주요 내용 :
- Neural Networks를 학습하기 위한 기법들
- 1) Learning Rate Schedules
- 2) Choosing Hyperparameters
- 3) Learning Curves
- 4) Model Ensembles
- 5) Transfer Learning
- 6) Distributed Learning
1) Learning Rate Schedules
- 학습률은 대부분의 최적화 방법론에서 하이퍼파라미터
- 사용자가 직접 지정해줘야 하는 값이며, 크기에 따라 성능에 큰 영향을 미침
- 학습률이 너무 크면 gradient 폭발로 인해 loss가 치솟는 문제 발생
- 학습률(Learning Rate)은 가중치(Weights)를 업데이트할 때 얼마나 크게 조정할지를 결정하는 하이퍼파라미터
- 만약 학습률이 너무 크다면, 각 가중치 업데이트의 크기가 너무 커져서 모델의 가중치가 매우 큰 값으로 점프하게 됨 => 손실 함수의 최소값으로 수렴하는 것이 아니라, 손실 함수의 경사를 따라 크게 이동하면서 오히려 손실 값이 더 커질 수 있음
- 큰 기울기 값들이 계속해서 누적되면서 기울기가 폭발적으로 커지게 되고, 이로 인해 가중치가 매우 큰 값으로 갱신되면서 네트워크가 불안정해짐
- 학습률이 너무 낮으면 학습 속도가 느려짐
- 적절한 학습률을 선택하면 빠르게 수렴하면서도 좋은 성능을 보일 수 있음.
- High → Low 학습률 전략
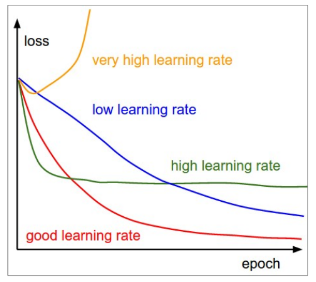
높은 학습률로 빠르게 수렴하고, 점차 줄여서 적절하게 수렴하는 전략을 사용함.
Step Learning Rate Decay
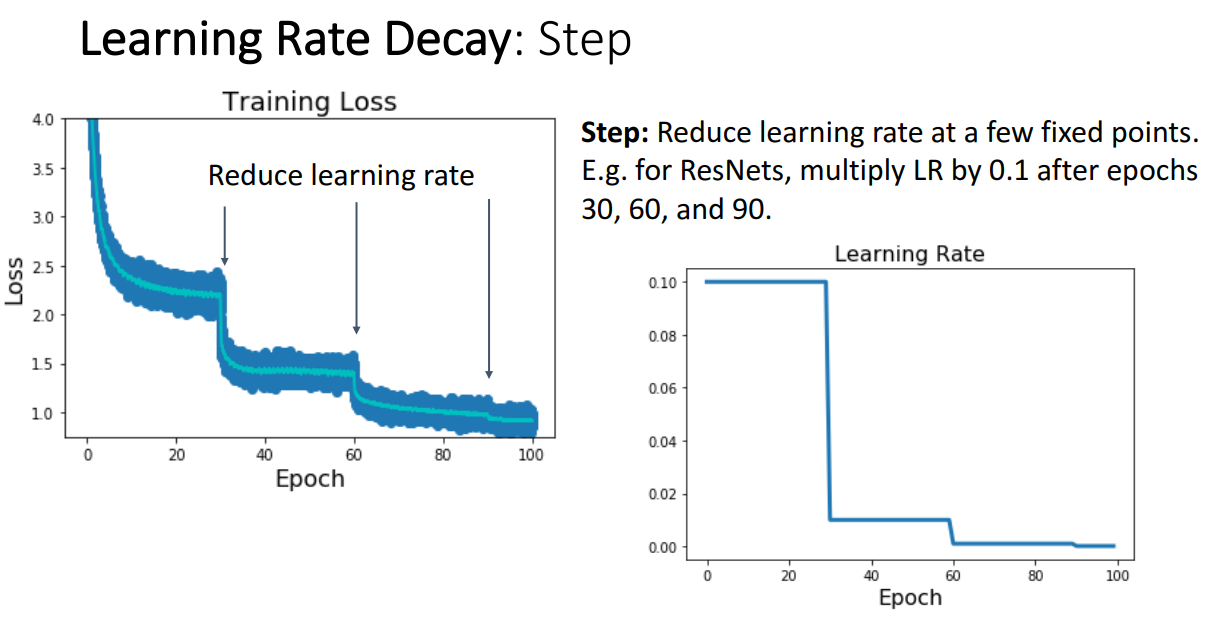
- 학습 진행에 따라 일정 간격으로 학습률을 줄이는 방식
- 예시: 30 epoch마다 LR에 0.1을 곱해 학습률을 줄임.
- 결과적으로 Loss 값이 계단식으로 감소하는 패턴을 보임.
- 결정해야 할 하이퍼파라미터 :
- 처음 시작할 때의 LR
- 학습률을 얼마나 줄일 것인지
- 언제 줄일 것인지
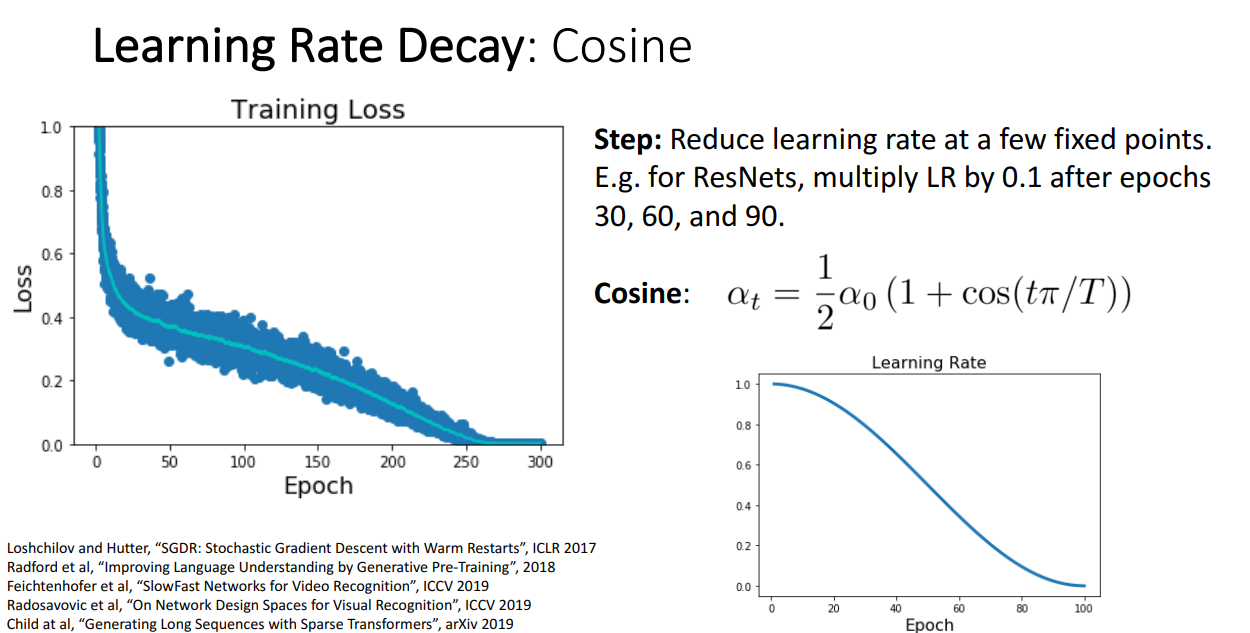
Cosine Learning Rate Decay
- Cosine 함수에 따라 학습률을 줄이는 방식
- Step 방식보다 하이퍼파라미터가 적고, 튜닝하기 쉬움.
- Computer Vision에서 많이 사용됨.
- 하이퍼파라미터: α0와 T
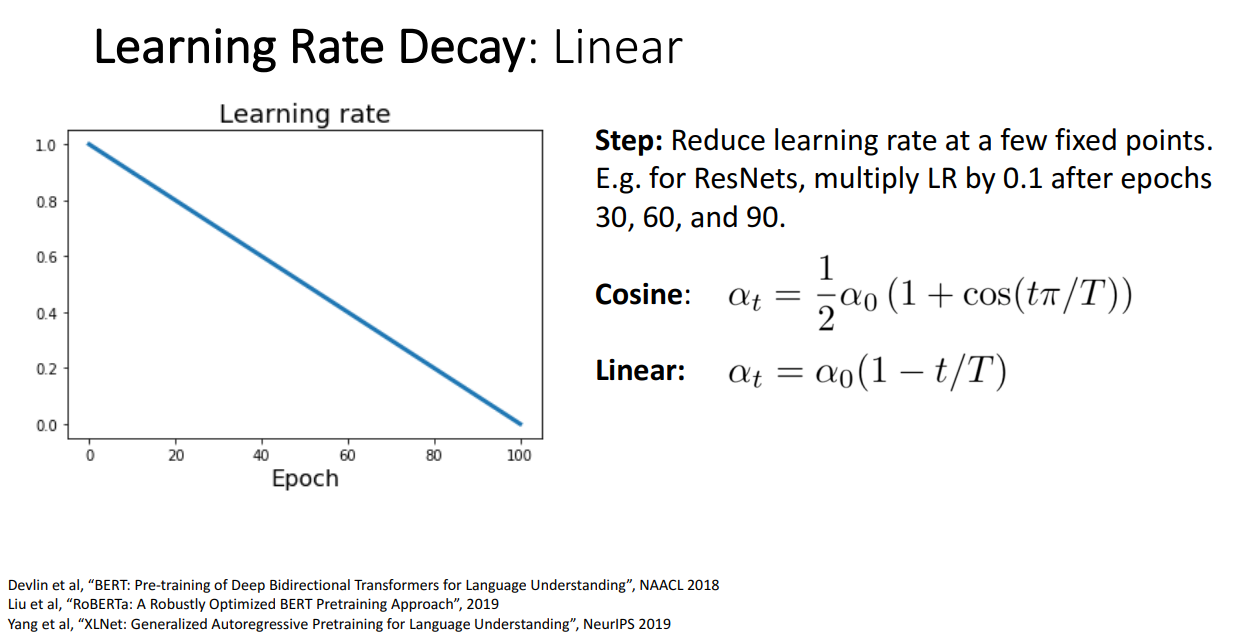
Linear Decay
- Cosine Decay와 유사하지만, Linear하게 학습률을 줄여나가는 방식임.
- 성능이 유사하지만 매우 단순한 방식임.
- NLP에서 많이 사용됨.
Inverse Sqrt Decay
- 학습률을 점차 줄이는 방식
- 초반에 빠르게 줄이고, 뒤로 갈수록 천천히 줄어듦
- 정해줘야할 하이퍼파라미터는 α0
- Transformer 모델에서 자주 사용됨
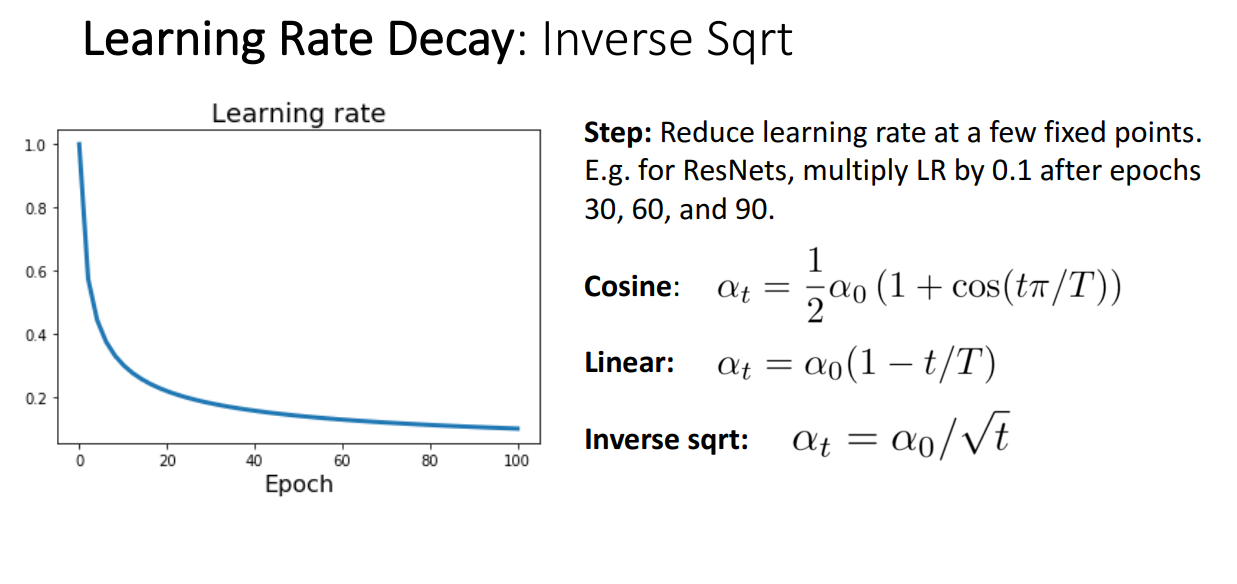
Constant Learning Rate
- Constant LR을 사용해도 성능이 나쁘지 않음.
- Adaptive한 LR 방식이 틀릴 때도 있기 때문에, 단순하게 Constant로 설정할 때도 있음.
- Momentum을 사용하는 최적화 방법에서는 LR Decay 사용 추천
- RMSProp, Adam 등에서는 Constant LR 사용도 무방
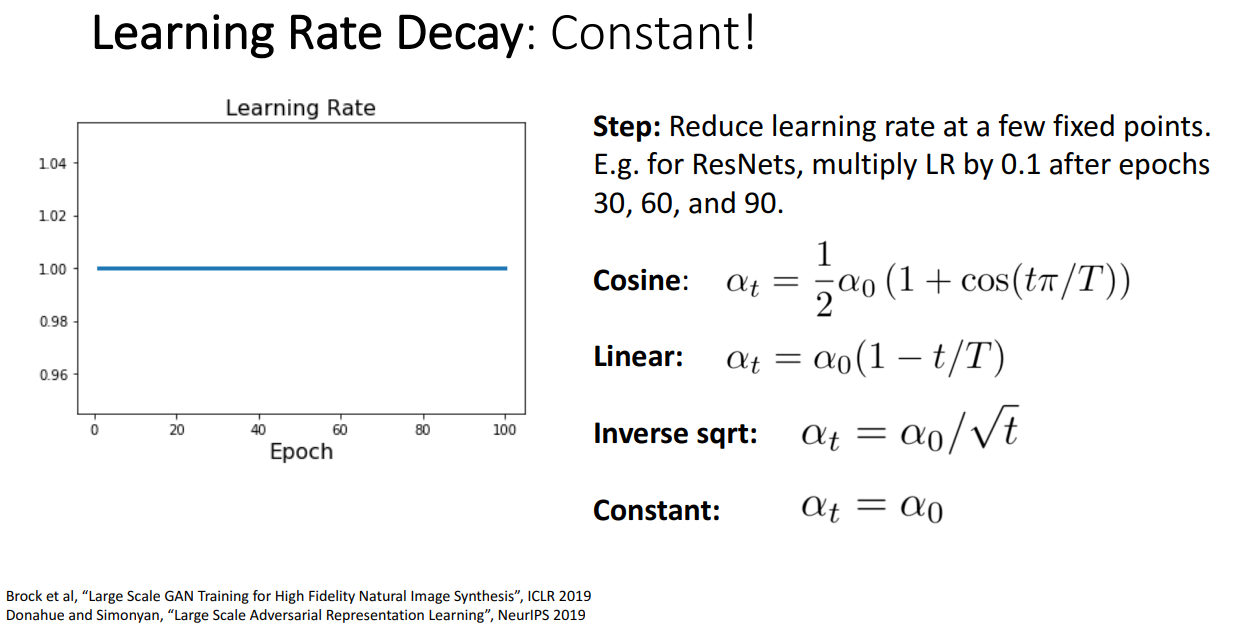
Early Stopping
- 제일 추천 방식
- 학습 도중 Var Acc가 가장 높을 때 학습을 멈추는 방법
- 학습이 과도하게 진행되어 exploding 되는 상황 방지
2) Choosing Hyperparameters
- 하이퍼파라미터를 적절하게 고르는 것이 중요함.
- 대표적인 방법: Grid Search와 Random Search
- 1) Grid Search
- 하이퍼파라미터의 후보 Set을 정해 모든 조합을 살펴보는 방식
- 단점: GPU가 충분하지 않다면 모든 조합을 살펴보는 데 어려움이 있음.
- 2) Random Search
- 하이퍼파라미터의 range를 정해 그 안에서 random value로 설정하는 방식
- Grid Search보다 더 효율적인 방법임.
- 중요한 파라미터의 최적값을 찾을 확률이 높아짐.
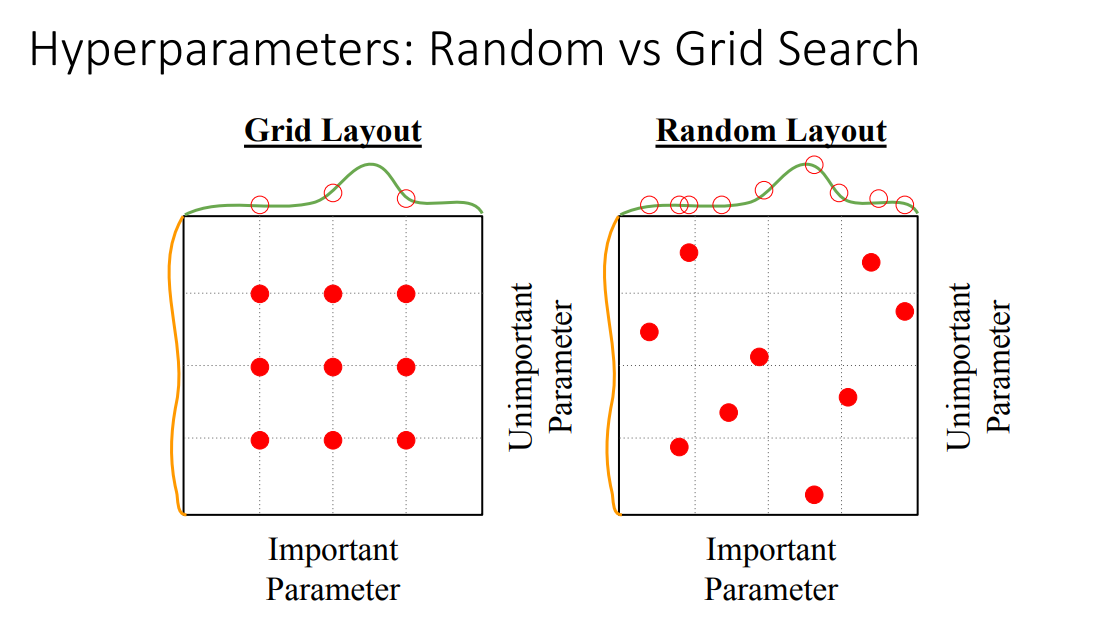
- 비슷해보이지만 Random Search 방법이 훨씬 좋음
- 안 중요한 파라미터와 중요한 파라미터가 있을때 Grid Search의 경우 두 파라미터의 격자에 해당하는 조합만 사용가능, 즉중요한 파라미터의 최적 값을 사용할 수 없을 수도 있음
- Random Search는 굳이 격자에 해당하는 값 아니어도 설정할 수 있기 때문에 확률적으로 중요한 하이퍼파라미터의 최적값을 찾아낼 수 있음
- 1) Grid Search
- 3) Step-wise Approach for Hyperparameter Tuning
- GPU가 충분하지 못할 때 하이퍼파라미터를 잘 고르는 방법
- Step 1: Weight decay를 끄고 loss가 적절하게 설정되었는지 확인함.
- Step 2: 적은 양의 학습 데이터로 100% 정확도를 도출해봄
- Regularization을 끄고 Overfitting 되도록 학습 !
- Step 3: Loss를 잘 줄일 수 있는 LR을 찾음.
- 일반적으로 좋다고 알려진 LR: 1e-1, 1e-2, 1e-3, 1e-4
- Step 4: LR와 Weight decay를 여러 조합으로 실험함.
- 일반적으로 괜찮은 weight decay는 1e-4, 1e-5, 0
- Step 5: LR decay 없이 더 긴 학습을 통해 최선의 모델을 찾음.
- Step 6: Learning Curves를 분석함
4) Learning Curves
- Loss는 상당히 Noisy할 수 있기 때문에, 각 학습별로 산점도를 그리고 Trend를 알 수 있는 Moving average를 뽑기
- Learning curve를 잘 보면 무엇이 잘못 되었는지를 알 수 있음
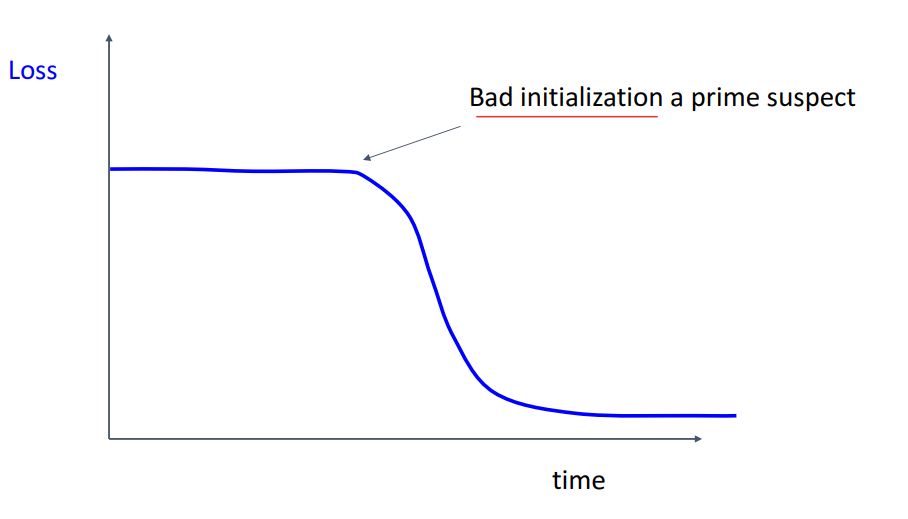
- 1) Loss가 flat하다가 갑자기 떨어지면 애초에 Initialization이 잘못 됐을 수 있음
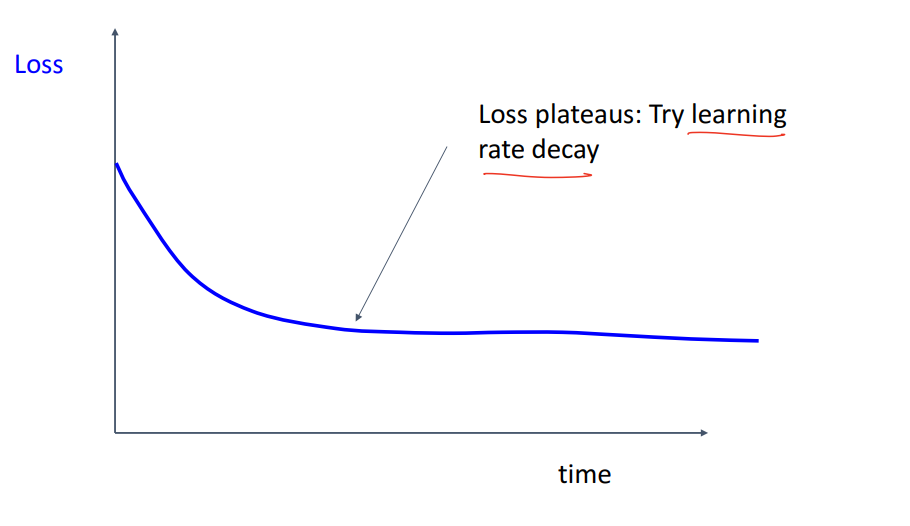
- 2) Loss가 이렇게 평평해지면 Learning rate decay 고려해봐야함
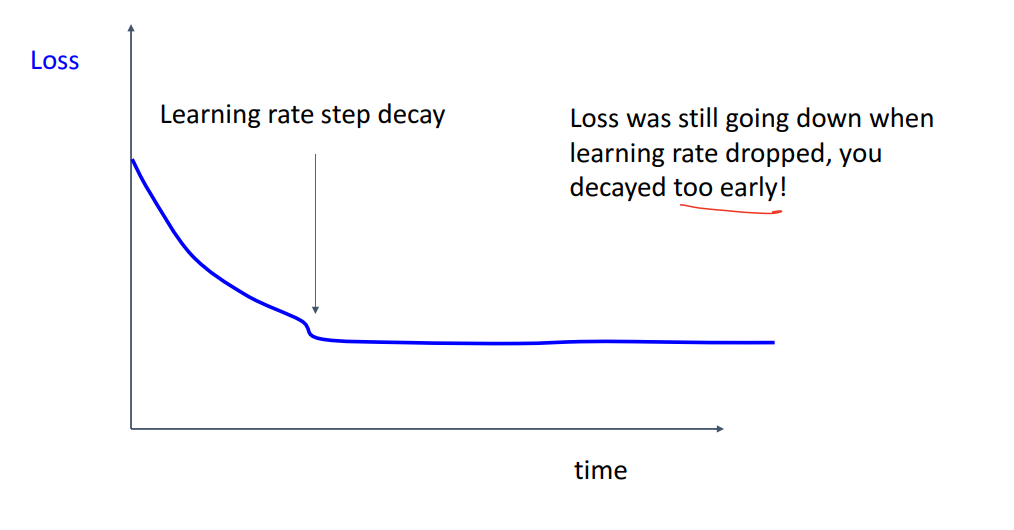
- 3) Learning rate decay 후에도 Loss가 더 떨어지는 경향이 있다면 Decay를 너무 빨리 한 것
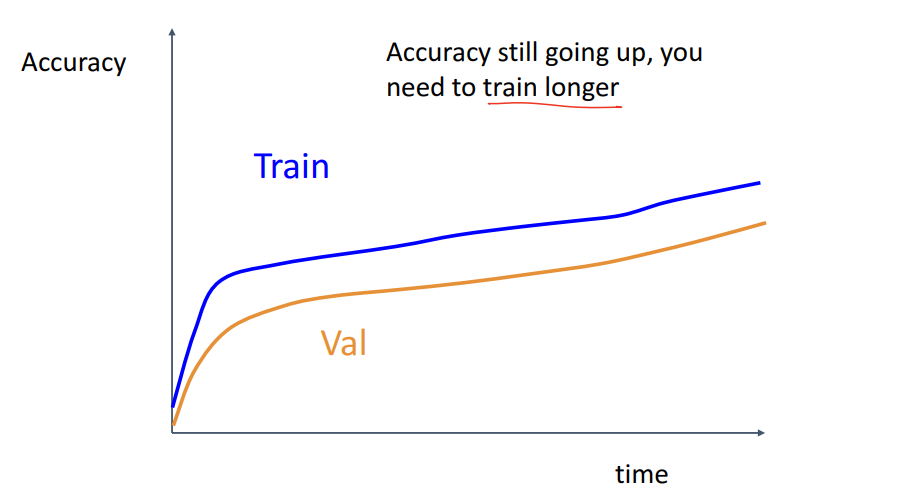
- 4) Acc가 계속 올라간다면 학습을 더하기
- 5) Train과 Val 정확도 gap이 너무 크면 Regularization이나 학습 데이터를 더 확보해서 Overfitting을 막기
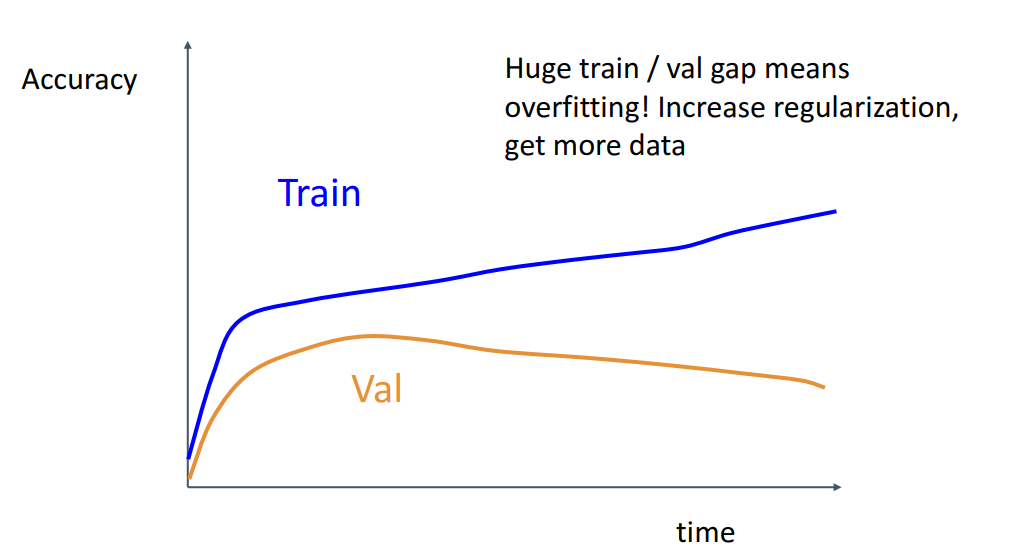
- 6) Train과 Val 정확도 gap이 너무 작아서 비슷하다면
Undefitting 의심. 학습을 더 오래하거나, 더 거대한 모델 사용하시
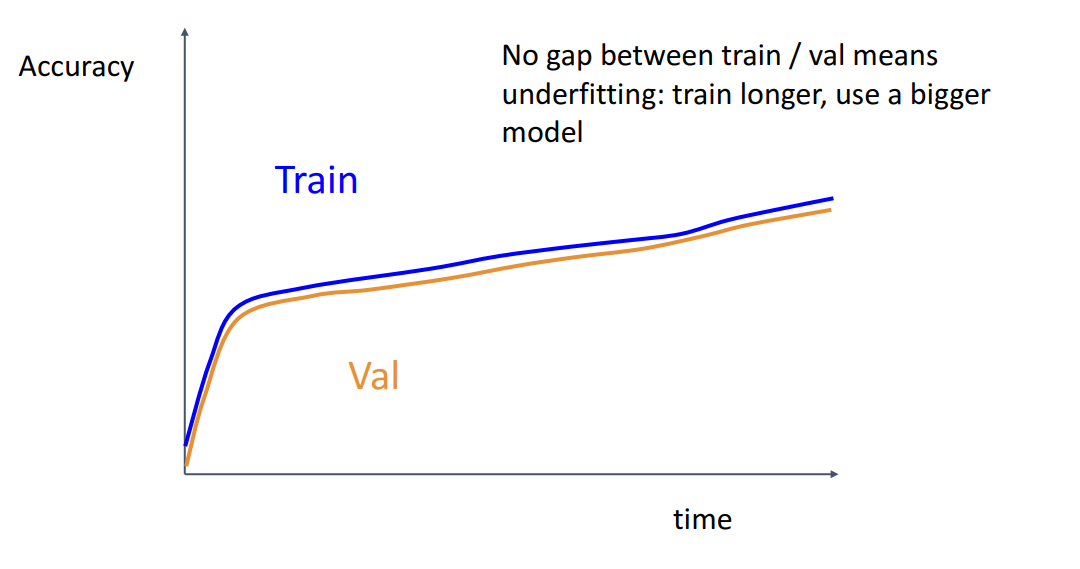
- 1) Loss가 flat하다가 갑자기 떨어지면 애초에 Initialization이 잘못 됐을 수 있음
Model Ensembles
-
학습이 끝난 후 정확도를 더 높이기 위한 방법으로 앙상블을 사용
-
Snapshot Ensemble: Cyclic한 LR 스케줄에 따라 여러 모델을 순차적으로 학습
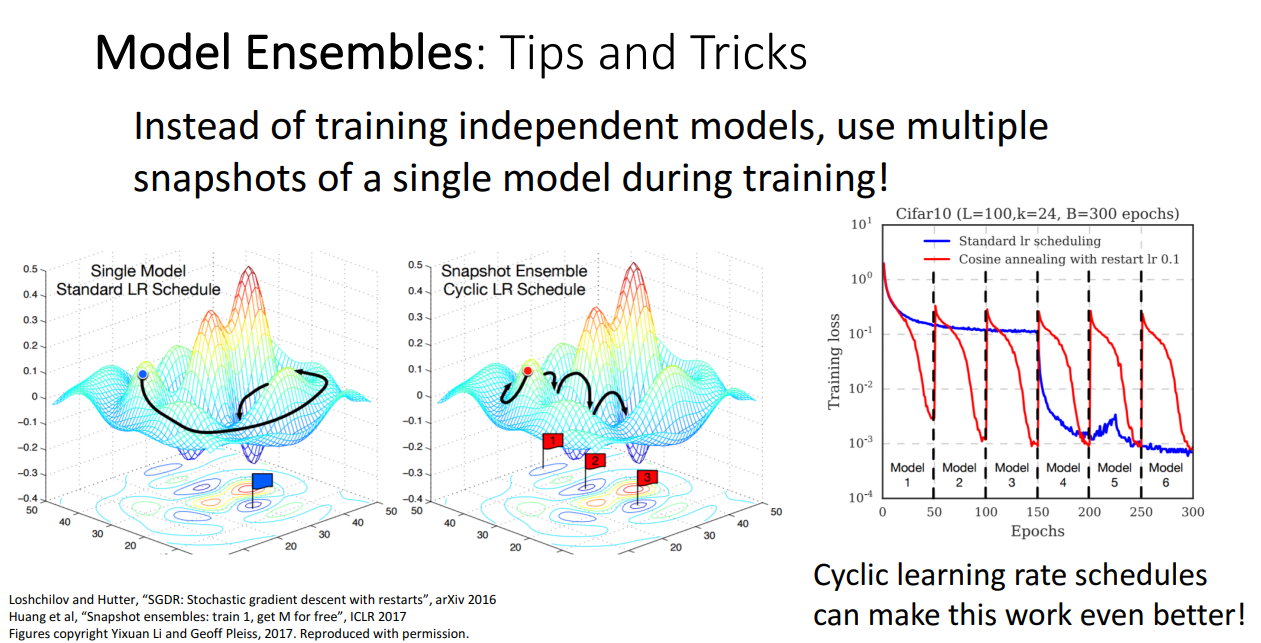
-
Polyak averaging: 파라미터 대신 평균을 사용하는 방식임

Transfer Learning
-
CNN 같은 모델을 학습하고 사용하려면 무조건 많은 데이터가 필요하다는 전제를 깨부순 학습 방법
- 많은 데이터를 필요로 하지 않음
-
전이학습:
- 예) 데이터셋으로 CNN 구조를 학습시키고 분류 Task를 수행하는 마지막 Layer만 날려서 다른 데이터셋에 사용

- 전이 학습 결과가 더 좋음
- 예) 데이터셋으로 CNN 구조를 학습시키고 분류 Task를 수행하는 마지막 Layer만 날려서 다른 데이터셋에 사용
-
Fine-tuning을 통해 성능을 더 향상시킬 수 있음
- 그대로 전이학습 해서 사용해도 좋지만, 그보다는 새로운 Task를 위해서 Fine-tuning 시키는 방식이 성능 향상에 더 도움
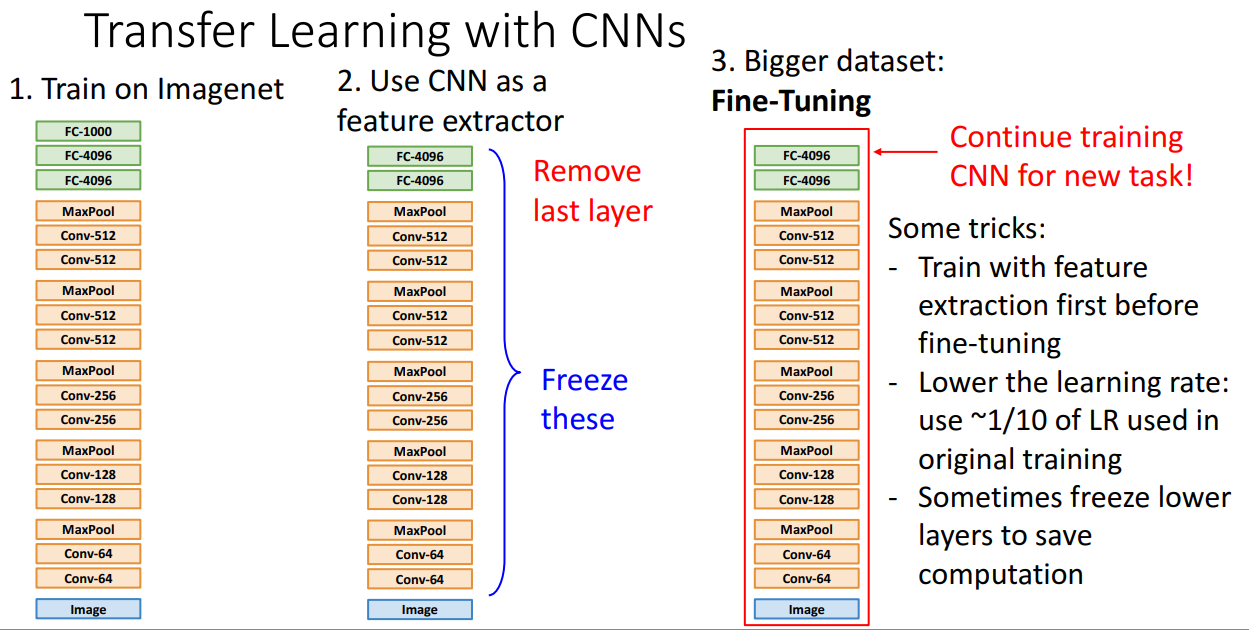
- 그대로 전이학습 해서 사용해도 좋지만, 그보다는 새로운 Task를 위해서 Fine-tuning 시키는 방식이 성능 향상에 더 도움
- 주의할 점: 아래와 같이 전이학습해서 해결할 데이터셋이 Pretrain 데이터셋이랑 너무 다르고 수가 적은 상황
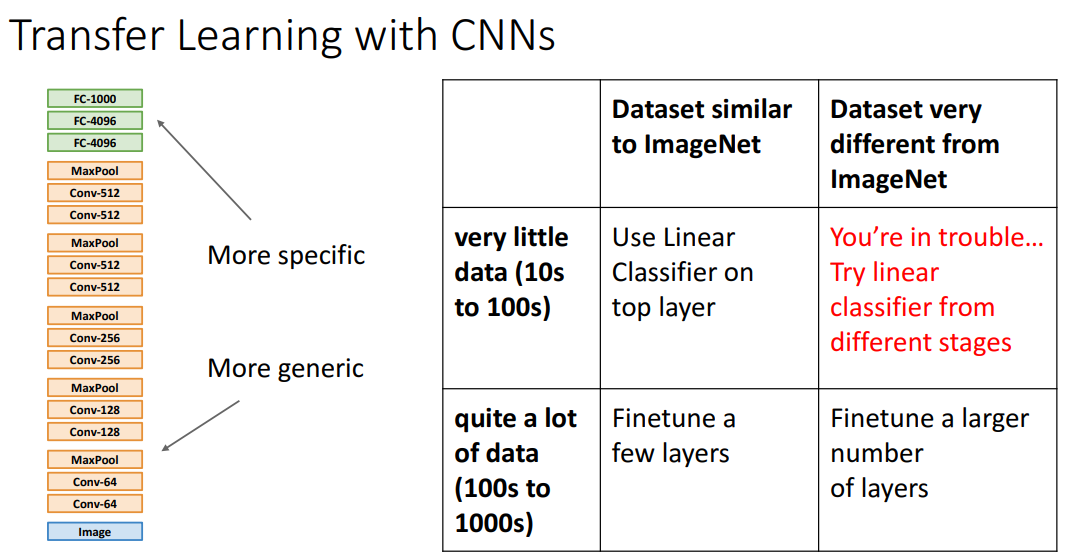
- 물론 데이터셋이 충분히 있고 학습을 오래한다면 전이학습이랑 처음부터 학습한 네트워크랑 성능이 비슷함
Distributed Learning
- 모델을 학습시키기 위해서 여러 GPU를 사용하는 방법론
Recurrent Neural Networks
주요 내용
- Recurrent Neural Networks
- RNN Computational Graph
- Truncated Backpropagation Through Time
- Searching for Interpretable Hidden Units
- Image Captioning
- Long Short Term Memory(LSTM)
Recurrent Neural Networks(RNN): 시계열적인 데이터를 처리할 때 유용한 네트워크
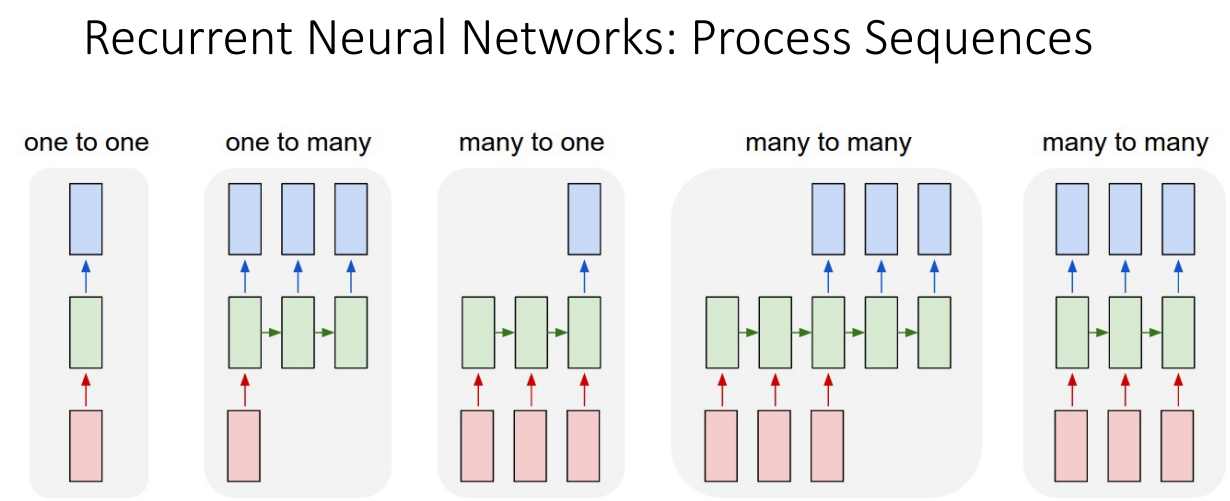
-
Input과 Output 종류에 따라 5가지 정도로 나눌 수 있음
- one to one: RNN으로 분류 X, 하나의 input이 들어가서 하나의 output이 나오는 경우, 대표적으로 Image classification
- one to many: 하나의 input이 들어가서 여러개의 output이 나오는 경우, 대표적으로 Image Captioning
- many to one: 여러개의 input이 들어가서 하나의 output이 나오는 경우, 대표적으로 Video classification
- many to many(1): 여러개의 input이 들어가서 여러개의 output이 나오는 경우, 대표적으로 Machine Translation
- many to many(2): 여러개의 input이 들어갈때 각각의 input에 해당하는 output이 나오는 경우, 대표적으로 Per-frame video classification
-
RNN은 주로 시퀀스를 다루는 네트워크이지만, 시퀀셜 데이터뿐만 아니라 Non-Sequential 데이터에도 적용 가능
-
예를 들어, 이미지를 glimpse의 집합으로 간주하여 분류하거나 이미지를 작은 시퀀스처럼 그려나가며 분류하는 경우에도 RNN을 활용 가능
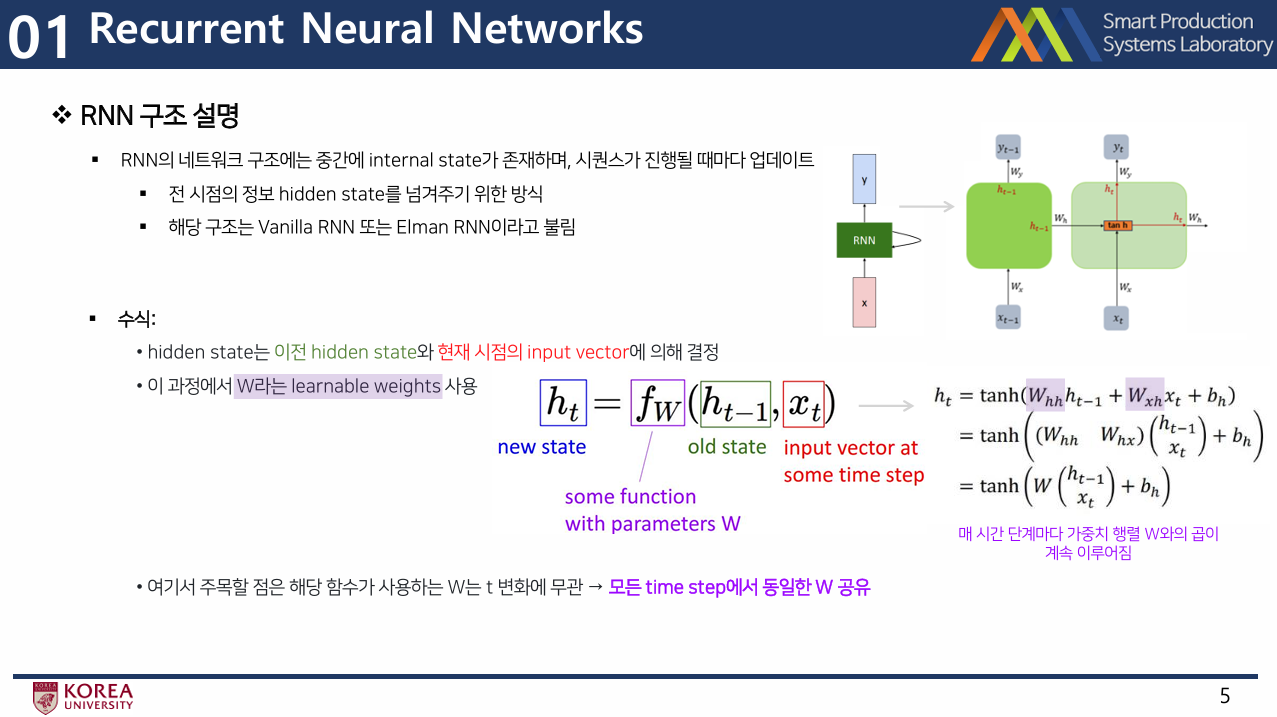
RNN 구조 설명
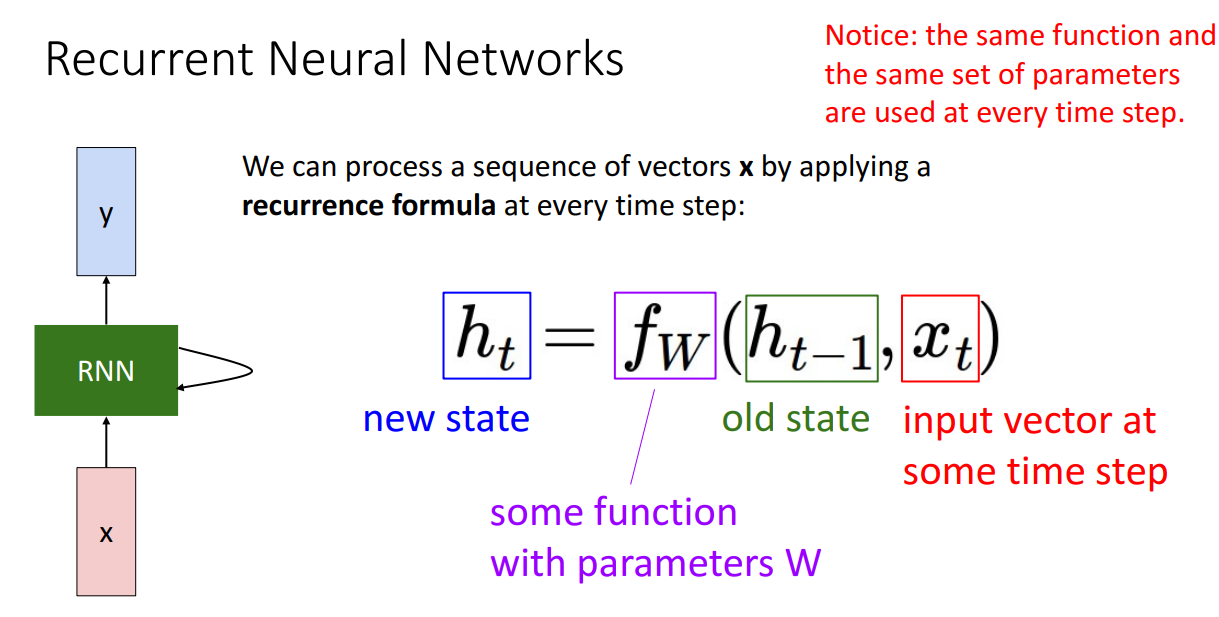
- RNN의 네트워크 구조에는 중간에 internal state가 존재하며, 시퀀스가 진행될 때마다 업데이트됨.
- 수식으로 나타내면, hidden state는 이전 hidden state와 현재 시점의 input vector에 의해 결정됨. 이 과정에서 W라는 learnable weights가 사용
- 여기서 주목할 점은 해당 함수가 사용하는 W는 t에 무관하다는 점
- 모든 time step에서 동일한 W를 공유함.
- 모든 time step에서 동일한 W를 공유함.
- 해당 구조는 Vanilla RNN 또는 Elman RNN이라고 불림.
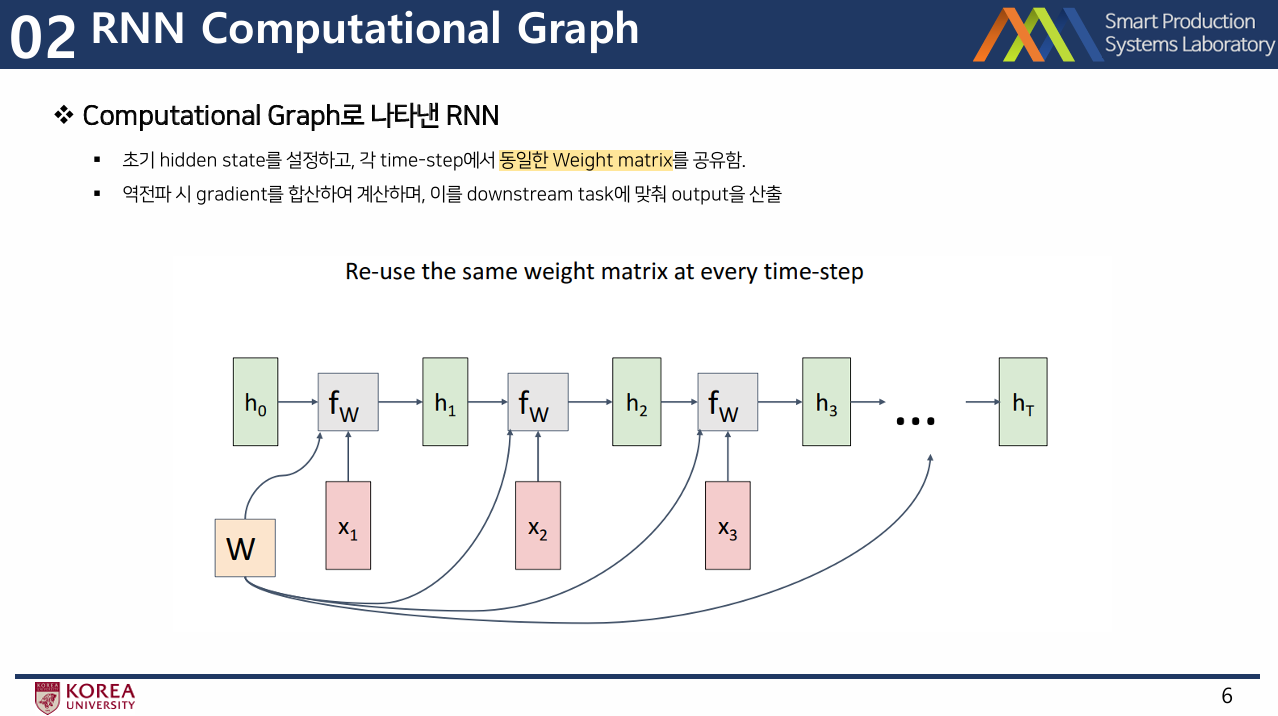
RNN Computational Graph
- RNN 구조를 Computational Graph로 나타내면, 초기 hidden state를 설정하고, 각 time-step에서 동일한 Weight matrix를 공유함.
- 역전파 시 gradient를 합산하여 계산하며, 이를 downstream task에 맞춰 output을 산출함.
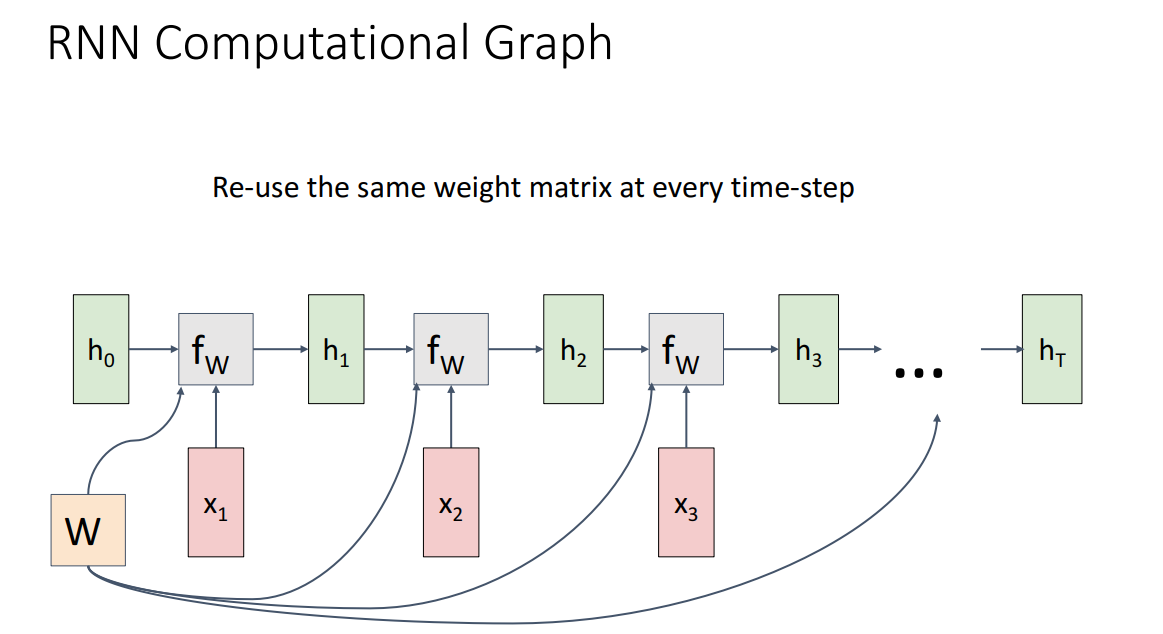
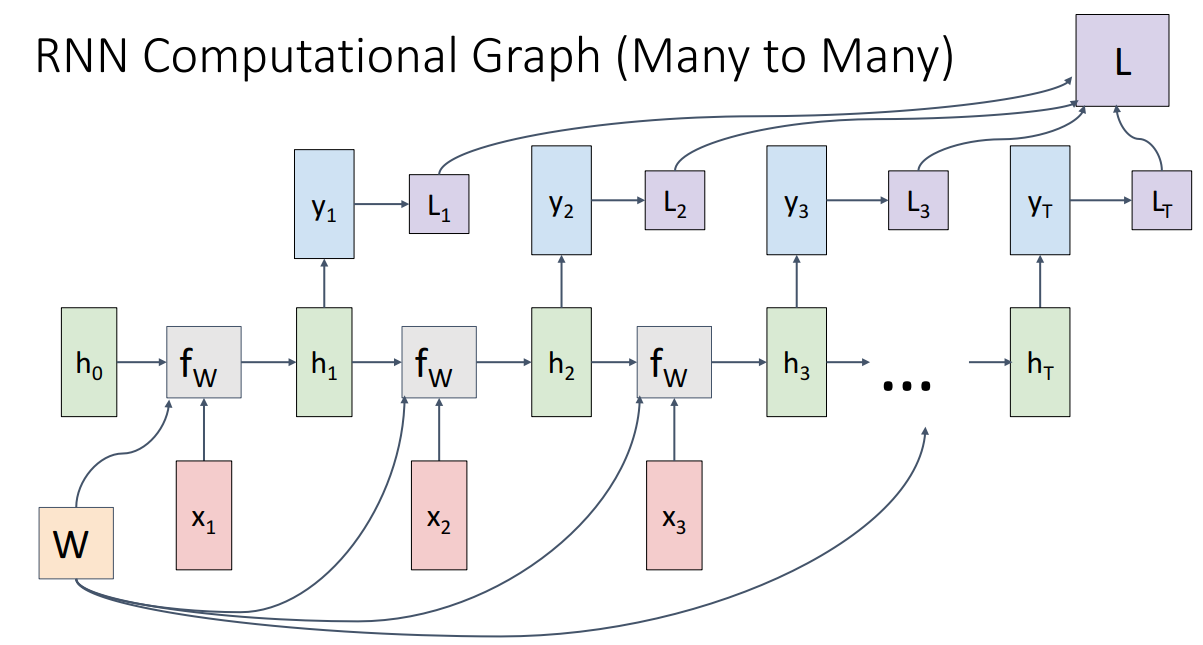
Many to Many
- Per-frame Video Classification의 경우, 각 input에 따라 output이 산출되며, 모든 time-step에서의 Loss를 합산하여 최종 Loss를 계산함.
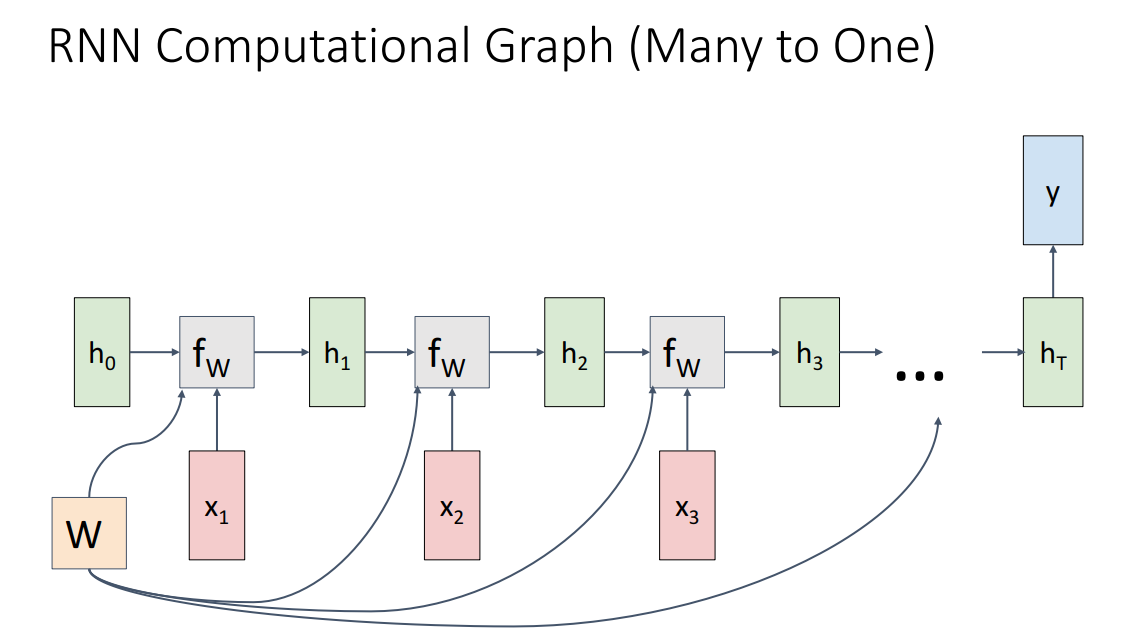
Many to one
- 여러개의 input이 들어가서 하나의 output이 나오게되는 경우
- 대표적으로 Video classification
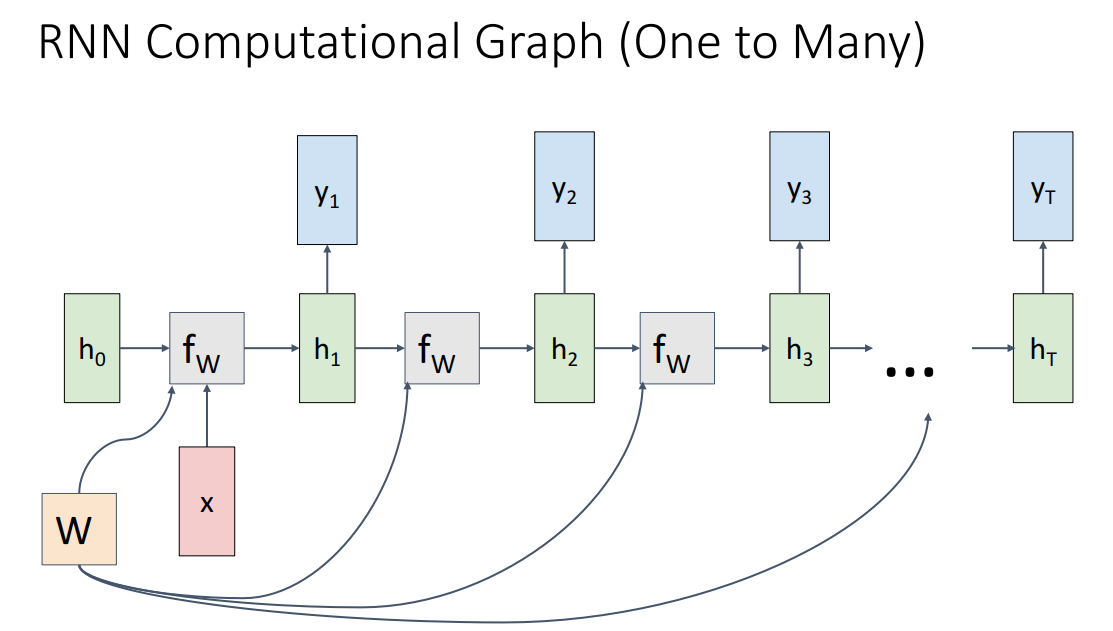
one to Many
- 하나의 input이 들어가고 여러개의 input이 나오는 구조, 대표적으로 Image Captioning
Seq2Seq 구조
- Many to Many 구조 중에서 Machine Translation 상황에서는 Sequence to Sequence(seq2seq)로 불림
- 여러 input이 하나의 vector로 요약되고, 이 vector로부터 여러 output이 생성
- 이 구조는 Encoder-Decoder 구조로, input token의 개수와 output token의 개수가 다를 수 있음.
예) Language Modeling
- Language Modeling에서는 Vocabulary를 one-hot vector로 변환하여 input으로 사용
- 해당 네트워크는 input이 주어졌을 때 다음에 올 element를 맞히는 Task를 수행하도록 학습
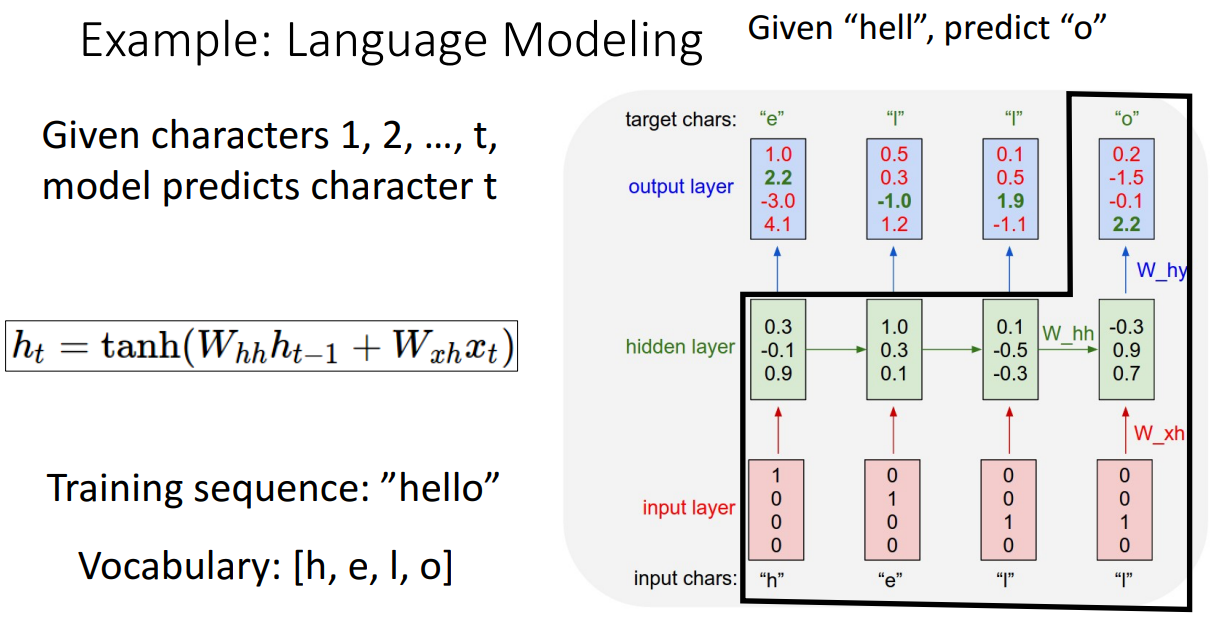
- 학습이 잘 이루어지면 seed token만으로도 다음 글자를 예측하고, 이를 반복하여 단어를 생성 가능
- seed token으로 "h"만 주어져도 다음 글자인 "e"를 잘 얻어내고,
얻어낸 "e"를 다시 input으로 사용해서 다음 글자를 얻어내고 해당 과정을 반복해서 단어를 생성
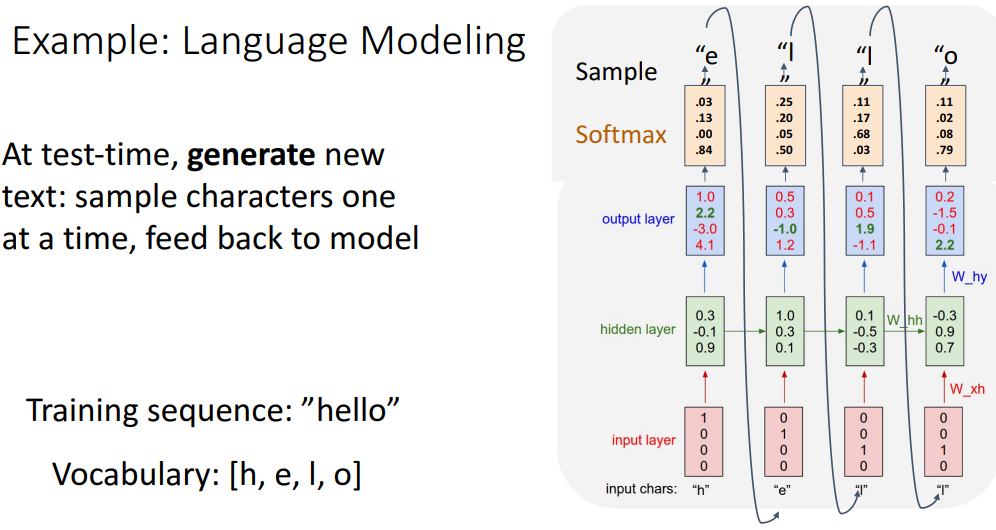
- seed token으로 "h"만 주어져도 다음 글자인 "e"를 잘 얻어내고,
- 이때 one-hot vector를 행렬곱하는 것은 너무 trivial
- 따라서 행렬곱 대신에 특정 위치 요소 추출하는 방식을 사용하는 것이 좋고,
one-hot vector를 통해 바로 hidden layer를 구하는 것보다는 Embedding layer를 하나 더 도입해서 hidden layer를 구하기도 함
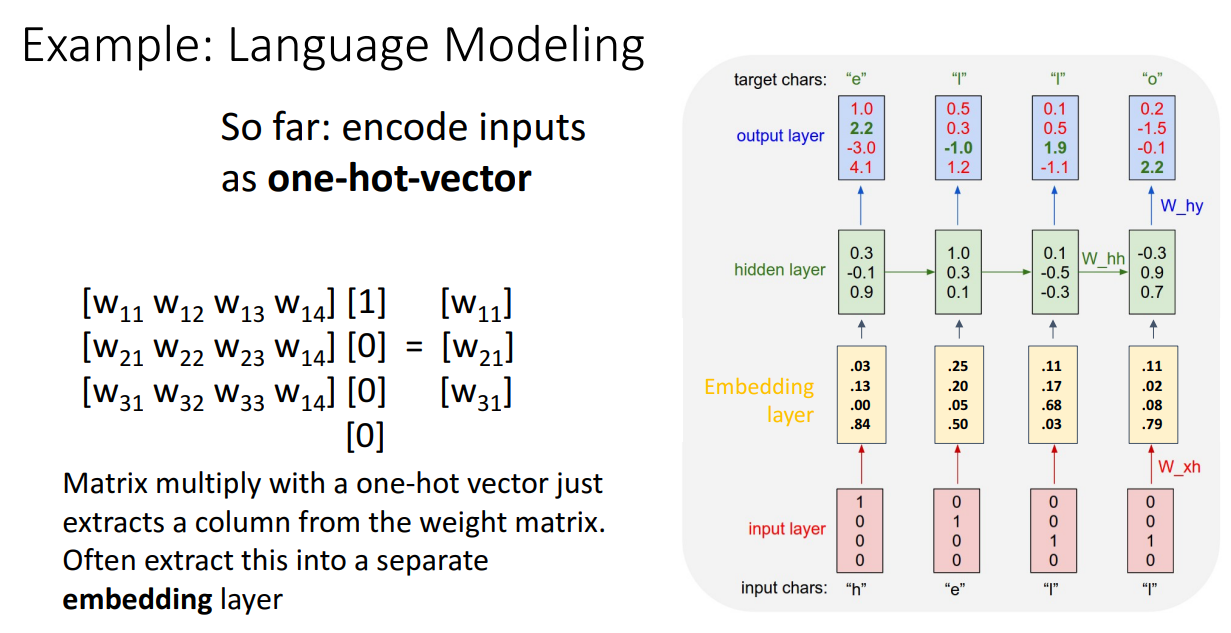
- 따라서 행렬곱 대신에 특정 위치 요소 추출하는 방식을 사용하는 것이 좋고,
Truncated Backpropagation Through Time
- RNN의 단점 중 하나는 시퀀스가 길어질수록 역전파 시 많은 메모리를 소모한다는 점
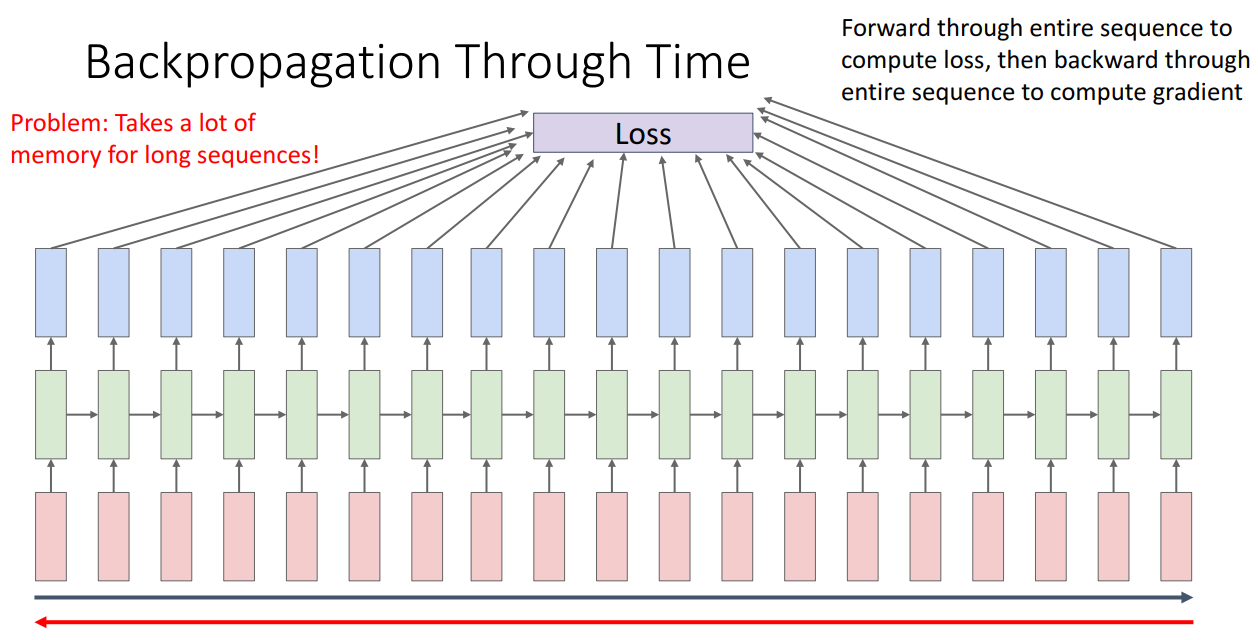
- 이를 극복하기 위해 Truncated Backpropagation Through Time이 도입됨. - 순전파는 계속 진행하고, 역전파 시 chunk로 잘라서 진행하는 방법
- 이렇게 학습을 수행한다면 GPU memory가 한정적이어도 RNN을 돌릴 수 있음
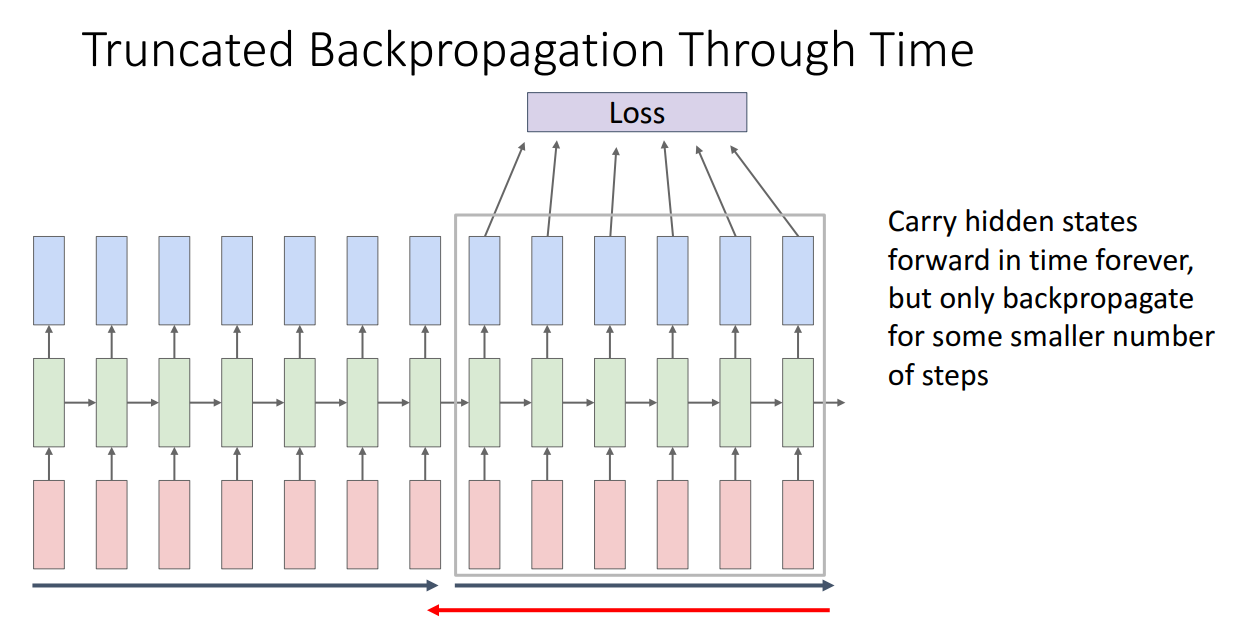
- 이렇게 학습을 수행한다면 GPU memory가 한정적이어도 RNN을 돌릴 수 있음
Searching for Interpretable Hidden Units
- RNN의 재밌는 특징 : Next character를 찾기 위한 네트워크를 학습시켜본다면 hidden state 내부에는 다양한 기능을 갖도록 학습이 이루어진다는 것
- 아래 이미지에서 빨간색에 가까워질수록 1, 파란색에 가까워질수록 -1 즉 빨간색이 해당 hidden state가 집중한 부분
- 위 예시는 톨스토이의 작품을 학습시킨 결과이며, 대부분의 hidden state가 보여주는 모습으로 어디에 주목한지는 모르는 상황을 나타냄
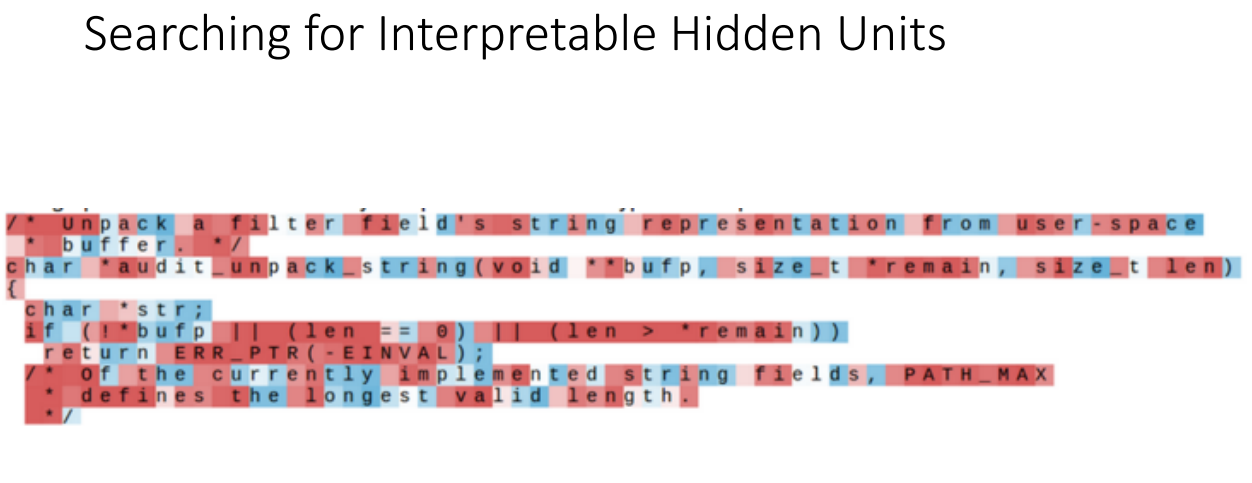
- 하지만 앞선 상황과 다르게 특정 부분에만 집중해서 예측을 진행하는 cell 존재
- 예) quote detection cell ( 인용하는 파트에만 집중 )

- 예) line length tracking cell ( 문장이 80자가 넘으면 다음으로 가는 것을 고려하는 cell로 문장의 끝부분에만 집중 )

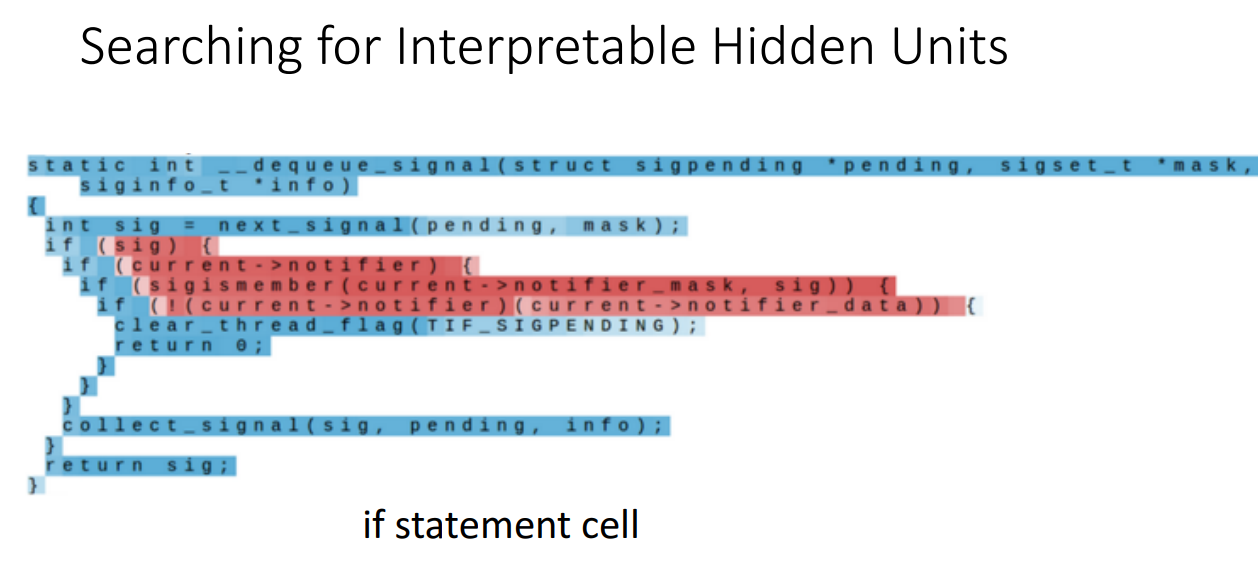
- 예) if statement cell ( if문에서 들여쓰기 한 부분만을 집중하는 cell )
- 예) quote detection cell ( 인용하는 파트에만 집중 )
- 위 예시는 톨스토이의 작품을 학습시킨 결과이며, 대부분의 hidden state가 보여주는 모습으로 어디에 주목한지는 모르는 상황을 나타냄
Image Captioning
- CNN과 RNN을 함께 사용하여 Image Captioning 수행 가능 ( 이미지에서 텍스트를 생성 )
- Image Captioning의 경우 다른 RNN 구조들과는 다르게 actual start & actual end 지점을 알아야 함
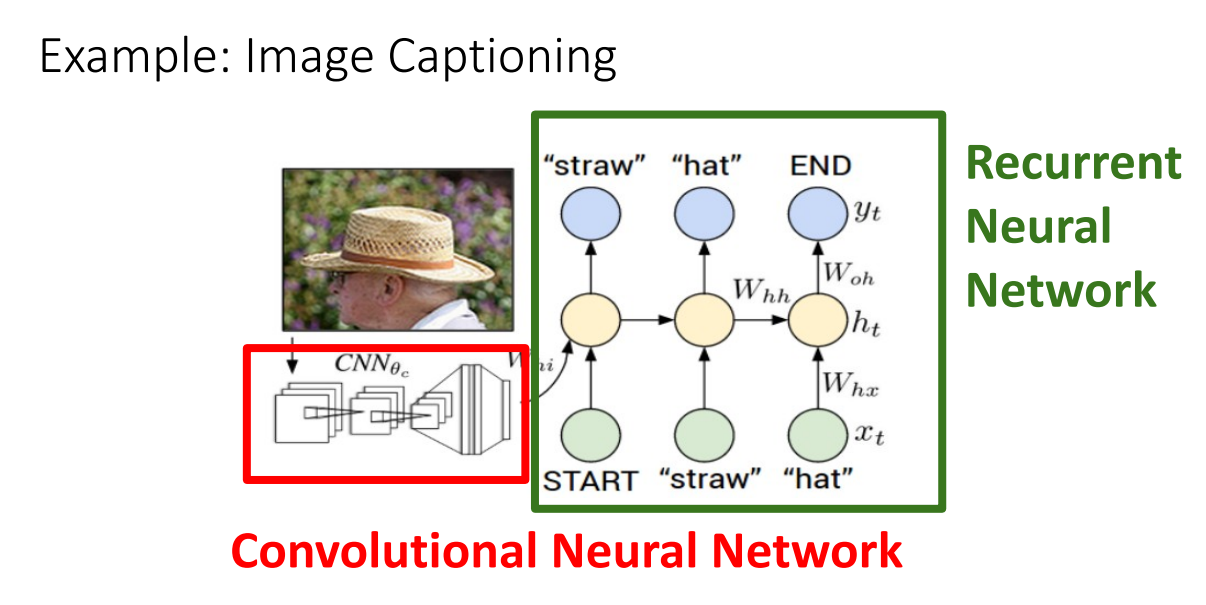
- Image Captioning이 진행되는 네트워크 구조 :
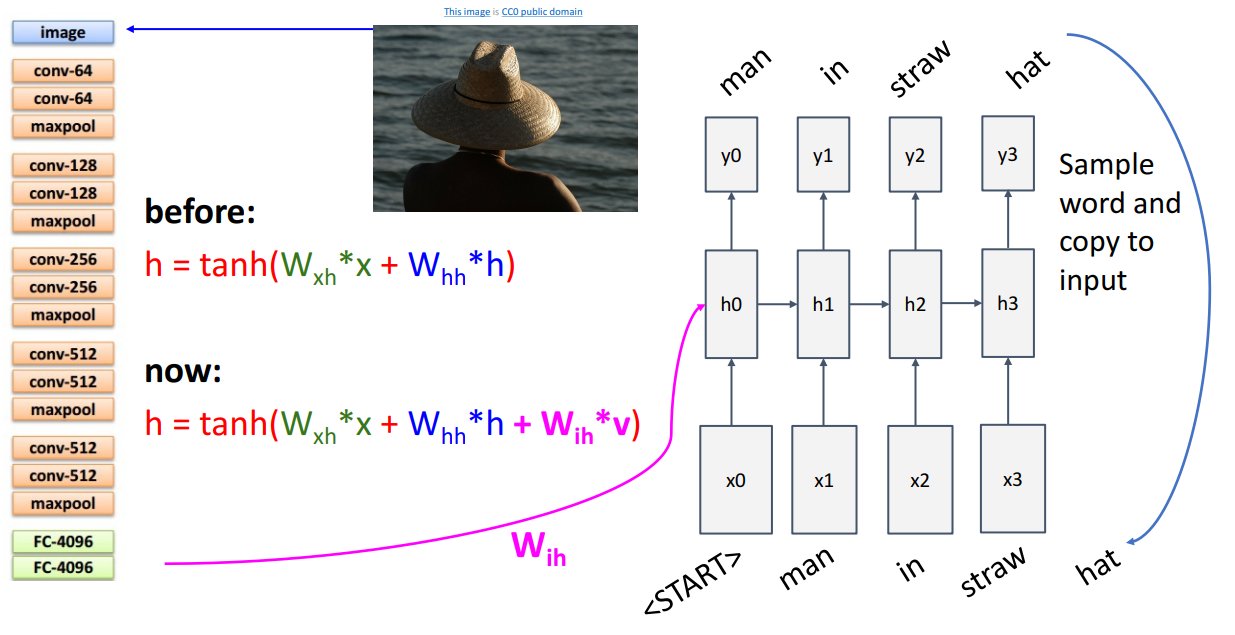
- input과 weights 외에도 CNN 네트워크를 통해 추출된 feature를 입력으로 받음
- 이후에는 <"START"> token이 주어지면 다음으로 나올 단어를 예측하고,예측된 단어는 그 다음 입력으로서 사용되고 최종적으로 <"END"> token이 나오면 문장 종료
- 이미지 캡셔닝 결과

- Image Captioning의 경우 다른 RNN 구조들과는 다르게 actual start & actual end 지점을 알아야 함
Long Short Term Memory(LSTM)
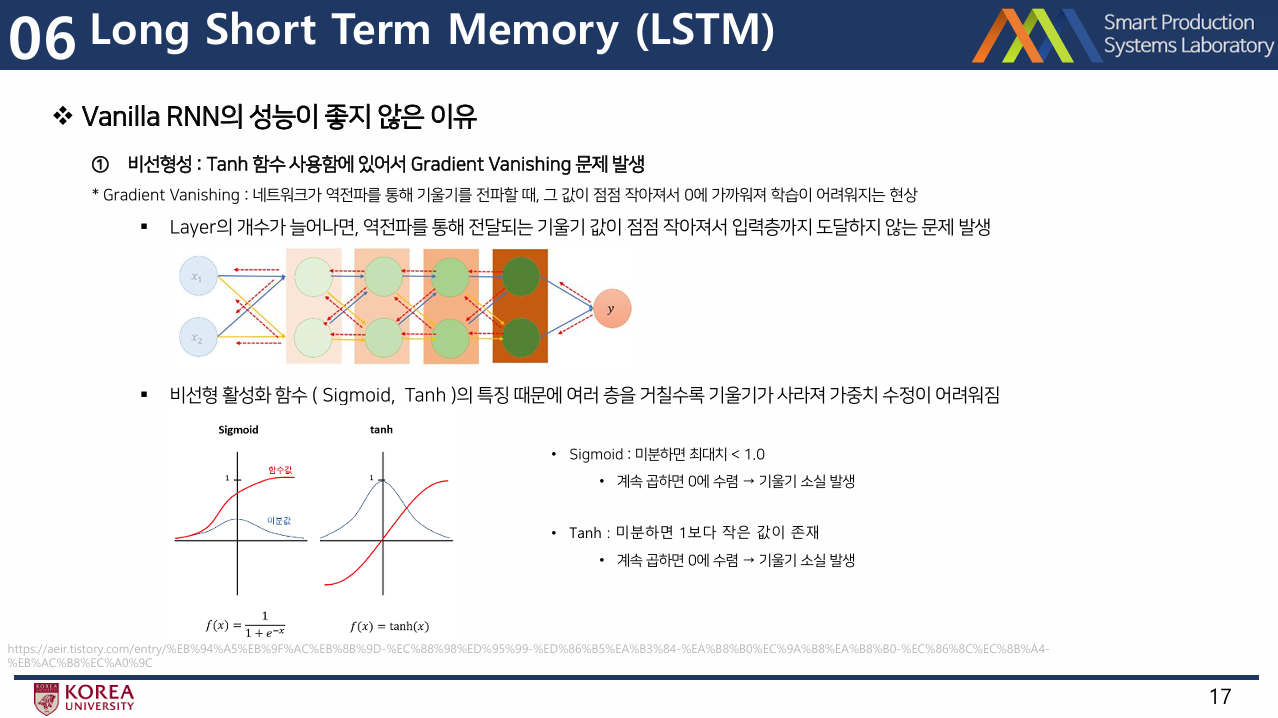
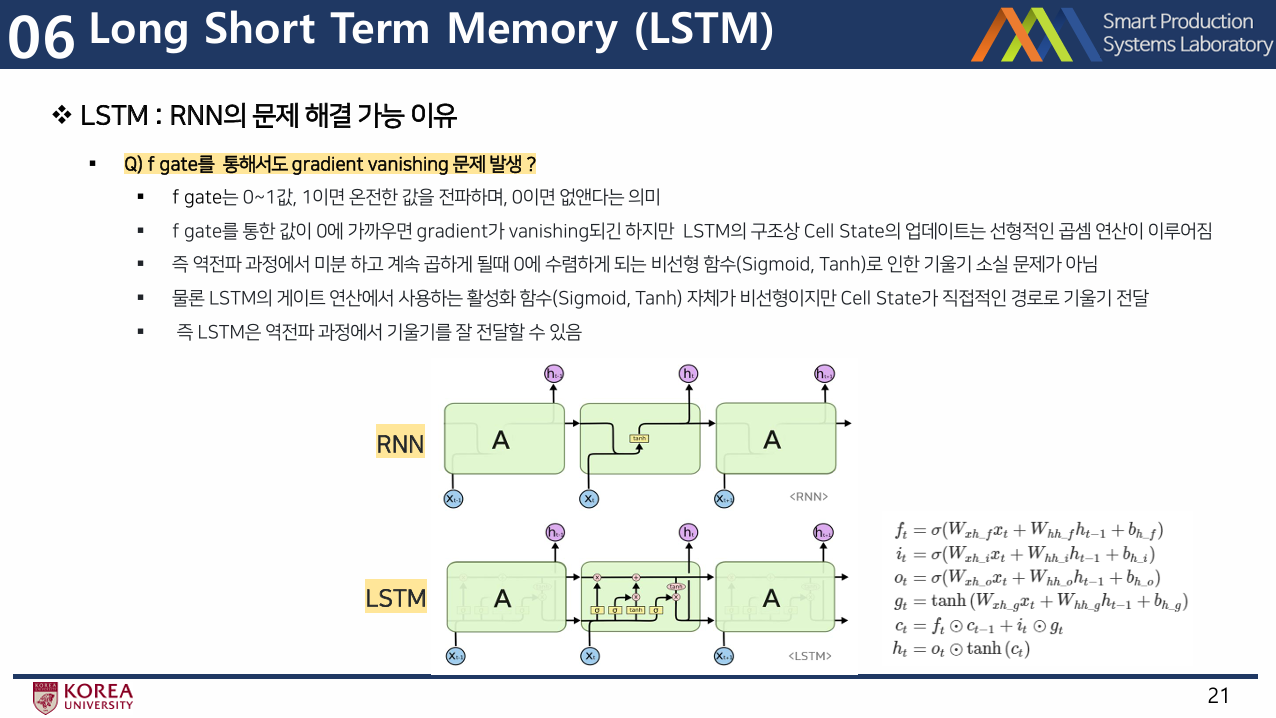
- Vanilla RNN의 성능이 좋지 않은 이유:
- 1) tanh 함수 사용 ( 역전파 시에 좋지 않음 )
- 2) 역전파 시에 동일한 W 행렬을 계속 곱해나가야 함
- Sequnce의 길이가 길어질수록( hidden state가 길어질수록 ) 똑같은 행렬을 반복해서 곱해나가는 것은 메모리와 성능에 큰 악영향
- 아래 그림처럼 계속 곱해나갈때 max(singular value)>1이면 기울기가 폭발,
반대로 max(singular value)<1이며 기울기 소실
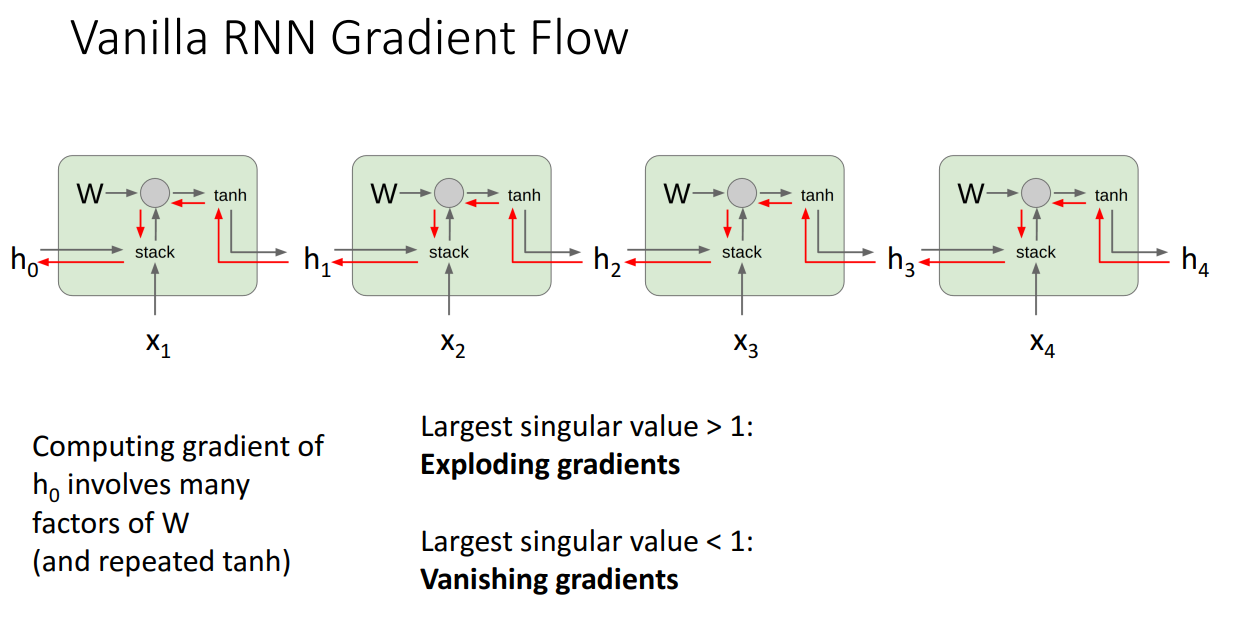
- 이를 해결하기 위해 LSTM(Long Short-Term Memory) 구조 도입
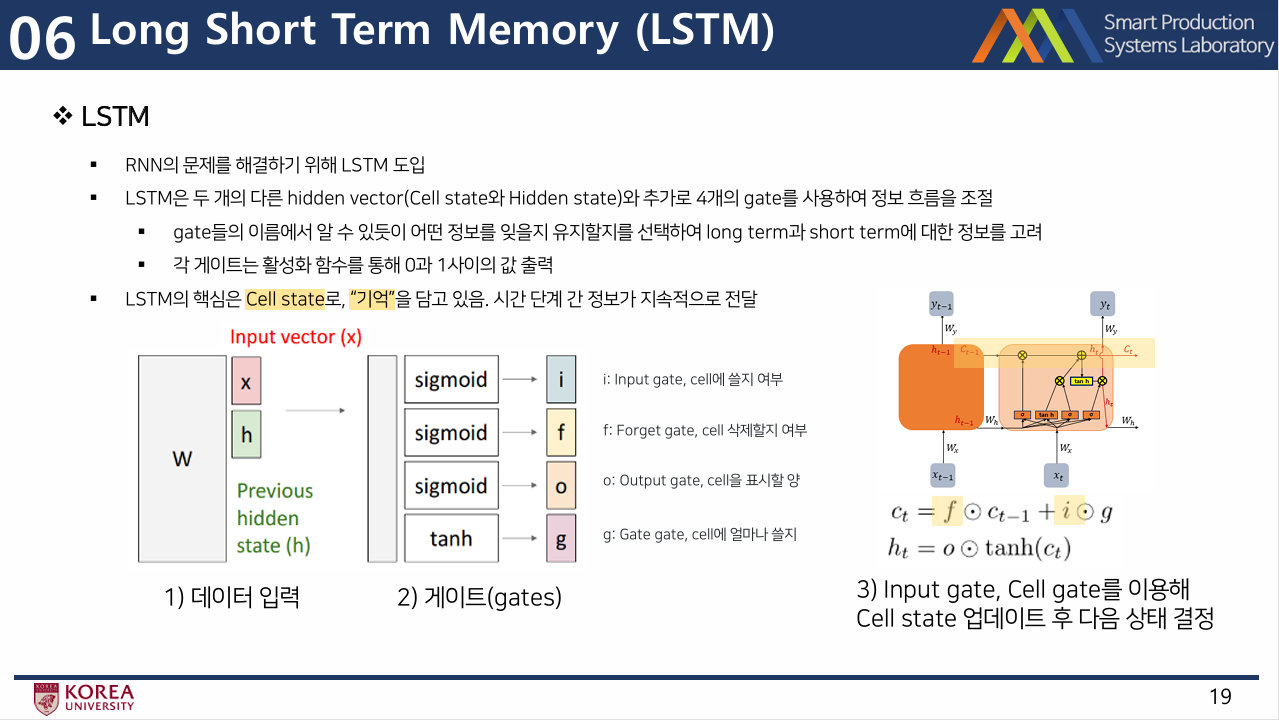
- LSTM은 두 개의 다른 hidden vector(Cell state와 Hidden state)와 추가로 4개의 gate를 사용하여 정보 흐름을 조절
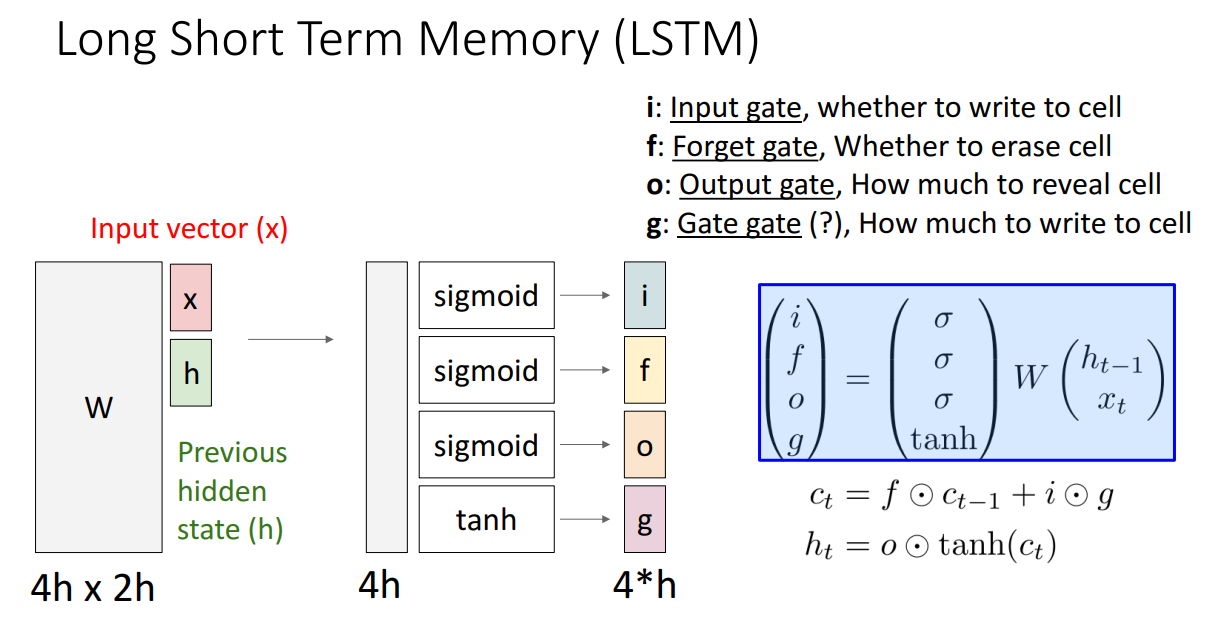
- 각 state 기능
- 1) i: Input gate, cell에 쓸지 여부
- 2) f: Forget gate, cell 삭제할지 여부
- 3) o: Output gate, cell을 표시할 양
- 4) g: Gate gate, cell에 얼마나 쓸지
- 각 state 기능
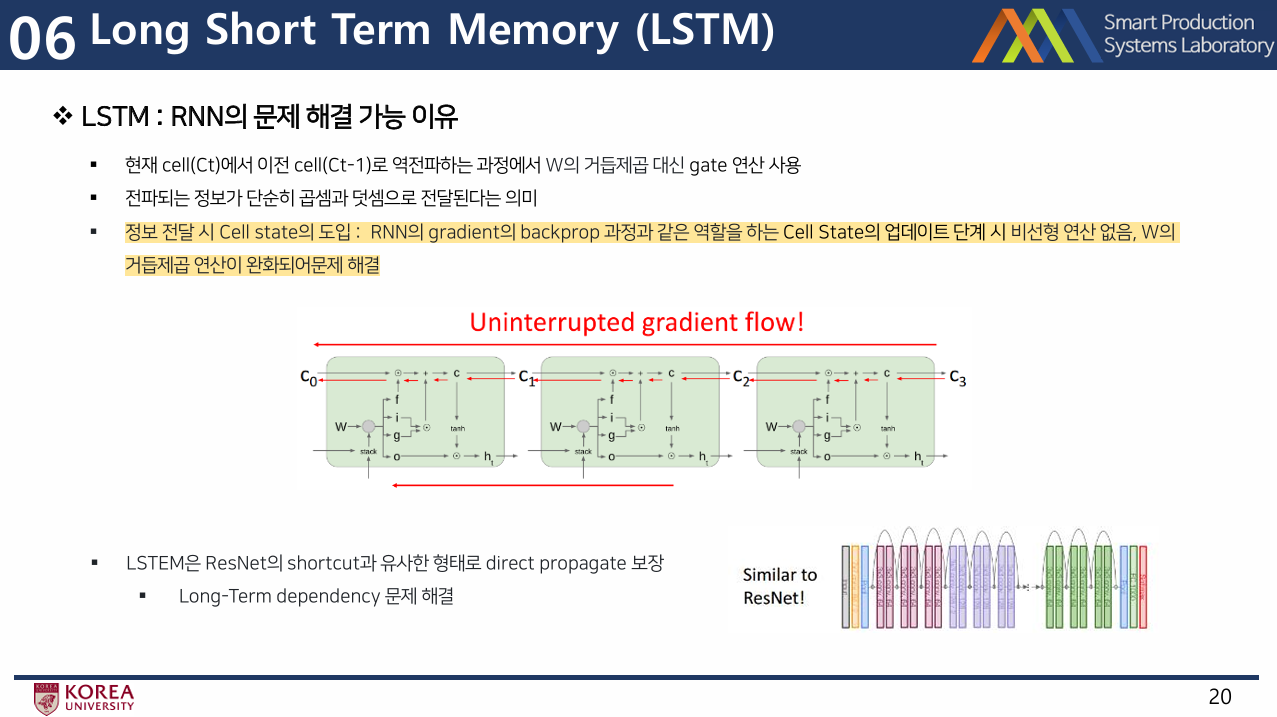
- LSTM은 RNN과 달리 Ct에서 Ct-1로 역전파하는 과정에서 행렬곱 대신 elementwise 곱만을 사용
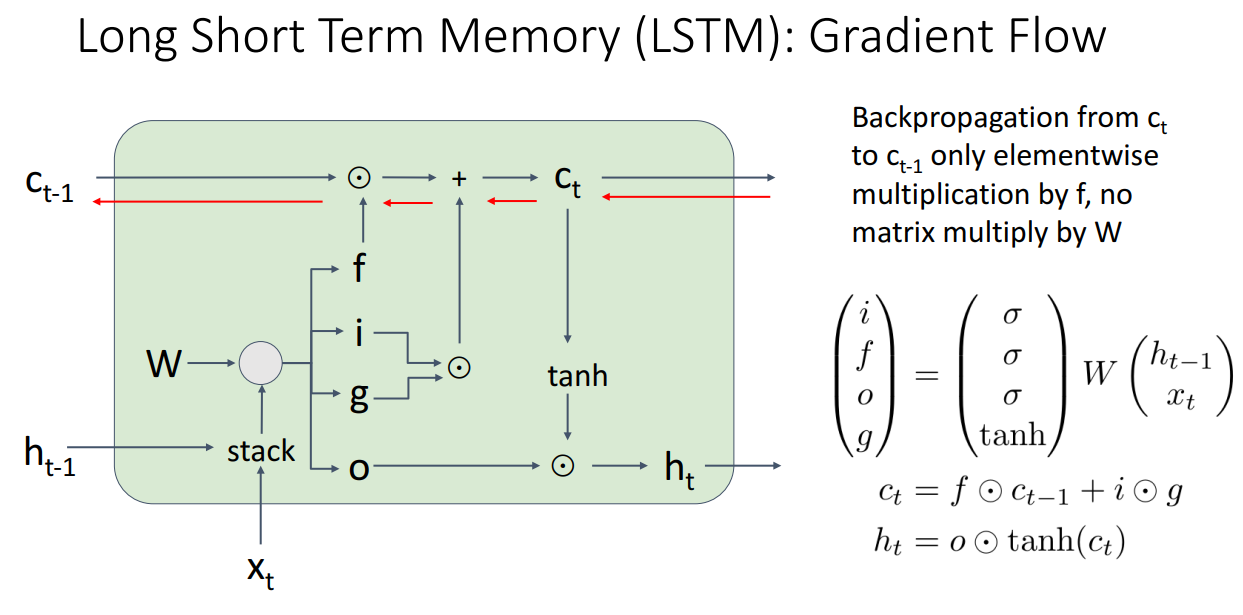
- 따라서 역전파시에 수월하게 넘길 수 있음
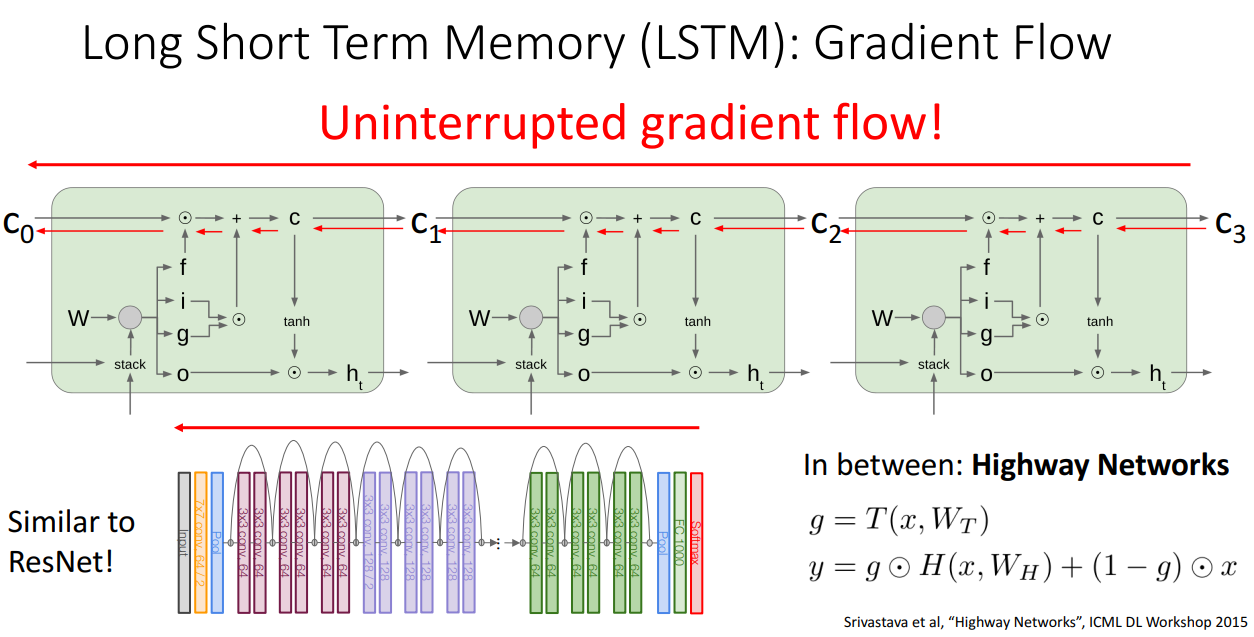
- RNN의 경우 hidden state를 깊게 쌓을수도 있음
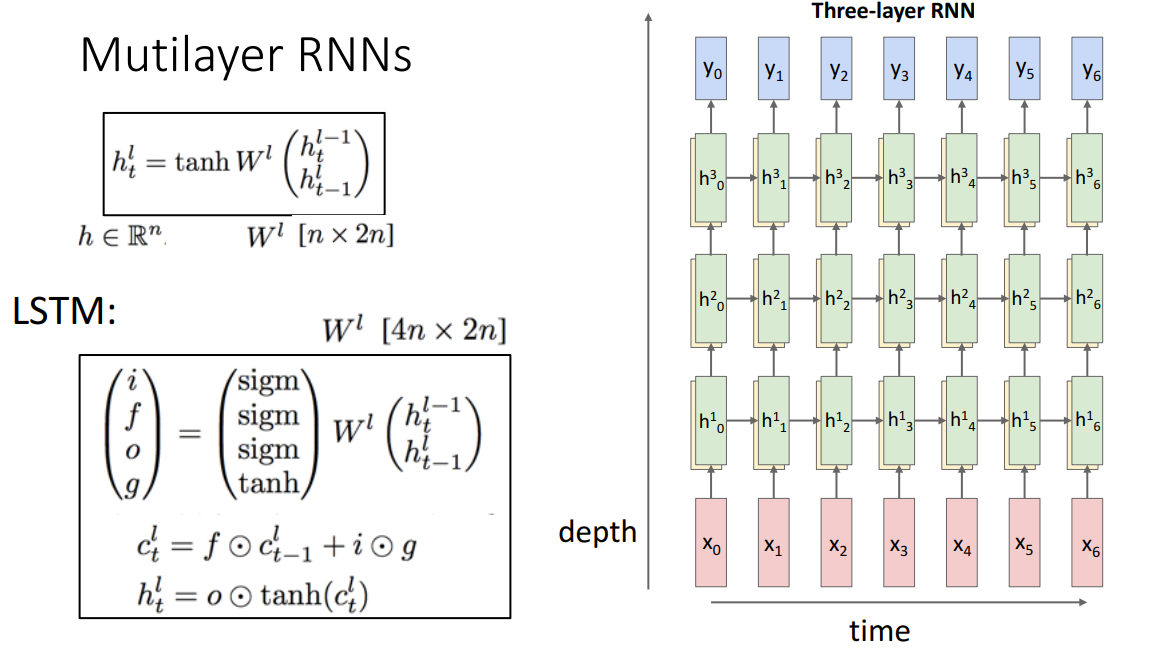
- LSTM의 단순화된 버전인 GRU(Gated Recurrent Unit)도 존재

[ 중요 부분 PPT로 보는 RNN LSTM GRU 정리 ]



[PT Lecture Review] 발표한 자료는 아래와 같습니다

발표자료 :
https://drive.google.com/file/d/1R_VVK1Fucl5NYBlLsztF8_SL2MTcgtJv/view?usp=sharing
참고 강의:
https://youtu.be/WUazOtlti0g?si=42LDeJ69wsEb8Ctb
https://youtu.be/dUzLD91Sj-o?si=4W0TNwDMiEaoHzzP

[ SPS Lab Paper Seminar YouTube ] : https://www.youtube.com/@spslab.1648