[논문분석] RDAM: Domain adaptation under small and class-imbalanced samples (Knowledge-Based Systems 2025)
[ 논문 분석 ]
요약:
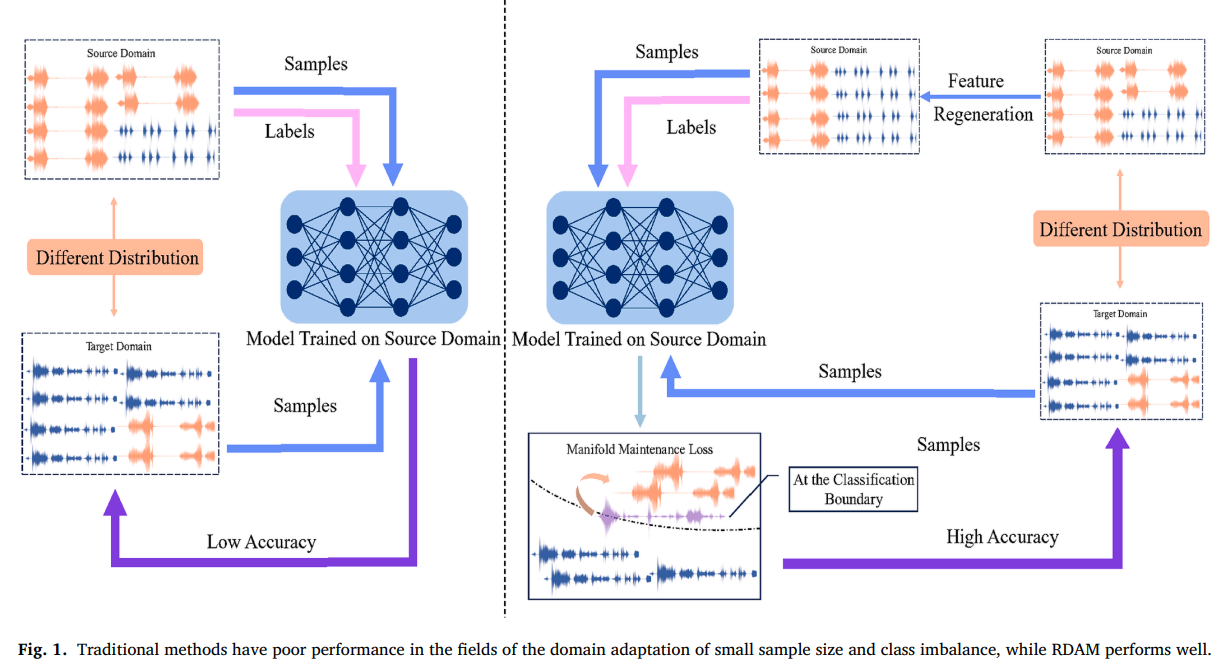
- RDAM은 Small Sample Size 및 Class-Imbalanced 샘플 환경에서 Domain Adaptation 의 성능 저하 문제를 해결하기 위해 Feature Regeneration과 Manifold Maintenance Loss를 제안함.
- Feature Regeneration은 Source Domain의 Feature Quantity를 균형 있게 조정하여 Target Domain의 Feature Spatial Distribution을 효과적으로 커버하며, Manifold Maintenance Loss는 로컬 기하학적 구조를 보존하고 모호한 샘플의 정렬을 개선함.
- 4가지 Time Series 데이터셋과 4가지 Image Domain Adaptation 벤치마크에 대한 광범위한 실험을 통해 RDAM이 다양한 모달리티와 불균형 설정에서 우수한 정확도와 견고성을 달성함을 입증함.
문제 배경
- 주요 문제 : (1) 소규모 샘플 크기와 (2) 클래스 불균형
- 도메인 적응은 소스 도메인 라벨 데이터로 학습한 뒤 타깃 도메인 라벨 없이도 성능을 유지하려는 설정이다.
이 논문은 특히 두 가지 현실 조건을 동시에 다룬다.- 소스 샘플 수가 작다
- 소스 라벨 분포가 클래스 불균형이다
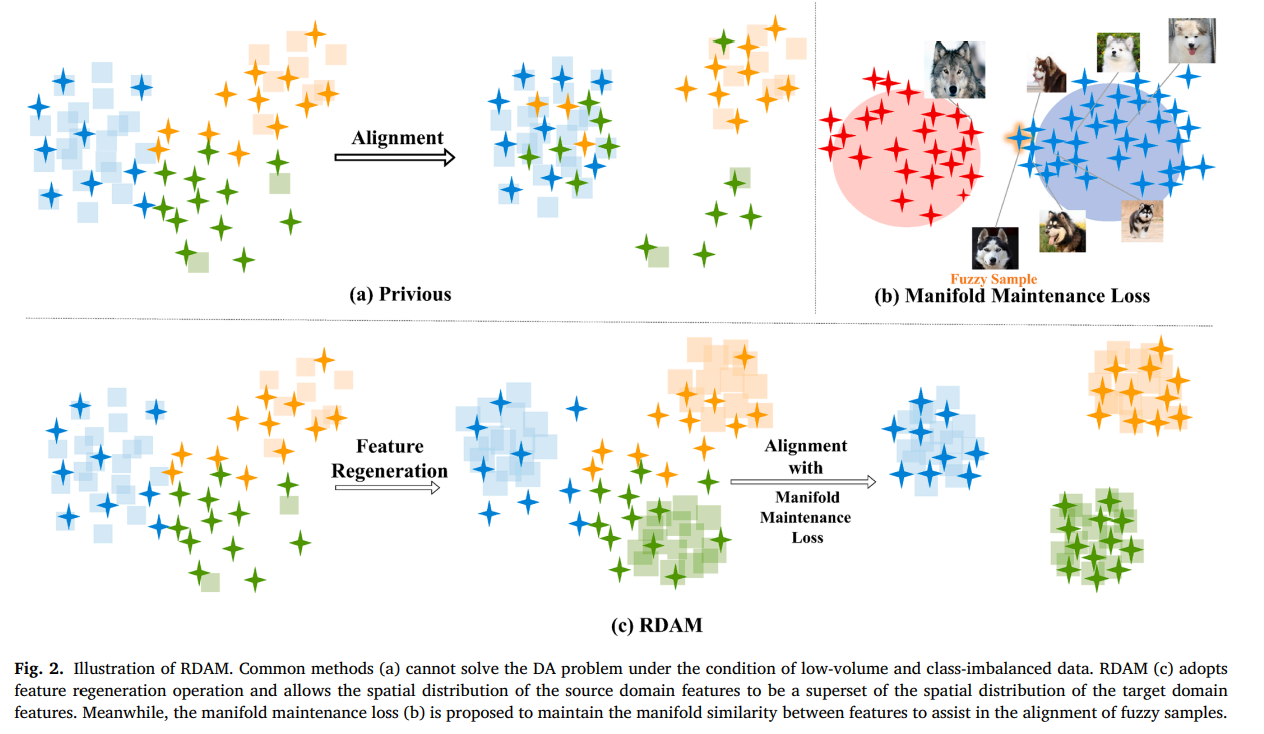
- 저자들은 MCD 계열의 불일치 기반 정렬에서 불균형이 생기면 특정 클래스의 서포트 공간이 과도하게 촘촘해지고 그쪽으로 타깃 특징이 끌려가 오정렬이 발생한다고 설명한다.
- 그래서 클래스마다 서포트 공간이 비슷한 밀도를 갖도록 특징을 재생성하고 모호한 타깃 샘플은 국소 이웃 구조를 보존하며 정렬하도록 설계한다.
방법론
- RDAM은 feature extractor 와 classifier head 그리고 두 개의 discriminant networks 로 구성된다.
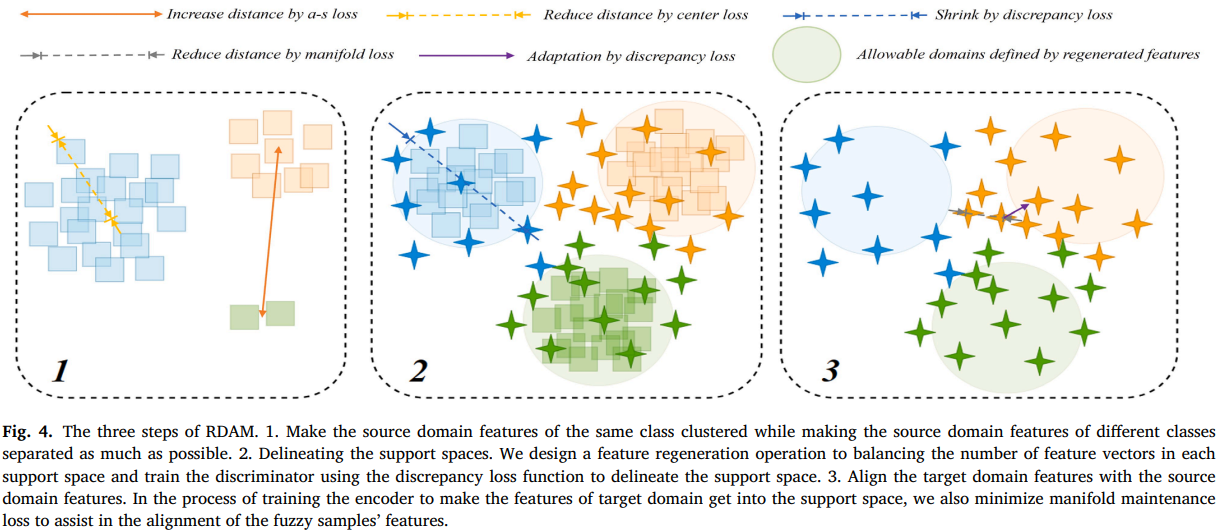
- 절차는 3단계다.
Step 1 소스 특징 공간 정리
- 목표 : 소스 특징이 클래스 내부는 뭉치고 클래스 간은 벌어지게 만든다.
이 구조가 Step 2에서 클래스 중심을 이용한 재생성의 기반이 된다. - 손실 구성 : am softmax loss + center loss
am softmax는 클래스 분리를 강화한다.
center loss는 같은 클래스의 응집을 강화하고 클래스 간 분리에도 기여한다. - 센터 업데이트
- 센터 벡터는 배치 특징에 따라 갱신된다.
- 업데이트 형태는 다음과 같이 제시된다.
- 업데이트 식 :
여기서 은 learning rate다
Step 2 Feature Regeneration
핵심 아이디어
각 클래스에 대해 동일한 prior로 특징을 재생성해서 클래스별 특징 수를 맞춘다.
이렇게 하면 불균형으로 인해 discriminator가 특정 클래스 서포트 공간에 편향되는 현상을 줄인다.
재생성 수식
먼저 클래스 라벨을 균일하게 뽑는다.
- 는 클래스 개수
- 는 재생성 샘플 인덱스
- 는 “재생성 특징 가 속한다고 가정할 클래스”
클래스가 정해졌으면 그 클래스 중심 근처에서 특징을 뽑는다. 즉 해당 클래스 중심 주변에서 가우시안으로 특징을 샘플링한다.
,
재생성 집합 정의
생성된 것들을 세트로 모은다.
- 의미
- 은 재생성 특징 총 개수
- 는 재생성 특징의 집합
- 는 그에 대응하는 재생성 라벨 집합
- 중요한 관찰
는 “진짜 라벨”이 아니라
중심 기반으로 만든 synthetic label이다.
하지만 Step 1이 잘되었다면 주변은 실제 클래스 특징이 있을 법한 위치라는 점을 이용한다.
설정
클래스 중심 간 최소 거리 기반으로 경계를 선명히 유지하도록 설정한다.
- 모든 클래스 센터 쌍 사이 거리 중 최소값을 찾는다
- 그 최소 거리의 절반을 로 둔다
재생성 특징의 역할
재생성 특징은 오직 학습에만 사용해 분류 손실 경로로의 노이즈 전파를 줄인다고 명시한다.
MCD 방식으로 discriminator 학습
는 재생성 특징에 대해 올바른 분류를 유지하면서 타깃 특징에서 discrepancy를 키우도록 학습한다.
목표식
는 타깃 샘플 를 로 인코딩한 특징 행렬이다.
Step 3 Feature Alignment
기본 정렬
Step 3에서는 를 고정하고 를 학습해 discrepancy를 줄인다.
추가 아이디어
정렬 중에 애매한 타깃 샘플이 잘못 끌려가는 문제를 줄이기 위해 manifold maintenance loss를 추가한다.
최종 목적식
- 여기서 는 fuzzy target들 사이의 국소 이웃 거리를 보존하도록 설계된다.
fuzzy target 집합은 두 classifier의 예측이 불일치하는 샘플로 정의된다. - 집합
- 정의 핵심
각 에 대해 최근접 이웃 를 잡는다.
그리고 이웃 거리들 중 작은 값 위주로 개만 평균낸다.
논문 수식
- 의도 설명
가까운 이웃 관계를 유지하면서 outlier 영향은 줄인다.
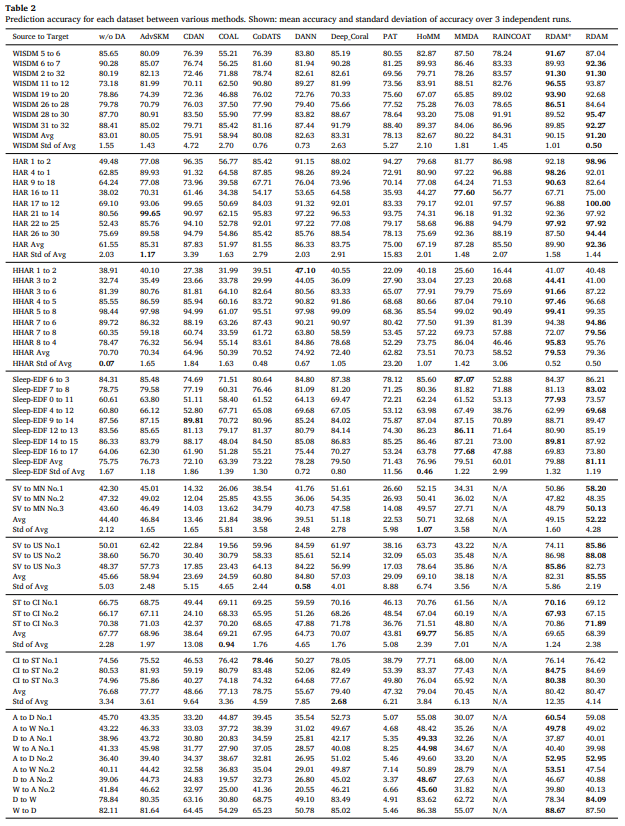
실험 및 실험 결과
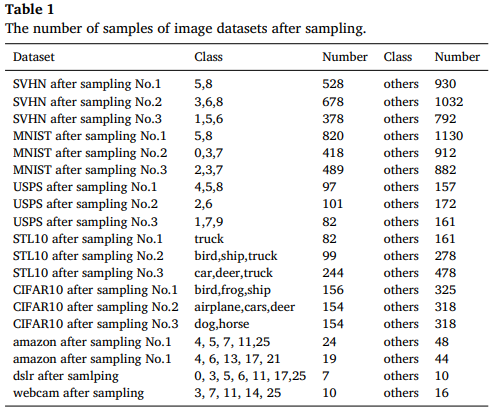
데이터셋 구성
이미지 데이터는 원본에서 random extraction으로 소량 불균형 셋을 만든다.
CIFAR10과 STL10은 클래스 구성이 완전히 같지 않아 open set task라고 언급한다.
Office 31은 Amazon dslr webcam 세 도메인을 사용한다.
샘플링 상세는 Table 1로 제시된다.
비교 방법
- 총 10개 DA 방법을 비교한다고 밝힌다.
- 일반 UDA baselines : Deep Coral
CDAN, DANN, HoMM, COAL - 시계열 UDA baselines : CODATS, AdvSKM, MMDA, RAINCOAT
- 불균형 특화 baseline : PAT
구현 조건
- RTX 4090에서 수행.
- 시계열은 1D CNN
- 일반 이미지 DA는 2D CNN
- Office 31은 ResNet 50
- STL10 CIFAR10은 ViT B16
전체 성능 요약
총 54개 태스크, 11개 baseline 대비 대부분 태스크에서 SOTA임. SOTA가 아닌 경우에도 상위권이라고 주장
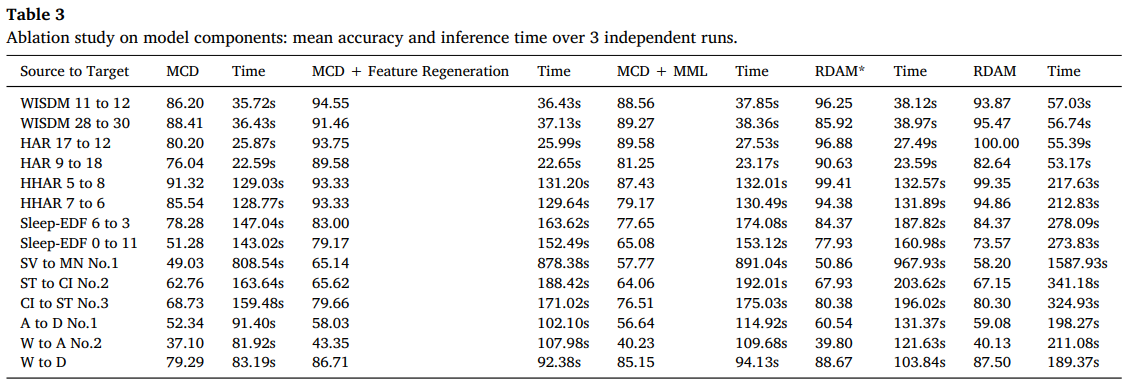
Ablation Study
비교 변형
- MCD
- MCD + feature regeneration
- MCD + MML
- RDAM*
- RDAM
정성 결론
- feature regeneration의 기여가 매우 크다고 정리한다.
- MML은 대부분 도움 되지만 조건에 따라 악화도 가능하다고 설명한다.
- 악화 원인 설명
가 클래스 분리를 충분히 만들지 못하거나 가 너무 낮아 클래스 클러스터가 가까워지면 MML이 이웃 기반 보조 라벨링에서 오판을 유도할 수 있다고 말한다. - 시간 오버헤드
를 3배로 늘려도 학습 시간이 100퍼센트 미만 증가라며 부담이 크지 않다고 주장한다.
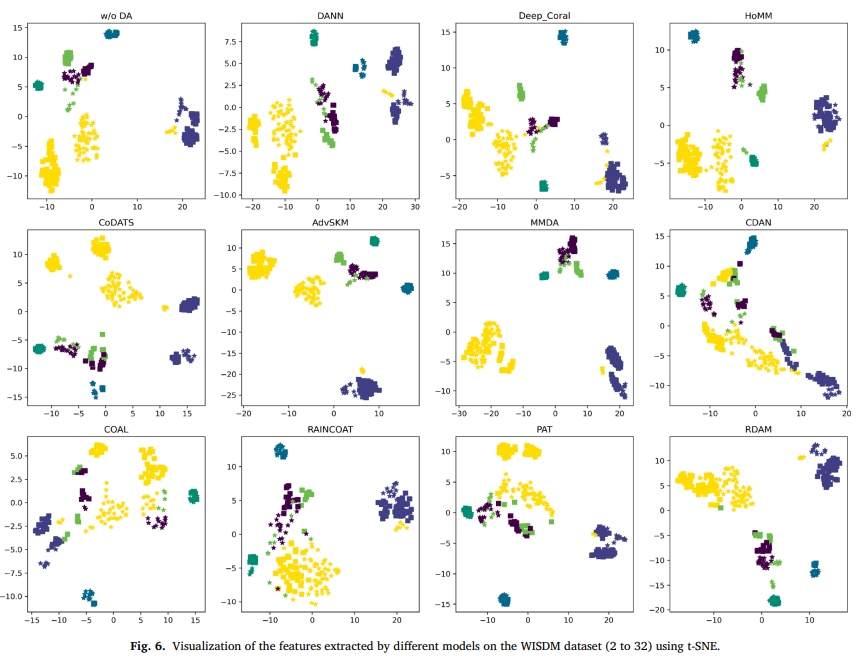
결론
- RDAM을 소량 샘플과 클래스 불균형 상황의 도메인 적응 모델로 제안한다.
- 핵심은 두 가지다.
- feature regeneration으로 클래스별 특징 수를 균형화
- 소스 특징 공간이 타깃 특징 공간을 포함하는 형태로 서포트 공간을 열어두기
- 또한 MML로 모호한 타깃 샘플 정렬을 보조한다고 정리한다.
- 시계열 데이터와 이미지 데이터에서 유효성을 보였다고 결론낸다.
인사이트
- 주로 시계열 데이터를 위해 개발되었지만, 본 방법론은 이미지 데이터셋에서도 놀라운 다재다능함과 효과를 보여주며, 개방형(open-set) DA 설정에서도 잘 작동한다고 함.
- 불균형 UDA 실패는 손실 가중치 문제가 아니라 특징 공간의 밀도 불균형 문제다. 그래서 정렬 전에 클래스별 서포트 공간을 균형화해야 하고, 이를 가장 직접적으로 하는 방법이 중심 기반 feature regeneration이다.
- 또한 애매한 타깃은 pseudo label로 밀지 말고 국소 이웃 구조를 유지하며 오정렬을 방지해야 한다.
