Stack (스택)
- 들어온 시간 순으로 데이터를 쌓아갈 때, 가장 위 (가장 최근에 삽입)에 있는 데이터를 삭제하거나, 거기에 이어서 새로운 데이터를 삽입할 수 있도록 하는 추상 자료형.
- LIFO (Last-In First-Out)
스택 구성도
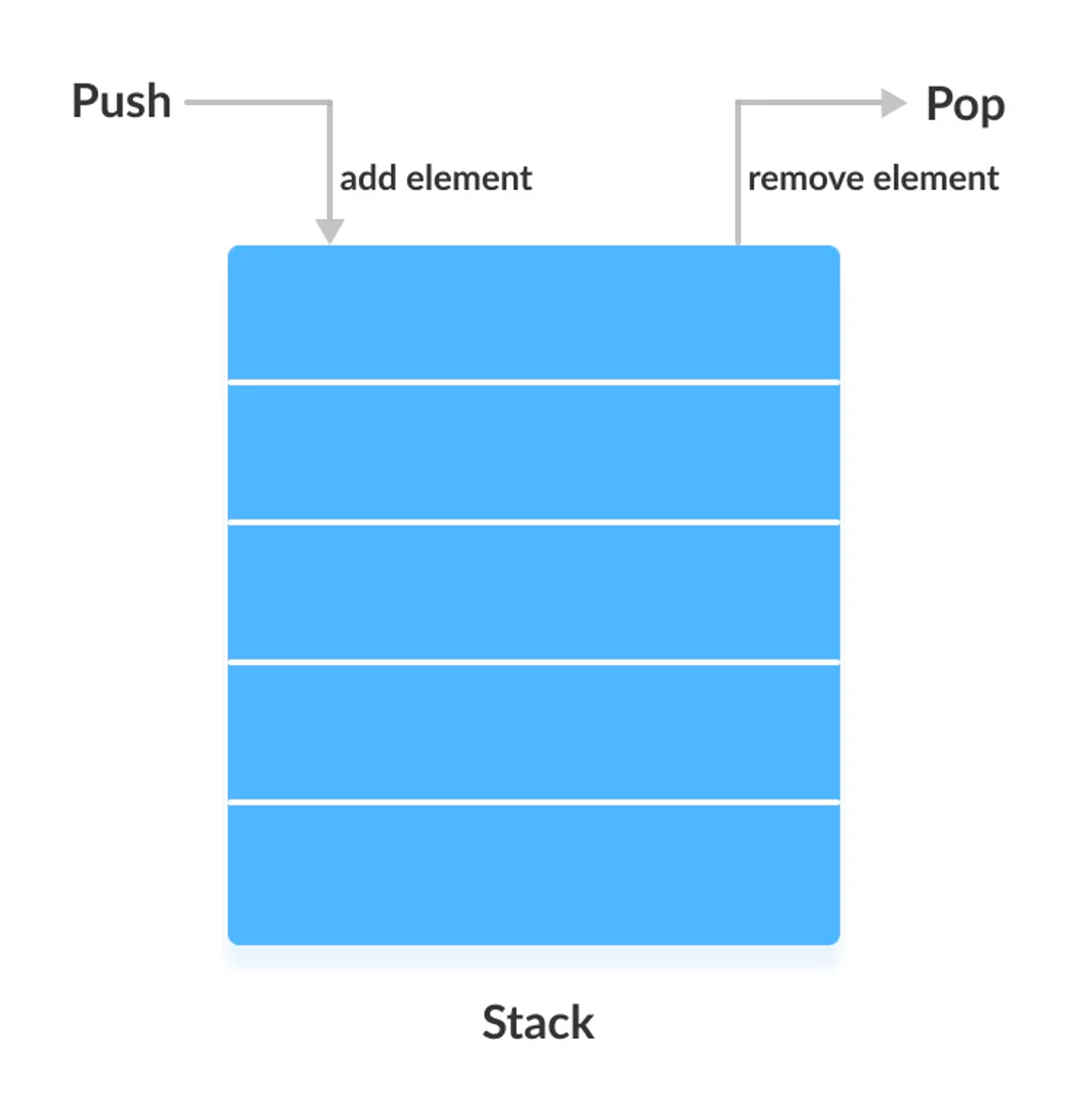
- 한 방향으로만
PUSH와POP을 이용하여 자료를 넣고 꺼낸다. TOP은 스택에서 가장 위에있는 데이터로, 스택 포인터(Stack Pointer)라고도 불린다.
스택 연산
- 스택에는
POP,PUSH가 있다.
| 연산 | 설명 |
|---|---|
| push() | 데이터를 차례대로 스택에 넣는 연산 |
| pop() | 스택의 가장 위에있는 데이터를 제거하고, 꺼내는 연산 |
| peek() | 스택의 가장 위에 있는 데이터를 제거하지 않고, 리턴하는 연산. |
스택 응용분야
-
인터럽트 처리
- 현재 진행중인 명령어 위치를 스택에
PUSH하고, 인터럽트 발생 상황을 처리한 후에 인터럽트 전에 진행중이던 명령어 위치를 스택에서POP을 통해 받아온다.
인터럽트가 발생하면 현재 실행중인 명령어 위치(주소)를 스택 PUSH에 저장한다. 그런 다음 인터럽트를 처리한다. 인터럽트 처리가 완료되면 스택에서 POP(제거 및 반환)을 사용한다. → 인터럽트가 발생하기 전에 실행중이던 명령어의 위치를 다시 가져온다. 이렇게 하면 원래의 작업을 계속 진행할 수 있다!
- 현재 진행중인 명령어 위치를 스택에
-
함수 호출 (재귀호출에 포함)
- 함수를 호출 시, 현재 진행중인 명령어 주소를 스택에 저장한다.
스택 함수호출은 프로그램이 함수를 사용할 때 어떻게 진행되는지 추적하는 방법이다. → 함수가 호출될 때, 그 함수가 시작한 지점의 “주소”가 스택에 저장된다. 특히 재귀호출에 중요한데, 프로그램이 어디서 멈추었는지 알 수 있게 해주기 때문이다. 함수가 모두 실행되고 종료되면, 스택에서 가장 최근에 저장된 주소를 찾아서 그곳으로 돌아간 다음, 프로그램의 실행을 계속 할 수 있는 것이다.
-
후위표현 연산
- Postfix를 계산할 때 사용한다.
후위표현식(Postfix): 연산자가 피연산자 뒤에 오는 표현식
스택을 사용하면 후위표현식을 효과적으로 사용할 수 있게 된다.
피연산자를 만날때마다 스택에PUSH하고, 연산자를 만나면 스택에서 피연산자를POP하여 연산을 수행하고, 결과를 다시 스택에PUSH한다. 이 과정을 표현식이 끝날 때 까지 반복하면 최종 결과가 스택의 맨 위에 남게된다! -
깊이 우선 탐색 (DFS)
- 깊이 내려갈 때마다 스택에 값을 PUSH 하고, 더 이상 깊이 갈 곳이 없을 경우 스택에서 POP한 노드와 인접한 노드를 찾는다.
깊이우선탐색(DFS) 알고리즘에서는 스택을 사용하여 노드를 탐색한다. 탐색을 시작할 때마다 스택에 값을 PUSH 하고, 더 이상 탐색할 곳이 없을 경우 스택에서
POP한 노드와 인접한 노드를 찾는다.
DFS 공부하고 다시 복기하기.
- 깊이 내려갈 때마다 스택에 값을 PUSH 하고, 더 이상 깊이 갈 곳이 없을 경우 스택에서 POP한 노드와 인접한 노드를 찾는다.
-
역순 문자열 만들기
-
웹 브라우저 방문기록(뒤로가기)
- 가장 나중에 열린 페이지부터 다시 보여준다.
오 신기하다.. 특정 페이지 방문할 때마다 그 정보가 스택에 쌓이고 →
‘뒤로가기’를 클릭하면 가장 최근에 방문한 페이지 정보가 스택에서‘POP’되어 이전 페이지를 보여주게 되는 것이다. -
실행 취소(undo)
- 가장 나중에 실행된 것부터 실행을 취소한다.
-
수식의 괄호 검사
- 연산자 우선순위 표현을 위한 괄호 검사
Java Stack Basics
public class Main {
public static void main(String[] args) {
Stack stack = new Stack(); // create a stack
Stack<String> stack2 = new Stack<String>(); // create a stack with a Generic type
Stack<Integer> stack3 = new Stack<Integer>();
stack2.push("Hi"); // push element on Stack
for (int i = 0; i < 5; i++) {
int a = i++;
stack3.push(a);
}
System.out.println(stack3);
}
}[0, 2, 4]
왜 1, 3은 PUSH 되지 않는걸까? 아니 나 뭐한거지?..
0회차 반복에서 0 push & i는 1로 중가 → for문의 i++로 인해 i는 2회차로 넘어감
2회차 반복에서 2 push & i는 3으로 증가 → for문의 i++로 인해 i는 4회차로 넘어감
4회차 반복에서 4 push
다시 본론으로 돌아간다.
public class Main {
public static void main(String[] args) {
Stack stack = new Stack(); // create a stack
Stack<String> stack2 = new Stack<String>(); // create a stack with a Generic type
Stack<Integer> stack3 = new Stack<Integer>();
stack2.push("Hi"); // push element on Stack
for (int i = 0; i < 5;) {
int a = ++i;
stack3.push(a);
}
System.out.println(stack3);
stack3.pop();
System.out.println(stack3); // pop element from stack
System.out.println(stack3.peek()); // peek at top element of stack
stack3.search(3);
System.out.println(stack3.search(3)); // index = 2
System.out.println(stack3.size()); // size = 4
}
}Queue (큐)
스택과는 달리 한 쪽에서는 데이터 삽입, 다른 한 쪽에서는 데이터의 삭제만 가능한 FIFO(First-In First-Out)의 구조를 가지고 있다.

큐 용어
- Queue Front : 줄의 맨 앞
- 삭제 연산만 수행되는 곳,
DEQUEUE가 실행됨.
- 삭제 연산만 수행되는 곳,
- Queue Rear : 맨 뒤
- 삽입 연산만 수행되는 곳,
ENQUEUE가 실행됨.
- 삽입 연산만 수행되는 곳,
Add(ENQUEUE): 큐 리어에 데이터를 삽입Remove(DEQUEUE): 큐 프론트의 데이터를 삭제하는 작업
큐 응용분야
데이터가 입력된 순서에 따라 처리되어야 할 때 사용된다. 예를 들면 은행업무, 놀이동산 등.
- BFS(Breadth-First Search) 너비우선탐색 알고리즘
- 멀티스레딩(Multithreading)에서 스레드를 관리하는데에 사용
- 대기열 시스템에 사용. (우선순위 대기열)
- 동영상 스트리밍 앱에서 데이터를 Queue에 모아두었다가, 동영상 재생에 충분한 데이터가 모였을 때 동영상을 재생.
- 프린터 대기열
큐 연산
자바 API에서 FIFO를 처리하기 위해 Queue를 사용할 수 있는데, 유사한 메서드들이 있다.
기능적인 차이는 아니며 문제 상황에서 예외를 던지느냐? 아니면 null, false를 반환하냐?의 차이가 있다.
| 예외발생 | 값 리턴 | |
|---|---|---|
| 추가(Enqueue) | add(e) | offer(e) |
| 삭제(Dequeue) | remove() | poll() |
| 검사(Peek) | element() | peek() |
즉, enqueue를 할 시에 이미 큐가 꽉 찬 경우 add는 예외를 발생시키지만, offer은 false를 반환하게 된다.
Reference
