파이썬 데이터분석 프로젝트 : 교통사고를 많이 내는 특정한 연령이 있을까?

ai 스쿨 5주차
미드 프로젝트가 5일간 진행되었다!
기간이 긴 건지 짧은 건지 몰랐는데 짧은 편이라고 한다.
어쩐지 시간이 너무 부족하더라;;
이번에는 교통사고분석시스템 TAAS의 데이터를 활용해서 분석을 진행했다.
사고유형/발생 시기/차종/도로형태/연령/법규위반 별로 나눠서 진행했는데, 내가 고른 주제는 가해자 연령!
개인적으로는 어린이 교통사고 데이터에 좀 관심이 있었는데 가해자 위주로 분석하자는 의견이 있어서 가해자 연령으로 갔다.
해보고 싶은 분석이 점점 많아지고 있다.
0. 가설 설정
이번에는 데이터가 다양해서 가설도 많이 세웠다.
- 교통사고 발생량이 많은 특정 연령이 있을 것이다.
- 여름 휴가를 가는 8월과 눈으로 인해 많이 나는 겨울에 사고 건수가 높을 것이다.
-> 이건 연령과 딱히 상관이 없는데 데이터가 있길래 그냥 설정해봤다. - 20세 이하 운전자의 경우 연말과 연초, 11 ~ 2월 동안 사고 건수가 많을 것이다.
- 직장인이 많은 30-40대 운전자들은 출퇴근 시간에 교통사고가 일어났을 것이다.
- 20대와 30대 운전자의 요일별 교통사고 발생 건수에 차이가 있었던 것처럼 시간별 발생 건수에도 차이가 있을 것이다.
- 50대 운전자의 수가 많으니 사고량도 더 많겠지만, 사고 발생 시간에는 차이가 없을 것이다.
더 있었는데 폐기하고 남은 게 이만큼이다. 분석에 유의미한 결과가 나오지도 않았고 시간도 여유롭지 않았기 때문.
1. 분석을 위한 준비
TAAS 교통사고분석시스템에서 경찰DB-운전자관련-가해운전자 연령층별 데이터들을 받았다. 사고건수/사망자수/부상자수 이렇게 나뉘어 있는데 구분이 필요없어서 체크 해제. 2021년 데이터만 사용할 거니까 연도도 해제.
http://taas.koroad.or.kr/web/shp/sbm/initUnityAnalsSys.do?menuId=WEB_KMP_OVT_UAS
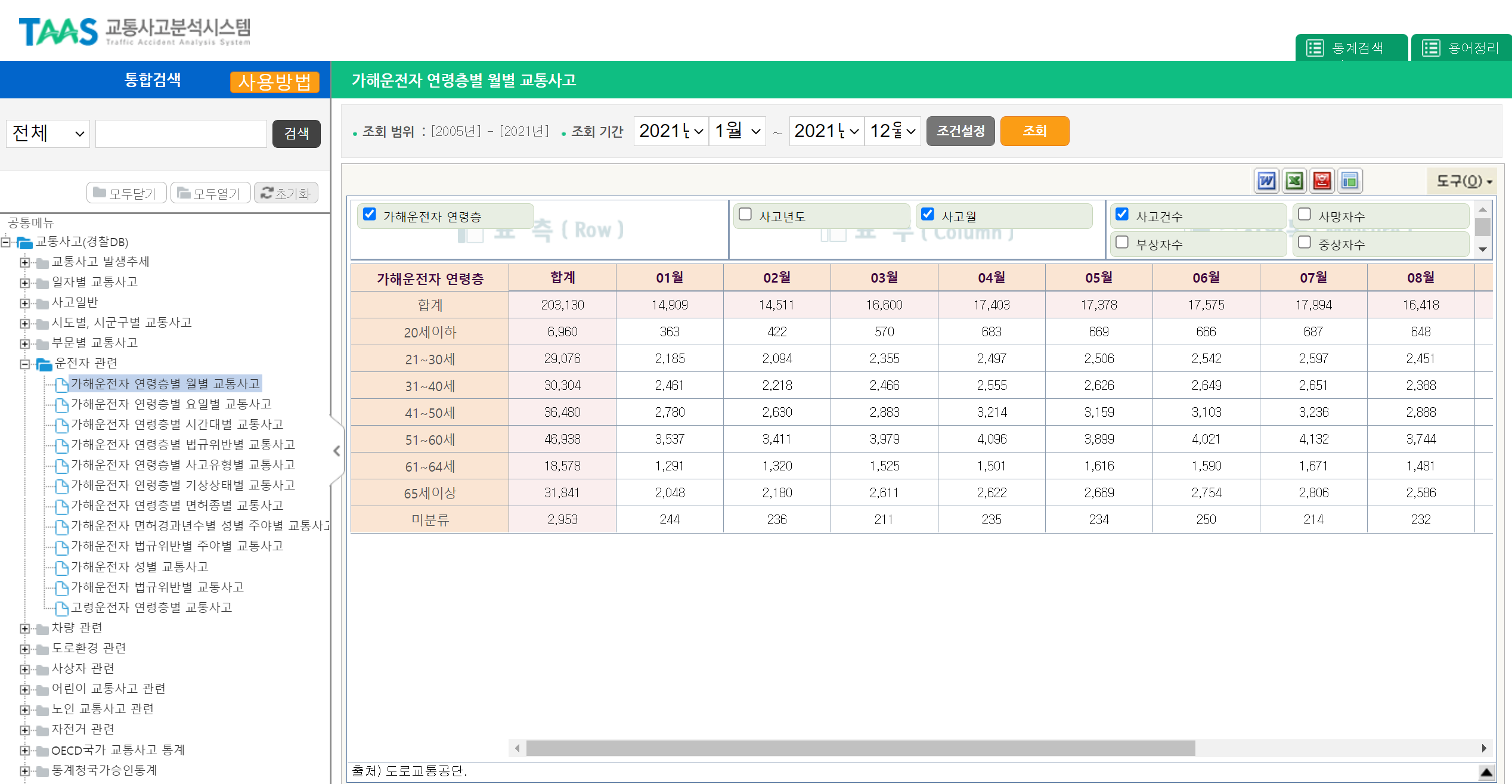
연령층이 들어간 데이터를 전부 다 받아서 전처리를 했는데 굳이 그럴 필요가 있었나 싶기도 하고. 전처리에 시간을 엄청 많이 썼는데 시각화까지 끝내고 스트림릿에 올리려고 하니까 쓸 데이터는 두 개뿐이었다. 슬프다 진짜....
2. 데이터 전처리
데이터가 많아서 glob으로 불러왔다.
import pandas as pd
from glob import glob
file_name = glob("연령*.xls")
month = pd.read_excel(file_name[6])
month.head(3)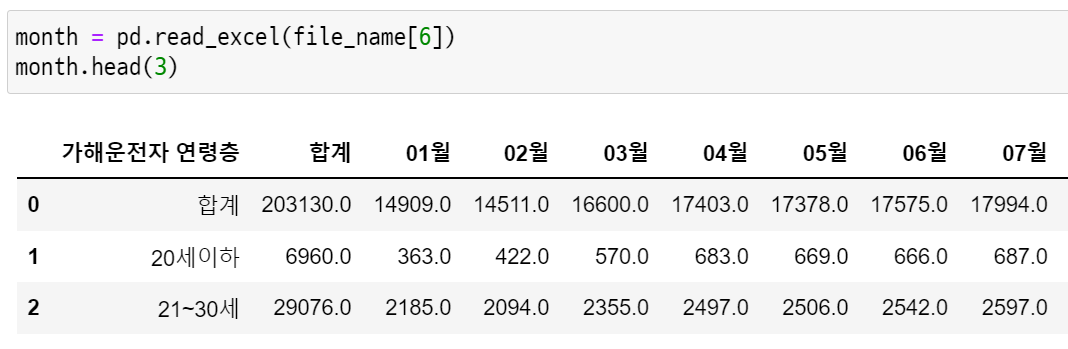
데이터를 불러오면 이렇게 생겼다. 일단 컬럼명을 바꿔줘야 하고 합계 행도 중복이니까 날려줄 필요가 있다.
# 결측치 제거
month = month.dropna()
# 월별 합계가 있는 첫번째 행 제거
month = month.drop([0])
# 컬럼명을 바꿔주기 위해 기존 컬럼명을 리스트로 생성
col = month.columns.to_list()
# 리스트에서 "월"을 split으로 날리고 할당해준다.
# 리스트의 0번째 값은 '가해운전자 연령층'이므로 제외한다.
col = [i.split("월")[0] for i in col[1:]]
# 처리된 리스트에 '가해운전자 연령층'이 없으므로 '연령'으로 넣어줬다.
new_col = ["연령"] + col
# 완성된 리스트를 컬럼명으로 적용
month.columns = new_col여기까지의 결과물
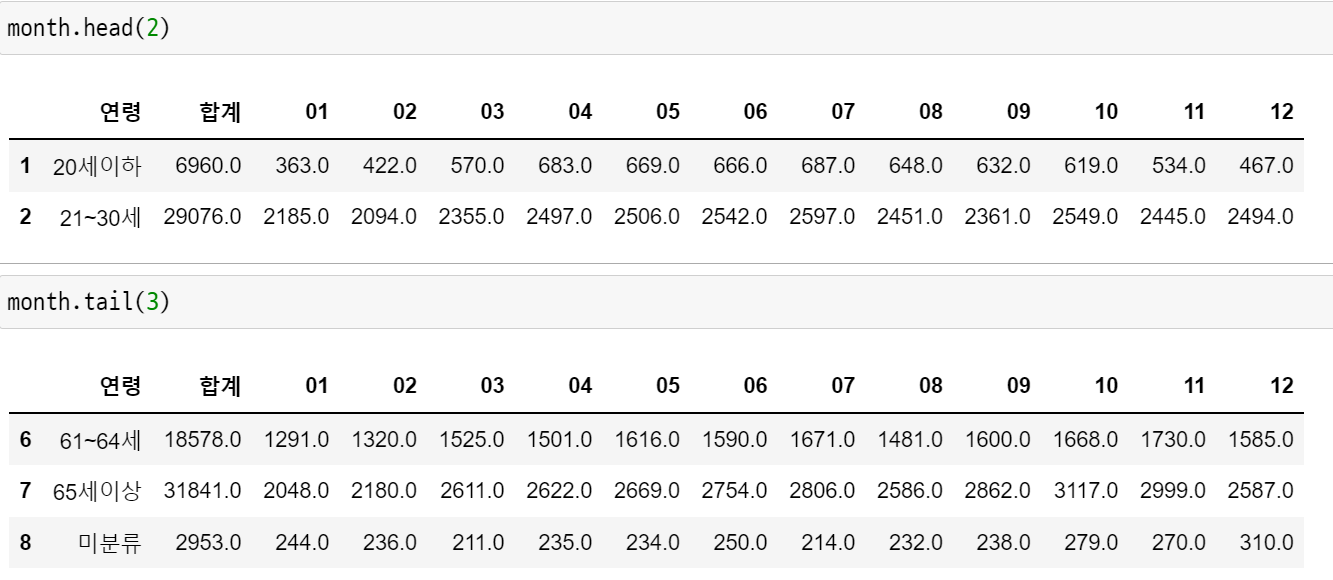
이제 미분류 행을 빼주고 tidy 데이터로 바꿔줄 차례.
month = month.drop(index=8)
# 연령과 합계를 기준으로 melt
mon_melt = pd.melt(month, id_vars=["연령","합계"])
# 컬럼명 지정
mon_melt.columns = ["연령", "합계", "월", "발생건수"]
# 타입 변환
mon_melt = mon_melt.astype({'월':'int'})
mon_melt = mon_melt.astype({'합계':'int', '발생건수':'int'})
# 전처리와 시각화를 따로 진행할 예정이라 저장해주기
mon_melt.to_csv("연령_월별.csv", index=False, encoding='cp949')이 과정을 모든 데이터에 반복했다.
이게 왜 오래 걸렸지? 라는 의문이 들 수 있는데,
다 적을 수는 없지만 전처리에만 꼬박 이틀을 쓰고!
시각화를 하다가도 전처리가 덜 돼서 다시 돌아갔다가 그냥 포기하고 스트림릿 구현할 코드에서 전처리 했다가 거의 뭐 청기백기
두 가지만 말하자면 첫 번째로 다른 주제의 데이터들 전부 같은 형식으로 바꿔서 아래로 concat 했다가 붙인 의미가 없어서 버렸고.
두 번째로는 모든 데이터를 연령을 기준으로 옆으로 쭉쭉쭉 붙였다가 이러면 사용하기 힘들다고 정리해야 한다는 말을 듣고 다시 뗐다...
그 외에도 for문을 굳이굳이 써야겠다고 머리 싸매고 있다가 도움받아서 해결했는데 막상 처리하고 보니까 생각한 형식이 아니라서 버리기도 했고 다양하게 삽질을 했다.
교훈 : 전처리 하기 전에 기준부터 잘 세우자
3. 시각화
기억 상으로는 주피터 노트북에서 1차적으로 시각화를 해보고 스트림릿에 올릴 것만 뽑아서 vscode를 켰는데 왜 시각화 파일이 없을까...........?
기록을 잘 하자
간신히 넘어온 시각화에서도 우여곡절이 많았다.
무슨 plot을 써야할지도 모르겠고
대체 무엇을 어떤 모양으로 보여주고 싶은 건지도 모르는 상황.
망한 시각화 대회 안 열리는지 궁금할 정도로 다양하게 망했다.

유형 1. 뭐가 뭔지 알 수 없는 시각화
이건 아마 전처리를 덜해서 전부 범주형 데이터가 되어버린 경우인듯
유형 2. 이게 뭐라고요?
역시나 답이 없다
유형 3. 고무찰흙 생성기
왜 이렇게 된 걸까...
어쨌거나 시각화를 하면서 버릴 건 버리고 스트림릿에 올릴 것만 추렸다.
예시로 가해자 연령별 기상 상태별 사고건수 데이터가 있어서 '연령별로 어떤 기상 상태에서 사고가 많이 나는지' 알아보려 했다.
막상 시각화를 해보니 모든 연령에 비슷한 결과가 나와서 lineplot 모양이 거의 똑같았고 비오는 날과 안개낀 날의 비율을 구해야 분석이 될 것 같아서 드랍했다.
4. Streamlit 구현
스트림릿 링크 : https://seonseono-traffic-accident-data-analysis-pagesage-4t7s6m.streamlitapp.com/
스트림릿은 딱 두 가지만 기억하면 된다.
- 깃헙 Raw data 링크로 파일 가져오기
- 인코딩은 무조건 utf-8
가설도 흥미로웠던 두 가지만 선정해봤다.
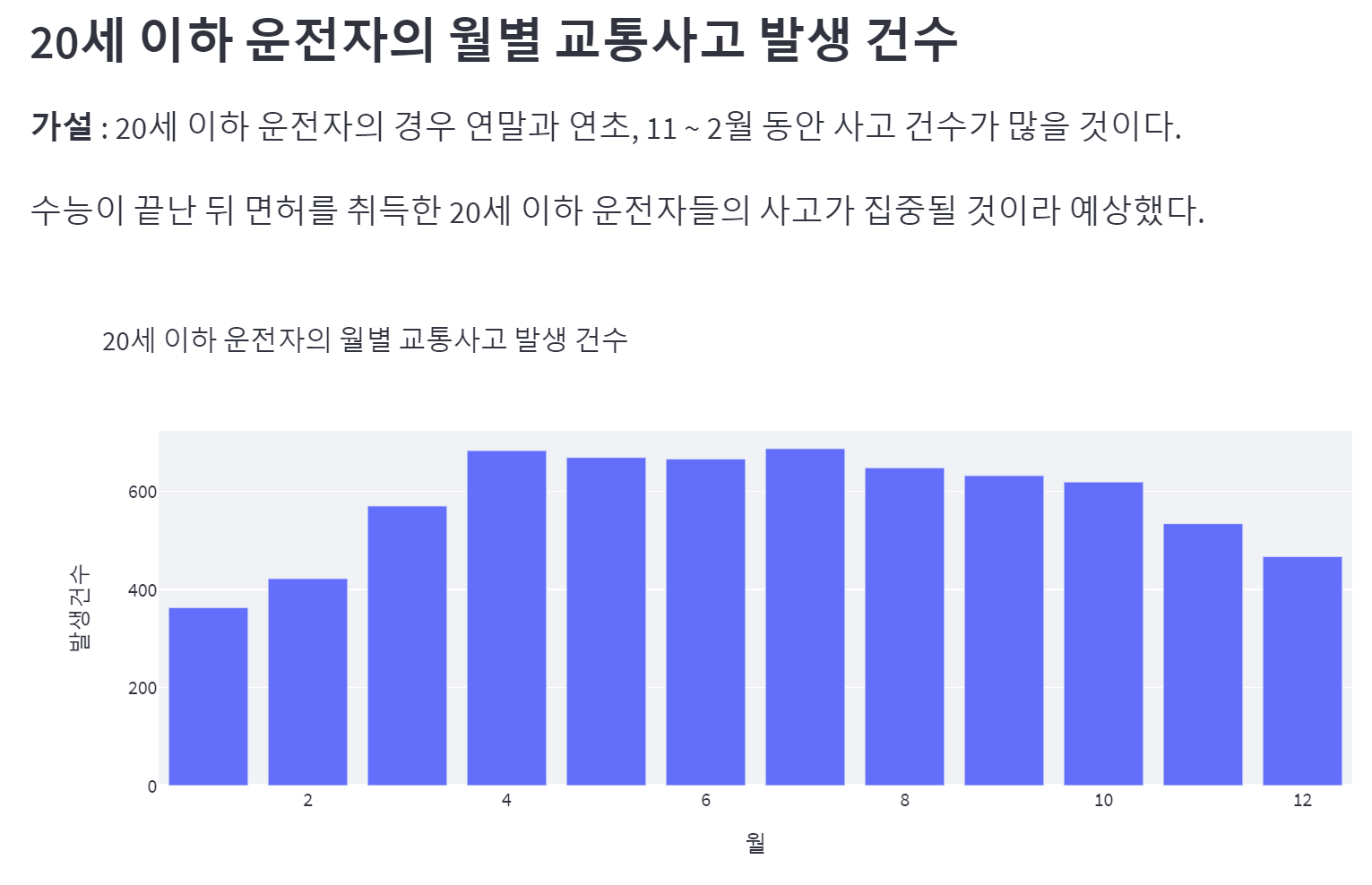
가설과 달리 연말과 연초를 기점으로 점차 사고 건수가 늘어나고 특히 2월과 3월 사이에 큰 폭으로 상승하는 그래프가 그려졌다.
연말과 연초에 사고 건수가 가장 적어서 의문이었는데 면허를 취득하는 시기와 실제로 도로에 나오는 시기 사이의 갭을 고려하지 않아서 생긴 차이이다.
가설 설정 시 고려해야 할 점을 하나 알게 된 사례.
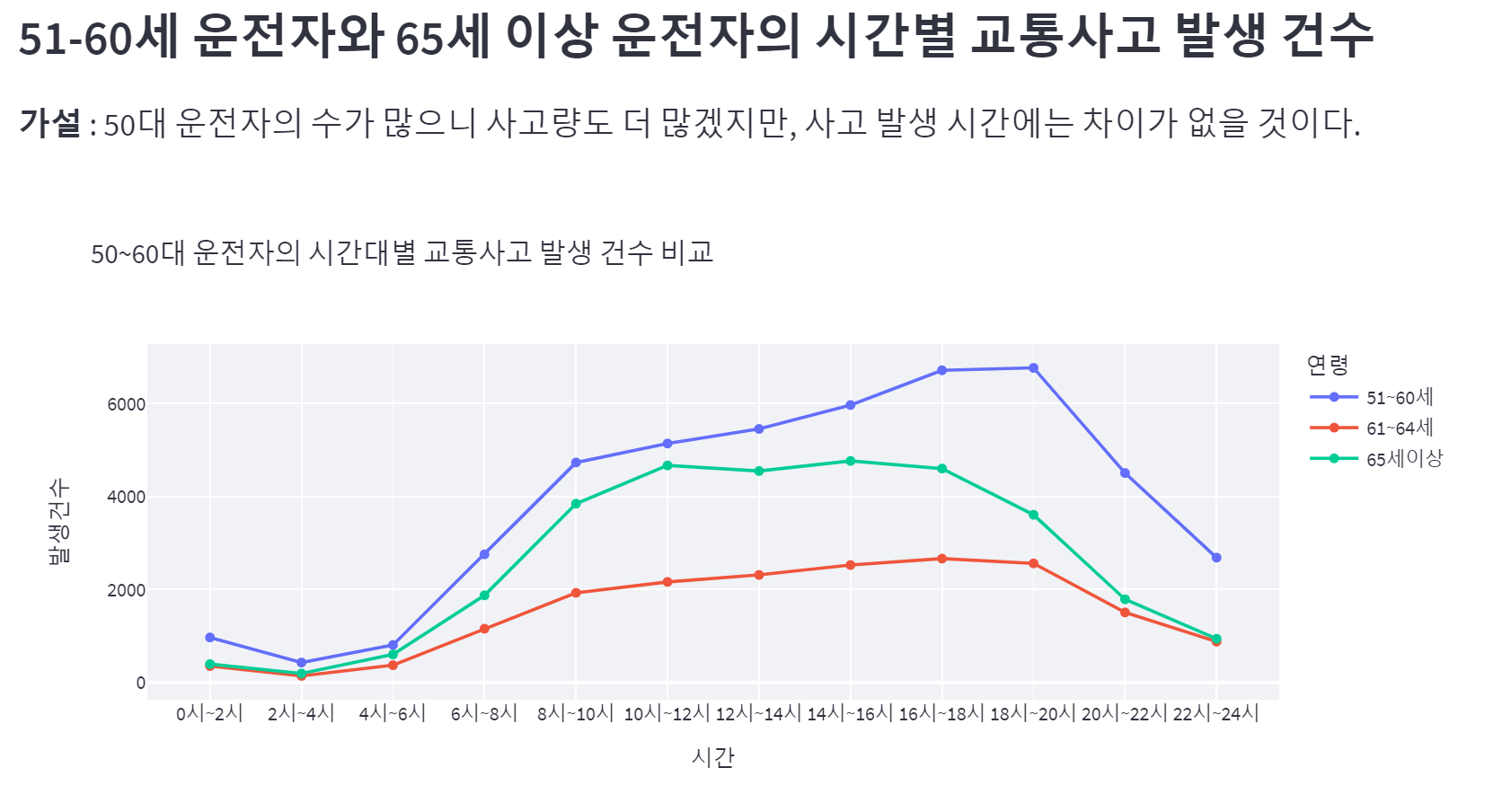
61~64세 운전자보다 65세 이상 운전자의 교통사고 발생 건수가 많은데, 연령 범위가 더 넓어서 나타나는 현상일 수 있으므로 유의미한 지표는 아니다.
51-60세, 61-64세 운전자는 20-40대 운전자와 마찬가지로 출퇴근 시간에 높은 사고 건수를 기록했다.
그러나 65세 이상 운전자는 10-12시, 14-16시에 피크를 찍은 것으로 보아, 출퇴근 시간이 있는 직장인은 아니라고 추측할 수 있다.
실제로 한국의 정년퇴직 나이를 분석한 기사에 따르면 한국인이 '주된 일자리(가장 오랜 기간 일한 일자리)'에서 퇴직하는 연령은 평균 49.3세.
이들 대부분은 퇴직 후에도 경제활동 지속을 위해 재취업을 원하는데 반해, 65세 이상은 9-6 정규직 형태의 취업은 잘 이뤄지지 않음을 확인할 수 있다.
고령자 교통사고가 많이 발생하는데 면허 반납에 반응이 저조한 이유를 알 수 있는 분석이었다.
5. 결론
운전자 연령이 교통사고에 미치는 영향은 예상했던 것보다 크지 않았다!!
대부분의 분석에서 연령이 아닌 외부 변수(휴가철, 가설 설정 오류 등)에 의해 차이가 발생했다.
오히려 그 점에서 볼 때, 파악하기 어려운 지표인 연령별 실질 운전자수를 연령별 교통사고 발생 건수로 대체해서 활용할 수 있겠다는 인사이트를 얻었다.
다음엔 또 어떤 프로젝트를 할 지 기대된다.
