한줄요약 : Tabular Deep Learning 에서 Deep Lasso( 입력 피쳐의 gradient sparsity를 활용 ) 라는 새로운 Feature Selection 방법 제안
[Background]
- 테이블 형식 데이터에서 Feature Selection이 매우 중요한 역할을 함.
- 테이블 데이터는 산업과 과학적 응용에서 널리 사용되며, 데이터사이언티스트들은 가능한 많은 특징을 수집하고, 때로는 기존 특징을 바탕으로 새로운 특징을 추가로 만듬
- 그러나 이러한 과정에서 발생하는 많은 특징 중 상당수는 유용하지 않음.
- 불필요한 특징들이 모델 학습 과정에서 overfitting을 유발할 수 있음
- 이를 방지하기 위해 자동화된 Feature Selection 방법론이 사용됨.
[Motivation]
- 기존의 Feature Selection 벤치마크는 주로 고전적인 모델이나 합성 데이터에 기반
- 딥러닝 기반 테이블 모델에서의 Feature Selection 성능 평가가 부족
- Tabular Deep Learning의 인기가 증가함에 따라, 실세계 데이터를 바탕으로 한 더 현실적인 Feature Selection 벤치마크의 필요성 대두
[Contribution]
- 1) 현실적인 Feature Selection 벤치마크를 제시함.
- 2) Tabular Transformer 모델을 포함한 최신 딥러닝 모델들을 활용하여 Feature Selection 방법론의 성능을 평가함.
- 3) Deep Lasso라는 새로운 Feature Selection 방법을 제안함.
- 이는 딥러닝 모델에서 입력 피쳐의 gradient sparsity를 활용하여 성능을 향상시킴.
[Research Flow]
- 테이블 형식 데이터에서 과도한 feature들이 모델 성능에 미치는 영향 분석
- Feature Selection 알고리즘들이 실제 데이터에서 얼마나 효과적으로 동작하는지를 평가하는 새로운 벤치마크를 설계
[Proposed Method]
Overall Architecture:
-
이 연구는 딥러닝 모델에서 다양한 Feature Selection 알고리즘을 비교함.
- Feature Selection 알고리즘:
- Univariate Statistical Test:
- 통계적인 방법을 통해 각각의 피쳐가 목표 변수와의 선형 의존성을 측정하고, 이를 기반으로 특징을 선택함.
- Lasso:
- L1 정규화를 활용하여 희소성을 촉진하는 방법임. 이 알고리즘은 회귀 모델에서 특징의 중요도를 특징의 계수 크기를 기준으로 평가함.
- First-Layer Lasso:
- MLP 모델의 첫 번째 레이어에서 Group Lasso 페널티를 적용한 방법임. 첫 번째 레이어의 가중치에 기반하여 특징을 선택함.
- Adaptive Group Lasso (AGL):
- First-Layer Lasso의 확장판으로, 가중치에 적응형 파라미터를 추가해 그룹별 가중치를 다르게 처리함.
- LassoNet:
- 특징 희소성을 촉진하기 위해 스킵(잔차) 레이어를 추가한 신경망 아키텍처임. 특징이 스킵 레이어와 연결되었을 때만 활성화됨.
- Random Forest (RF):
- 앙상블 기법을 사용해 각각의 노드에서 특징 분할로 인한 불순도 감소를 기준으로 특징 중요도를 계산함.
- XGBoost:
- Gradient Boosted Decision Tree 알고리즘으로, 각 노드에서 특징이 분할될 때의 평균 이득을 기준으로 특징 중요도를 계산함.
- Deep Lasso:
- 이 논문에서 제안된 방법으로, 입력 특징의 gradient sparsity를 적용하여 모델을 학습시킴.
- Gradient Sparsity: 모델의 특정 파라미터들에 대해 기울기가 거의 0이 되는 현상(해당 파라미터들이 손실 함수에 거의 영향을 미치지 않음을 의미 즉, 해당 파라미터들은 모델이 학습하는 데 중요한 역할을 하지 않는다는 것)
- 훈련 과정에서 입력 특징들에 대한 손실 함수의 기울기에 Group Lasso 페널티를 적용함으로써, 모델이 특정 입력 특징에 대한 의존성을 줄이고 중요하지 않은 특징들을 효과적으로 제거하도록함
- 즉 이 방법은 중요하지 않은 특징에 대한 모델의 민감도를 줄여 더 나은 성능을 보임.
- loss 방식
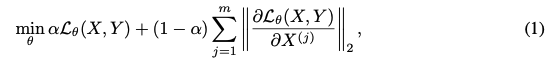
- j번째 피쳐 중요도
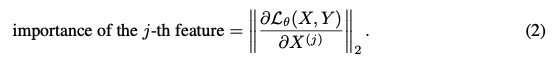
- j번째 피쳐 중요도
- 이 논문에서 제안된 방법으로, 입력 특징의 gradient sparsity를 적용하여 모델을 학습시킴.
- Univariate Statistical Test:
- Feature Selection 알고리즘:
-
MLP와 FT-Transformer 모델을 사용하며, 세 가지 유형의 불필요한 feature을 추가한 데이터셋을 생성하여 실험을 수행함
-
세 가지 유형의 불필요한 feature:
- 1) Random Features:
- 랜덤한 가우시안 분포에서 샘플링한 특징을 추가함.
- 실제 데이터에서는 보기 드문 간단한 시나리오를 제공함.
- 2) Corrupted Features:
- 원래의 특징에서 샘플링한 후 가우시안 노이즈를 추가한 특징임.
- 이 시나리오는 노이즈가 포함된 데이터를 반영함.
- 3) Second-Order Features:
- 기존의 특징 두 개를 선택해 이들의 곱을 계산하여 생성한 이차 특징
- 이 방법은 피쳐 엔지니어링의 대표적인 예임.

- 1) Random Features:
-
- 각 알고리즘은 실제 데이터에서 선택된 특징들이 모델의 성능에 어떻게 영향을 미치는지 평가함.
[Experiments]
- Dataset: ALOI, California Housing, Covertype, Eye Movements 등 총 12개의 데이터셋을 사용함.
- 평가 지표: 분류 문제에서는 정확도, 회귀 문제에서는 RMSE로 성능을 평가함.
- Implementation Details: 각 모델에 대한 하이퍼파라미터 튜닝은 Optuna를 통해 수행됨.
[Results]
- Deep Lasso는 특히 잡음이나 이차 특징이 포함된 데이터셋에서 더 나은 성능을 보임.
[Conclusion]
Summary:
- 이 연구는 실제 데이터를 기반으로 한 딥러닝 모델에서 Feature Selection 알고리즘을 평가하는 벤치마크를 제시함.
- 특히 Deep Lasso가 복잡한 데이터 환경에서 우수한 성능을 보였음.
Research Question with Comments:
- Deep Lasso는 강력한 성능을 보이지만, 계산 복잡도가 높음. 특히 대규모 데이터셋에서 효율성을 높이기 위한 최적화 전략이 필요함
- 더 큰 데이터셋에서 Deep Lasso와 다른 Feature Selection 방법들의 성능을 평가하는 연구가 필요
- Feature Selection은 모델의 해석 가능성을 높이는 데 중요한 역할을 함. Deep Lasso와 같은 알고리즘이 선택한 특징들이 실제로 어떤 의미를 가지며, 이로 인해 모델이 어떻게 학습되고 있는지에 대한 해석 가능성을 높이는 연구가 필요함
- 이 부분에서 사용자에게 더 직관적인 설명을 제공하는 방법론의 발전이 가능함.

[ SPS Lab Paper Seminar YouTube ] : https://www.youtube.com/@spslab.1648