전체요약
1) Time-series UDA는 시간 및 주파수 특징에 대한 domain shift의 다양한 영향으로 인해 어려움을 겪으며, 본 연구는 이를 해결하기 위해 Time-Frequency Consensus Domain Adaptation (TFCDA) 프레임워크를 제안함
2) TFCDA는 기존 UDA 방법에 주파수 encoder, trainable Time-Frequency Mapping (TFM), 그리고 consensus loss를 추가하여 시간-주파수 특징 간의 본질적인 관계를 활용하여 domain shift를 효과적으로 완화함
3) 4개의 publicly available time-series dataset에 대한 광범위한 실험 결과, TFCDA는 기존 UDA 방법의 성능을 크게 향상시키며 real-world application에 대한 잠재력을 보여줌
배경
시간열 분류는 HAR, 수면 단계 분류 같은 문제에서 딥러닝 성능이 좋지만 라벨 의존이 크고 도메인 시프트가 생기면 성능이 급락한다.
이 논문이 강조하는 핵심은 시간열에서 도메인 시프트가 시간 영역 특징과 주파수 영역 특징에 서로 다르게 영향을 줄 수 있다는 점이다.
기존 UDA는 비전 중심이라 주파수 관점을 놓치기 쉽고 시간열 UDA에서도 시간 특징과 주파수 특징을 단순 결합하는 경우가 많다. 그런데 시프트가 시간만 크게 건드리거나 주파수만 크게 건드리는 상황에서는 단순 결합이 오히려 단일 모달리티보다 나빠질 수 있다고 지적한다.
저자들은 시간 신호와 주파수 신호가 변환 가능하다는 점을 근거로 시간 특징과 주파수 특징 사이에는 도메인에 무관한 일관된 매핑이 존재해야 하며 UDA 과정에서도 그 일관성이 유지되어야 한다고 본다
문제정의
- 소스 도메인은 라벨이 있고 로 둔다. 타깃 도메인은 라벨이 없고 로 둔다
- 시간열 입력은 형태이며 는 타임스텝 길이, 은 채널 수이다.
- 시간 입력 는 1D DFT로 주파수로 바꾸고 진폭 스펙트럼을 사용한다
- 변환은 이고 진폭은 로 정의한다
- 결과 주파수 입력은 로 두며 이다
- 목표는 시간 분포 와 를 맞추는 것뿐 아니라 주파수 분포 와 도 함께 정렬하는 것으로 확장한다
방법론
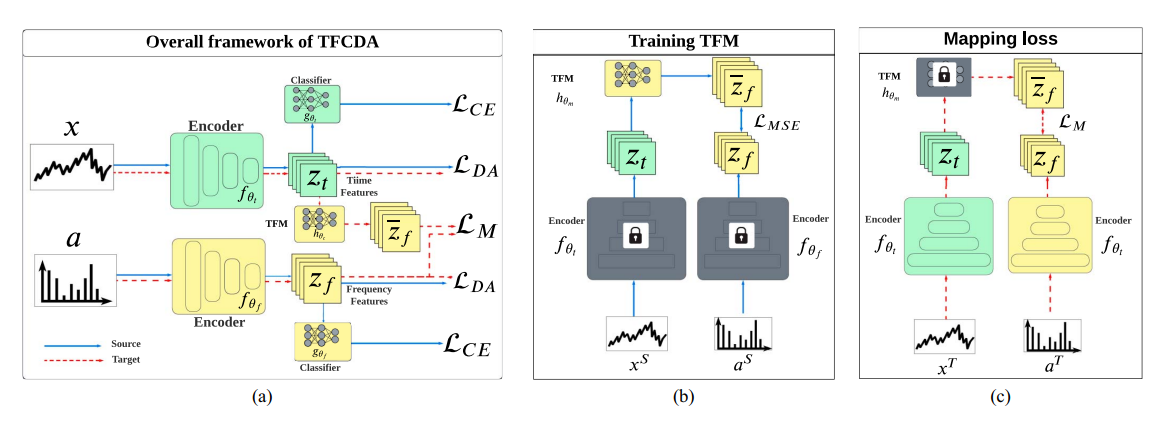
TFCDA는 기존 UDA에 주파수 인코더를 추가하고 시간과 주파수 사이의 관계를 보존하는 TFM과 합의 제약을 넣는다
요소 1 ) 주파수 인코더와 주파수 분류기
- 주파수 인코더는 이고 주파수 분류기는 로 둔다
- 분류 손실과 도메인 손실을 시간과 주파수 양쪽으로 확장한다
- 예를 들어 분류 손실은 로 두고,
- 도메인 손실은 처럼 쓴다
하지만 여기까지만 하면 여전히 단순 결합에 가까워 시프트 불균형 상황에서 성능이 떨어질 수 있다고 지적한다
요소 2 ) TFM : Time Frequency Mapping
- 핵심은 시간 특징 에서 주파수 특징을 예측하는 매핑을 학습해 시간과 주파수 표현을 일관되게 묶는 것이다
- TFM은 로 정의한다.
- 주파수 특징은 로 얻고, 시간 특징으로부터는 를 만든다
- 논문 직관은 푸리에 변환이 어느 도메인에서도 성립하므로 시간과 주파수 사이의 관계는 도메인 불변이며 UDA 중에도 보존되어야 한다는 것이다
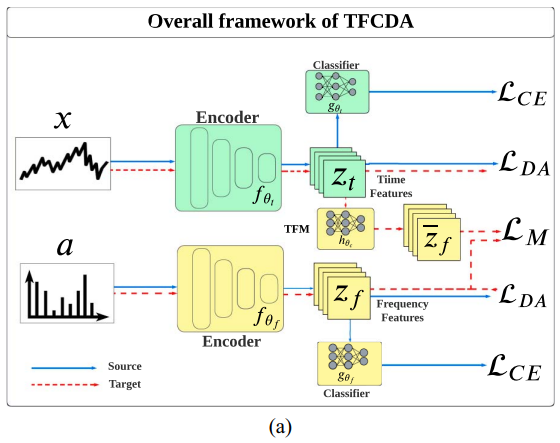
요소 3 ) 소스에서 TFM 학습 손실
- TFM은 소스에서만 학습하며 이 단계에서는 인코더와 분류기를 고정하고 TFM만 업데이트한다
- 손실은 이다
- 이는 소스에서 관측되는 시간 특징과 주파수 특징의 관계를 내부 특징 수준에서 맞춰 도메인 불변 매핑을 근사하는 역할이다.
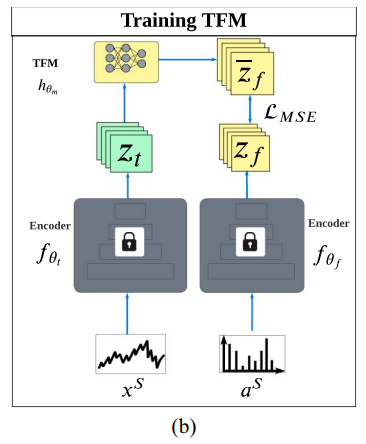
요소 4 ) 타깃에서 합의 손실 매핑 손실
- 이 논문에서 consensus는 매핑 손실 로 구현된다.
- 타깃 적응 단계에서는 TFM을 고정하고 인코더를 업데이트하면서 관계를 유지하게 만든다
- 손실은 이다
- 의미는 타깃에서 시간 특징이 시프트로 흔들려도 시간에서 유도된 가 실제 주파수 특징 와 합의하도록 강제하는 것이다.
- 반대로 주파수 쪽이 흔들리는 상황에서도 두 표현이 계속 합의하게 만든다. 그래서 시간과 주파수 양쪽 시프트를 함께 줄이되 단순 결합이 아니라 관계 보존을 통해 적응적으로 줄인다는 주장이다
요소 5 ) 전체 목적 함수
- 최종 손실은 로 정리한다
- 는 분류 성능 유지, 는 도메인 정렬 강도, 는 시간 주파수 합의 강도다.
요소 6 ) 학습 절차
- 첫째, 특징을 추출해 와 를 만든다.
- 둘째, 를 고정하고 만 로 업데이트한다.
- 셋째, 를 고정하고 를 전체 손실 로 업데이트한다.
추론 시에는 시간 분류기와 주파수 분류기의 예측 확률을 평균내 최종 예측을 만든다
실험 설정
- 데이터셋은 UCIHAR, HHAR, WISDM, SSC 4개를 사용한다
- 각 사람 또는 피험자를 도메인으로 보고 소스에서 학습한 뒤 타깃으로 적응하는 cross domain 시나리오를 랜덤 선정한다
- 비교는 일반 UDA 10종에 TFCDA를 결합해 성능 향상 여부를 보며 mapping 기반 6개와 adversarial 기반 4개로 구성된다
또한 시간열 특화 UDA 3종 ADVSKM, RAIN, SEA와도 비교한다 - 모델은 시간 인코더와 주파수 인코더 모두 동일한 1D CNN 백본을 쓰며 3개의 conv block으로 구성된다
- TFM은 FC 레이어 1개와 BatchNorm, ReLU로 구성된다
- Adam, learning rate , batch size 32를 사용한다
- 기본 가중치는 , , 이다
실험 결과
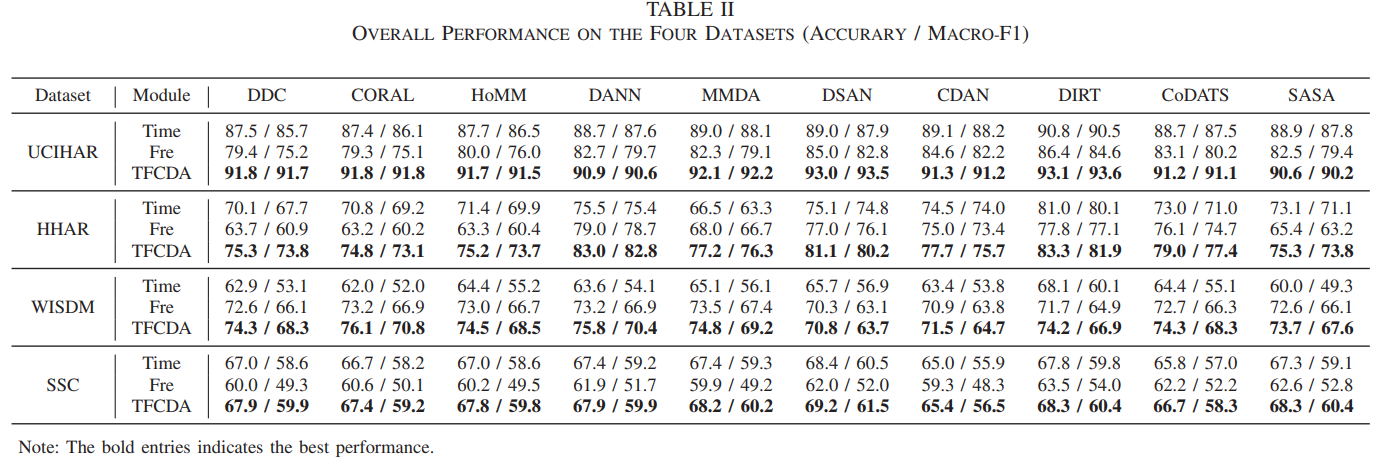
- Table II는 Time, Fre, TFCDA 세 설정을 비교한다
- TFCDA는 대부분의 방법과 데이터셋에서 Time과 Fre보다 높은 성능을 보인다
- 저자들은 평균 향상 폭을 Time 대비 accuracy와 MF1, Fre 대비 accuracy와 MF1로 요약해 제시한다
- 불균형 데이터셋인 WISDM과 SSC에서는 accuracy와 MF1의 차이가 커지며 저자들도 불균형에서는 MF1을 더 신뢰해야 한다고 명시한다
- 또한 데이터셋마다 Time이 더 강한 경우와 Fre가 더 강한 경우가 갈리는데 이는 시프트가 시간과 주파수에 불균형하게 작용할 수 있다는 배경 논지와 연결된다
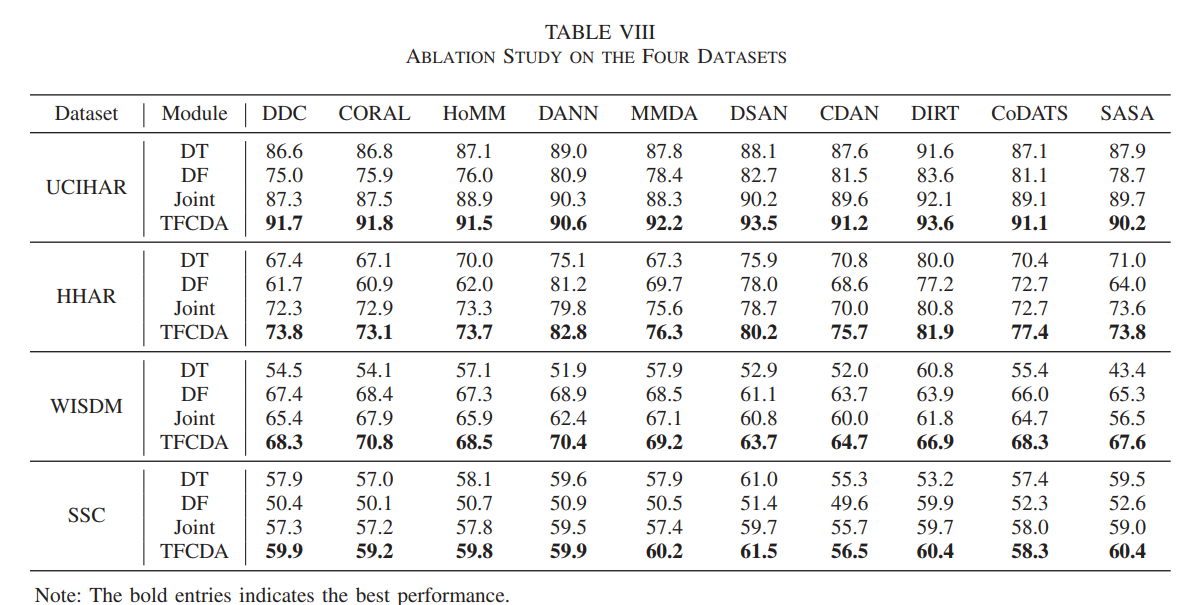
Ablation
- Joint:
시간과 주파수 UDA 손실을 그냥 함께 쓰되
TFM과 은 제거 - DT:
두 인코더 모두 시간 입력만 받게 함
Fre를 없애고 파라미터 수만 맞춘 대조군 - DF:
두 인코더 모두 주파수 입력만 받게 함
핵심 관찰:
- TFCDA는 Joint보다 평균 MF1이 더 높다
저자는 이를 TFM과 이 단순 결합의 한계를 넘어선다는 증거로 해석한다 - TFCDA가 DT와 DF보다 높다
즉 파라미터가 두 배라서 좋아진 것이 아니라 시간과 주파수의 관계를 잡았기 때문이라고 강조한다
매핑 손실만으로도 효과가 있는가
- 으로 두고 만 남긴 설정
cross domain에서 baseline이 크게 떨어지지만
mapping loss만으로도 성능이 크게 복구된다
저자들은 이를 근거로 이 도메인 시프트를 효과적으로 줄이며 향후 source free domain adaptation으로 확장 가능성을 언급한다
결론
- 시간열 UDA에서 시간과 주파수 시프트가 다르게 나타날 수 있다는 문제를 정면으로 다룸
- 기존 UDA에 주파수 인코더, TFM, 매핑 손실 을 추가한 TFCDA를 제안
- 소스에서 TFM으로 시간 주파수 관계를 학습하고
타깃에서는 로 그 관계가 유지되게 강제해서 일관된 전이를 유도 - 4개 공개 데이터셋에서 기존 UDA를 전반적으로 부스팅함
- 향후 source free domain adaptation으로의 확장을 미래 과제로 제시
