
7장 MySQL
7.1 데이터베이스란?
7.2 MySQL 설치하기
7.3 워크벤치 설치하기
7.4 데이터베이스 및 테이블 생성하기
7.4.1 데이터베이스 생성하기
nodejs 라는 이름을 가진 데이터 베이스를 생성해보자.
아래 문장은 utf8을 기본 문자로 갖는 nodejs 이름의 데이터 베이스를 생성하는 것이다. MySQL에서는 데이터베이스와 스키마는 같은 개념이라서 아래 두 구문은 같은 말이다.
mysql> CREATE SCHEMA nodejs DEFAULT CHARACTER SET utf8;
또는
mysql> CREATE DATABASE nodejs DEFAULT CHARACTER SET utf8;책에는 'nodejs' 라고 작은 따옴표가 있지만, 버전의 차이로 작은 따옴표를 빼야한다.
우리가 만든 데이터베이스를 확인해보고 싶다면 아래 문장을 입력하면 현재 만들어져있는 데이터베이스의 목록을 확인할 수 있다.
mysql> show databases;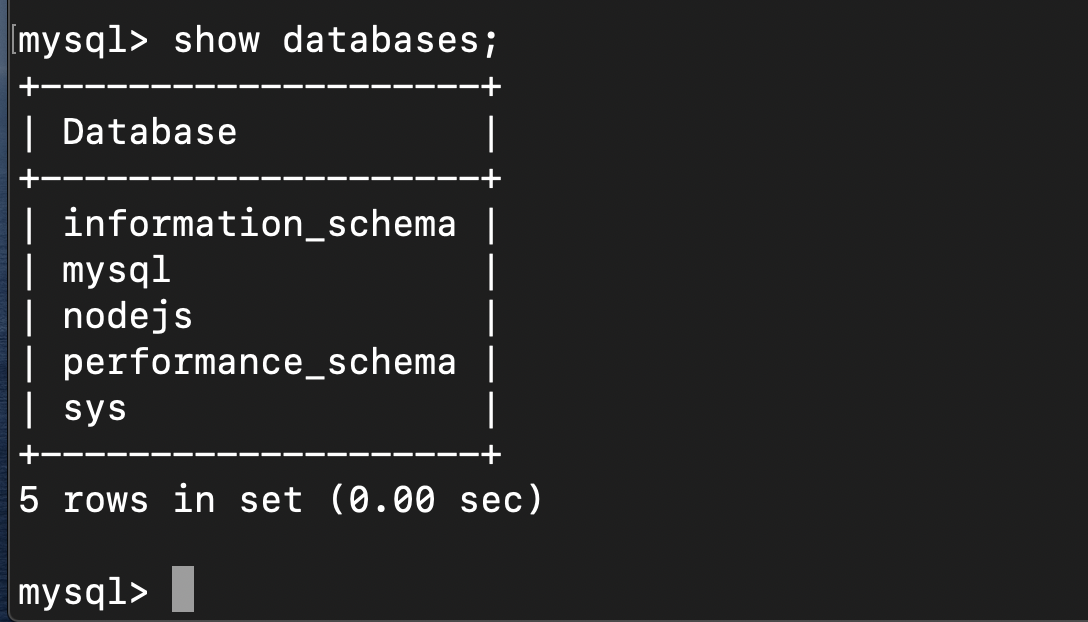
조금 전에 생성했던 nodejs를 사용하기 위해 데이터베이스로 바꿔보자.
mysql> use nodejs;
7.4.2 테이블 생성하기
테이블이란 데이커가 들어갈 수 있는 틀을 뜻하며 테이블에 맞는 데이터만 들어갈 수 있다.
테이블을 생성하는 명령문은
mysql> CREATE TABLE [데이터베이스명].[테이블명]책에 있는 예시문을 같이 보면
mysql> CREATE TABLE nodejs.users (
-> id INT NOT NULL AUTO_INCREMENT, //
-> name VARCHAR(20) NOT NULL,
-> age INT UNSIGNED NOT NULL,
-> married TINYINT NOT NULL,
-> comment TEXT NULL,
-> created_at DATETIME NOT NULL DEFAULT now(),
-> PRIMARY KEY(id), //고유 식별자로 사용
-> UNIQUE INDEX name_UNIQUE (name ASC))
-> COMMENT = '사용자 정보'
-> DEFAULT CHARACTER SET = utf8
-> ENGINE = InnoDB;id, name, age, married 를 갖는 칼럼을 만들었다.
칼럼의 자료형
- INT : 정수
- FLOAT / DOUBLE : 소수
- VARCHAR(자릿수) : 예를들어 VARCHAR(27) 이라면 0~27의 길이인 문자열을 넣을 수 있음
- CHAR(자릿수) : 고정 길이 문자열로 CHAR(27)이라면 반드시 길이가 27인 문자열만 넣어야 함
- TEXT : 긴 글을 저장할 때 사용
- TINYINT : -128 ~ 127 까지의 정수를 저장할 때 사용. 1 과 0 만 저장한다면 boolean 과 같은 역할을 할 수 있음
- DATETIME : 날짜와 시간에 대한 정보
- DATE : 날짜
- TIME : 시간
자료형 뒤 옵션
- NULL / NOT NULL : 빈칸을 허용할지 여부 설정
- AUTO_INCREMENT : 숫자를 자동으로 올린다는 의미
- UNSIGNED : 숫자 자료형에 적용되는 옵션으로 음수를 무시할 때 사용 (FLOAT, DOUBLE 에서는 UN 적용 불가능)
- ZEROFILL : 숫자의 자릿수가 고정되어 있을 때 사용
ex). INT(4) 일 때, 숫자 1을 넣었다면 0001 로 저장. - now() : 현재 시각 (= CURRENT_TIMESTAMP)
- PRIMARY KEY : 해당 컬럼이 기본키인 경우. 기본키란 로우를 대표하는 고유한 값
- FOREIGN KEY : 외래키라고 부르며 다른 테이블의 기본키를 저장하는 컬럼.
-> CONSTRAINT [제약조건명] FOREIGN KEY [컬럼명] REFERENCES [참고하는 컬럼명] - UNIQUE INDEX : 해당값이 고유해야한다면 설정.
- ON UPDATE CASCADE / ON DELETE CASCADE : 수정되거나 삭제되면 그것ㄷ과 연결된 정보도 같이 수정하거나 삭제.
** PRIMARY KEY, UNIQUE INDEX의 경우 디비가 별도로 컬럼을 관리하므로 조회시 속도가 빠르다.
테이블 자체에 대한 설정
- COMMENT : 테이블에 대한 보충 설명. 이 테이블이 무슨 역할을 하는 지 기재.
- DEFAULT CHARACTER SET utf8 : 이 설정이 없다면 한글 입력이 안된다.
- ENGINE : 여러가지가 있지만, MyISAM 과 InnoDB가 제일 많이 사용된다.
만들어진 테이블 확인하는 명령어
mysql> DESC [테이블명];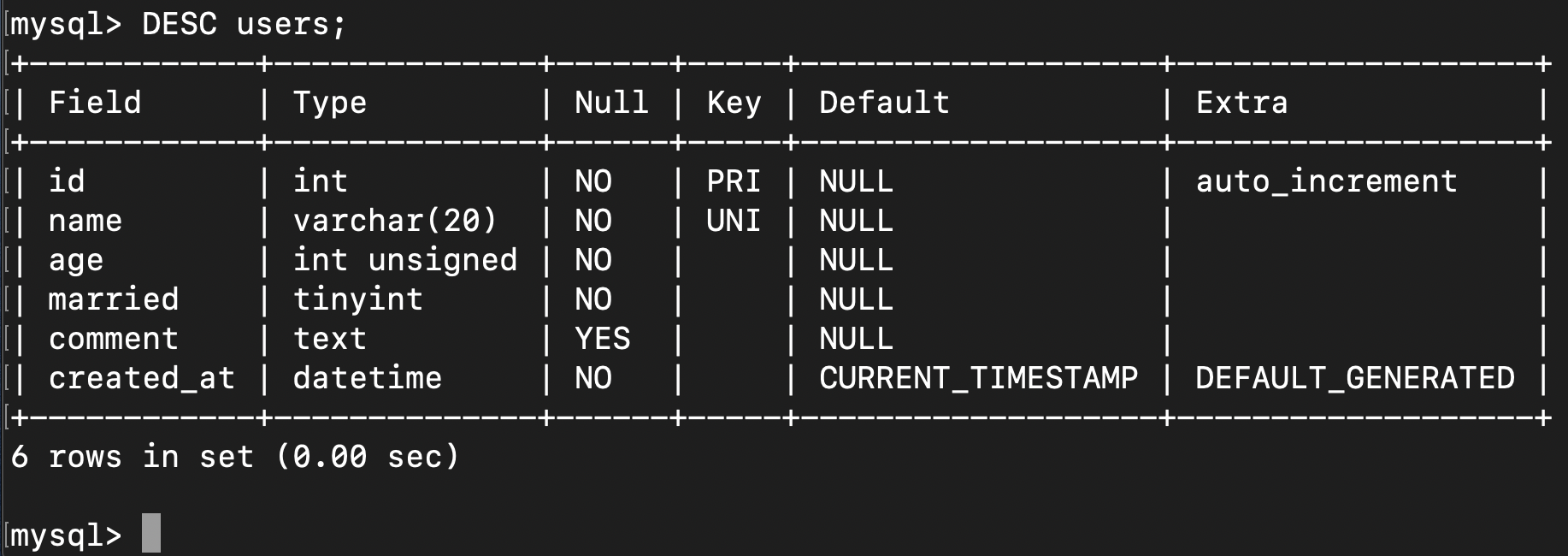
현재 데이터베이스에 있는 테이블들을 확인하는 명령어
mysql> SHOW TABLES;테이블 삭제 명령어
mysql> DROP TABLE [테이블명];7.5 CRUD 작업하기
7.5.1 CREATE (생성)
:: 데이터를 생성해서 데이터베이스에 넣는 작업
mysql> INSERT INTO [테이블명] ([컬럼1], [컬럼2], ...) VALUES ([값1], [값2], ...)
위의 사진에 명령어를 해석해보면
nodejs 데이터베이스에 들어있는 users 테이블에 name컬럼 값을 'zero', age 컬럼 값을 24, married 컬럼 값을 0, comment 컬럼 값을 '자기소개1'을 갖는 로우를 생성해서 넣겠다는 의미이다.
7.5.2 READ (조회)
:: 데이터베이스에 있는 데이터를 조회하는 작업
mysql> SELECT * FROM [데이터베이스명].[테이블명];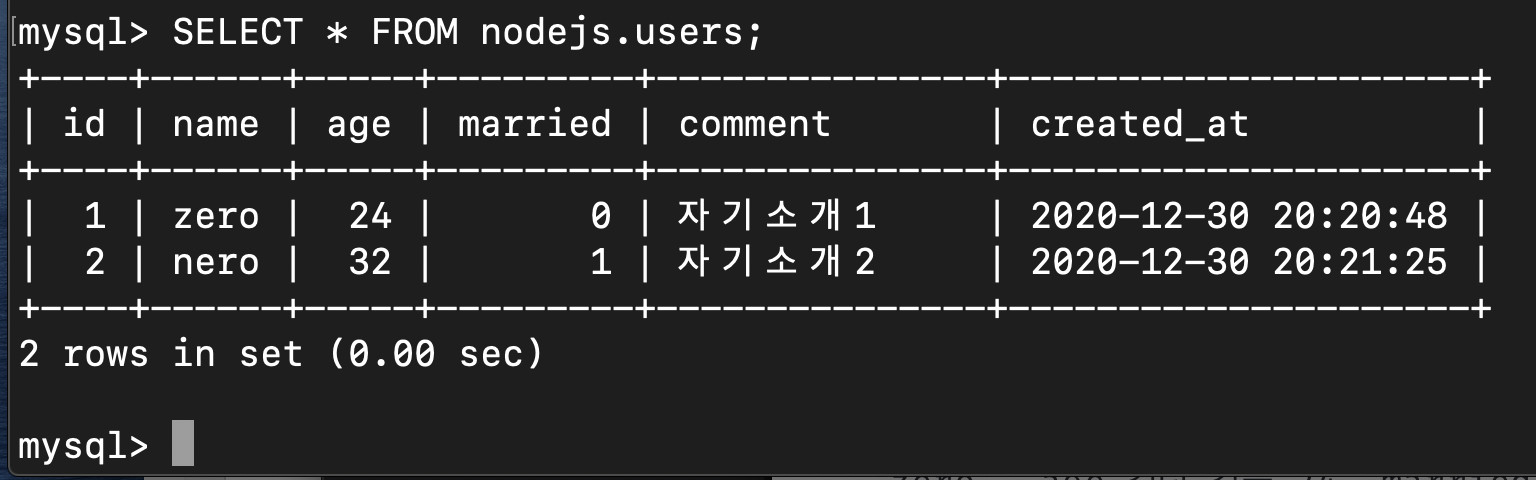
조금전 추가 했던 2개의 로우를 확인할 수 있다.
특정 컬럼만 조회하기
nodejs.users 테이블에서 이름과 결혼 여부만 확인하고 싶다면
SELECT [조회할 컬럼명] FROM [테이블명]; 으로 확인할 수 있다.
mysql> SELECT name, married FROM nodejs.users;WHERE 절을 사용하면 특정 조건을 가진 데이터만 조회할 수 있다.
AND 로 여러 조건을 묶어줄 수도 있으며,
OR 로 조건들 중 어느 하나라도 만족하는 데이터를 찾을 수 있다.
mysql> SELECT name, age
-> FROM nodejs.users
-> WHERE married = 1 AND(OR) age > 30;해석해보자면 name, age 컬럼을 nodejs.users 테이블에서 찾을건데 조건이 하나 있다. married=1 이고(AND) age > 30 인 로우를 찾습니다. 만약 OR가 들어갔다면, married=1 이거나(OR) age > 30 인 로우를 찾아준다.
ORDER BY [컬럼명][ASC/DESC] 키워드를 사용하면 정렬이 가능하다.
DESC는 내림차순, ASC는 오름차순으로 정렬한다.
LIMIT [숫자] 키워드를 사용하면 조회할 로우 개수를 설정할 수 있다.
OFFSET [건너뛸 숫자] 키워드를 사용하면 몇 개의 로우를 건너뛸지 설정할 수 있다.
mysql> SELECT id, name
-> FROM nodejs.users
-> ORDER BY age DESC LIMIT 1 OFFSET 1;즉, 위의 명령문은 nodejs.users 테이블에서 id, name 컬럼만 조회하는데 나이순으로 내림차순 정렬을 하고 하나의 로우를 건너뛰고 하나의 로우만 출력해라. 라는 의미이다.
7.5.3 UPDATE (수정)
:: 데이터베이스에 있는 데이터를 수정하는 작업
UPDATE [테이블명] SET [컬럼명=바꿀 값] WHERE [조건] 명령어로 컬럼을 수정할 수 있다.
mysql> UPDATE nodejs.users
-> SET comment = '바꿀 내용'
-> WHERE id = 2;nodejs.users 테이블에서 id가 2인 로우의 comment컬럼 내용을 '바꿀 내용'으로 수정한다는 말이다.
7.5.4 DELETE (삭제)
:: 데이터베이스에 있는 데이터를 삭제하는 작업
Delete from [테이블명] WHERE [조건] 명령문으로 삭제가능하다.
mysql> DELETE FROM nodejs.users
-> WEHRE id = 2;nodejs.users 테이블에서 id가 2인 로우를 삭제한다는 뜻이다.
7.6 시퀄라이즈 사용하기
시퀄라이즈는 ORM(Object-relational Mapping)으로 분류된다.
ORM은 자바스크립트 객체와 데이터베이스의 릴레이션을 매핑해주는 도구로 자바스크립트 구문을 SQL로 바꿔주기 때문에 사용한다.
7.6.1 MySQL 연결하기
7.6.2 모델 정의하기
시퀄라이즈는 시퀄라이즈의 모델과 MySQL의 테이블을 연결해주는 역할을 하는데 MySQL의 테이블은 시퀄라이즈의 모델과 대응된다. 시퀄라이즈의 모델 이름은 기본적으로 단수형으로, 테이블 이름은 복수형으로 사용한다.
시퀄라이즈의 자료형은 MySQL의 자료형과는 조금 다르다.
VARCHAR(100) ---> STRING(100),
INT ------------> INTEGER,
TINYINT --------> BOOLEAN,
DATETIME -------> DATE,
INT UNSIGNED ---> INTEGER.UNSIGNED,
NOT NULL -------> allowNull: false,
UNIQUE ---------> unique: true,
DEFAULT now() --> defaultValue: Sequelize.NOW
7.6.3 관계 정의하기
테이블과 테이블간의 관계를 정의할 수 있는데, 1:1, 1:N, N:M 으로 정의할 수 있다.
7.6.3.1 1:N
시퀄라이즈에서는 1:N의 관계를 hasMany라는 메서드로 표현한다. 이 메서드를 이용하면 users 테이블의 로우 하나를 불러올 때 연결된 comments 테이블의 로우들도 같이 불러올 수 있다. 반대로 belongsTo 메서드를 사용하면 comments 테이블의 로우를 불러올 때 연결된 users테이블의 로우를 가져온다. 즉, 다른 모델의 정보가 들어가는 테이블에 사용한다.
7.6.3.2 1:1
1:1관계에서는 hasOne메서드를 사용한다. 여기서도 반대의 경우 belongsTo 메서드를 사용하는데, 반대로되면 안된다.
7.6.3.3 N:M
N:M 관계를 표현하기 위해 belongsToMany 메서드를 사용한다. 이 관계에서는 양쪽 보델에 모두 belongToMany 메서드를 사용한다.
7.6.4 쿼리 알아보기
시퀄라이즈로 CRUD 작업을 하기위해서는 시퀄라이즈 쿼리를 먼저 알아야한다. SQL문을 자바스크립트로 생성하는 것이라 시퀄라이즈만의 방식이 있다.
- 로우를 생성하는 쿼리문
// SQL문
INSERT INTO nodejs.users (name, age, married, comment) VALUES ('zero', 24, 0, '자기소개1');//시퀄라이즈문
const { User } = require('../models');
User.create({
name: 'zero',
age: 24,
married: false,
comment: '자기소개1',
});- 테이블의 모든 데이터를 조회
// SQL문
SELECT * FROM [테이블명];//시퀄라이즈문
User.findAll({});- 테이블의 하나의 데이터만 가져올 때
// SQL문
SELECT * FROM [테이블명] LIMIT 1;//시퀄라이즈문
User.findONE({});- 원하는 컬럼만 가져오기
// SQL문
SELECT name, married FROM [테이블명];//시퀄라이즈문
User.findAll({
attributes: ['name', 'married']
});- where 옵션 사용
// SQL문
SELECT name, age
FROM [테이블명]
WHERE married = 1 AND age > 30;//시퀄라이즈문
const { Op } = require('sequelize');
const { User } = require('../models');
User.findAll({
attributes: ['name', 'age'],
where: {
married: true,
age: { [Op.gt]: 30 },
},
});=> 시퀄라이즈는 Op.gt 같은 ES2015 문법의 특수한 연산자들을 사용하게 된다.
- 시퀄라이즈를 이용한 정렬
// SQL문
SELECT id, name
FROM [테이블명]
ORDER BY age DESC;//시퀄라이즈문
User.findAll({
attributes: ['id', 'name'],
order: [['age', 'DESC']],
limit: 1,
offset:1,
});=> order 옵션으로 정렬 가능하며, limit 옵션으로 로우 개수를 설정할 수 있다. OFFSET 도 offset 속성으로 구현 가능하다.
- 로우 수정 쿼리
// SQL문
UPDATE [테이블명]
SET comment = '바꿀 내용'
WHERE id = 2;//시퀄라이즈문
User.update({
comment: '바꿀 내용',
}, {
where: { id: 2 },
});=> 첫 번째 인수는 수정할 내용, 두 번째 인수는 어떤 로우를 수정할지에 대한 조건이다.
- 로우 삭제 쿼리
// SQL문
DELETE FROM [테이블명]
WHERE id = 2;//시퀄라이즈문
User.destory({
where: { id: 2 },
});7.6.4.1 관계 쿼리
관계 쿼리란 MySQL의 JOIN 기능으로 시퀄라이즈의 include 속성을 사용한다.
findOne이나 findAll 메서드를 호출할 때 프로미스의 결과로 모델을 반환한다(findAll은 모두 찾는 것이므로 모델의 배열을 반환한다).
const user = await User.findOne({
include: [{
model: Comment,
}]
});
console.log(user.Comments); //사용자 댓글특정 사용자를 가져오면서 그 사람의 댓글까지 모두 가져오는 시퀄라이즈문이다. 어떤 모델과 관계가 있는지 include 배열에 넣어주면 된다. 이때, 배열인 이유는 다양한 모델과 관계가 있을 수 있기 때문이다.
관계를 설정했다면 getCOmments(조회) 이외에도 setComments(수정), addComment(하나 생성), addComments(여러개 생성), removeComments(삭제) 메서드를 지원한다.
//관계 설정시 as로 등록
db.User.hasMany(db.Comment, {
foreignKey: 'commenter',
sourceKey: 'id',
as: 'Answers'
});
//쿼리할 때
const user = await User.findOne({});
const comments = await user.getAnswers();
console.log(comments); //사용자 댓글** include나 관계 쿼리 메서드에서도 where이나 attributes 같은 옵션을 사용할 수 있다.
7.6.4.2 SQL 쿼리하기
만약 시퀄라이즈의 쿼리를 사용하기 싫거나 잘 모르겠다면 직접 SQL문을 통해 쿼리할 수 있다.
const [result, metadata] = await sequelize.query('SELECT * from comments');
console.log(result);