
배경
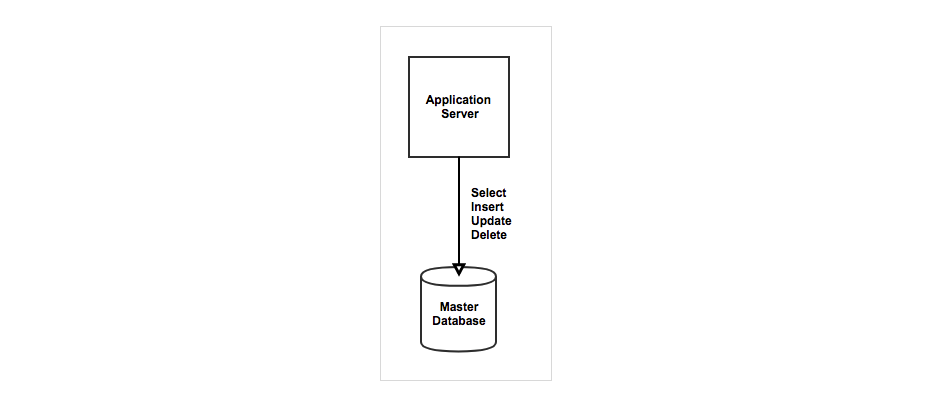
아주 단순한 시스템를 구성할 때는
하나의 서버와 하나의 데이터베이스를 구성하게 된다.
이러한 단순한 구조가 유지되고
사용자가 점차 많아질수록 데이터베이스가 많은 Query 문을 처리하기 힘들어진다.
이를 해결하기 위해 나온 방식이 Replication 이다.
개념
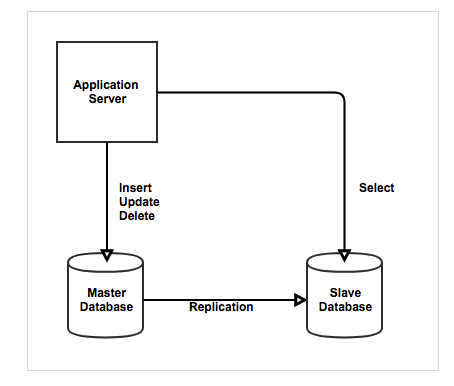
사용자로부터 받는 Query문의 대부분은
Select 문이다.
이를 초점으로 만든 해결방식으로
두 개 이상의 DBMS 시스템은 Master / Slave 로 나눠서 동일한 데이터를 가지는 방식이다.
Master 데이터베이스는 삽입, 수정, 삭제 쿼리 문을 받으며 변경사항을
Slave 데이터베이스에 실제 데이터를 복제하여 전달한다.
Slave 데이터베이스는 조회 문만 처리한다.
데이터를 복제하는 방법
로그 기반 복제(Binary Log)
Statement Based: SQL 문장을 복사하여 진행단, SQL 에 따라 결과가 달라지는 경우 문제가 생긴다.
Row Based: SQL 에 따라 변경된 Row 라인만 기록하는 방식단, 데이터가 많이 변경된 경우 데이터가 커질 수 밖에 없다.
Mixed: 기본적으로 Statement Based로 진행하면서 필요에 따라 Row Based를 사용한다.
장점
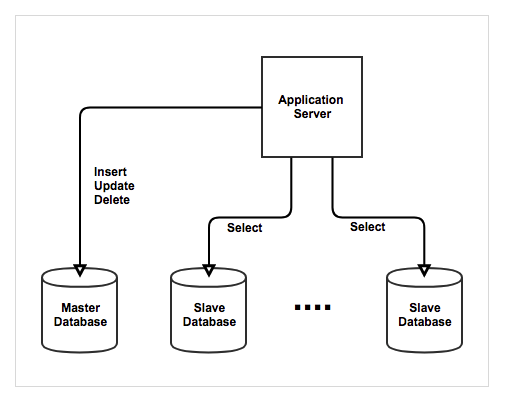
Query 문의 대부분은
select가 차지하고 있다.
이부분의 부하를 낮추기 위해 많은 Slave 데이터베이스를 생성하게 된다면
조회 성능 향상 효과를 얻을 수 있다.
또한 Master 데이터베이스 영향없이 로그를 분석할 수 있다.
원본 데이터베이스에 문제가 발생하더라도 복제본을 사용하여 서비스를 지속할 수 있다.
단점
복제 설정과 유지 관리는 복잡할 수 있으며, 적절한 전문 지식이 필요하다.
원본 데이터베이스와 복제본 사이에는
일관성을 유지하기 위해 데이터를 동기화하는 데 시간이 걸릴 수 있다.
이로 인해 지연 시간이 발생하며, 때로는 데이터 불일치 문제가 발생할 수 있다.
추가적인 하드웨어와 저장 공간이 필요하므로 비용이 증가한다.
모든 쓰기 작업은 모든 복제본에 적용되어야 하므로 쓰기 작업의 부하가 증가할 수 있다.
