ai-school 파이널 프로젝트 5일차 TIL 겸 에러 기록
부제 : 5일차이지만 1일차입니다
easyocr 모델을 돌렸다는 기쁨도 잠시, 새로운 과제가 찾아오는데?
AttributeError: module 'torchvision.models.vgg' has no attribute 'model_urls'
=> 새로운 이미지를 넣어 돌리려니 모델이 안 돌아가는 이슈가 발생했다. 노트북 끄기 싫더라니 정말..
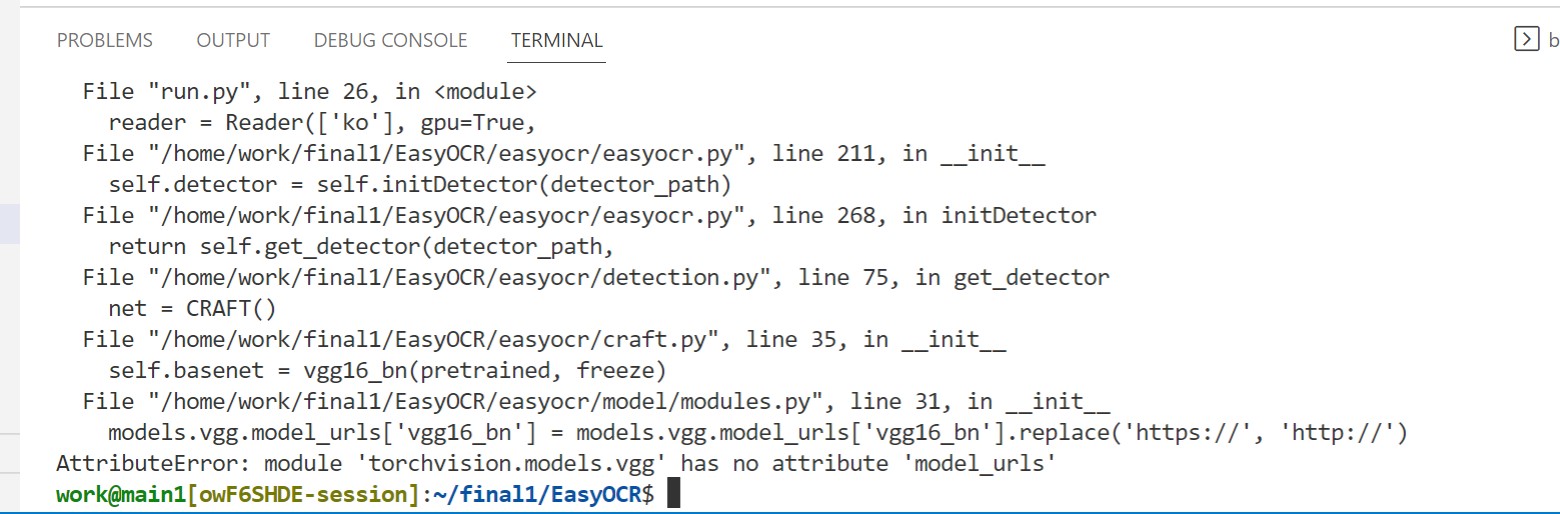
갑자기 왜 이러는지?
나 몰래 다운그레이드라도 했는지??
충돌이 생길까봐 환경은 최대한 안 건드리려고 했는데 -r requirements로 아예 다시 받아와도 해결되지 않아서 torchvision 버전을 업그레이드 했다. 이제 내일도 잘 돌아가길 기도할 수밖에. 하루하루 살얼음판 위를 걸어가는 심정으로 임하고 있다.
ModuleNotFoundError: No module named 'bidi'
=> 이 에러도 대체 왜 생겼는지 모르겠다. 일단 pip install python-bidi 은 했는데. 분명 어제는 잘 됐잖아..?
easyocr 개념을 뒤늦게 공부하고 팀원들과 진행상황을 공유하다가 파이널 프로젝트 기술 멘토님과 팀 미팅을 했다. 질문을 정리하지 못한 채 들어갔는데 다행히 많은 조언을 들었다.
일단 pretrained model을 사용해서 나의 기여가 없다는 문제-쓰고 보니까 진짜 억울하네 삽질을 얼마나 했는데-는 이미지 전처리 모듈을 만들고 성능을 개선하는 식으로 해결할 예정이다.
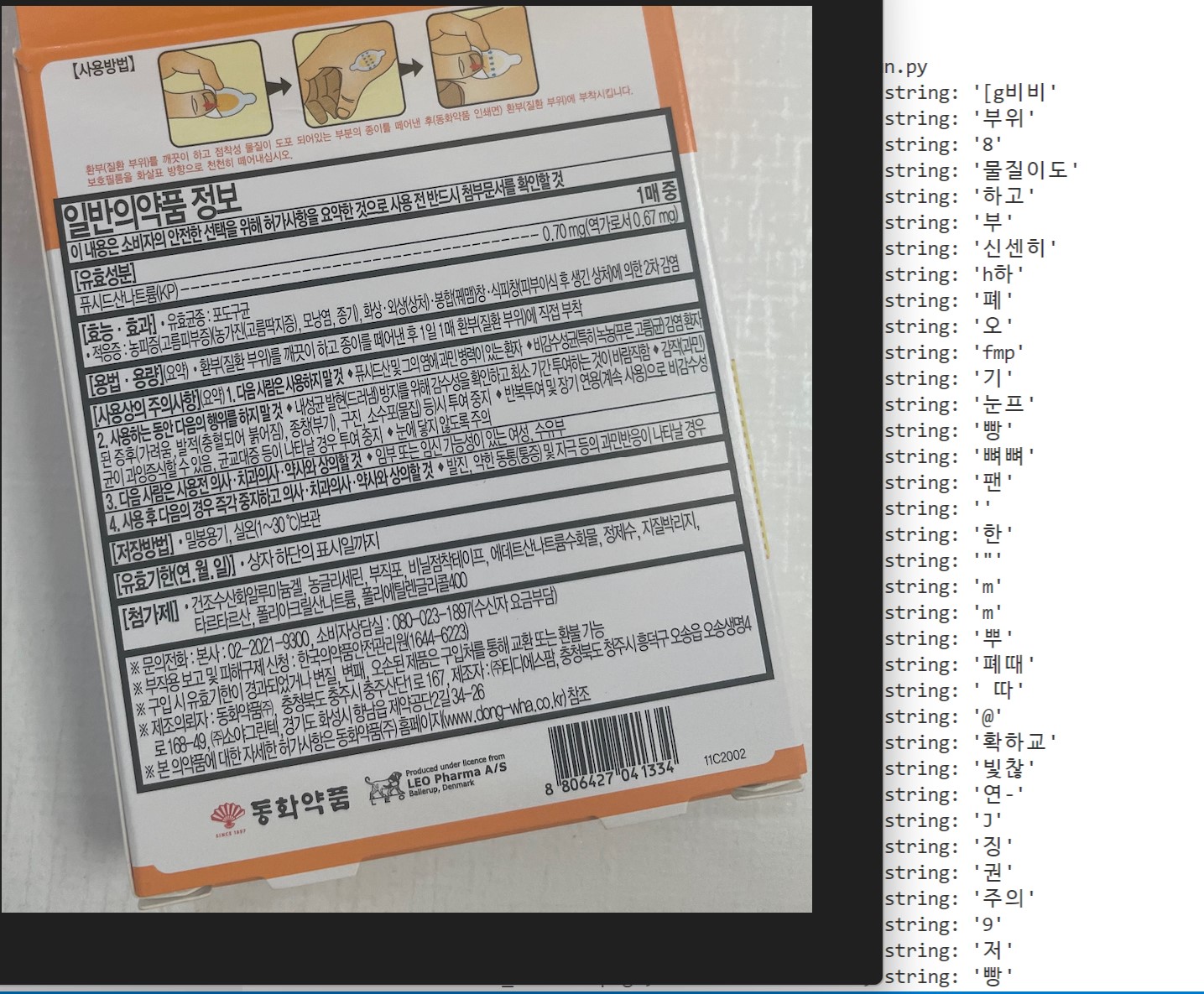
사진에 보이는 것처럼 이미지가 기울어져 있으면 인식률이 확 떨어져서 OpenCV 개념을 찾아보며 이미지 전처리 모듈을 짜고 있다. 사실 OpenCV도 깃허브에 프로젝트가 많이 공유되어 있어서 코드를 그대로 떠올 수 있지만.. 그랬다간 모델만 남고 내 머리는 텅 빌 것 같아서 시간을 많이 쓰고 있다.
쓰다가 든 생각인데 인식을 못 하는 게 텍스트 사이의 두꺼운 줄 때문일 수도 있겠다. 수동으로 평평하게 만들어서 돌려볼 걸!!

문장 안에 영어/숫자/특수문자가 섞여 있을 때도 인식률이 낮다. 한국어+영어/숫자/특수문자 데이터를 만들어볼까 생각했는데 음... 모르겠다. 그렇게도 가능한가? korean_g2 모델이 영어까지 인식하긴 한다만.
또 한 가지 발견한 것은 두꺼운 글씨를 잘 인식한다. 상품명이나 사명 부분을 보면 형태(폰트)가 조금 다른데도 정확도가 꽤 높다. 이 점을 참고해서 모듈에 이미지 dilate를 넣어볼 생각이다.
일단 모듈을 다 만들고 ai-hub의 패키징 데이터 라벨링 파일을 처리해서 easyocr의 dict에 의약품 용어를 추가해볼 생각이다. dict의 한국어 파일을 확인해보니 단어 종류나 양이 한국어 학습용 어휘 목록과 유사했다. 일상적인 단어 위주라 의약품 용어 인식이 떨어지는가 싶어서 시도해보려고 한다.
그런데 다음 단계에서 nlp 모듈로 용법, 용량, 유통기한과 같은 필요 텍스트만 추출할 거라 의약품 용어 인식은 별로 중요하지 않을지도...? 하지만 할 것이다. 잘 읽으면 좋잖아. 재밌기도 하고.
