요약
- Two-Stage Object Detection은 Region Proposal을 통해 객체가 있을 법한 후보 영역을 제안하고, 이를 기반으로 객체의 위치와 클래스를 예측하는 방식임.
- Single-Stage Object Detection은 한 번의 네트워크 처리로 객체의 위치와 클래스를 동시에 예측하는 방식임. 대표적인 예로는 YOLO와 SSD가 있음.
- Anchor Boxes는 이미지의 각 픽셀마다 다양한 크기의 사각형 박스를 설정해, 객체 탐지를 학습하는 방식임.
- Segmentation은 객체의 정확한 경계를 픽셀 단위로 구분하는 기술로, Instance Segmentation과 Semantic Segmentation으로 나뉘며, 각각 개별 객체와 동일 클래스 내 객체를 구분하는 방식임.
- Pooling과 Unpooling은 이미지의 특징을 추출하고 복원하는 과정에서 중요한 역할을 하며, 이를 통해 객체의 형태를 더 정밀하게 인식할 수 있음.
- 선형 보간(linear interpolation)은 객체의 특징을 정확하게 추출하고 역전파 과정에서 매끄러운 그래디언트를 유지하기 위해 사용되는 기법임
Computer Vision Task
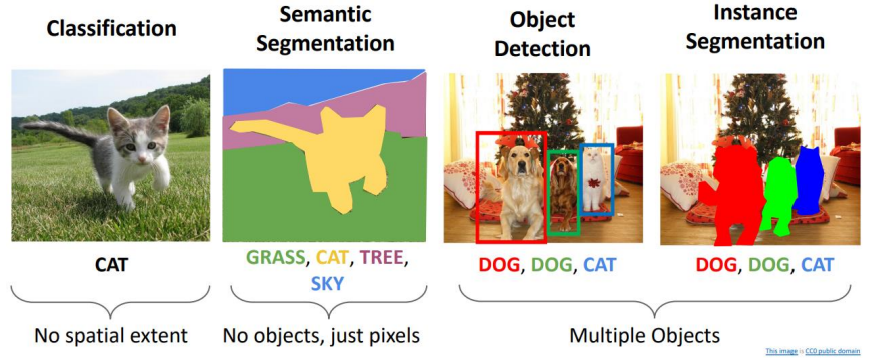
Object Detection과 Segmentation은 컴퓨터 비전에서 이미지 내 객체를 탐지하고 구분하는 두 가지 핵심 기술임. 각각의 기술은 서로 다른 방식으로 이미지 내 객체를 이해하며, 다양한 알고리즘과 기법들이 적용됨. 특히 선형 보간(linear interpolation)과 같은 기법은 더욱 정밀한 특징 추출을 위해 중요한 역할을 함. 이 두 기술에 대한 개념과 주요 알고리즘에 대한 설명임.
1. Object Detection (객체 탐지)
Object Detection은 이미지 내 객체를 탐지하고, 각 객체의 위치를 바운딩 박스로 표시하는 작업임. Object Detection에는 Two-Stage와 Single-Stage 방법이 있음.
1.1 Two-Stage Object Detection - 대표적으로 RCNN (Region-based CNN) 계열
-
Region Proposal:
먼저 이미지에서 객체가 있을 법한 영역을 찾는 과정임. 이 영역을 region proposal이라 부르며, 후보 영역을 사각형 박스로 제안함.
-
선형 보간(linear interpolation):
Region Proposal 내에서 특징을 추출할 때, 더 정확한 피쳐 맵을 얻기 위해 선형 보간이 사용됨. 스냅핑(snapping)을 사용할 경우, 값이 픽셀 단위로 고정되어 역전파(gradient backpropagation)에 문제가 생길 수 있음. 이를 해결하기 위해 선형 보간을 사용해 중간 값들을 매끄럽게 보간하여 그래디언트가 부드럽게 전달되도록 함.
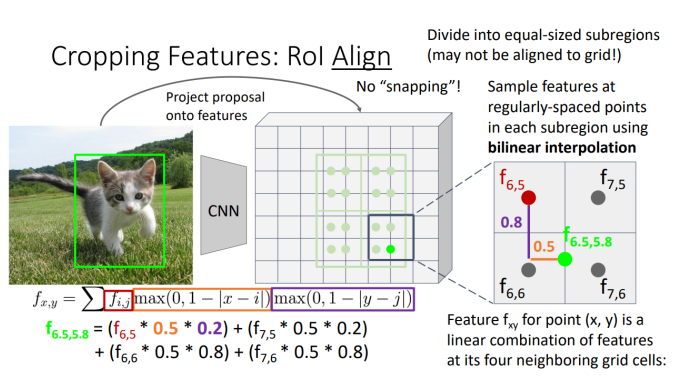
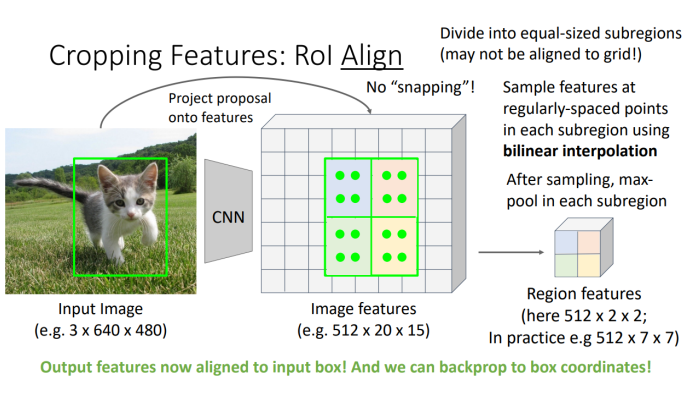
- 선형 보간은 두 점 사이의 값을 선형적으로 계산하여 중간에 위치한 값을 추정하는 방식임. 예를 들어, 네 개의 점에서 각 픽셀 값을 선형적으로 보간해 더 부드러운 특성 맵을 얻을 수 있음. 이 과정은 객체의 특징을 더 정확히 추출하고, 역전파 시 매끄러운 그래디언트를 유지하는 데 필수적임.
- 이 기법은 특히 객체의 특징을 정확히 뽑아내기 위해 필요하며, 선형 보간된 픽셀들이 객체의 경계에서 더 나은 예측을 제공함.
-
Pooling:
각 Region Proposal 영역에 대해 ROI (Region of Interest) Pooling을 수행하여 특정 영역의 특징을 추출함. 여기서 선형 보간된 특징이 객체의 특징을 더 정확히 반영함.
-
Second Stage:
추출된 피쳐 맵을 기반으로 객체의 클래스와 바운딩 박스를 예측함. 첫 번째 단계는 객체가 있을 법한 영역을 제안하고, 두 번째 단계는 객체의 위치와 클래스를 정확히 예측하는 구조로 나뉨.
1.2 Single-Stage Object Detection
Single-Stage Object Detection은 Two-Stage와 달리 Region Proposal과 Object Classification을 한 번에 처리하는 방식임. 대표적인 모델로는 YOLO(You Only Look Once)와 SSD(Single Shot MultiBox Detector)가 있음.
YOLO (You Only Look Once):
YOLO는 이미지를 그리드(grid)로 나누고, 각 그리드 셀에서 바운딩 박스와 클래스 확률을 예측함. 즉, YOLO는 이미지의 각 부분을 한 번만 살펴보며, 이를 통해 객체를 예측하는 방식임.
YOLO의 핵심 개념은 end-to-end 방식으로 이미지를 한 번에 처리하여 빠르고 효율적인 객체 탐지를 수행하는 것임. 이를 통해 실시간 객체 탐지가 가능함.
SSD (Single Shot MultiBox Detector):
-
SSD는 다양한 크기와 비율의 default boxes(기본 박스)를 사용하여 이미지를 한 번에 처리하고, 객체의 위치와 클래스를 동시에 예측함. 기본적으로 각 위치에서 여러 크기의 바운딩 박스를 사용하여 다양한 스케일의 객체를 탐지할 수 있음.
-
기본 박스(anchor box)는 모든 픽셀에 다양한 크기의 박스를 설정하고, 네트워크를 통해 객체가 포함된 박스를 찾아냄. 이 과정에서 anchor box와 실제 객체의 위치 차이를 줄이며 학습이 이루어짐.
1.3 Anchor Boxes - 앵커 박스
- 앵커 박스(Anchor Box)는 객체 탐지에서 중요한 개념으로, 이미지 내 픽셀마다 다양한 크기와 비율의 사각형 박스를 미리 설정해 두고, 각 박스가 객체에 해당하는지 여부를 학습하는 방식임.
- 모든 픽셀에 앵커 박스 생성: 각 픽셀에 여러 크기와 비율의 앵커 박스를 설정하고, 학습을 통해 실제 객체가 있는 앵커 박스만 남기고 나머지 불필요한 박스는 제거함.
네트워크 학습: 앵커 박스와 실제 객체 간의 차이를 줄여가며, 가장 적합한 앵커 박스를 선택하고, 불필요한 박스를 제거하는 방식으로 학습됨.
2. Segmentation (세그멘테이션)
Segmentation은 이미지 내 객체를 픽셀 단위로 구분하는 작업임. 객체 탐지가 객체의 위치를 사각형으로 나타낸다면, 세그멘테이션은 픽셀 단위로 객체를 구분하여 객체의 정확한 형태를 추출함.
2.1 Instance Segmentation과 Semantic Segmentation
Instance Segmentation:
같은 클래스에 속하는 여러 객체를 개별적으로 구분하는 방식임. 예를 들어, 여러 마리의 고양이가 있으면 각각의 고양이를 개별 객체로 인식함.
Semantic Segmentation:
객체의 개별성을 구분하지 않고, 같은 클래스에 속하는 모든 픽셀을 하나의 범주로 구분함. 즉, 모든 고양이를 동일한 클래스로 인식함.
-
Semantic Segmentation에서 Fully Convolutional Network(FCN)를 사용하여 모든 픽셀에 대한 예측을 동시에 수행
입력 이미지를 Conv 레이어로 처리한 후 각 픽셀의 클래스 레이블을 결정하는 방식임. -
이 과정에서 Conv 레이어를 여러 층 쌓으면서 receptive field가 선형적으로 증가함에 따라 더 깊은 레이어가 필요해짐. 또한, 고해상도 이미지를 처리하는 데 계산 비용이 매우 크다는 문제점이 존재함.

-
이를 해결하기 위한 방법으로 다운샘플링(downsampling)과 업샘플링(upsampling) 기법이 활용됨.
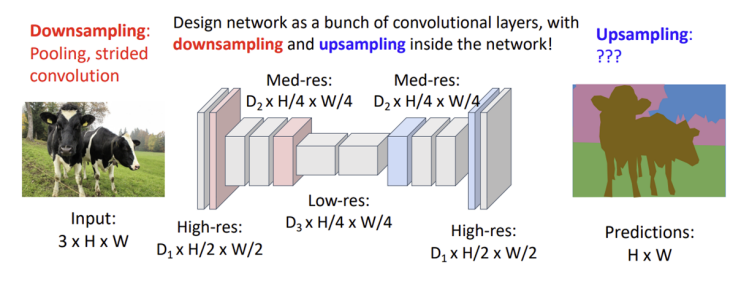
-
다운샘플링:
Pooling이나 stride를 사용해 고해상도 이미지를 낮은 해상도로 줄여 계산 효율을 높이는 과정임.
-
업샘플링:
낮은 해상도로 줄어든 이미지를 다시 원본 해상도로 복원하는 과정임. 2개가 있음 대표적으로.
-
업샘플링 1) Unpooling:
다운샘플링된 이미지를 복원하는 대표적인 방식임. Bed of Nails 방식은 빈칸을 0으로 채우는 방식이고, Nearest Neighbor 방식은 가장 가까운 픽셀 값을 복사하여 자연스럽게 채우는 방식임.
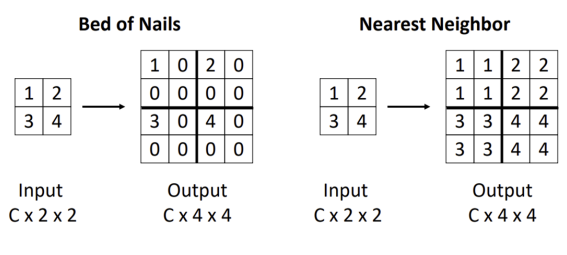
-
업샘플링 2) Bilinear Interpolation(선형 보간법):
더 부드러운 업샘플링을 가능하게 하는 방법임. 인접한 두 개의 이웃 픽셀 값을 이용해 선형적으로 값을 보간하여 경계를 자연스럽게 처리할 수 있음.
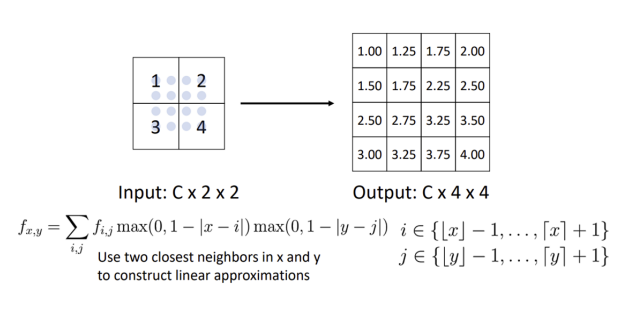
-
3. Pooling과 Unpooling
Pooling:
CNN에서 풀링은 이미지의 크기를 줄이면서 중요한 정보를 추출하는 과정임. 맥스 풀링(Max Pooling)을 통해 특정 영역에서 가장 큰 값을 선택해 중요한 특징만 남기고, 나머지는 버림.
맥스 언풀링(Max Unpooling):
풀링할 때 저장했던 좌표를 기억하고, 그 좌표를 이용해 업샘플링하는 방식임. 이는 다운샘플링된 이미지의 중요한 특징을 유지하면서 원본 크기로 복원하는 작업임.
