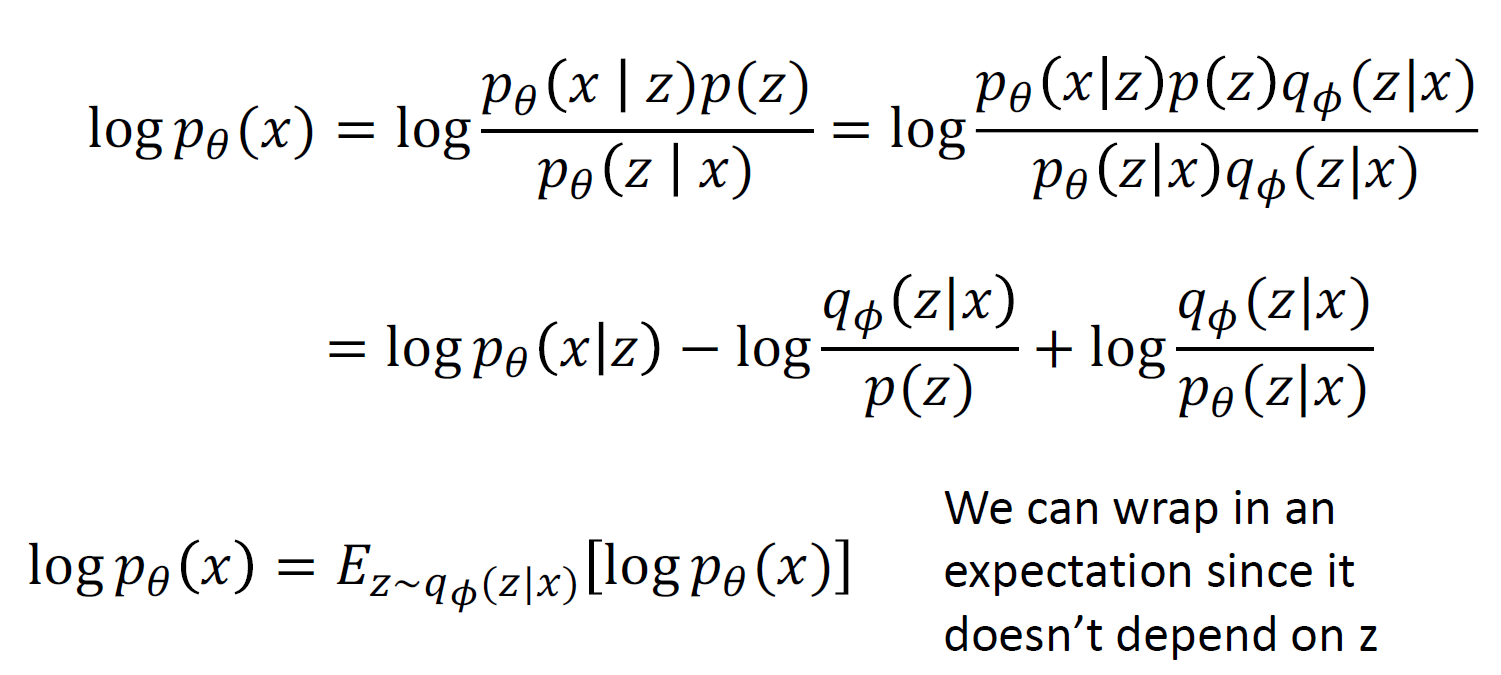
KL term 이 0보다 크므로, 이것을 없애는 것으로 lower bound를 만들 수 있음
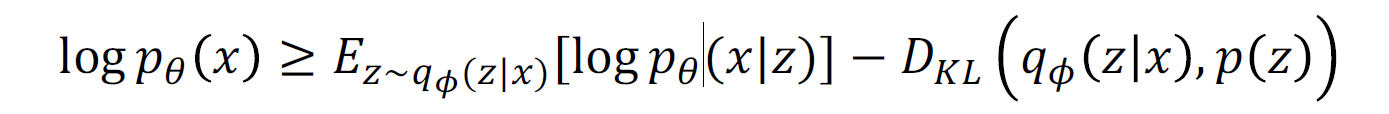
목표 : Lower bound를 maximize하기
ncoder와 decoder를 jointly 하게 학습시켜 data likelyhood의 vartiational lower bound를 maximize 하며 학습을 진행
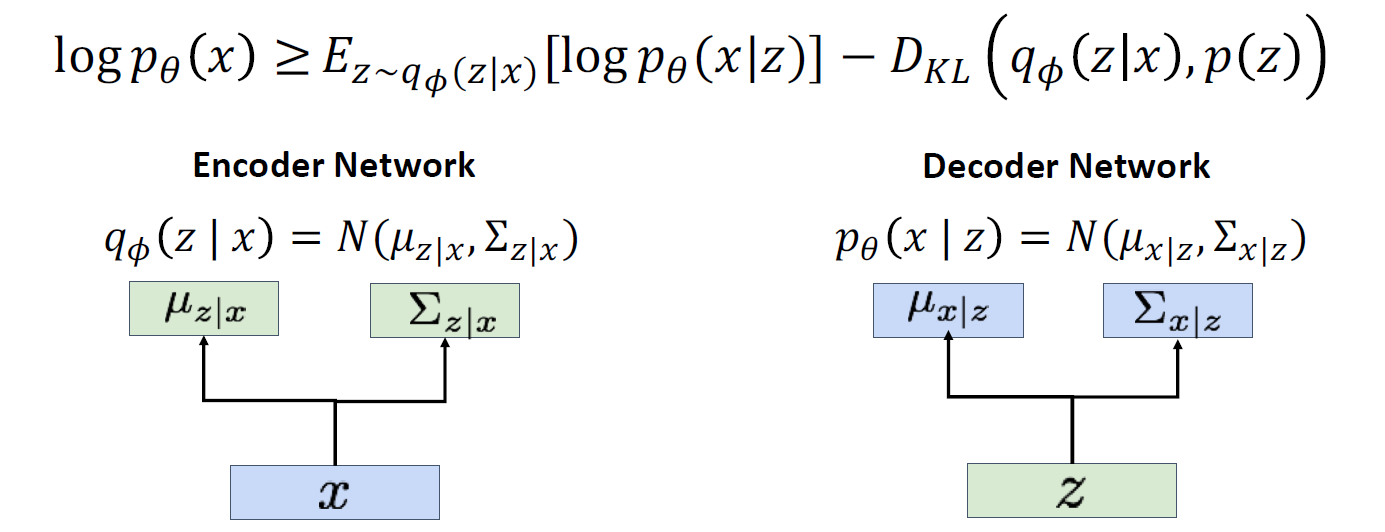
생성 모델 part 2
Review of Variational Autoencoders
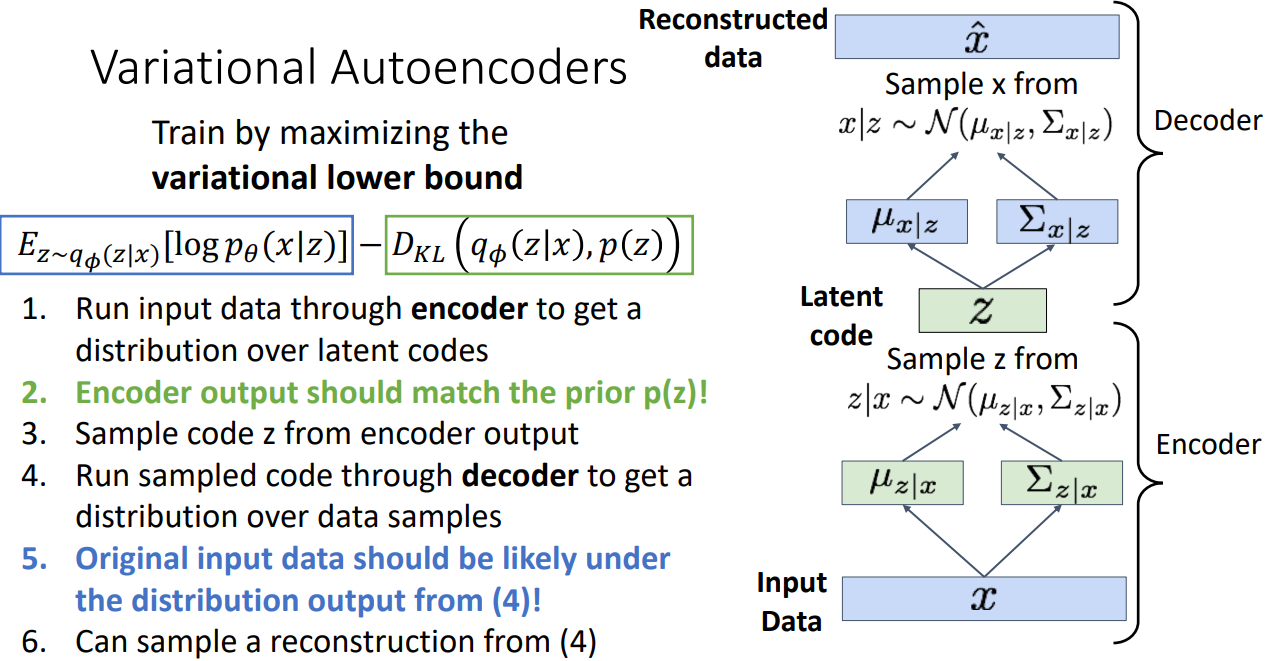
VAE는 Variational lower bound를 Maximize하여 간접적으로 모델을 학습함
VAE 목적함수
VAE의 학습 목표는 두 가지입
1) (파랑색 파트) 재구성 손실: 입력 데이터를 다시 잘 재구성하는 것 (이때 로그 가능도 log𝑝𝜃(𝑥∣𝑧) 최적화)
2) (초록색 파트) 정규화: 잠재 변수 z가 사전 확률 분포 p(z)를 따르도록 만드는 것 (KL Divergence를 최소화)
즉 인코더에서 나온 잠재 변수 분포 𝑞𝜙(z∣x)가 p(z) (사전 분포)와 가까워지도록 학습
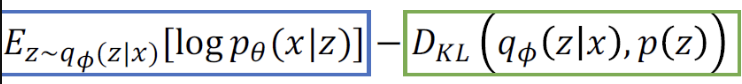
1) 인코더 학습과정
- lower bound를 maximize 하기 위해 첫 번째로 training set에서 mini-batch of data 를 취하고 encoder에 넣음
- 이런식으로 입력 데이터를 Encoder를 통과시켜 Latent codes의 분포를 얻음
- p(z/x) 가 나오게 되고 이것을 DkL term(2번째 term)에 집어넣게 됨
- 입력 데이터 x가 인코더를 거쳐 잠재 공간 z로 매핑될 때, 그 분포가 사전 확률 분포 p(z), 즉 Unit Gaussian (평균 0, 분산 1인 표준 정규분포)와 비슷하게 만들어야함.
- KL Divergence 항을 최적화하면서 인코더의 출력𝑞𝜙(z∣x)가 사전 확률 분포 p(z)와 최대한 가까워지도록 학습이 진행
- 왜 KL Divergence를 사용하는가: VAE는 잠재 변수를 사전에 정의된 단순한 분포(Unit Gaussian, 표준 정규분포)로 만들기 위해 학습. KL Divergence는 실제 인코더의 출력 분포와 사전 분포 간의 차이를 줄여주기 위한 도구
- KL Divergence 계산: KL Divergence는 두 Gaussian 분포 간의 차이를 측정하는데, 이 계산은 수학적으로 쉽게 closed form으로 해결할 수 있기 때문에 VAE에서 자주 사용

2) 디코더 학습과정
-
인코더를 통한 pridicted distribution에서 code z를 추출 할 수 있게 되고, 디코더 네트워크에 피드함
-
decoder network는 이미지 x에 대해 distribution을 예측
-
목적함수 중에 파랑색 파트: 인코더에서 예측한 z가 주어졌을 때, p(x/z) 값의 expectation, 즉 복원된 값이 원래랑 같아야 된다고 하며 학습을 진행 함
-
파란색 파트는 reconstruction을 잘 하는 방향으로 학습을 진행하고 많은 latent information 이 저장되도록 학습하지만, green term은 latent variables이 심플하고 gaussian을 따르도록 학습이 진행되어 일종의 constraint가 됨
-
이후 trained variational auto encoder로 새로운 data를 제작할 수 있음
2) 학습 완료 됐으면 생성
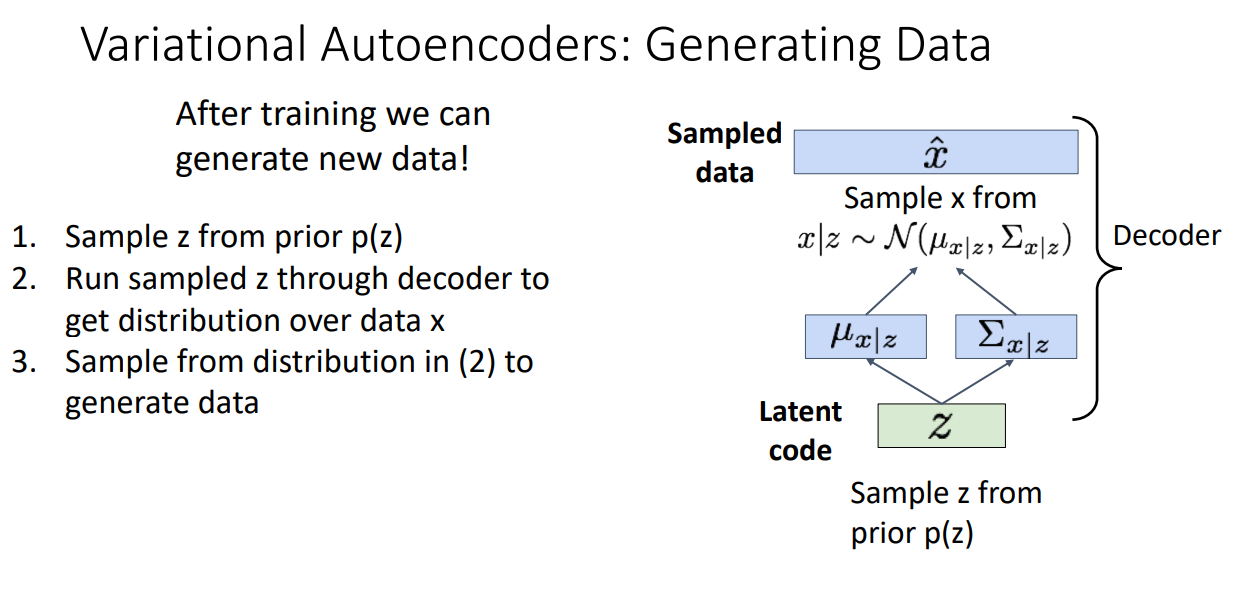
학습이 완료된다면 Decoder 만을 가져와서 생성을 진행
학습된 잠재 공간에서 잠재 변수(Latent code) z를 샘플링하고,
Decoder를 통해 이 z를 바탕으로 x에 대한 분포를 추정한 다음,
최종적으로 이 분포에서 샘플링하여 새로운 데이터를 생성
따라서, VAE를 사용하면 기존 데이터와 유사한 패턴을 가진 새로운 데이터를 생성할 수 있음
이 과정에서 잠재 공간의 z가 중요한 역할을 하며, 이 z가 Decoder를 통해 새로운 데이터로 변환되는 방식
다음과 같이 생성됨

VAE 특징 :
- 1)Disentangling factors of variation
- z의 분포를 Unit Gaussian에 match 되도록 학습을 진행하기 때문에, z의 차원이 서로 independent
- Unit Gaussian: 모든 차원이 평균 0과 분산 1을 갖는 다변량 정규 분포로, 각 차원이 독립적이고, 서로 상관성이 없도록 만듬
- 잠재 변수 z의 각 차원이 독립적으로 데이터의 서로 다른 특징을 나타냄
- latent z의 각 차원값들을 변화시키면 다른 이미지를 생성가능
아래 그림같이 latent z의 각 차원값들을 변화시키면 다른 이미지로 바뀜

- 2)Edit 가능
"Disentangling factors of variation" 특징 덕분에 VAE는 이미지를 edit 하는데 유용
Edit 방법은 원래 VAE 학습하는 과정과 유사한데 추가된 것은 Sample code z를 Modify하여
Decoder를 학습한다는 점
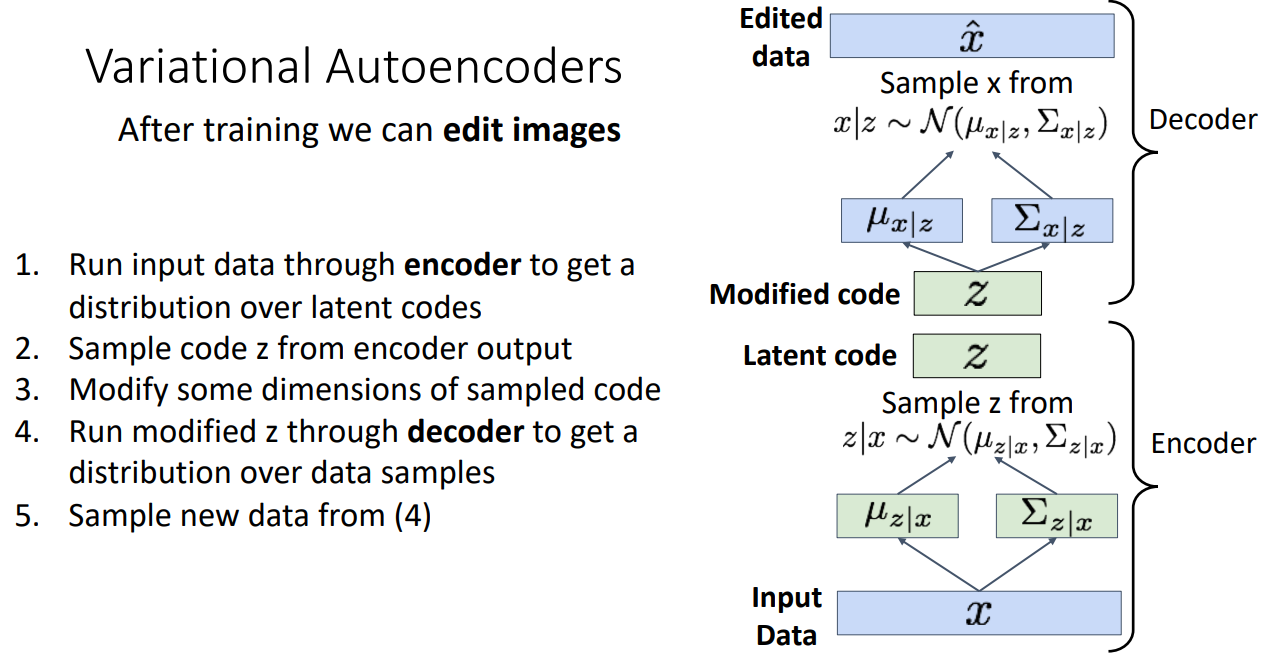
Edit 하도록 학습이 잘된다면 위 그림처럼 차원을 Degree of smile / Head pose로 나눠서 변형된 샘플을
생성 가능

VAE 단점 :
- Data Likelihood를 직접적으로 maximize하지 못하고, lower bound를 maximize 하는 방식으로
간접적으로 학습한다는 점 => 즉 good evaluation이 아님 - 19년 당시 SOTA 모델이었던 GAN 모델에 비해서 이미지들이 blurry하고 lower quality 라는 점

Autoregressive 모델과 VAE 모델 장단점 합친 모델 등장

VQ-VAE
VAE 처럼 학습하고, Latent code로부터 샘플링할 때는 PixelCNN을 사용
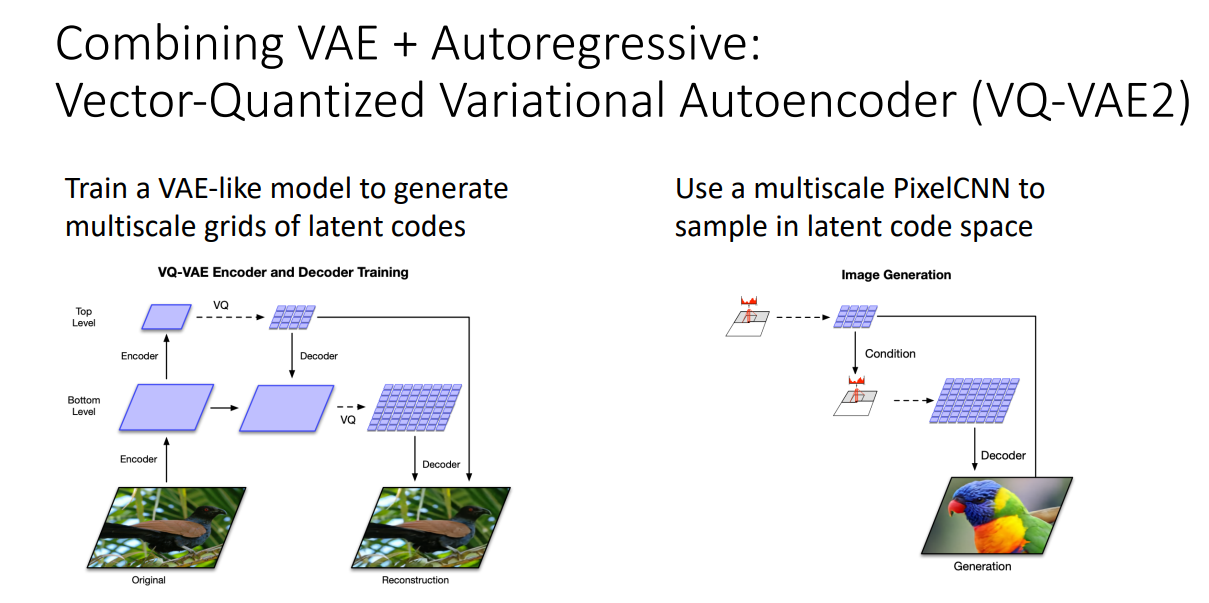
- VQ-VAE2를 사용하여 생성해낸 이미지 결과

Generative Adversarial Networks
Autoregressive 모델은 직접적으로 training data의 likelihood를 maximize 가능
VAE는 latent z를 도입했고, lower bound를 maximize 하는 방식으로 간접적으로 학습
적대적생성신경망(GAN)은 애초에 p(x) 모델링을 포기하고 샘플링만 잘하자라는 아이디어임

GAN 개요
데이터 xi는 pdata(x) 분포에서 나온다고 가정할 때,Latent variable인 z를 Generator Network G(z)에 통과시켜 생성한 x가 xi와 구분이 안되게 만들어주는 것
이를 위해서 Generator Network의 분포 pG를 pdata와 같도록 만들어주는 것
pG와 pdata가 같은지 다른지를 판단하기 위해서 Discriminator를 도입
Discriminator Network D는 data를 real(1) 또는 fake(0)으로 판단
결론적으로 이 Discriminator만 속이면 학습이 잘되었다 할 수 있음
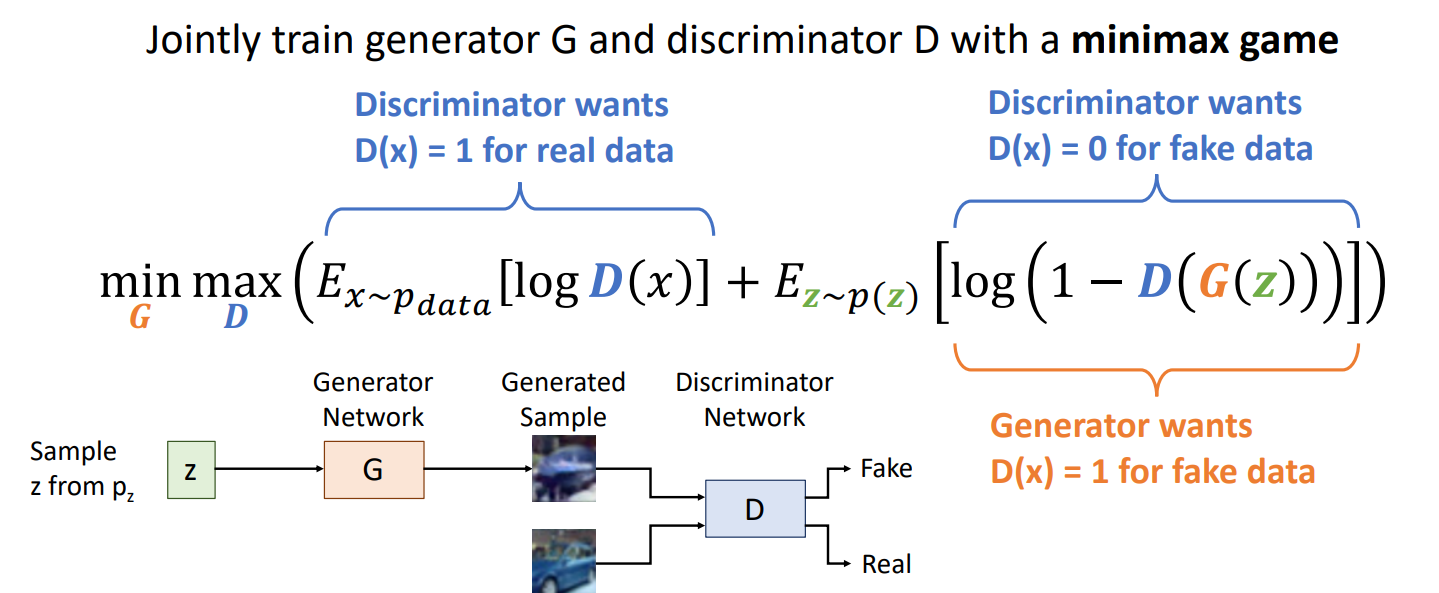
GAN 학습 목적 함수
Generator도 학습을 잘해야하고, Discriminator도 학습을 잘해야하는 상황
: minimax game
아래 그림에서 파란부분이 Discriminator, 주황부분이 Generator
- Discriminator는 Real data에 대해서는 1 / Fake data에 대해서는 0을 도출하도록 학습이 되어야하기 때문에 위 식을 최대화하고자 함
- Generator는 Discriminator가 생성된 데이터에 대해서도 1을 도출하도록 학습되기를 기대해야하기 때문에 위 식을 최소화
G와 D를 번갈아가면서 gradient update하여 학습
Discriminator update 하고 Generator update하고 계속 반복
이 경우에 전체적인 Loss를 minimize 하는 상황이 아니기 때문에 training curve는 볼 필요없음
아래 그림은 D(G(z)) 의 모습
- 파란색: 원래 Training objective에 있는 모습인데 보시면 학습 초반에는 Generator가 별로여서 0에 가깝다가 학습이 진행되면서 점점 낮아지는 모습
=> 근데 파란색처럼 학습했다가는 Gradient Vanishing 문제 발생 ! - 파란색 식을 minimize 하는 대신 주황색 식을 maximize 하는 방식으로 학습한다면 Generator가 더 strong한 gradient를 학습 초기에 갖게됨

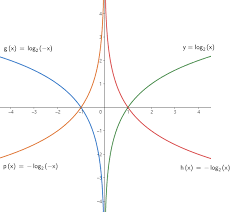
GAN 최적화
Training Objective가 JSD term을 포함한 간단한 minimize 문제가 됨
해당 minimize 문제의 최적 값을 구하면 아래 그림의 Summary 부분

최적화 시 주의할 점
- Discriminator와 Generator는 고정된 구조의 신경망이기 때문에 실제로 optimal Discriminator와 Generator를 나타내지 못할 수 있음
- 번갈아가면서 학습을 진행하기 때문에 Convergence 가 이뤄지지 않을 수 있을 위험이 있음

Application of GAN
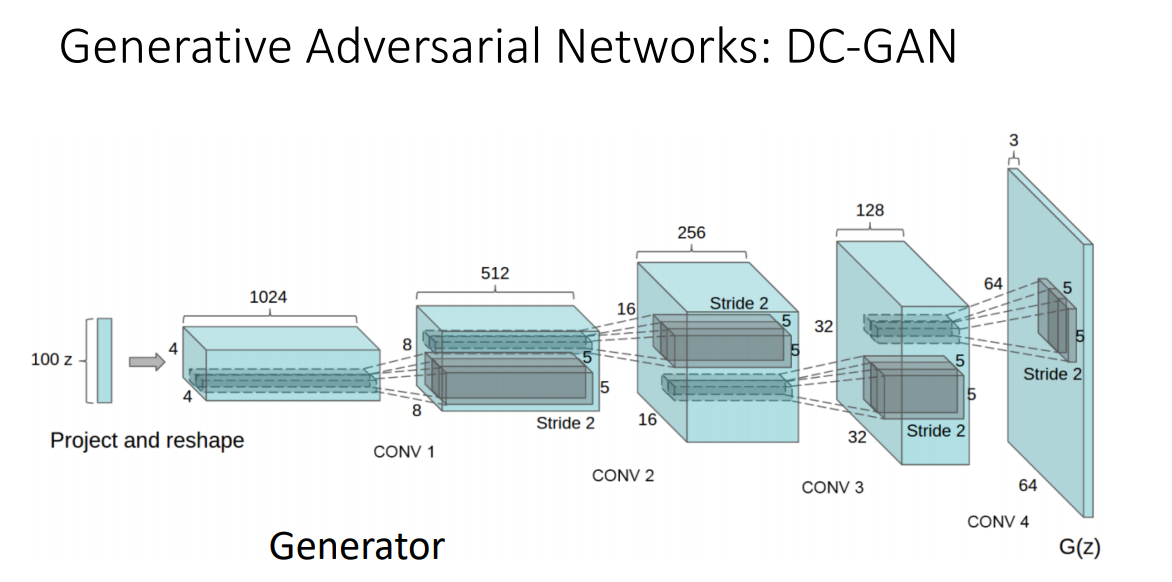
1) DC_GAN
CNN 구조와 GAN을 합친 구조

Latent z space의 두점을 보간하는 방식으로 이미지를 생성한다면
아래 같이 이어지는듯 유사한 이미지를 만들어낼 수 있음

Semi-interpretable vector map
Vector 계산하듯 이미지를 계산해서 원하는 이미지를 만들어낼 수 있음
아래 예시는 '안경 쓴 남성' 이미지에서 '안경 안 쓴 남성' 이미지를 빼고 '안경 안 쓴 여성' 이미지를 더한다면 결과적으로 '안경 쓴 여성' 이미지가 나오는 예시

Wasserstein GAN
Loss function을 수정하여 더욱 좋은 성능으로 이미지 샘플링

생성 결과

Conditional GANs(CGAN)
GAN은 무작위의 이미지를 생성해내지만 input으로 label 값을 같이 넣어준다면 원하는 class의 이미지만 생성해낼 수도 있음
- 기존 GAN 과 다르게 train data로 학습시켜 비슷한 data를 output으로 generate 하는 것이 아닌, 어떤 label을 generate 할 지 정함
따라서, label y를 input으로 추가
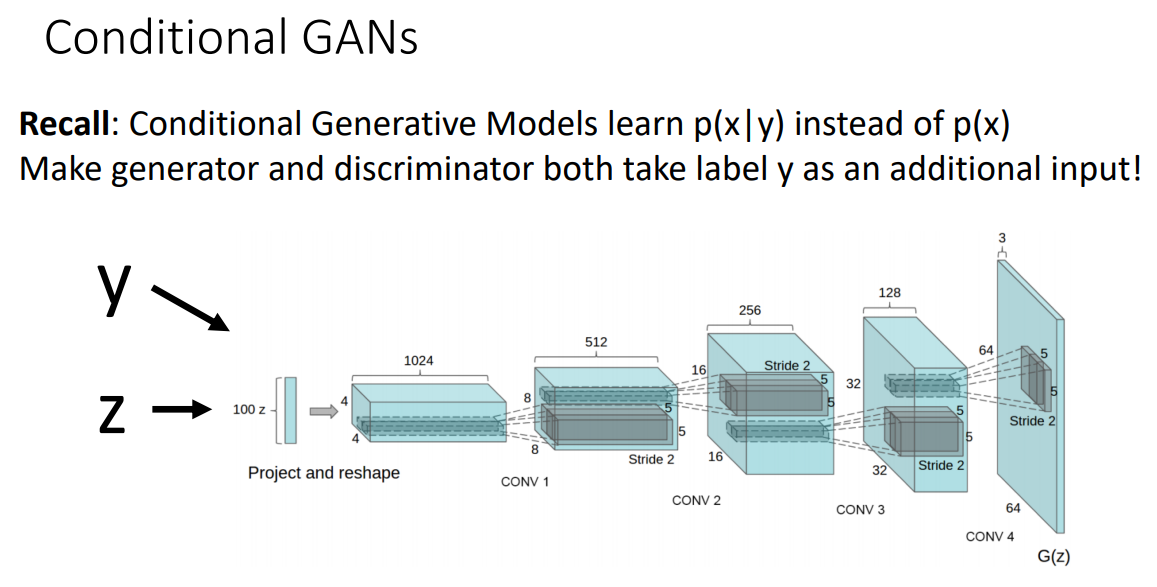
레이블 반영 방법 : input 값에 넣어줘도 되지만, 이처럼 Batch Normalization을 수행할 때 학습 가능한 파라미터인 scale과 shift 계수에 레이블 정보를 반영해줘도 됨 - Test 시 label을 지정하면 그것에 맞는 이미지 생성

결과 :
GAN에 Self-attention을 결합한 경우에도 고퀄리티의 이미지를 생성해낼 수 있음

단순히 Label 값을 넣어서 원하는 이미지를 생성해내는 것을 넘어, 문장을 입력으로 넣어서 해당 문장에 맞는 이미지를 생성해낼 수도 있음 즉 conditioning 을 label에서 text까지 가능함

- 해상도를 높이는 Super-Resolution
- 자기 자신 이미지를 upsampling 도 가능

- 자기 자신 이미지를 upsampling 도 가능
- 스케치 이미지도 실제 사물처럼 그려주는 GAN

- 이미지의 부분을 label map을 만들어 나누고 이를 이미지화 할 수 있음
semantic map과 style 이미지를 합치는 것

- 이미지 뿐만이 아니라, 사람들의 이동 경로를 예측하기도 함

요약
-
3가지 방법을 확인
1) Autoregressive Models
2) Variational Autoencoders
3) Generative Adversarial Networks -
GAN은 아주 많은 application이 가능하고, 높은 퀄리티의 이미지를 만들 수 있음

