[ 논문 분석 ] UniVAD: A Training-free Unified Model for Few-shot Visual Anomaly Detection(CVPR 2025)
[ 논문 분석 ]
✅ 요약 :
학습 과정 없이, 소수 정상 샘플만으로 구성 요소 분할→패치 매칭→그래프 모델링의 3단계로 이상을 다각도로 평가하여, 다양한 도메인에 적용 가능한 범용 Few-shot VAD 솔루션을 제공
- 목표 :
- 훈련 불필요(Training‑free), 도메인 통합(Universal), Few‑shot 이상 탐지 기법 제시
- 산업·의료·논리 등 서로 다른 분야의 데이터에 단일 모델로 대응하고, 사전 학습 없이도 몇 장의 정상 샘플만으로 새로운 객체의 이상을 탐지
- 입력 및 출력:
- 입력: 쿼리 이미지 와 K장의 정상 참조 이미지
- 출력: 픽셀 단위 이상 점수 맵 및 전체 이미지 이상 점수
- 핵심 처리 흐름:
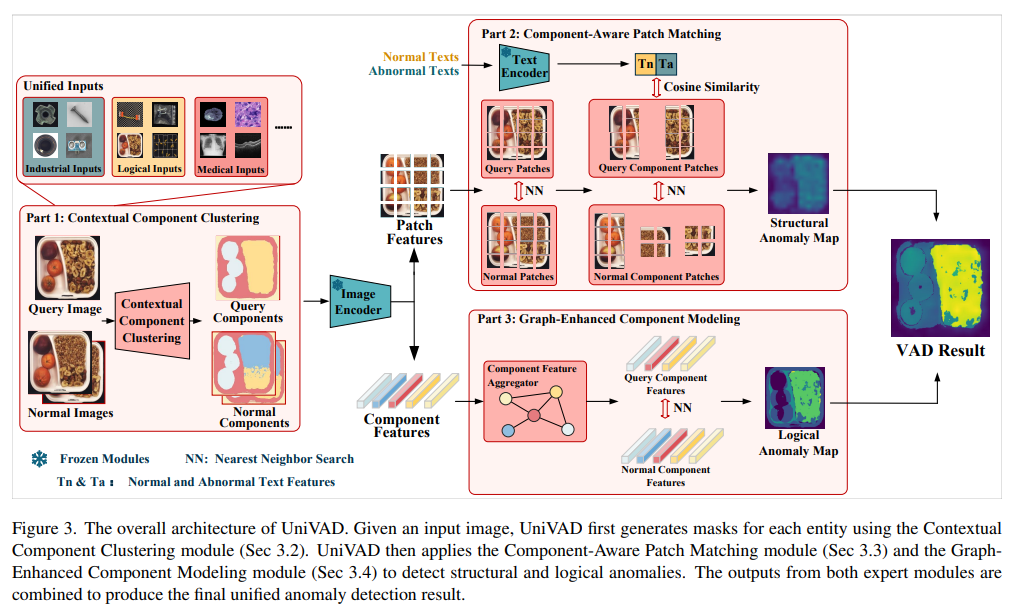
- Contextual Component Clustering (C3)
- SAM(또는 유사 모델)으로 얻은 초기 마스크를
- 정상 샘플의 특징 클러스터링과 IoU 기반 필터링으로 정제하여
- 구성 요소(컴포넌트) 단위로 분할
- Component‑Aware Patch Matching (CAPM)
- 각 컴포넌트를 작은 패치로 세분화하고
- 정상 샘플 패치와의 코사인 유사도, 컴포넌트 제약 매칭, 이미지‑텍스트 매칭을 결합해
- 구조적 이상 점수 산출
- Graph‑Enhanced Component Modeling (GECM)
- 분할된 컴포넌트들을 그래프 노드로 보고
- 노드 임베딩 간 어텐션 기반 유사도, 크기·위치·색상 등의 지오메트릭 정보를 활용해
- 논리적 이상 점수 산출
- 점수 통합 및 이상 판단
- 구조적 이상 점수와 논리적 이상 점수를 가중 합산하여
- 픽셀 단위의 이상 맵과 이미지 전체의 이상 점수를 결정
1. 서론
문제 정의 및 배경
- Visual Anomaly Detection (VAD) 은 이미지에서 ‘정상(정상 샘플 분포)’을 벗어나는 부분을 자동으로 찾아내는 과제
- 적용 분야: 제조 불량 검사, 의료 영상 판독, 논리적 규칙 검증 등 광범위하게 활용되나,
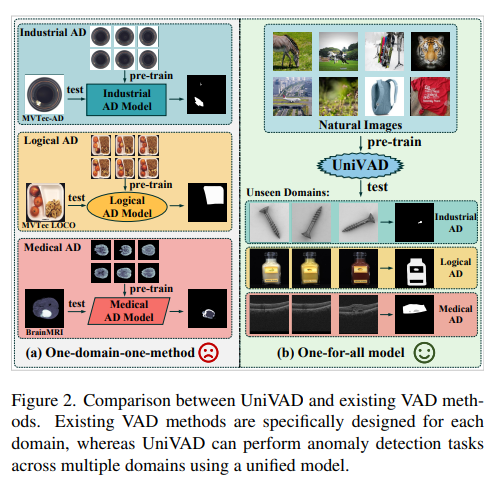
- 한계점
- 도메인 특화: 산업용·의료용·교통용 등 각 분야별로 별도의 모델을 훈련해야 하며
- 카테고리별 학습: 객체별(one‑category‑one‑model) 모델 구조로, 새로운 객체마다 대량의 “정상” 데이터를 확보해야 함.
→ 이로 인해 새로운 도메인·새로운 객체에 대한 범용성 및 확장성이 크게 저해됨.
연구 목표 및 기여
- 훈련 불필요(Training‑free): 사전 훈련이나 파인튜닝 없이도
- 범용 통합(Unified): 산업·의료·논리 등 서로 다른 도메인을 단일 파이프라인으로 처리
- Few‑shot: 테스트 시 몇 장(예: 1~5장)의 정상 샘플만으로 새로운 객체의 이상을 탐지
이를 위해, 컴포넌트 분할→패치 매칭→그래프 모델링의 3단계 모듈로 이상 신호를 다각도로 통합 평가하는 UniVAD 프레임워크를 제안함.
2. 관련 연구 정리
1) 카테고리‑별 전통 VAD
- 각 객체(카테고리)마다 하나의 모델을 학습
- 대량 정상 샘플 필요, 새로운 카테고리 대응 어려움
2) 도메인 일반화·도메인 적응 기반 VAD
- 여러 도메인의 공통 표현 학습 시도
- 대부분 파인튜닝 또는 별도 도메인 레이어 추가 필요
3) 소수샷 VAD / 제로샷 VAD
- 정상 샘플 수를 극소화하려는 연구
- 하지만 대부분 사전 학습된 인코더에 의존하며, 비지도 세부 모듈 설계는 미흡
예를 들어 One-for-All Few-Shot Anomaly Detection via Instance-Induced Prompt Learning (ICLR 2025)는 인코더(비전·언어 백본)는 사전학습된(Pre-trained) CLIP/BLIP 스타일 모델을 그대로 가져다 씀. 그리고 인스턴스 유도 프롬프트 생성기가 도메인 레이어라고 이해할 수 있음.
- 기존 백본의 일반적 표현력은 그대로 유지
- 특정 도메인·샘플(few-shot)에서 필요한 정보만 추가로 학습
- 결국 논문에서는 별도의 도메인 레이어(adapter)가 사전학습된 고정된 백본 위에 얹혀 있다고 보면 됨
4) 훈련 불필요(Training‑free) 접근
- 통계적·메모리 기반 방법 등
- 일반화 성능은 제한적이거나, 복잡한 수작업 전처리 필요
차별점: UniVAD는 어떠한 파인튜닝·추가 학습 없이, “소수의 정상 샘플”만으로 구성 요소 분할→패치 매칭→관계 그래프 분석을 일사불란하게 수행해 범용 VAD를 실현
3. 제안 방법론 (UniVAD)
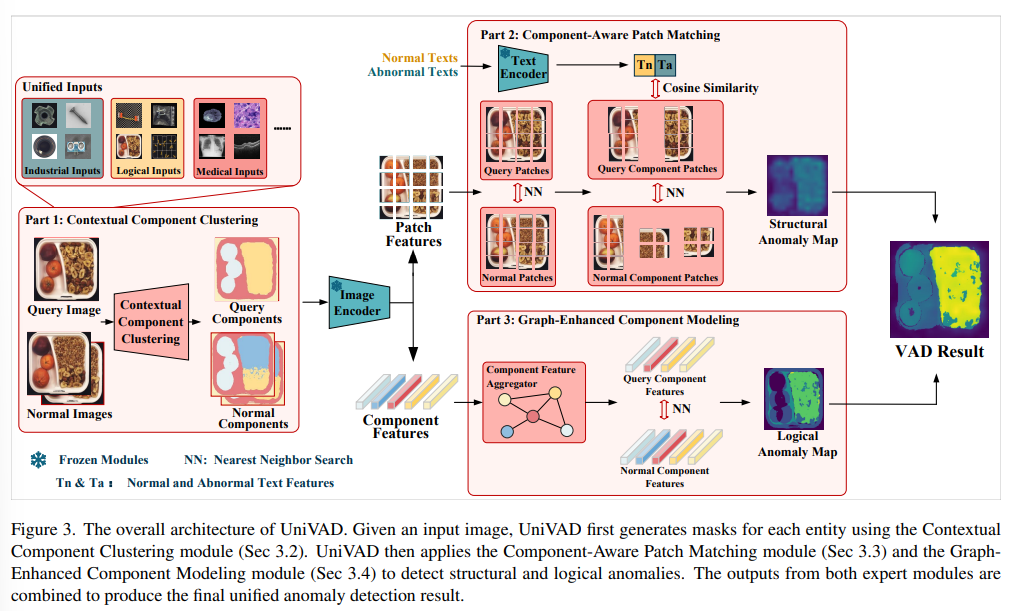
전체흐름:
A[쿼리 이미지 + K 정상 샘플] --> B[C3: 컴포넌트 분할]
B --> C[CAPM: 구조적 이상 점수]
B --> D[GECM: 논리적 이상 점수]
C & D --> E[이상 점수 통합 → 결과 출력]
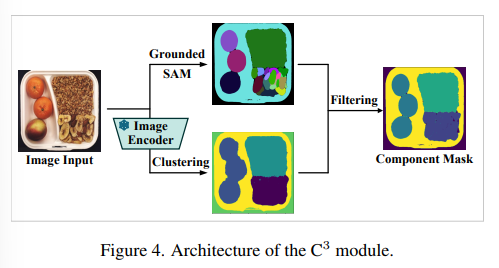
Contextual Component Clustering (C3)
- 초기 분할: SAM(Segmentation Anything Model) 또는 유사 모델로 대략적 마스크 획득
- 특징 클러스터링: 정상 샘플의 특징 벡터에 K‑means 적용 → N개 중심(cluster)
- 마스크 정제: 각 클러스터 중심과 SAM 마스크의 IoU 매칭 → 최종 컴포넌트 단위 마스크 도출
- 효과: 소수 정상샘플 환경에서도 과세분화/과소분할 없이 안정적 분할 가능
Component‑Aware Patch Matching (CAPM)
-
패치 생성: C3가 분할한 각 컴포넌트 영역을 고정 크기 패치로 재세분화
-
구조 매칭
- 패치별 코사인 유사도 계산
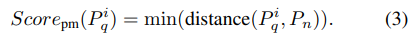
- “컴포넌트 제약 매칭”: 동일 컴포넌트 간 패치 페어링을 위해 매칭 범위를 제약함
- 잘못된 부위끼리 매칭해서 생기는 잡음(false alarm)을 줄이고,각 부위별로 구조적으로 얼만큼 닮았는지를 정확히 평가

- 잘못된 부위끼리 매칭해서 생기는 잡음(false alarm)을 줄이고,각 부위별로 구조적으로 얼만큼 닮았는지를 정확히 평가
- 패치별 코사인 유사도 계산
-
이미지‑텍스트 매칭: Visual‑Language 특징 매핑을 추가해 클래스 지식 활용
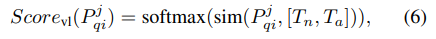
-
구조적 이상 점수: 세 가지 점수를 가중 평균해 최종 구조 점수 산출
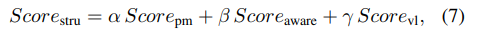
Graph‑Enhanced Component Modeling (GECM)
-
그래프 구성: 컴포넌트별 특징을 노드로, 유사도를 엣지 가중치로 설정
- 각 노드는 컴포넌트 영역을 CNN(또는 ViT) 인코더에 통과시켜 얻은 피처 벡터
- 엣지 가중치는 두 노드 사이의 관계를 숫자로 표현해 특징 유사도와 공간적 관계를 결합한 초기 인접 행렬을 만듬
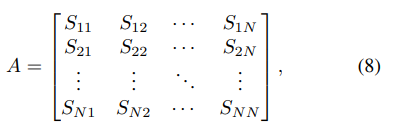
-
어텐션 기반 임베딩: 그래프 어텐션 네트워크(GAT)로 노드 임베딩 계산
- 정상 참조 샘플 그래프에서 얻은 임베딩과 쿼리 그래프 임베딩 간의 평균 유클리드 거리
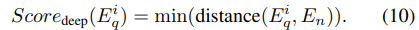
- 정상 참조 샘플 그래프에서 얻은 임베딩과 쿼리 그래프 임베딩 간의 평균 유클리드 거리
-
지오메트릭 정보: 크기·위치·색상 등 정형 특성도 노드에 부가
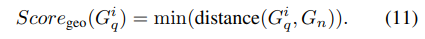
- 컴포넌트 위치·크기·색 분포 등의 정형 특성을 벡터로 만들고,쿼리 vs 정상 간 차이를 유사하게 측정
- 지오메트릭 특성 벡터 생성 방법

- 지오메트릭 특성 벡터 생성 방법
- 컴포넌트 위치·크기·색 분포 등의 정형 특성을 벡터로 만들고,쿼리 vs 정상 간 차이를 유사하게 측정
-
논리적 이상 점수: 어텐션 임베딩 거리와 지오메트릭 차이를 결합해 산출
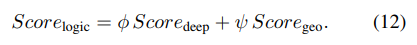
-
최종 이상 점수
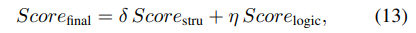
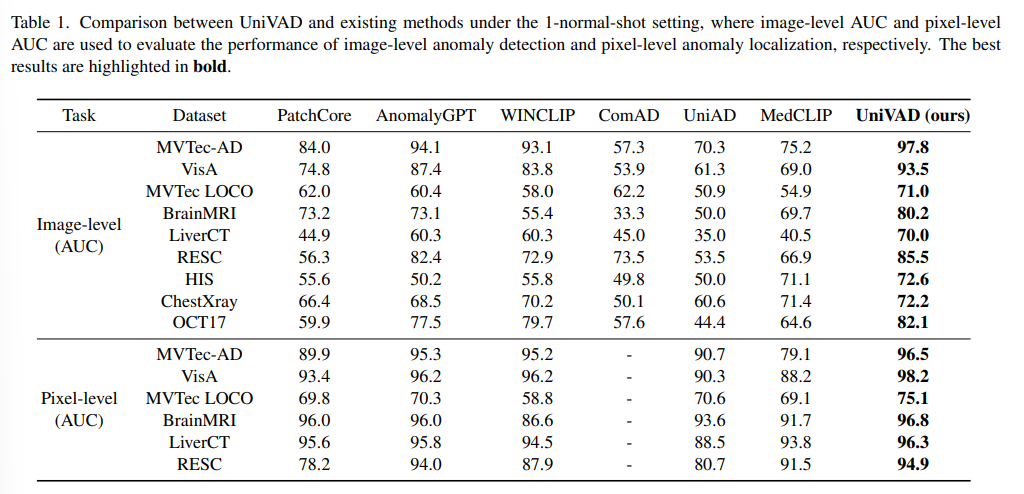
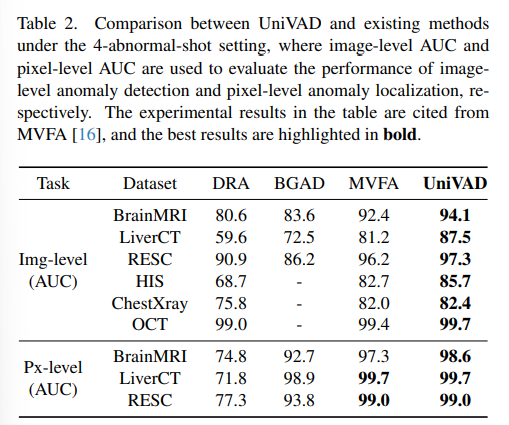
4. 실험 설정 및 결과
- 데이터셋: MVTec‑AD, VisA, MVTec LOCO, BrainMRI, 기타 산업·의료·교통 VAD 벤치마크 총 9종
- 소수샷 조건
- Normal‑shot: 참조 정상 샘플 1장
- Abnormal‑shot: 비정상 샘플 4장
- 평가지표: 이미지 수준 AUC, 픽셀 수준 AUC
Ablation Study
-
C3 단독 vs GECM 단독 vs CAPM 단독
- C3 추가 시 분할 오류 ↓, 전체 Image‑AUC +2.5%
- CAPM 구조 매칭만으로 False Alarm ↓, Pixel‑AUC +0.8%
- GECM 논리 매칭만으로 의미 수준 이상 검출 ↑, Image‑AUC +1.4%
-
전체 모듈 통합 시 가장 큰 성능 향상(벤치마크 평균 +6.2% Image‑AUC) 확인
5. 결론 및 향후 과제
결론
- UniVAD는 단일 모델로 다수 도메인·다수 객체의 이상을
- 훈련 없이, 소수샷만으로 검출하며
- 구성 요소 분할(C3), 패치 매칭(CAPM), 관계 그래프(GECM) 의 3단계로
- 구조적·논리적 이상을 통합 평가
향후 연구 과제
- 실시간성 개선: SAM·RAM 의존으로 인한 처리 지연 최소화
- 자동 파라미터 최적화: 클러스터 개수·패치 크기 동적 조정
- 확장된 멀티모달 통합: 영상+센서 데이터 결합 VAD
- 자기 지도 학습: 소수샷 참조 없이 완전 제로샷 성능 향상
질문
왜 지오메트릭 특성 벡터 생성할때 단순 컨캣하는 방향으로 하나?
