
파티셔닝의 배경
서비스의 크기가 점점 커지고 DB에 저장하는 데이터의 규모 또한 대용량화 되면서,
기존에 사용하는 DB 시스템의 용량(storage)의
한계와 성능(performance)의 저하 를 가져오게 되었다.
파티셔닝의 개념
큰 table이나 index를, 관리하기 쉬운 partition이라는 작은 단위로
물리적으로 분할하는 것을 의미한다.
물리적인 데이터 분할이 있더라도, DB에 접근하는 application의 입장에서는 이를 인식하지 못한다.
'파티셔닝(Partitioning)'기법을 통해 소프트웨어적으로 데이터베이스를 분산 처리하여
성능이 저하되는 것을 방지하고 관리를 보다 수월하게 할 수 있게 되었다.
파티셔닝의 목적
성능
- 특정 DML과 Query의 성능을 향상시킨다.
- 대용량 Data WRITE 환경에서 효율적이다.
- Full Scan에서 데이터 Access의 범위를 줄여 성능 향상을 가져온다.
- 많은 INSERT가 있는 OLTP 시스템에서 INSERT 작업을 작은 단위인 partition들로 분산시켜 경합을 줄인다.

가용성
- 물리적인 파티셔닝으로 인해 전체 데이터의 훼손 가능성이 줄고 데이터 가용성이 향상된다.
- 각 분할 영역(partition별로)을 독립적으로 백업하고 복구할 수 있다.
- table의 partition 단위로 Disk I/O을 분산하여
- 경합을 줄이기 때문에 UPDATE 성능을 향상시킨다.
관리의 용이성
큰 Table을 제거하여 관리를 쉽게 해준다.
파티셔닝의 장점
관리적 측면: partition 단위 백업, 추가, 삭제, 변경
- 전체 데이터를 손실할 가능성이 줄어들어 데이터 가용성이 향상된다.
- partition별로 백업 및 복구가 가능하다.
- partition 단위로 I/O 분산이 가능하여 UPDATE 성능을 향상시킨다.
성능적 측면: partition 단위 조회 및 DML수행
- 데이터 전체 검색 시 필요한 부분만 탐색해 성능이 증가한다.
- 즉, Full Scan에서 데이터 Access의 범위를 줄여 성능 향상을 가져온다.
- 필요한 데이터만 빠르게 조회할 수 있기 때문에 쿼리 자체가 가볍다.
파티셔닝의 단점
- table간 JOIN 에 대한 비용이 증가한다.
- table과 index를 별도로 파티셔닝할 수 없다.
- table과 index를 같이 파티셔닝해야 한다.
파티셔닝의 종류
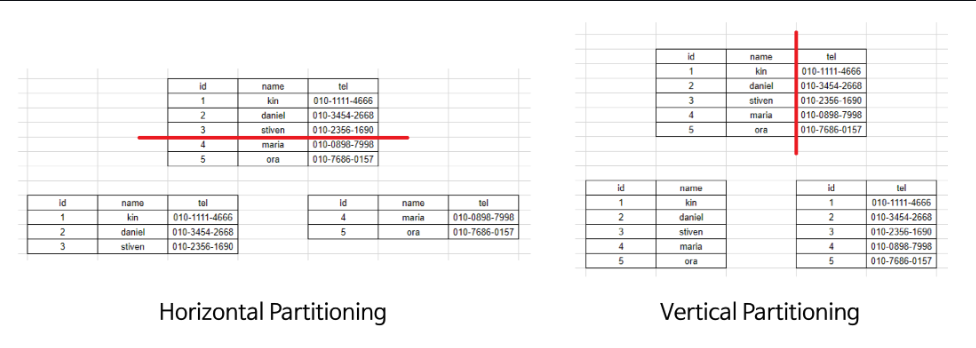
수평 파티셔닝(샤딩) 과 수직 파티셔닝이 있다.
일반적으로 분산 저장 기술에서 파티셔닝은 수평 분할을 의미한다.
파티셔닝의 분할 기준
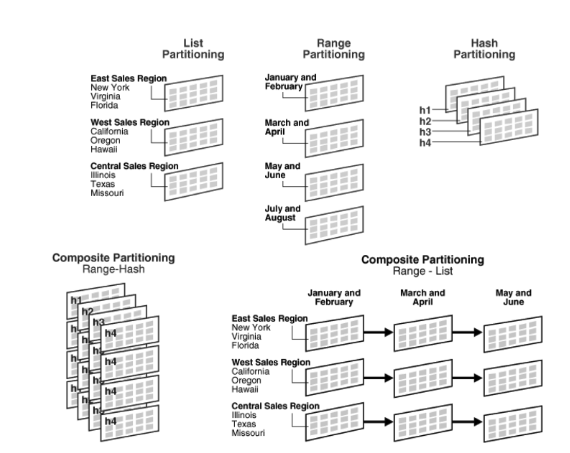
범위 분할
특정 열의 범위를 기준으로 데이터를 분할하는 방식이다.
예를 들어, 날짜 열이 있을 때, 각 파티션은 특정 날짜 범위의 데이터를 담는다.
2020년 데이터는 하나의 파티션, 2021년 데이터는 다른 파티션에 속할 수 있다.
목록 분할
열의 명시적인 값 목록을 기준으로 데이터를 분할하는 방식이다.
국가 코드를 기준으로 데이터를 분할하는 경우, 각 국가 코드는 특정 파티션에 매핑될 수 있다.
해시 분할
해시 함수를 사용하여 데이터를 분할하는 방식이다.
해시 함수의 입력으로 특정 열의 값을 사용하고, 함수의 출력은 파티션 번호가 된다.예를 들어, 4개의 파티션으로 분할하는 경우 해시 함수는 0-3의 정수를 돌려준다.
이 방식은 데이터를 균등하게 분산시키는 데 유용하다.
합성 분할
두 가지 이상의 파티셔닝 방식을 결합하는 방식이다.
범위 파티셔닝과 리스트 파티셔닝을 결합하여 사용할 수 있다.


글이 잘 정리되어 있네요. 감사합니다.