1. 이산화 정의
이산화란 Numerical Feature를 일정 기준으로 나누어 그룹화하는 것으로 사용하는 방식에 따라 다르지만 변수 값을 간격으로 정렬한다는 공통점이 있다.
2. 이산화가 필요한 이유
1) 이산화 과정이 사람의 사고방식과 부합하는 측면이 있어 직관적이다.
예를들어, 그룹 구성원이 많다면 개별 나이를 기준으로 분류하기 어렵다. 이 경우 10대, 20대, 30대와 같이 10살을 단위로 나눠 분석하면 분석하기에도 편리하고 경향이 뚜렷해져 이해하기 쉽다.
2) 데이터 분석과 머신러닝 모델에 유리하다.
유사한 예측 강도를 가진 유사한 속성을 그룹화하면 모델 성능 개선에 도움이 된다. 치우친 값이 범위 전체에 더 고르게 분산되기 때문인데, 이는 머신러닝 전처리 과정에서 transformation, log 처리를 해주는 것과 같은 이유이다.
3) 과대 적합을 방지할 수 있다.
모델이 특정 Numerical Feature에 과대 적합되면 값의 변화에 따라 예측 값이 지나치게 바뀌게 된다. 최소값, 최대값 등 이상치의 영향을 많이 받는다는 뜻이다.
이 경우 적절한 그룹화를 통해 Numerical Feature의 영향을 줄일 수 있다.
4) 연속 특징을 이산화할 경우 데이터가 단순해지고 학습 프로세스가 빨라져 더 정확한 결과 도출할 수 있다.
데이터가 많아질 수록 모델의 학습 속도가 느려지는 것은 당연하다. 적절한 이산화를 통해 이를 방지할 수 있다.
3. 이산화 주의점
이산화 알고리즘의 작업은 해당 간격에 대한 cut 포인트를 결정하는 것이다.
서로 다른 클래스 또는 대상 값과 강하게 연결된 값을 동일한 빈(bin)으로 결합하면 정보 손실을 초래할 수 있다. 따라서, 이산화 알고리즘은 정보를 크게 잃지 않는 최소 간격 결정을 목표로 한다.
4. 이산화 방법론
이산화 방법론에는 Equal width binning, Equal frequency binning, k-means clustering, Decision Tree Discretiser 등이 있다.
이 중 일반적으로 많이 사용되는 방법은 Equal width binning, Equal frequency binning 이다.
1) Equal width binning
등폭 이산화는 가능한 값의 범위를 동일한 너비의 간격(N개의 bins)으로 나누는 것으로 편향된 분포에 민감하다는 단점이 있다. 간격(width)을 계산하는 식은 다음과 같다.
width = (max−min)/N
Equal width binning은 절대평가와 비슷한 방식으로, 한 개의 분할 안에 몇 개의 값이 들어가는지와 무관하게 전체 범위에 대해 N분할을 적용한다.
pandas에서는 pd.cut으로 사용이 가능하다.
2) Equal frequency binning
등빈도 이산화는 빈도를 기준으로 범위를 나눈다. 연속형 변수를 동일한 구간으로 정렬하는데, 각 분할 안에 동일한 개수의 관측값이 들어간다. 따라서 각 간격의 너비는 계산한 특정 분위수를 기반으로 한다.
이는 상대평가와 유사한 방식으로 알고리즘 성능 개선에 도움이 될 수 있지만 binning이 대상과의 관계를 방해해 오히려 성능이 저하될 수도 있다.
pandas에서는 pd.qcut으로 사용이 가능하다.
cut()은 동일한 길이로, qcut()은 동일한 개수로 나눈다는 차이가 있다.
3) k-means clustering
유사한 관찰을 그룹화하는 구간 또는 빈(bin)을 생성하기 위해 k-mean과 같은 클러스터링 알고리즘을 사용할 수 있다.
k-means를 사용한 이산화에는 하나의 매개변수인 k, 클러스터 수 또는 빈(bin) 수가 필요하다.
scikit-learn으로 이산화를 수행할 수 있다.
from sklearn.preprocessing import KBinsDiscretizer4) Decision Tree Discretiser
Decision Tree Discretiser는 학습 과정 동안 연속 속성을 이산화하는데, 다음을 거쳐 실행된다.
1) 특성의 가능한 모든 값을 평가하고 엔트로피 또는 지니 불순도과 같은 성능 metric을 활용하여 클래스 분리를 최대화하는 cut 포인트를 선택
2) 특정 중지 기준에 도달할 때까지 첫 번째 데이터 분리의 각 노드와 후속 데이터 분할의 각 노드에 대해 프로세스를 반복
→ 설계상 좋은 클래스 일관성을 갖는 구간으로 변수를 분할하는 컷 포인트 세트를 찾을 수 있다.
결정 트리를 사용하여 각 연속 변수에 대한 최적의 파티션을 식별한다.
from sklearn.preprocessing import KBinsDiscretizer
from sklearn.tree import DecisionTreeRegressor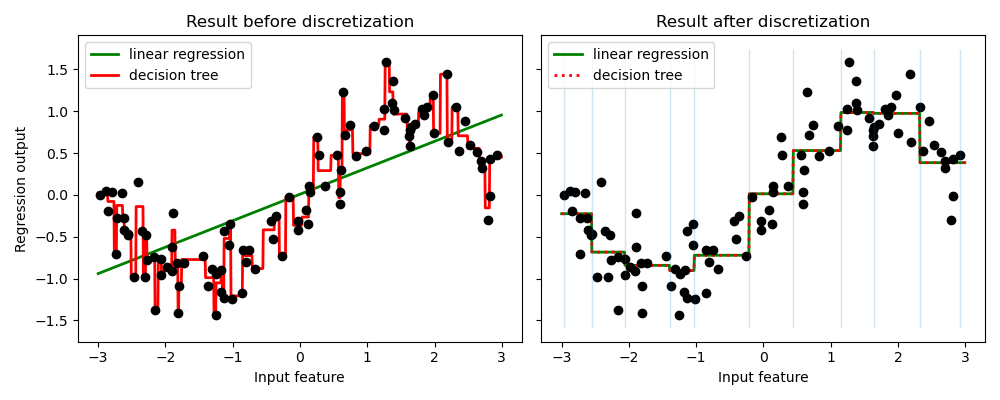
위는 이산화가 있는 경우와 없는 경우 선형 회귀(선형 모델), 의사 결정 트리(트리 기반 모델)의 예측 결과를 비교한 그림이다.
선형 모델은 훨씬 더 유연해지며 의사 결정 트리는 훨씬 덜 유연해짐을 확인할 수 있다.
그러나, 일반적으로 트리 기반 모델에 이산화는 유익한 효과가 없다.
외에도 MonotonicBinning, WOE(Weight of Evidence) 방법이 있다.
5. 참고 자료
https://feature-engine.readthedocs.io/en/0.6.x_a/discretisers/EqualWidthDiscretiser.html
https://feature-engine.readthedocs.io/en/1.1.x/discretisation/EqualWidthDiscretiser.html
