✅ 요약 :
- 문제 제기: 자기주목(self-attention)은 본질적으로 순열 불변이라, 순서가 핵심인 시계열에서 시간 정보 손실이 생길 수 있음. 저자들은 “Transformer가 LTSF(장기 시계열 예측)에 정말 효과적인가?”라는 질문을 제기합니다.
- 핵심 아이디어: 매우 단순한 직접 다단계(DMS) 선형 베이스라인 LTSF-Linear(및 변형 DLinear, NLinear)를 제시하여 기존 LTSF-Transformer들과 정면 비교.
LTSF-Linear의 기본식은 (시간축 선형층)입니다.
- 주요 결과: 9개 벤치마크에서 20–50%까지 Transformer SOTA(FEDformer)보다 더 나은 성능을 다수 경우에서 보임(다변량).- 분석/어블레이션: (i) 입력 순서 셔플 시 일부 Transformer의 성능 저하가 작아 순서에 둔감—시간 관계 학습 한계 시사(표 5), (ii) Attention→Linear로 단계적 단순화할수록 성능이 오히려 개선(표 4), (iii) look-back 길이 증가에 대해 Transformer는 흔히 개선이 없거나 악화.
- 의의: 선형 모델 제안이 목적이 아니라, LTSF-Transformer의 효과성에 의문을 제기하고 다각도로 원인을 분석한 점에 공헌이 있다고 결론
1. 서론
문제 정의 및 배경
LTSF는 긴 구간 미래를 예측해야 해 순서 정보가 결정적입니다. 그러나 self-attention은 순열 불변이라 포지셔널 인코딩을 써도 시간 정보가 일부 소실될 수 있습니다. NLP처럼 의미가 풍부한 도메인과 달리, 수치 시계열은 점간 의미 관계가 빈약해 순서 자체가 본질입니다.
기존 LTSF-Transformer들은 좋은 수치를 보였지만, 대조군(비-Transformer)으로 주로 반복 다단계(IMS)를 써서 오차 누적 불리함이 있었습니다. 이에 저자들은 직접 다단계(DMS) 전략으로 재검증합니다.
연구 목표 및 기여
(1) Transformer의 LTSF 효과성 재검증 문제 제기,
(2) 매우 단순한 선형 베이스라인(LTSF-Linear)을 제시해 9개 벤치마크와 광범위 비교,
(3) 여러 설계요소/가정을 체계적으로 분석·토의.
2. 관련 연구 정리
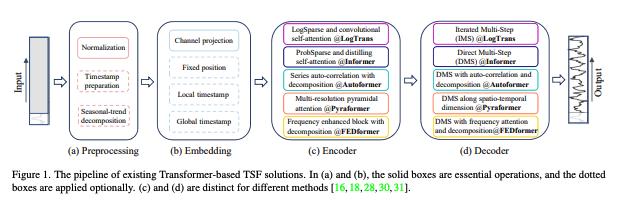
비교 대상 Transformer들: FEDformer, Autoformer, Informer, Pyraformer, LogTrans 등. 디코더는 느린 autoregressive의 한계를 피하려 DMS식을 다양하게 구현(주파수/자기상관/완전연결 등).
기존 연구의 전제: self-attention은 순열 불변이며, 시계열에서 시간 관계 학습은 포지셔널 인코딩 등에 강하게 의존. 이 특성 자체가 LTSF에 불리할 수 있다는 비판적 관점.
저자들의 문제 제기 배경: 기존 비교군이 IMS여서 DMS인 Transformer가 유리했을 가능성. → DMS 선형으로 공정 비교를 설계.
3. 제안 방법론
기본 LTSF-Linear: 각 변수 𝑖에 대해
(시간축 선형층, ). 변수 간 공간 상관은 모델링하지 않고 시간 축만 회귀.
DLinear: 입력을 이동평균으로 Trend와 Remainder(Seasonal)로 분해 후, 각 가지에 1층 선형을 적용, 두 출력을 합산. 뚜렷한 추세가 있을 때 유리.
NLinear: 테스트 분포가 학습 분포와 평균 이동(shift)을 보이는 경우, 입력에서 마지막 값을 빼고 선형층을 거친 뒤 다시 더해주는 단순 정규화로 분포 이동을 보정.
(부록 설명) 장점:
(i) 경로 길이 O(1) → 근접/장기 의존 모두 포착,
(ii) 매우 효율적(파라미터/메모리/추론속도),
(iii) 가중치 해석 가능, (iv) 튜닝 용이.
4. 실험 설정 및 결과
데이터셋/지표: 9개 다변량 벤치마크(ETTh1/2, ETTm1/2, Traffic, Electricity, Weather, ILI, Exchange-Rate), MSE/MAE 사용.
비교군: 위 Transformer 5종 + Repeat(마지막 값 반복) 단순 베이스라인. FEDformer는 Fourier 변형(f)이 더 좋아 그 버전을 채택.
주요 정량 결과
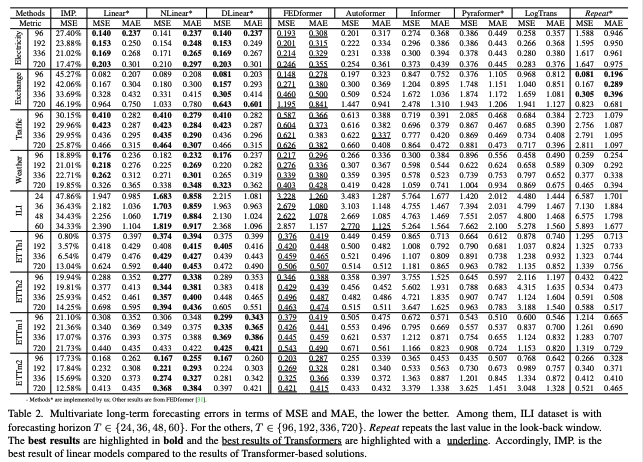 LTSF-Linear가 FEDformer 대비 20–50% 개선을 다수 케이스에서 달성(다변량). 데이터 특성에 따라 NLinear(분포 이동 보정), DLinear(추세 처리)가 강점.
LTSF-Linear가 FEDformer 대비 20–50% 개선을 다수 케이스에서 달성(다변량). 데이터 특성에 따라 NLinear(분포 이동 보정), DLinear(추세 처리)가 강점.
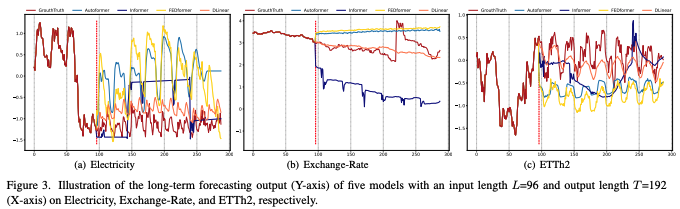
흥미로운 점: Repeat가 Exchange-Rate에서 Transformer 전부를 ~45% 앞서는 경우 존재(Transformer가 잡음에 과적합해 잘못된 추세를 예측).
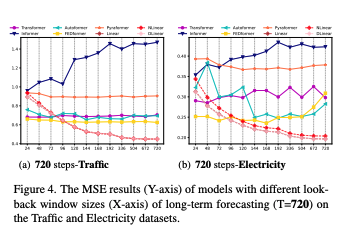
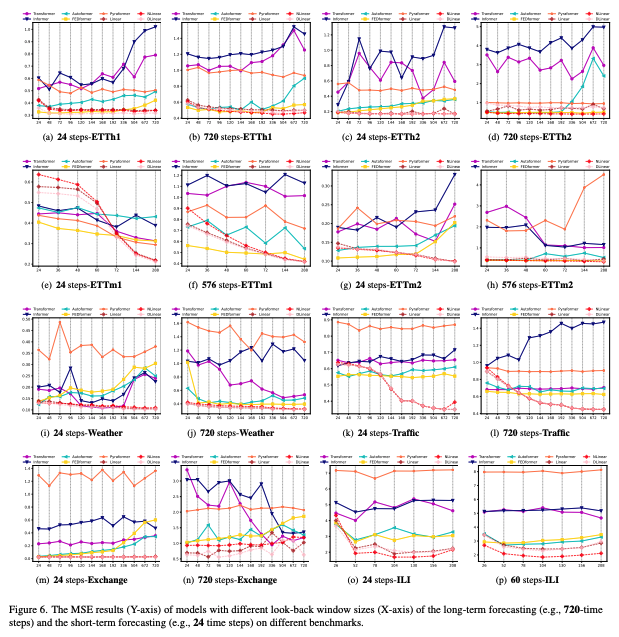
입력 길이 증가 시 Transformer는 정체/악화가 흔함. 반면 선형 계열은 일관된 개선(예: ETTm1, Traffic). 일부(Exchange-Rate)는 본질적 정보-대-잡음 비가 낮아 길이 증가 이점 미미.
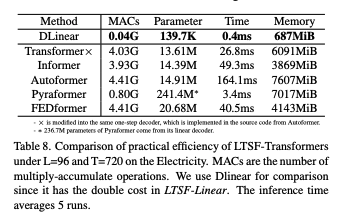
DLinear: 0.04G MACs, 0.4ms, 139.7K 파라미터, 687MiB. 대조: Autoformer/FEDformer 등은 수십 배 MACs/파라, 수십~수백 ms 추론. 또한 “메모리 이슈가 최신 GPU에 치명적 문제인지” 재고가 필요하다고 주장.
Ablation Study
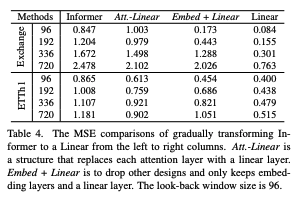
Informer → Linear 단계적 단순화(표 4):
Attention을 Linear로 대체, FFN 제거 등 간소화할수록 성능 향상 → Self-attention의 필요성 재고.
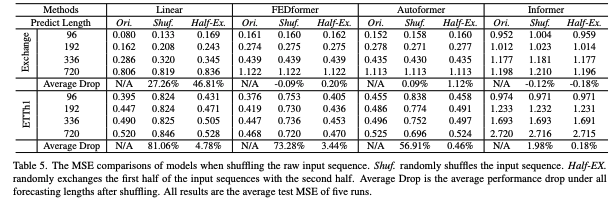
입력 순서 셔플(표 5):
Shuf./Half-Ex.으로 원시 입력 순서를 교란. 일부 Transformer는 성능 저하가 매우 작거나(때로는 미미/가벼운 호전) → 시간 순서에 둔감해 순서 정보 추적 약점을 시사. (예: Exchange에서 FEDformer/Autoformer는 변동이 거의 없음)
근접 vs 원거리 정보(표 3):
동일한 미래 720스텝을 근접(원래 L=96) vs 더 이전 L=96에서 예측하면 SOTA Transformer의 성능 하락이 작음 → 주로 인접 구간 신호만 포착하고 내재 주기/추세 일반화는 약할 수 있음을 시사. 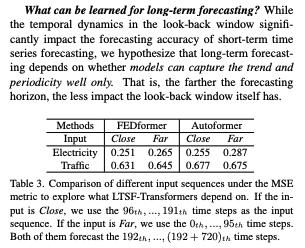
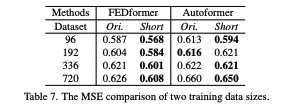
학습 데이터 규모(표 7):
축소 데이터로도 성능 저하가 크지 않음 → 성능 한계 원인이 데이터 양 부족만은 아님.
NLinear 동기(부록):
Train/Test 분포 이동(평균 이동) 시 마지막 값 보정이 큰 이득(ETTh1/2, ILI에서 유의 개선). Electricity처럼 이동 적은 데이터는 Linear/NLinear/DLinear 유사 성능.
5. 결론 및 향후 과제
결론
이 연구의 공헌은 “선형이 최고”를 주장하려는 것이 아니라, 현행 LTSF-Transformer의 효과성에 관해 본질적 질문을 던지고 다각적 실험으로 왜 그런 현상이 나오는지 보여준 데 있습니다. 향후 연구가 이 통찰을 바탕으로 나아가길 기대한다고 마무리합니다.
향후 연구 과제
벤치마크 재설계: 순서·주기·추세/잔차의 시간 구조를 더 강하게 요구하는 태스크/지표 구성. (현 벤치마크가 attention의 장점을 충분히 필요로 하지 않을 가능성)
시간 순서 보존 메커니즘 강화: 순열 불변을 보완하는 순서 민감 표현/아키텍처(예: 엄밀한 시계열 유도바이어스, 비정규 샘플링·결측 대응).
분포 이동 대응: NLinear식 간단 보정을 일반화한 테스트 시 적응/정규화 모듈 연구.
효율-해석성-성능 동시 달성: DLinear의 단순·해석가능 장점을 계승하면서, 변수 간 상관(공간 축)까지 최소비용으로 통합하는 방법 모색.
