[논문 분석] FastFlow: Unsupervised Anomaly Detection and Localization via 2D Normalizing Flows (2021)
[ 논문 분석 ]
개념 정리
Normalizing Flow: 특징 맵을 정규 분포로 변환하는 기본 아이디어
- 모델은 학습 과정에서 정상 데이터의 분포를 학습하고, 이를 표준 정규 분포로 변환하는 함수 를 최적화함.(학습 과정에서 를 최대화하여 모델 최적화)
즉, 정상 데이터가 표준 정규 분포에서 높은 확률(likelihood)을 갖도록 학습됨- 정상 데이터의 로그 가능도를 최대화하면, 이상 데이터와의 분포 차이를 극대화할 수 있음
- 이상 데이터는 정상 분포에서 벗어나므로 낮은 로그 가능도를 갖게 됨
- 이상치 탐지 시에는 낮은 likelihood를 가진 구간을 효과적으로 찾을 수 있음
**Affine Coupling Layer : “입력을 두 부분으로 분리하여 한 쪽을 조건으로 다른 쪽을 변환하는” 구조
- 입력 데이터에 대해 가역적(역변환이 가능한)인 변환을 적용하는 방법
- 주요 아이디어는 입력 데이터를 두 부분으로 나눈 후, 한 부분은 그대로 두고 다른 부분에 대해 스케일(scale)과 이동(translation) 변환을 적용하는 것 => 역변환 가능하게 됨
- 여기서 s(⋅)와 t(⋅)는 보통 신경망으로 구현되며, 의 정보를 바탕으로 에 대한 스케일과 이동 값을 계산
- 반적으로 Affine Coupling Layer에서 s(⋅)와 t(⋅) 함수는 Conv2d + ReLU + Conv2d와 같은 블록으로 구현. 이 블록은 입력 특징 맵을 받아서 각 위치별로 스케일과 이동 파라미터를 계산하는 역할을 하며, 이를 통해 해당 채널에 대해 비선형 변환을 수행함
- 이러한 Affine Coupling Layer를 여러 번 쌓음으로써 복잡한 데이터 분포를 효과적으로 모델링하고, 학습 과정에서 확률 분포를 정규 분포로 변환하는 데 사용

[Background]
비지도 학습 기반 이상 탐지 및 로컬라이제이션은 라벨링이 어려운 현실적인 문제를 해결하기 위해 연구됨.
- 기존 방식:
Feature-based approach: CNN을 사용하여 정상 이미지의 특징을 추출하고 비정상 여부를 통계적 방법으로 탐지.
Distribution Estimation: 기존 방식은 비정상 특징과 정상 특징 간의 분포 차이를 활용했지만, 비효율적이며 정밀도가 떨어짐.
그래서 점차 NormalizingFlow 등장
Through a trainable process that maximizes the log-likelihood of normal image features, they embed normal image features into standard normal distribution and use the probability to identify and
locate anomalies.
- 문제점:
기존 방법들은 이미지 패치를 개별적으로 평가해야 해서 추론 속도가 느림.
1D Normalizing Flow를 활용한 방법들은 공간 정보를 보존하지 못함.
지역적(anomaly-specific) 특성과 전역적(global) 특성을 효율적으로 통합하지 못함.
[Motivation]
기존의 비지도 학습 기반 이상 탐지 기법들의 한계를 극복하고자함
✅ 기존 방법론의 한계점
- KNN 기반 메모리 뱅크 방식 (Patch Core, SPADE 등)
정상 패치(Feature)를 메모리에 저장하고, KNN으로 거리 측정
메모리 저장 비용이 크고, 검색 속도가 느림 - GAN/VAE 기반 이상 탐지
정상 데이터만을 생성하도록 훈련된 모델(GAN, VAE) 기반으로 이상 탐지 수행
모델 학습이 복잡하고, 생성 품질에 따라 성능이 제한됨 - Normalizing Flow 기반 방법 (CFlow)
Flow 모델을 사용해 정상 데이터의 확률 밀도를 학습하여 이상 탐지
그러나 픽셀 단위 분석을 위해 슬라이딩 윈도우 기법을 적용해야 함 → 속도가 느림
따라서 복잡한 다중 크기 전략이나 슬라이딩 윈도우 기법을 사용해서 FastFlow를 활용하여 엔드 두 엔트 테스트 단계에서 learnable하게 글로벌, 로컬 분포를 반영하려는 모델링을 함
✅ FastFlow가 해결하려는 문제
🏆 End-to-End 방식의 효율적인 이상 탐지 구조 제안
🏆 KNN 없이 직접 확률 밀도를 학습하는 모델
🏆 모든 픽셀을 한 번에 처리하는 2D Normalizing Flow 적용
🏆 ResNet과 ViT(Visual Transformer) 백본 활용하여 강력한 특징 추출
🏆 픽셀 단위(Local) + 전역(Global) 정보 반영하여 이상 탐지 성능 향상
[Contribution]
✅ FastFlow: 2D Normalizing Flow 기반 비지도 이상 탐지 및 로컬라이제이션 모델 제안
기존의 1D Normalizing Flow를 2D로 확장하여 공간 정보를 보존.
Convolution 기반의 연산을 적용하여 공간적 특성을 유지하면서도 이상 탐지를 수행.
✅ 가벼운 네트워크 구조
3×3 및 1×1 컨볼루션을 교차 배치하여 모델 크기를 줄이고 계산량을 최적화함.
슬라이딩 윈도우 없이도 효율적인 이상 탐지 수행.
✅ SOTA 성능 달성
MVTec AD, BTAD, CIFAR-10 등 다양한 데이터셋에서 최고 성능 달성.
특히, 99.4% AUC를 달성하며 기존 방법 대비 정확도와 속도 모두 향상.
[Proposed Method]
✅ 문제정의
-
비지도 이상 탐지(One-class Classification & Out-of-Distribution Detection)
- 훈련 시: 정상 이미지만 학습
- 테스트 시: 정상 & 이상 이미지가 함께 등장
이상 탐지는 테스트 데이터가 정상 분포에서 얼마나 벗어나는지 측정하여 수행
-
기존 Representation-based Method
- 정상 데이터 특징을 저장하고, KNN을 이용해 테스트 데이터와 거리 측정
- 일반적으로 정규 분포, n-Sphere 중심, Gaussian 분포 등을 사용하여 정상 특징을 모델링
✅ FastFlow는 이러한 방식 대신, Feature Distribution을 표준 정규 분포에 직접 매핑하는 방식 채택!
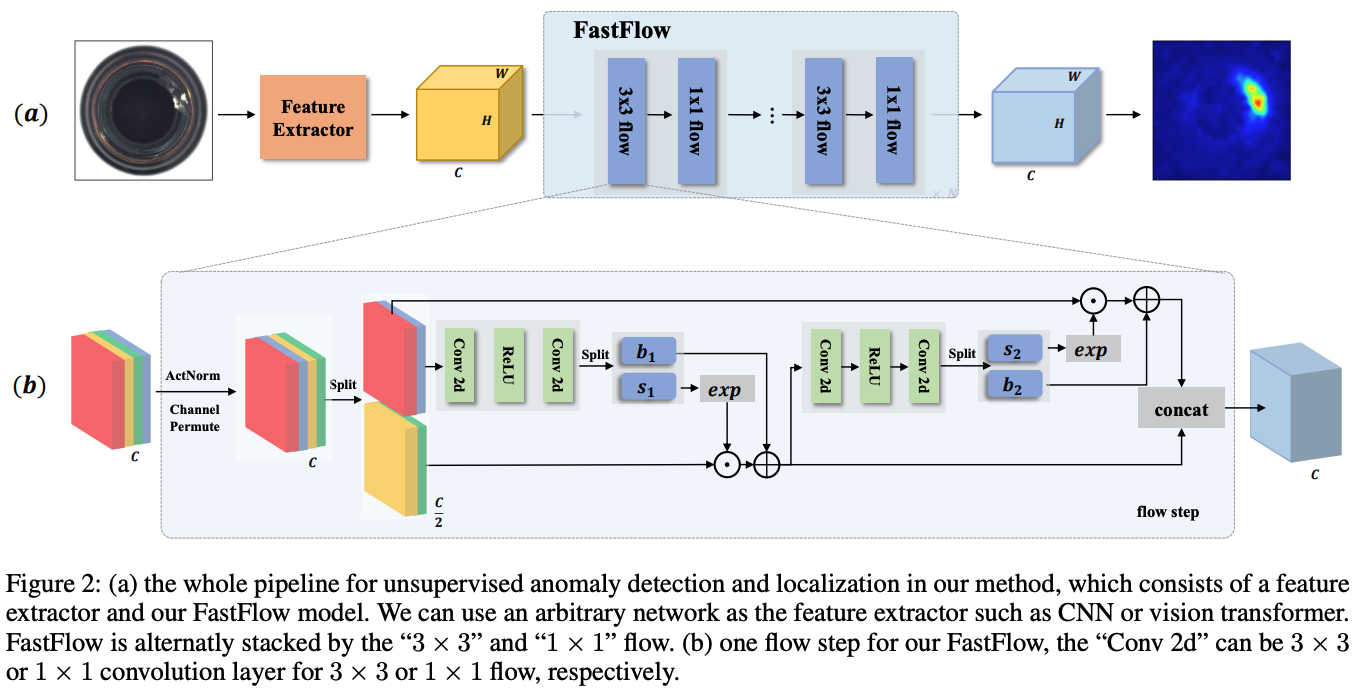
FastFlow는 Feature Extractor + 2D Normalizing Flow의 두 가지 주요 모듈로 구성됨.
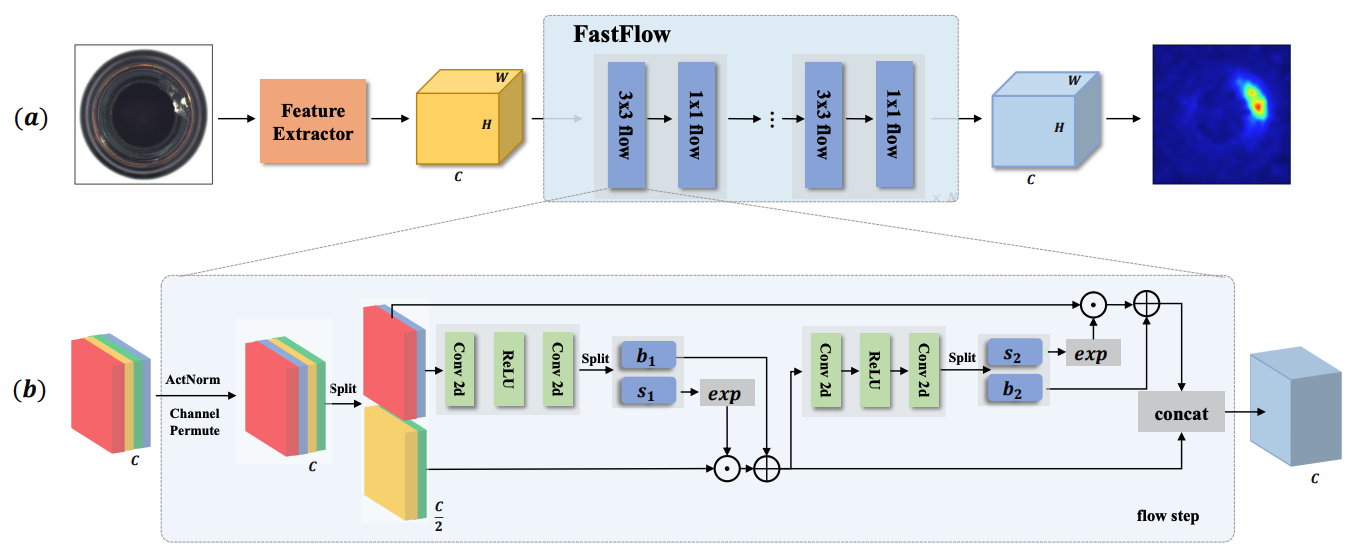
1️⃣ Feature Extractor
ResNet & ViT 기반의 Feature Extractor 사용
- ResNet
마지막 3개의 블록(layer)에서 특징을 추출하여 각각 개별적인 FastFlow 모델에 입력 - Vision Transformer (ViT)
한 개의 특정 레이어의 출력을 사용 → 전역(Global) 패턴을 잘 학습
CNN보다 더 넓은 범위의 상관 관계를 학습하는 능력이 뛰어남
2️⃣ 2D Normalizing Flow
✅ 기본 개념
입력 특징 벡터 를 역변환 가능 함수(Bijective Function) 를 통해 정규 분포 로 변환
학습된 확률 밀도(likelihood) 를 기반으로 이상 여부 판별
이상 데이터는 학습된 정상 데이터의 분포를 벗어나므로 낮은 확률(likelihood) 을 가짐
✅ FastFlow 전체 파이프라인
특징 맵을 정규 분포(standard normal distribution)로 변환하기 위해 Normalizing Flow 기반 모델을 사용
3×3 Flow와 1×1 Flow를 교차(stacking)하여 모델을 구성
- 3×3 Flow: 국소적인 정보를 활용
- 1×1 Flow: 채널 차원에서 정보를 조정
확률 맵 생성 → 이상 탐지 (Anomaly Detection & Localization)
변환된 특징 맵을 기반으로 확률(likelihood) 맵을 생성
이상 영역(anomalous regions)은 확률이 낮으며, 이를 heatmap 형태로 시각화 가능
✅ 개별 Flow Step (Flow Block 구조)
1) 입력 특징 맵(Channel C) → ActNorm & Channel Permute
- ActNorm (Activation Normalization): 특징의 분포를 정규화하여 학습 안정성 향상
- Channel Permute (채널 순열 변환): 특정 채널 정보를 교환하여 흐름을 다르게 학습
2) Split (특징을 두 부분으로 분할, c/2 채널씩 나눔)
- 하나는 직접 전달되고, 나머지는 변환 연산 수행
3) Affine Coupling Layer (비선형 변환 수행)
- 나눠진 한 부분을 입력으로 받아 변환을 수행
- Conv2d + ReLU + Conv2d 블록을 거친 후, 최종적으로 비선형 변환을 수행
4) 변환된 부분을 다시 결합 (Concat)
- 두 부분을 다시 결합하여 다음 Flow Step으로 전달
- 이 과정이 여러 번 반복되면서 데이터 분포가 정규화됨
✅ FastFlow의 확률 밀도 변환 과정
2️⃣-1️⃣ 확률 밀도 변환
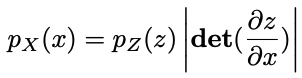
: 원본 데이터의 확률 밀도
: 변환된 공간에서의 확률 밀도 (표준 정규 분포)
: Jacobian Determinant, 변환 함수의 미분 행렬
2️⃣-2️⃣ 로그 가능도(log-likelihood) 계산
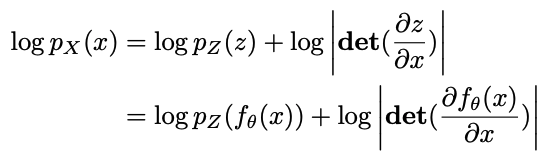
학습 과정에서 를 최대화하여 모델 최적화
이상 데이터는 학습된 정상 분포에서 벗어나므로 낮은 로그 가능도 값을 가짐
왜 를 최대화해야 하는가?
정상 데이터의 확률을 높여야 함
모델은 학습 과정에서 정상 데이터의 분포를 학습하고, 이를 표준 정규 분포로 변환하는 함수 를 최적화함.
즉, 정상 데이터가 표준 정규 분포에서 높은 확률(likelihood)을 갖도록 학습됨.
이상 데이터는 정상 분포에서 벗어나므로 낮은 로그 가능도를 갖게 됨
정상 데이터는 학습 과정에서 분포를 맞추지만, 이상 데이터는 학습된 정상 분포에 포함되지 않음.
따라서 이상 데이터는 모델이 학습한 정상 분포에서 벗어나며 낮은 확률(likelihood) 값을 가짐.
이상 탐지는 이 낮은 확률을 감지하여 수행됨.
즉, 정상 데이터의 로그 가능도를 최대화하면, 이상 데이터와의 분포 차이를 극대화할 수 있음
🎯 2D Normalizing Flow 설계
FastFlow는 K개의 변환 블록(transform block)으로 구성
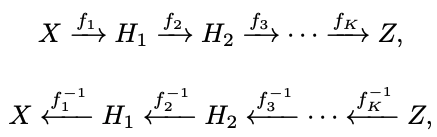
모든 변환 는 Affine Coupling Layer 기반으로 설계됨
CNN 기반 3×3 및 1×1 컨볼루션 을 활용하여 공간적 특징을 유지
[Experiments]
✅ 1. 데이터셋
MVTec AD: 15개 산업 제품, 5,354개 이미지 (정상 & 이상 데이터 포함)
BTAD: 산업 제품 3개 카테고리 (2,540개 이미지)
CIFAR-10: 10개 카테고리에서 1개 카테고리를 이상치로 간주
AUROC (Area Under ROC Curve) 기준으로 평가
✅ 2. 비교 실험
1) MVTec AD 데이터셋에서 Anomaly Detection 및 Localization 성능 비교
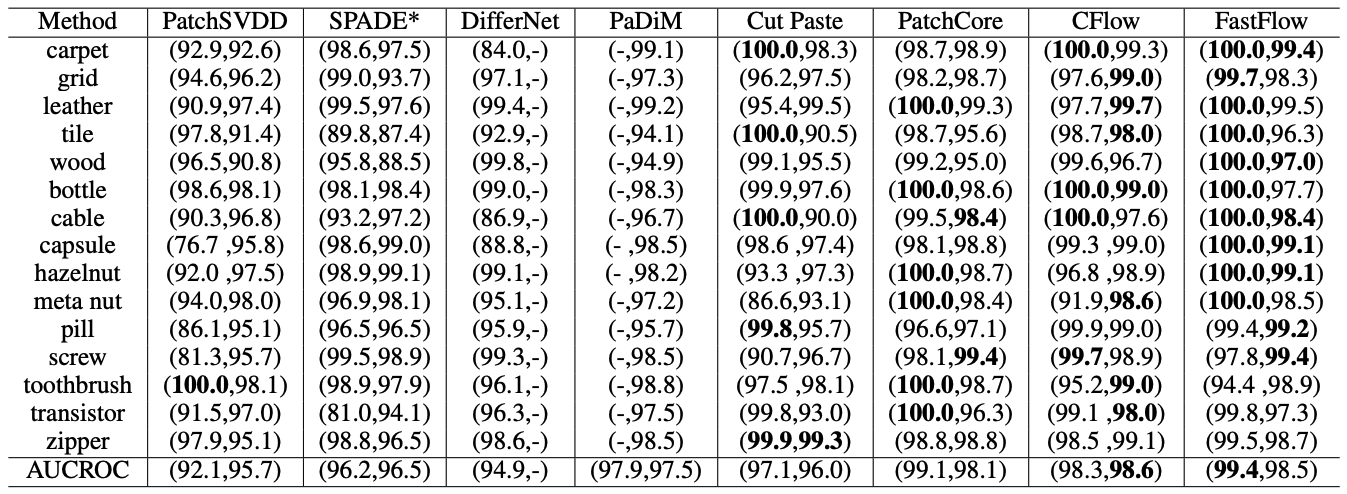
FastFlow는 기존 SOTA 모델들보다 더 높은 Image-level (99.4%) 및 Pixel-level AUC (98.5%)를 기록.
기존 모델들과 비교했을 때 정확도와 효율성(추론 속도)에서 우수한 성능을 보임.
특히 PatchCore, CFlow 대비 향상된 Pixel-level 성능을 보이며, 이상 패턴을 더욱 정밀하게 탐지 가능.
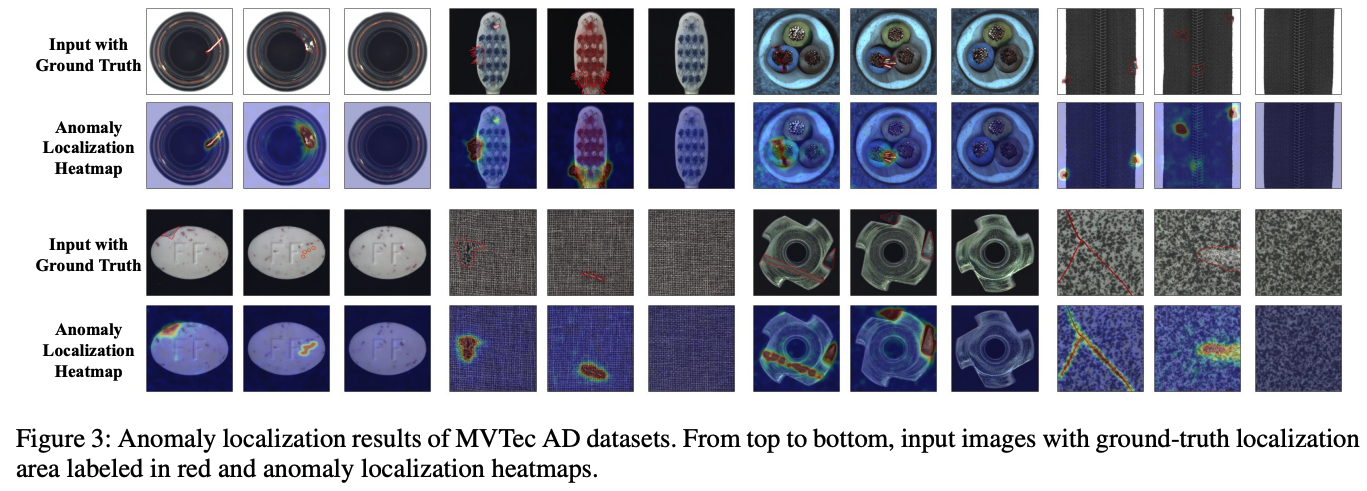
2) BTAD 데이터셋에서 Anomaly Localization 성능 비교
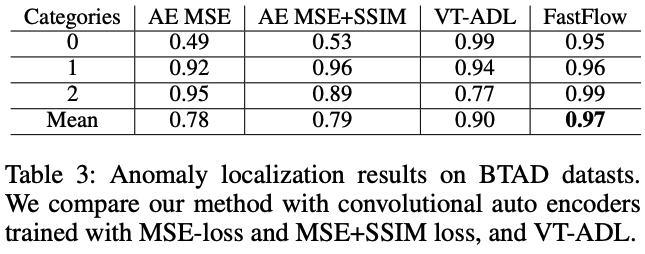
FastFlow는 BTAD 데이터셋에서도 가장 높은 97%의 Pixel-level AUC를 기록
기존 Autoencoder 기반 기법(AE MSE, AE MSE+SSIM)보다 최대 19% 향상된 성능
이상 데이터의 픽셀 단위 탐지(localization)에서 매우 효과적
3) CIFAR-10 데이터셋에서 Anomaly Detection 성능 비교
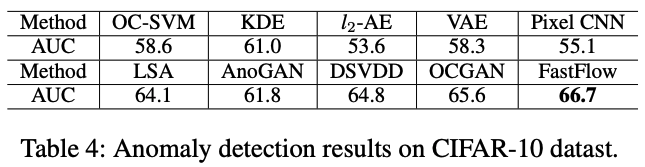
CIFAR-10과 같은 자연 이미지에서도 FastFlow는 가장 높은 AUC(66.7%)를 기록
기존 이상 탐지 기법(OCSVM, KDE, VAE, PixelCNN 등)보다 높은 성능을 보임
하지만 MVTec AD, BTAD 대비 상대적으로 낮은 성능 → 자연 이미지에서의 이상 탐지는 더 어려운 문제
✅ 3. Ablation Study
Ablation Study - FastFlow의 컨볼루션 커널 실험
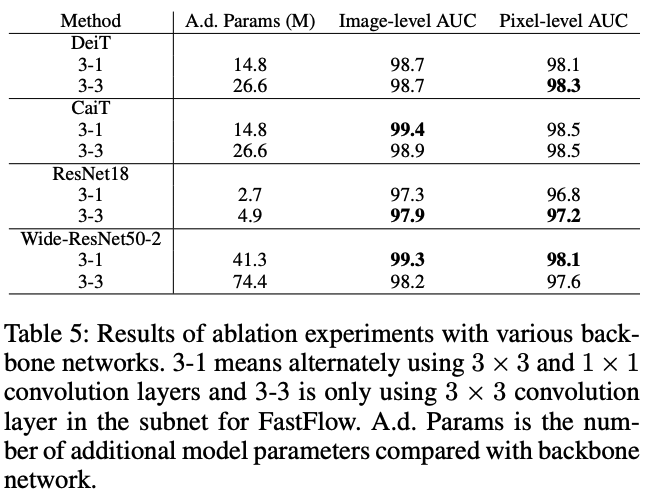
3×3 + 1×1 커널을 교차적으로 사용하는 것이 성능과 속도에서 균형 잡힌 선택
3-3 (3×3 only) 모델은 더 많은 파라미터를 가지지만 성능 향상은 미미함
3-1 (3×3 + 1×1 혼합) 모델은 비슷한 성능을 유지하면서도 파라미터 수와 계산량을 절약
Wide-ResNet50-2와 CaiT 기반 모델에서 가장 높은 성능 기록
99.4% (CaiT), 99.3% (Wide-ResNet50-2)로 최고 성능
✅ Feature Visualization and Generation
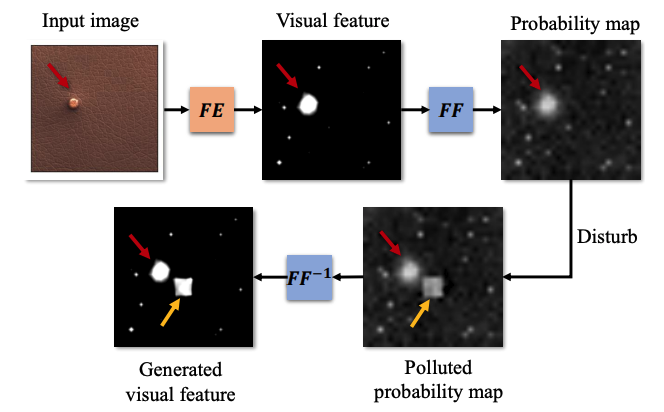
1️⃣ 순방향 과정 (Forward Process)
입력 이미지(Input Image) → 특징 추출(Feature Extractor, FE) → FastFlow 변환(FF) → 확률 맵(Probability Map)
- 입력 데이터를 정규 분포로 매핑 → 이상 탐지
1) 입력 이미지가 FE(Feature Extractor, 예: ResNet, ViT)를 통해 특징 벡터로 변환됨
2) FastFlow(FF):
- 정규 분포(𝒩(0, I))로 변환되도록 학습됨
- 이상치(Anomaly)는 학습된 정상 데이터의 분포에서 벗어나므로 확률 값이 낮아짐
3) 최종적으로, 이미지의 각 픽셀에 대해 "이상 탐지 확률 맵(Probability Map)"이 생성됨
빨간색 화살표 (Red Arrow) → 원래 존재했던 이상 영역 (Original Anomaly)
2️⃣ 역방향 과정 (Inverse Process, FF⁻¹)
확률 맵(Probability Map) → FastFlow 역변환(FF⁻¹) → 생성된 특징 맵(Generated Visual Feature)
- 정규 분포에서 데이터를 복원 → 추가된 노이즈가 이상으로 감지되는지 테스트
1) FastFlow의 역변환(FF⁻¹)을 수행하여 원래의 특징 벡터를 복원
2) 특정 영역(노란색 화살표 부분)에 노이즈를 추가하여 변형된 확률 맵을 생성
3) 이 변형된 확률 맵을 다시 FastFlow 역변환을 통해 시각적 특징으로 변환
- 이 과정에서 FastFlow가 추가된 노이즈를 "새로운 이상 영역(New Anomaly)"으로 인식하는지 확인
- 노란색 화살표 (Yellow Arrow) → 새로운 이상이 탐지됨 (New Anomaly Introduced by Noise Disturbance)
FastFlow는 단순히 이상 탐지만 수행하는 것이 아니라 역방향 변환을 통해 데이터 분포를 복원하는 능력도 가짐!
추가된 노이즈에 대해 모델이 어떻게 반응하는지 평가하여, 이상 탐지의 신뢰성을 검증할 수 있음!
[Conclustion]
✅ FastFlow는 2D Normalizing Flow를 기반으로 한 비지도 이상 탐지 및 로컬라이제이션 기법.
✅ 기존 방식 대비 추론 속도 향상 및 정확도 증가.
✅ CNN뿐만 아니라 Transformer 백본에도 적용 가능하여 확장성이 뛰어남.
✅ MVTec AD, BTAD, CIFAR-10 데이터셋에서 최고 성능을 달성.
✅ 향후 연구 방향: 보다 정밀한 이상 탐지 및 다양한 백본 네트워크와의 조합 최적화.
개인연구 아이디어
- Affine Coupling Layer는 입력을 두 부분으로 나눠 한 쪽의 정보를 조건으로 다른 쪽을 변환하기 때문에, 로컬 정보와 글로벌 정보를 동적으로 결합하는 데 도움을 줄 수 있음.
- 예를 들어, 전체 입력의 글로벌 컨텍스트를 이 제공하고, 이 정보를 바탕으로 에 대해 스케일과 이동 변환을 적용하면, 해당 입력의 로컬 특성을 조건부로 조정할 수 있다.( 글로벌 정보로 로컬 정보 를 조정) 이러한 방식은 복잡한 데이터 분포를 효과적으로 모델링하는 데 유리하며, 동적 변화에 적응하는 데도 도움이 됨
- 시계열에서 채널 차원 분할 말고 서로 다른 역할(예, 글로벌 컨텍스트 vs. 지역 정보)을 담당하도록 분할해서 비슷한 역할을 하도록 설계
- 시계열 데이터는 1차원 데이터이기 때문에 Conv2d 대신 Conv1d를 사용하여 동일한 구조, 즉 Conv1d + ReLU + Conv1d 블록을 적용하기 => 이렇게 하면 시계열의 국소 패턴을 포착하고, s(⋅)와
t(⋅) 함수를 효과적으로 학습 - 의 정보를 바탕으로 에 대한 스케일과 이동 값을 계산
- 조건부 정보 활용:
의 정보를 사용함으로써 에 적용되는 변환이 해당 입력의 문맥이나 특징을 반영할 수 있. 이는 전체 데이터 분포의 복잡한 비선형 관계를 효과적으로 모델링하는 데 도움 - 가역적 구조 유지:
을 그대로 유지하고, 에 대해 조건부 변환을 적용하면 역변환이 명시적인 수식으로 표현되어, 모델의 확률 밀도를 계산하거나 샘플링할 때 효율적 - 모델의 유연성 및 표현력:
와 를 복잡한 함수(예, Conv2d+ReLU+Conv2d 또는 시계열의 경우 Conv1d+ReLU+Conv1d)로 구현하면, 단순한 활성화 함수 이상의 표현력을 가지게 되어 데이터의 다양한 패턴을 학습
- 조건부 정보 활용:
