ai-school 파이널 프로젝트 4일차 TIL 겸 에러 기록
드디어! ocr 모델을 돌렸다!!!
pre-trained model(korean.g2)인데도 성능이 썩 좋지는 않다. 그래도 결과물이 나왔다! 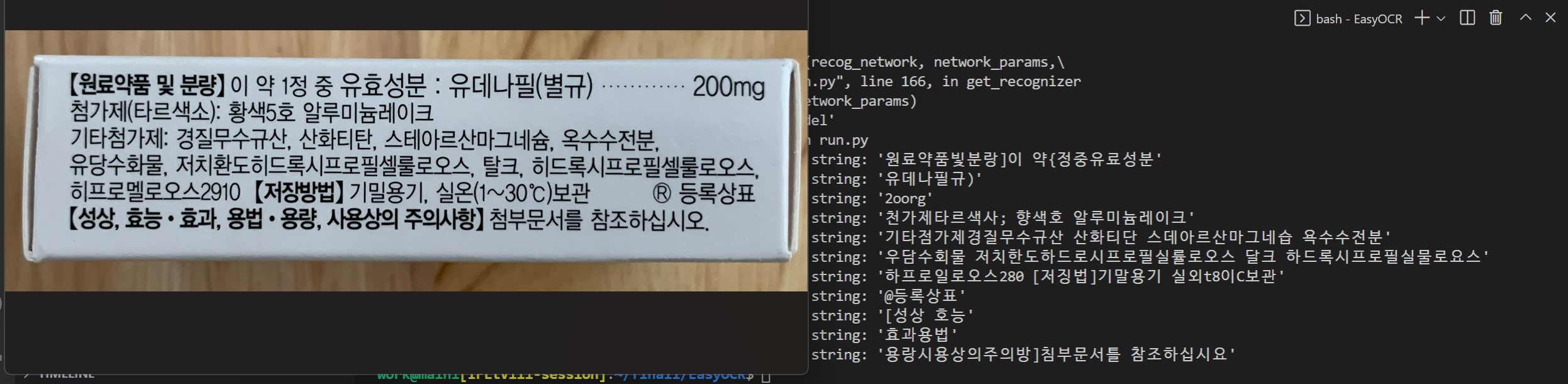
사진처럼 특수문자와 숫자가 함께 있는 텍스트는 인식을 잘 못 한다. 인식해야될 글자가 많아서 성능이 더 떨어지는 건가? 라는 생각도 든다. 데이터를 좀 더 만들어서 학습시켜야겠다. 숫자 섞인 데이터도 만들어지겠지? 폰트를 몇 종류 더 넣고 흐릿한 데이터도 만들어서 돌려봐야겠다.
백엔드.ai로 옮기고 안 돌아가던 trdg는 pip install wikipedia 해주니까 됐다. 역사적인 이게 왜 되지? 의 순간이다. 어제랑 에러 메시지가 다르지만 일단... 돌아가니까... 노트북 끄기 싫어진다 갑자기...
AttributeError: '_MultiProcessingDataLoaderIter' object has no attribute 'next'
=> 이 에러는 코드 파일 속 next 문법이 현재 버전 파이썬과 맞지 않아서 생긴 에러였다. data.next() 를 next(data)로 변경해주니 잘 작동했다.
AttributeError: module 'custom' has no attribute 'Model'
=> 이 에러도 한참 헤맸는데 Model이 아니라 모듈 파일(custom.py)을 잘못 만들어서 생긴 오류였다. 모델만 한참 뒤졌는데 그래도 해결해서 다행이다. 파일들이 서로 연결되어 있어서 중간에 꼬이진 않을지 걱정이다.
오늘의 발견 : 백엔드.ai에 이미지를 압축해서 zip 파일로 올리고 주피터에서 압축을 푸는 방법이 있음
못 올린 덕분에 한국어 학습용 어휘 목록 만들었으니까 오히려 좋아^^..
지금까지 진행해본 ocr 프로젝트는 5단계로 나뉜다.
1) 데이터 생성
- 텍스트 파일과 폰트를 폴더에 넣어주면 이미지가 생성된다.
- Belval/TextRecognitionDataGenerator
- https://github.com/Belval/TextRecognitionDataGenerator/tree/master/trdg
2) 데이터 구조 변환
- 다음으로 편하게 넘어가기 위한 단계
- 랜덤하게 생성된 이미지 파일 이름을 deep-text-recognition-benchmark에서 요구하는 형식으로 바꿔주고 gt.txt 파일을 생성해준다.
- DaveLog/TRDG2DTRB
- https://github.com/DaveLogs/TRDG2DTRB/blob/main/README.md
3) lmdb 파일로 변환
- 이미지 데이터를 모델 학습 가능한 파일로 변환
- clovaai/deep-text-recognition-benchmark
- https://github.com/clovaai/deep-text-recognition-benchmark
4) 학습
- lmdb 파일로 모델 학습
- ocr은 언어를 학습하는게 아니라 형태를 인식해서 구분한다고 한다.
- clovaai/deep-text-recognition-benchmark
- https://github.com/DaveLogs/TRDG2DTRB/blob/main/README.md
5) test
- 모델을 적용하고 테스트
- JaidedAI/EasyOCR
- https://github.com/JaidedAI/EasyOCR/tree/master/easyocr
쓸까말까 망설였던 부분인데 처음에는 TPS-ResNet-BiLSTM-CTC와 TPS-ResNet-BiLSTM-Attn 구조의 모델을 학습시켰다. 구글에 보이는 ocr 프로젝트 글을 전부 읽었는데 개인이 연구한 논문(https://github.com/parksunwoo/ocr_kor)에 의하면 이 구조의 모델이 정확도가 높았다. 하지만 EasyOCR로 넘어가는 단계에서 모듈 파일 생성에 실패해서 쓸 수 없었다. 학습을 다 시켜놓고 pretrained 모델을 쓴 이유가 바로 이것이다.
지금 사용한 모델은 korean.g2 모델로 None-VGG-BiLSTM-CTC 구조인데, 모듈 파일의 None 부분을 TPS로 어떻게 바꾸는지 도통 모르겠다. 아니 애초에 바꿀 수 있는지도 모르겠고 뭐가 어떻게 다른 구조인지도 이해 못 했다. 이걸 바꿔보는 게 중요할까 인식 정확도를 올리는 게 중요할까?
성장을 위해서는 더 찾아보는 게 맞다는 생각이 든다. 실무자가 보기에 정확도 몇 퍼센트 개선은 별 것도 아니라는 말을 듣기도 했고. 그렇지만 다음 단계인 스트림릿, 유튜브 실행 영상으로 뭘 보여줄 수 있을지 모르는 상황이라 ocr 부분에서라도 정확도를 높여야할 것 같고... 고민이다.
