1. 대회설명
Overview
- 소개
이번 대회는 computer vision domain에서 가장 중요한 태스크인 이미지 분류 대회이다. 보험보상과 관련된 이미지들이 주어지고 이것을 17개의 클래스로 분류하는 모델을 만든다. - input : 1570개의 이미지
- output : 3140개 이미지의 클래스
Timeline
- 2024년 7월 29일 : 대회시작 각자 데이터 EDA
- 2024년 7월 30일 ~ 8월 2일 : 온라인 강의, 데이터 Augmentation을 이용한 모델링, Baseline code 학습
- 2024년 8월 5일 : Swin Tranform, Convnext v2 적용
- 2024년 8월 6일 : OCR, Augrapy 코드 공유 적용
- 2024년 8월 7일 : 데이터 오프라인 증강, Test data의 Denoising 적용
- 2024년 8월 8일 : 각자의 모델 Hyper parameter tuning, LM3 적용
- 2024년 8월 9일 ~ 11일 : 각자의 모델 학습시키면서 리더보드 올리기
Model descrition
- EfficientNet_b4
- SWIN(Shifted Window)
- ConvNeXt
- OCR
2. 목표와 결과
학습데이터를 테스트데이터와 비슷하게 만들자
- 학습데이터들은 깔끔하고 정돈된 형태로 스캔된 형식들이였는 데, 테스트데이터들은 회전, 플립, 노이즈, 믹스 등등 많은 형태로 변형되어있었다.
- 결과
- Augmentation으로 데이터증강하여 3개의 모델 실험 (flip, noise, rotation)
-> 과적합의 문제, 0.91이상으로는 잘 오르지 않음
-> 두개의 모델들을 앙상블한 결과도 0.92정도
- Augmentation으로 데이터증강하여 3개의 모델 실험 (flip, noise, rotation)
Swin t의 하이퍼파라미터를 튜닝하였다.
- swin t 모델은 생각모다 수렴도 잘 되지 않고 어느 순간 리더보드에 올린 결과값들도 0.91후반으로 오르지 않앟다.
- wandb의 sweep을 사용하여 하이퍼파라미터를 모니터링하였고, 그중 ㅣloss 값이 작고 f1값이 크면서도 epoch을 길게 가져가는 하이퍼파라미터를 선택하였다.
- 결과
- 0.92후반대까지 오를 수 있었다.
wandb 실험결과
- 0.92후반대까지 오를 수 있었다.
test 데이터의 Denoising
- test이미지들 중에 문서이미지들의 회전을 바르게 돌려놓기위해 노력했다.
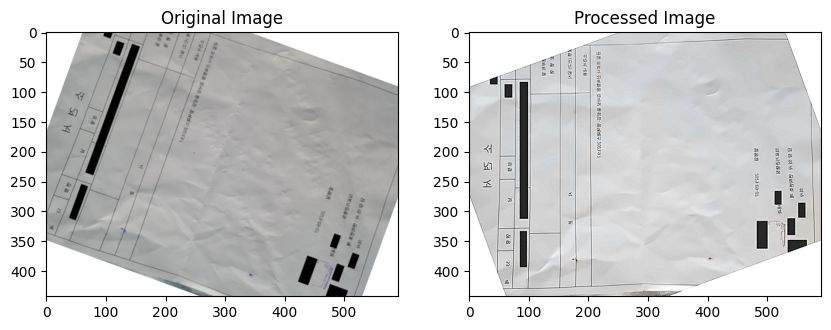
- 결과
-- 0.0011정도의 값이 올랐다.
- 점수가 좀처럼 오르지 않았을 때 값이 오른 것이여서 이것을 좀더 적극적으로 이용해야 겠다고 생각했다.
test Denosing에 맞는 학습데이터 다시 구축
- test이미지들이 Denoising 되면서 그에 맞는 학습데이터를 만들면 좋겠다고 생각했다. 그래서 일부러 원래의 학습데이터에 노이즈와 회전을 주어서 오프라인으로 25,000개정도를 저장하고, 이 이미지들을 다시 Denoising하는 과정을 거쳐 test 이미지와 비슷하게 만들도록 노력했다.
- 결과
-- 이것때문인건지 많은 데이터를 학습한 덕분인지는 알수 없으나, ocr을 적용하기 전 가장 높은 점수인 0.9386을 얻을 수 있었다. (swin + conv)
OCR을 사용하여 데이터를 Postprocessing하였다.
- test데이터와 가장 비슷하게 만든 학습데이터 중 헷갈리는 몇몇 클래스의 문서에서 Paddleocr을 사용하여 단어들을 추출하였다.
- 단어들을 정제하여 각 클래스 별 단어사전을 만들었다.
- test데이터에서도 단어를 추출한 후, 단어사전을 이용하여 클래스를 재분류하였다.
- 결과
- 40여개의 이미지가 클래스를 변환했고, f1값은 0.013정도 오르게 되었다.
3. 새로운 시도
파일을 나눠서 저장
- 전에는 하나의 ipynb파일에 여러모델들을 만들고 저장하였는데, 이번부터는 모델마다, 실험내용마다 모두 다른 파일에 만들어서 실수를 줄이도록 노력했다.
- 결과 : 확실히 실수가 줄었고, 관리가 오히려 쉬웠다. 그러나 파일명의 체계성이 없어서 이 부분은 개선이 필요하다.
wandb의 sweep 사용
- sweep으로 하이퍼파라미터를 모니터링해보았다. sweep은 어느정도 정보가 모이면 하이퍼파라미터의 중요도를 알아서 보여준다. 그래서 어떻게 하이퍼파라미터를 조정해야하는지에 대한 감을 알려주었고, 이로 인해 모델에 대한 이해도도 같이 높일 수 있었다.
nohup으로 py 파일 돌리기
- nohup을 사용하여 백그라운드로 py파일을 돌려보았다. 이것은 log파일을 만들어서 모니터링도 쉽게 해주었고, 컴퓨터를 켜고 끄는 것에 대한 자유도 주어 굉장히 편하게 할 수 있었다. 다만 메모리 관리를 좀더 열심히 해주어야 한다. 아니면 cuda에러가 나서 잘 하던 것들이 날라갈 수 있다.
팀장과 발표를 하였다!
- 발표는 떨렸지만 재밌었다. 팀장으로써는 아직 개선해야할 점들이 보인다.
4. 프로젝트 후기
- 데이터증강할 때 10만개정도로 더더 많이 해볼꺼 하는 아쉬움이 남는다.
- 팀별로 운영되어지는 대회의 경우, 가장 필요한 것이 팀안에서의 체계성인것 같다. 정보를 공유하고 모델링을 하는 과정에서 서로서로 겹쳐지는 부분을 최소화하기 위해 이와 같은 것이 필요한 데, 우리는 아침에 모여 열띤 토론을 하고 토론 내용도 매일 슬랙에 올려놓았지만, 서로 무엇을 하는 지에 대한 정말 구체적인 정보가 없기 때문에 서로에 대한 피드백을 정확히 할수 었었던 것 같다.
- 나의 파일관리에 대한 체계성도 아직 부족함을 느꼈다. 이름짓기 너무 어렵다.
- 여러모델을 많이 다뤄보았다. 확실히 수업만 듣는 것보다 이렇게 수업듣고 바로 대회를 하니, 많은 부분들이 체화되는 것을 느꼈다.
- postprocessing을 할 때, '어 모델링 대회인데 이런걸 해도 되나' 하는 생각을 했는 데, 결국 이것으로 인해 점수를 잘 받았게 되었고 현업에서도 이런 식의 일이 진행된다는 것을 듣고 생각을 바꾸게 되었다.
5. 다음 대회에서 할 일
팀 단위 체계성
- 현재 진행하고 있는 모델링이나 데이터전처리에 대한 구체적인 정보를 기재하는 구글 엑셀시트를 만들어 서로 공유하며 진행해보려한다.
개인의 체계성
- 파일 분리까지는 잘했으나, 파일명에서 아직 부족함을 느꼈다. 파일명의 체계를 구성하고 개인 엑셀파일도 만들어서 기재하는 방향으로 진행하려한다.
모델 선정 기준잡기
- 지금까지는 막연히 좋을 것이라고 생각한 여러모델을 모두 돌려보는 방향으로 진행하였는데, 다음에는 모델에 대한 서치를 충분히 한 후, 그 중 학습데이터에 맞는 모델을 선정하는 것에 대해 공부하고 적용해보고 싶다.
이번에도 4위라는 아주 만족스러운 결과를 낼수 있었다. (5위안에만 들자는 것이 나의 목표다.) 너무 재미있었다.

나는 무엇이 될것인가!!