[ 논문 분석 ] Adaptive Normalization for Non-stationary Time Series Forecasting: A Temporal Slice Perspective (NeurIPS, 2023)
[ 논문 분석 ]
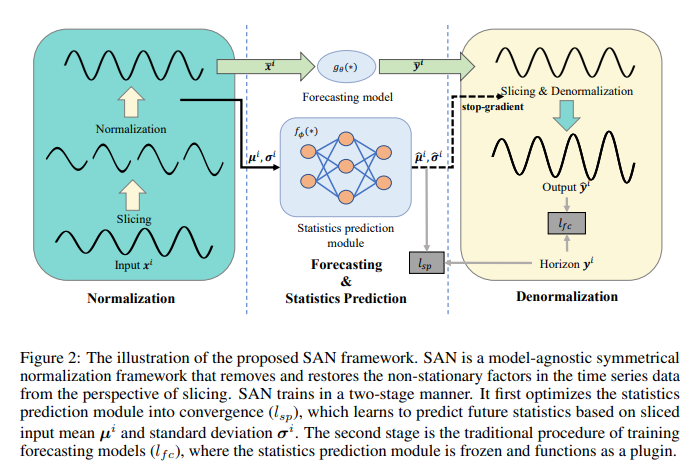
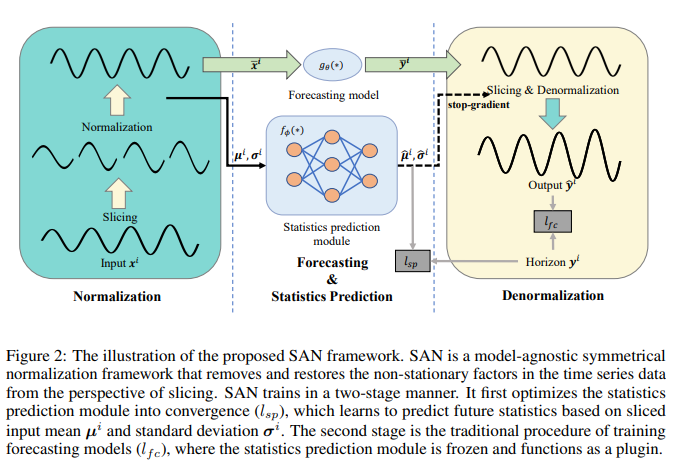
한줄 요약 : SAN(Slicing Adaptive Normalization)은 시계열 데이터를 지역적 슬라이스 단위로 정규화해서 비정상성을 제거하고, 미래 분포를 예측하는 통계 예측 모듈로 보다 정확한 예측을 수행함
[ 요약 ]
- 기존 문제 : 실제 데이터에서 비정상성으로 인해 정확한 예측을 하기에는 어려움
- 기존 접근 방식 문제 : 일반적으로 입력 시리즈와 예측 시리즈 간의 분포 차이를 간과
- 동일한 인스턴스 내의 모든 시간 점들이 동일한 통계적 특성을 공유한다고 가정
- 제안 방법 : SAN(Slice-Level Adaptive Normalization) 제안
- SAN은 보다 유연한 정규화 및 비정규화를 통해 시계열 예측을 강화하는 새로운 방식
- 1) 전체 인스턴스가 아닌 지역적인 시간 조각(즉, 하위 시리즈) 단위로 시계열의 비정상성을 제거하려고 시도
- 2) 원시 시계열의 통계적 특성의 변화하는 경향을 독립적으로 모델링하기 위해 작은 네트워크 모듈을 사용
- 3) SAN은 일반적인 모델에 구애 받지 않는 플러그인 방식으로 설계해서 시계열 데이터의 비정상적 특성의 영향 완화
- SAN은 보다 유연한 정규화 및 비정규화를 통해 시계열 예측을 강화하는 새로운 방식
[ 기여점 ]
- 비정상적 시계열 데이터를 지역적 슬라이스 단위로 정규화하는 새로운 접근법 제안
- 미래 분포를 예측하는 통계 예측 모듈 설계
- SAN이 다양한 예측 모델에서의 성능을 크게 향상시킬 수 있음을 실험적으로 검증함
[ 문제 정의 ]
- 비정상적 시계열 데이터는 시간이 지남에 따라 데이터 분포가 변하는 특성을 가짐
- 기존 정규화 방법은 이러한 분포 변화를 충분히 반영하지 못해 예측 성능이 저하됨
- 특히, 모든 시점의 데이터가 동일한 통계적 특성을 가진다고 가정하는 것은 실제 데이터의 복잡성을 반영하지 못함.
[ 관련 연구 ]
- 시계열 예측
- ARIMA와 같은 전통적인 방법들은 시계열 데이터의 이상적 특성을 가정하고 예측을 수행함. 최근에는 RNN, Transformer와 같은 딥러닝 기반 모델이 등장하여 시계열 데이터의 복잡한 종속성을 더 잘 포착할 수 있게 되었음. 특히, 긴 시계열의 예측을 위해 self-attention 메커니즘과 합성곱 네트워크가 활용됨.
- 비정상적 시계열 예측
- 비정상성 문제를 해결하기 위한 다양한 방법들이 연구되었음. DDG-DA는 도메인 적응 방식으로 데이터 분포의 변화를 예측하고, Du et al.은 적응형 RNN을 통해 분포 특성을 고려한 예측을 제안함. 또한, RevIN과 같은 정규화 기반 접근법은 비정상적 요소를 제거하고 일관된 분포로 데이터를 정규화하는 방법을 제시함.
- 정규화 기법
- 기존의 정규화 기법들은 입력 시퀀스와 출력 시퀀스 간의 분포 차이를 무시하거나, 모든 시점이 동일한 통계적 특성을 가진다고 가정하는 경향이 있음. DAIN은 각 입력 인스턴스를 비선형 네트워크로 정규화하는 방식을 사용하며, ST-norm은 시공간적 관점에서 정규화 모듈을 제안함.
- 비정상적 요소의 중요성
- 일부 연구는 비정상적 요소가 예측 정확도에 중요한 역할을 한다고 지적하며, 단순히 이를 제거하는 것이 아닌 적절한 방식으로 고려해야 한다고 주장함. 예를 들어, Non-stationary Transformers(NST)는 self-attention 메커니즘에서 비정상적 요소를 포함하는 비정규화 방식을 도입하여 성능 향상을 도모함.
[ 제안한 방법 구조 ]
-
수식정리 :

-
슬라이스 분할: 입력 시계열 데이터를 비중첩 비율로 슬라이스로 나누어 각각의 슬라이스에 대해 평균 및 표준 편차를 계산함.
-
Normalization: 각 슬라이스의 통계적 특성에 따라 정규화하여 비정상성을 제거함.
- 각 슬라이스의 평균과 표준편차
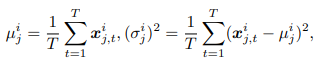
- 각 슬라이스의 정규화 식
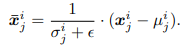
-
Statistics Prediction: 두 레이어의 퍼셉트론 네트워크를 사용하여, 입력 슬라이스의 통계적 속성을 기반으로 미래 슬라이스의 통계적 분포를 예측함.
- 직면했던 문제 : 어떻게 각 슬라이스 단위로 정규화를 진행할것인가 ( how to estimate the evolving distributions for each future slice )- 메트릭(평균 등)을 직접 예측하는 대신, 잔차 학습(residual learning) 기법을 적용하여 미래 데이터의 평균과 전체 입력 데이터의 평균 간의 차이를 학습하도록 함
- 다양한 변수들이 서로 다른 규모의 변화를 보일 수 있기 때문에, 각 변수에 대해 개별적인 가중치 선호도를 나타내기 위해 초기값이 1인 두 개의 학습 가능한 벡터 𝑊1,𝑊2 사용 => 이를 통해 예측이 가중합 형태로 계산되도록 함
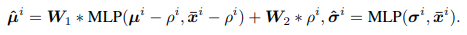
- Denormalization: 예측된 통계적 속성을 사용하여 예측된 결과를 비정규화하여 원래 데이터 분포로 복원함.
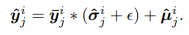
-
Two-stage Training Schema: 통계 예측 모듈을 먼저 학습하고, 이를 고정한 후 예측 모델을 학습하는 방식으로 수행됨.
- 상위 최적화 문제: 예측 손실 함수 𝑙를 최소화하는 매개변수 𝜃를 찾는 것. 이때 𝜙∗ 는 하위 최적화 문제를 해결하여 얻어진 최적 매개변수
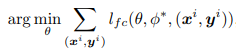
- 하위 최적화 문제: 분포 유사성을 나타내는 손실 함수 𝑙를 최소화하는 매개변수 𝜙를 찾는 것
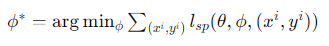
- 상위 최적화 문제: 예측 손실 함수 𝑙를 최소화하는 매개변수 𝜃를 찾는 것. 이때 𝜙∗ 는 하위 최적화 문제를 해결하여 얻어진 최적 매개변수
[ 실험 ]
- 데이터 셋 : Electricity Exchange, Traffic, Weather, ILI (Influenza-Like Illness), ETT (Electricity Transformer Temperature)
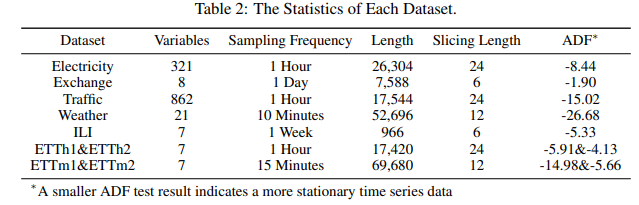
- 슬라이싱 길이 : {6, 12, 24, 48}
- 백본 모델 :DLinear, Autoformer,FEDformer, SCINet
- 옵티마이저 : ADAM
- 평가 지표 : MSE와 MAE
[ 평가 결과 ]
-
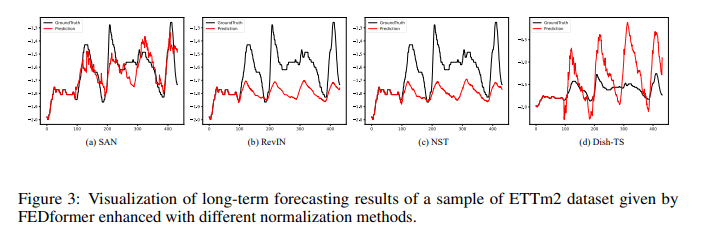
정확도 향상: SAN을 적용한 모델은 기존의 정규화 방법을 사용한 모델에 비해 MSE와 MAE 평가 지표에서 일관되게 낮은 값을 보이며, 예측 정확도가 크게 향상됨.
-
모델 간 비교: SAN은 RevIN, NST, Dish-TS 등 최신 정규화 방법과 비교했을 때 전반적으로 우수한 성능을 나타냄. 특히 비정상성이 강한 데이터셋에서 SAN의 효과가 두드러짐.
-
시계열 특성 반영: SAN은 기존 정규화 방법들이 간과한 슬라이스 단위의 분포 변화를 효과적으로 반영하여 예측 성능을 개선함.
[ 비판적 사고(comment) ]
- 새롭게 본 shift에 대해서도 예측할 수 있다는 ablation test 가 존재하는지
- 통계량 예측이 shift 감안한 예측에 도움이 될 수 있다고 했는데, 통계량으로 예측한거면 비정상적과는 관련없고 정상성으로 예측한 것 아닌가?
