파이썬 데이터분석 프로젝트 : 이혼 사유 별 발생 건수는 어떻게 변화했을까?

ai스쿨에 지원할 때부터 가장 기대했던 팀 프로젝트! 두 번째 미니 프로젝트를 기록해보려 한다.
비대면인 데다 코딩 특성 상 학교에서 경험했던 그런 팀 프로젝트는 아니었다. 화면 공유한 상태로 다 같이 PPT 만들기나 다함께 밤새서 기업분석 보고서 쓰기 같은 거.
그러나! 확실히 팀으로 진행하니까 진행이 잘 된다.
기한 안에 못 끝내면 미팅 때 아무런 결과물도 보여줄 수 없다는 불안감! 효과가 굉장하다.
이번 미니 프로젝트는 kosis의 이혼 데이터를 활용했다. 팀 회의 중에 나가야 했어서 어떤 경로로 이혼이 선정된 건지는 모르지만, 재밌는 주제였다.
어차피 도메인 지식도 없으니 재밌으면 그만이다.
1 연도별이혼 + 이혼사유
2 연도별이혼 + 동거기간
3 연도별이혼 + 평균이혼연령
총 세 가지 중에 하나씩 선택해서 분석을 진행했다. 이 중 제일 재밌을 것 같은 연도별이혼+이혼사유를 골랐다. 그리고 이번 프로젝트에서는 가설도 설정해서 진행해봤다.
0. 가설 설정
과거에는 이혼에 보수적이었으니 최근에 가까워질 수록 성격 차이로 이혼하는 경우가 많아질 것
이라는 가설을 세웠다. 과연 결과는??
1. 분석을 위한 준비
주피터 노트북에서 환경 설정을 해준다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 한글폰트
import koreanize_matplotlib
# retina 디스플레이 설정
%config InlineBackend.figure_format = 'retina'
pd.Series([1, -1, 3]).plot(title="한글", figsize=(5,1))kosis 첫 화면 그대로 다운 받아서 전처리를 하다가(삽질 99에 진행 1의 비율로) 멀티 인덱스를 도저히 처리할 수가 없어서 설정을 조금 바꿔서 다운받았다.
2. 데이터 파일 업로드
# glob을 사용해 파일 불러오기
from glob import glob
file_name = sorted(glob("data/divorce*.CSV"))
file_name3. 데이터 확인
dt = pd.read_csv(file_name[1], encoding='cp949')
dt.shape
dt.head(2)
dt.tail(2)
dt.info()
dt.isnull().sum()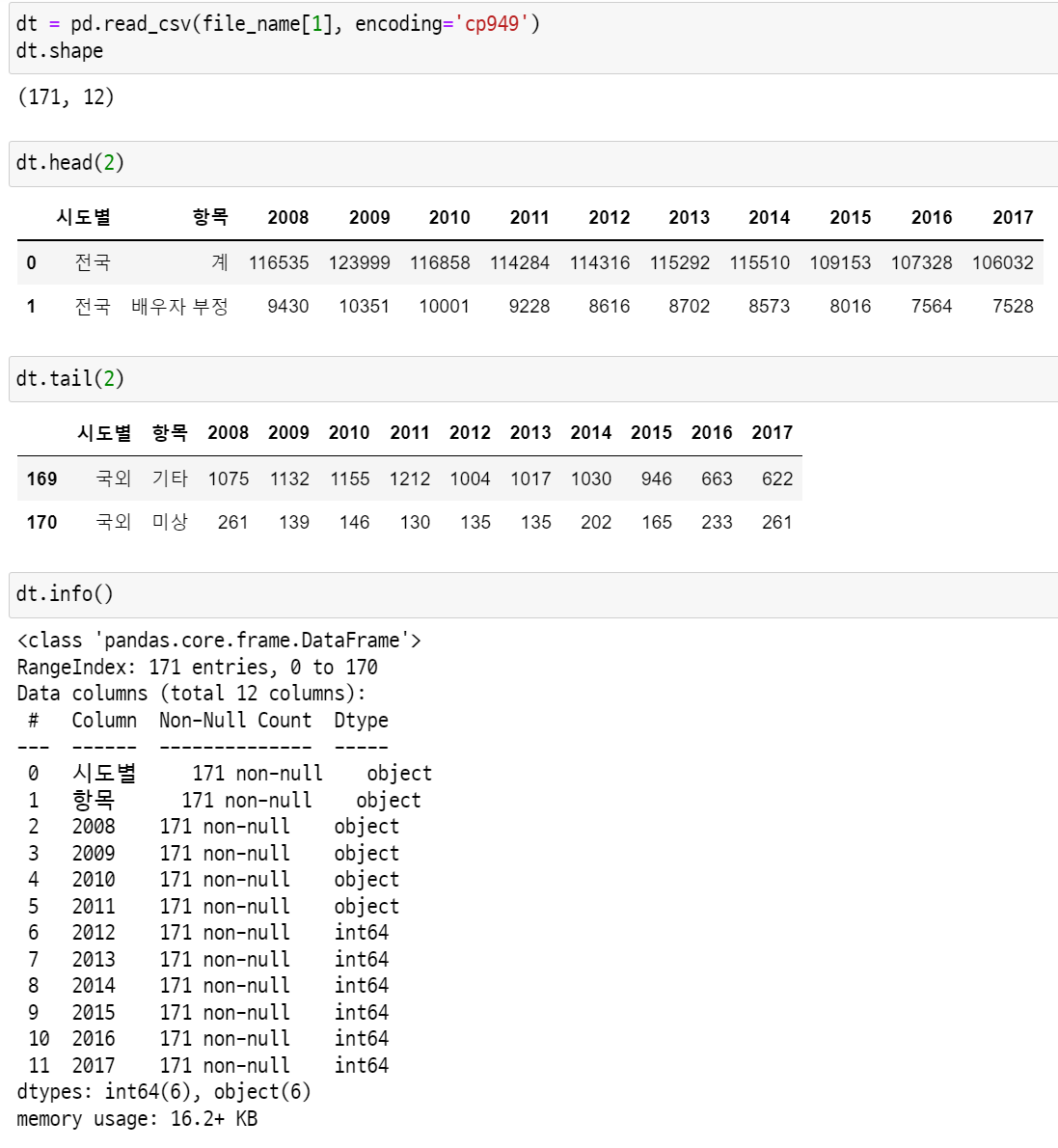
데이터를 확인해보니 행 인덱스에 연도가 들어가 있어서 분석에 적절하지 않다. 그리고 연도 중 일부는 object 타입으로 되어 있다.
왜일까?
차근차근 확인해보자.
4. 데이터 전처리
먼저 컬럼에 들어있는 연도를 행으로 녹여준다.
시도별과 항목을 기준으로 하고 variable name에 발생 연도를, value name에 발생 건수를 지정해줬다.
df = dt.melt(id_vars=dt.columns[:2], var_name="발생 연도", value_name="발생 건수")
df.head(3)
df.tail(2)
df.info()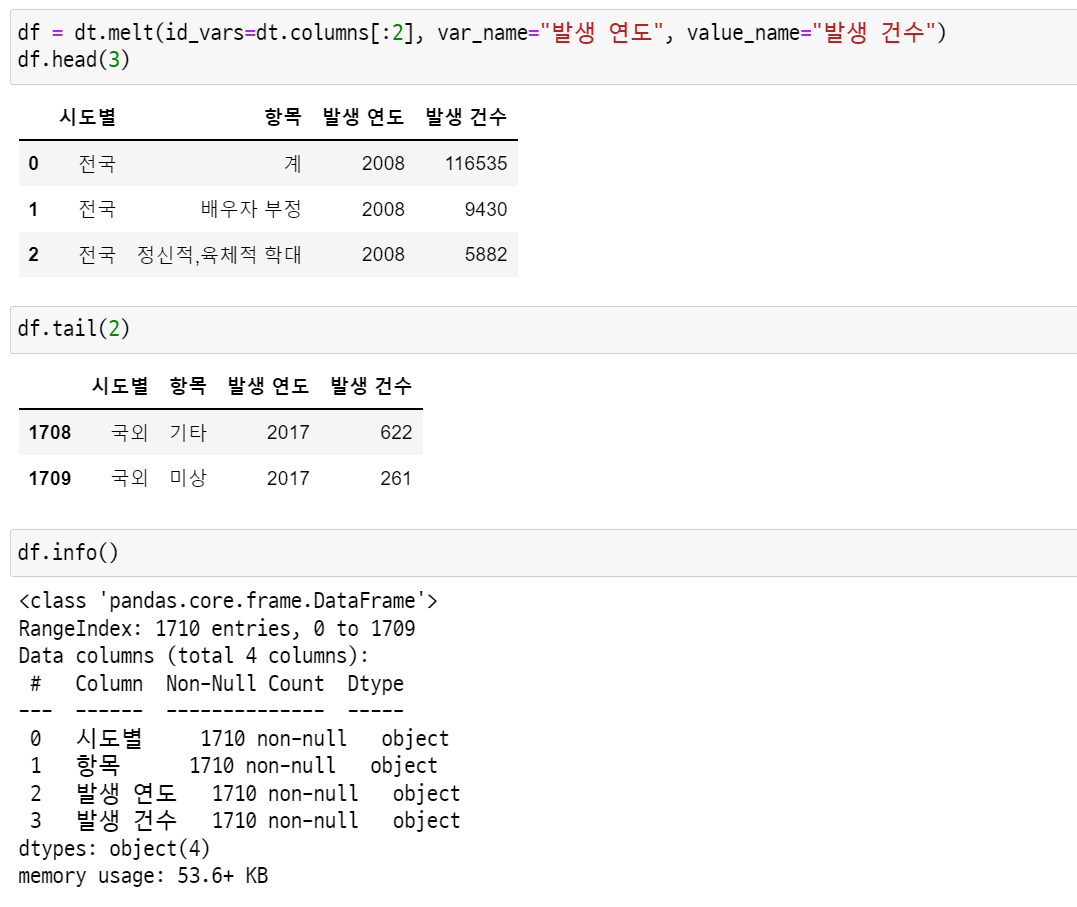
일단 컬럼 이름부터 바꿔주고 처리해야겠다.
df = df.rename(columns={'시도별':'지역', '항목':'이혼 사유'})
df.describe()
마음에 들어요
이제 object 타입인 두 컬럼을 int로 바꿔줄 차례
냅다 astype을 썼더니 변환은 안 되고 자꾸 오류 메시지가 떴다.
could not convert string to float: '-'
왜이러는 건데...
티스토리도 먹통이라 구글링 백시간 추가.
찾아보니 '-' 이게 있어서 int로 변환할 수 없다는 뜻이었다. 얘가 왜 있지??
또 삽질을 하다가 kosis에 들어가서 데이터를 확인했다.
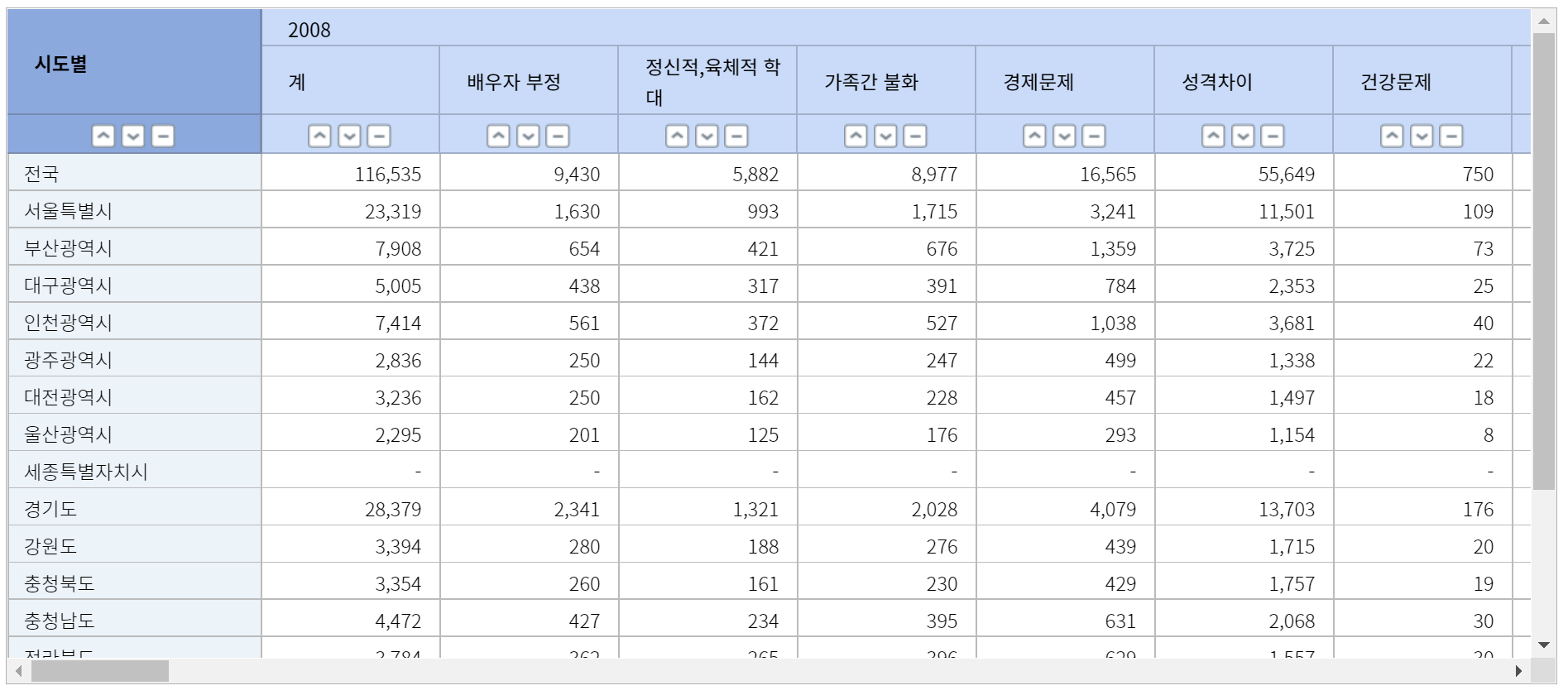
범인은 바로 세종시. 시로 승격되기 전인 2007~2011년에는 데이터가 없는데 그걸 -로 입력해둔 것이었다.
null값 없다매...............
아무튼 원인을 찾았으니 처리해준다.
df['발생 연도'] = df['발생 연도'].astype(int)
# df['발생 건수'] 에 있는 -값(세종시 등 새로 생긴 시에서 발생)을 0으로 변환
df['발생 건수'] = df['발생 건수'].replace("-", "0", regex=True)
df['발생 건수'].isnull().sum()
df['발생 건수'] = df['발생 건수'].astype(int)
df.info()
이거쥐
보다 편한 시각화를 위해 각 사유마다 있는 '계' 행도 삭제해줬다. 지금 생각해보니 살려두고 비율을 보는 것도 좋았을 것 같다.
# 이혼 사유 '계' 행 삭제
df = df.drop(index=df.loc[df['이혼 사유'] == '계'].index)4. 시각화
먼저 지역 별 이혼 발생 건수를 bar plot으로 시각화했다.
df.groupby('지역')['발생 건수'].sum().sort_values(ascending=False).plot(kind='bar')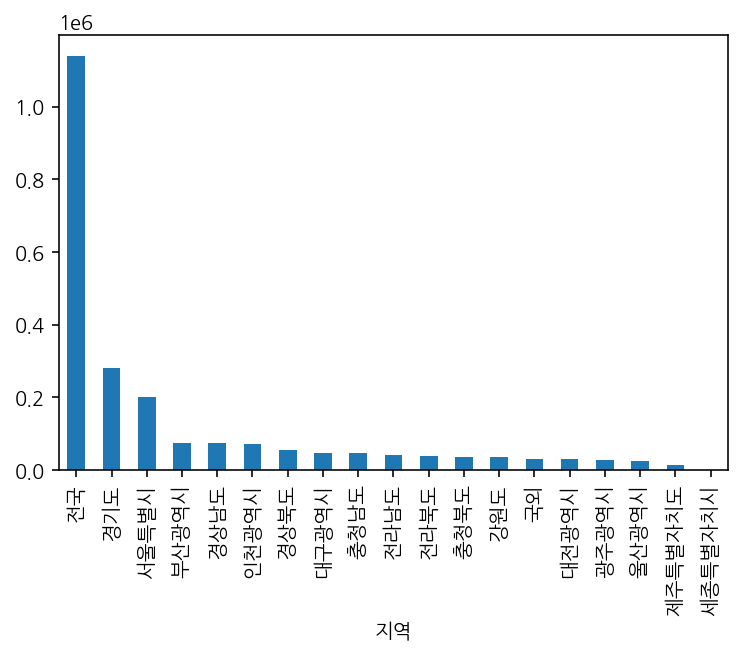
전국이 너무 커서 다른 지역은 확인이 안 된다.
새로운 데이터프레임을 만들고 인덱스도 reset.
ndf = df.drop(index=df.loc[df.지역 == '전국'].index)
ndf = ndf.reset_index()
ndf.groupby('지역')['발생 건수'].sum().sort_values(ascending=False).plot(kind='bar')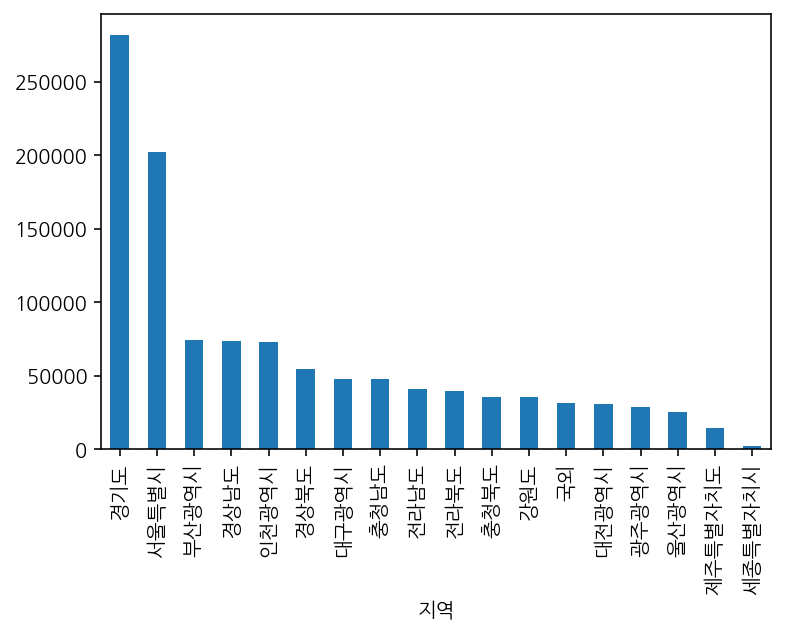
경기도가 상당히 튀지만 아까보단 낫다.
그래프를 보면 알겠지만, 상위를 차지한 지역들은 전부 인구가 많은 지역이다. 각 지역의 인구 수가 원인이므로 큰 의미는 없는 시각화인 셈.
이제 처음에 설정했던 가설을 검증할 차례다.
5. 가설 검증
그 전에 발생 건수가 가장 큰 이혼 사유 데이터를 확인해봤다.
# 발생 건수가 가장 큰 이혼에 대한 데이터
ndf.loc[ndf['발생 건수'] == ndf['발생 건수'].max()]
가설 깨지는 소리 들린다 들려.
하지만. 굴하지 않고. 끝까지 확인해본다.
personality = ndf.loc[ndf['이혼 사유'] == '성격차이']
personality.sort_values(by='발생 건수', ascending=False)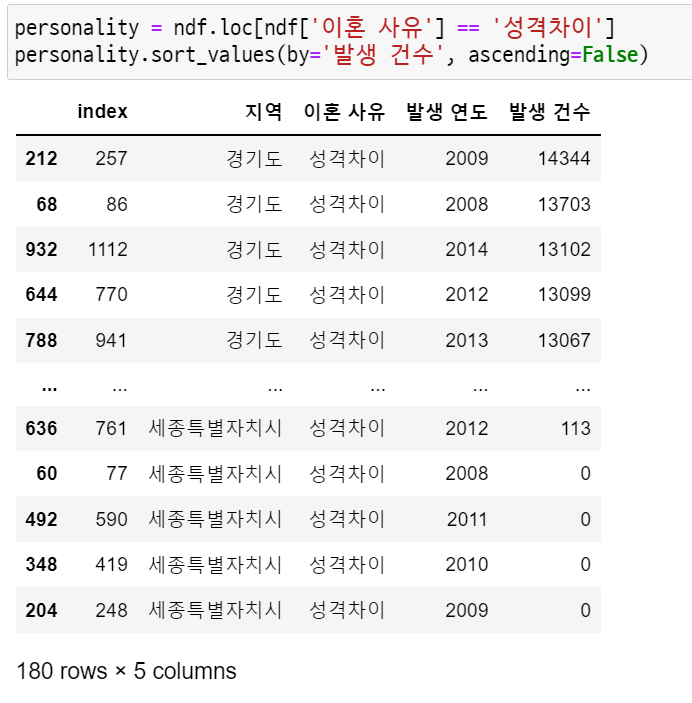
음... 그렇구나. 2009년에 max를 찍었구나.
시각화도 해본다.
ndf.pivot_table(index = '발생 연도', columns = '이혼 사유',
values = '발생 건수', aggfunc = 'sum').plot.bar(figsize=(10,8), title='각 지역의 이혼 사유별 이혼 발생 건수')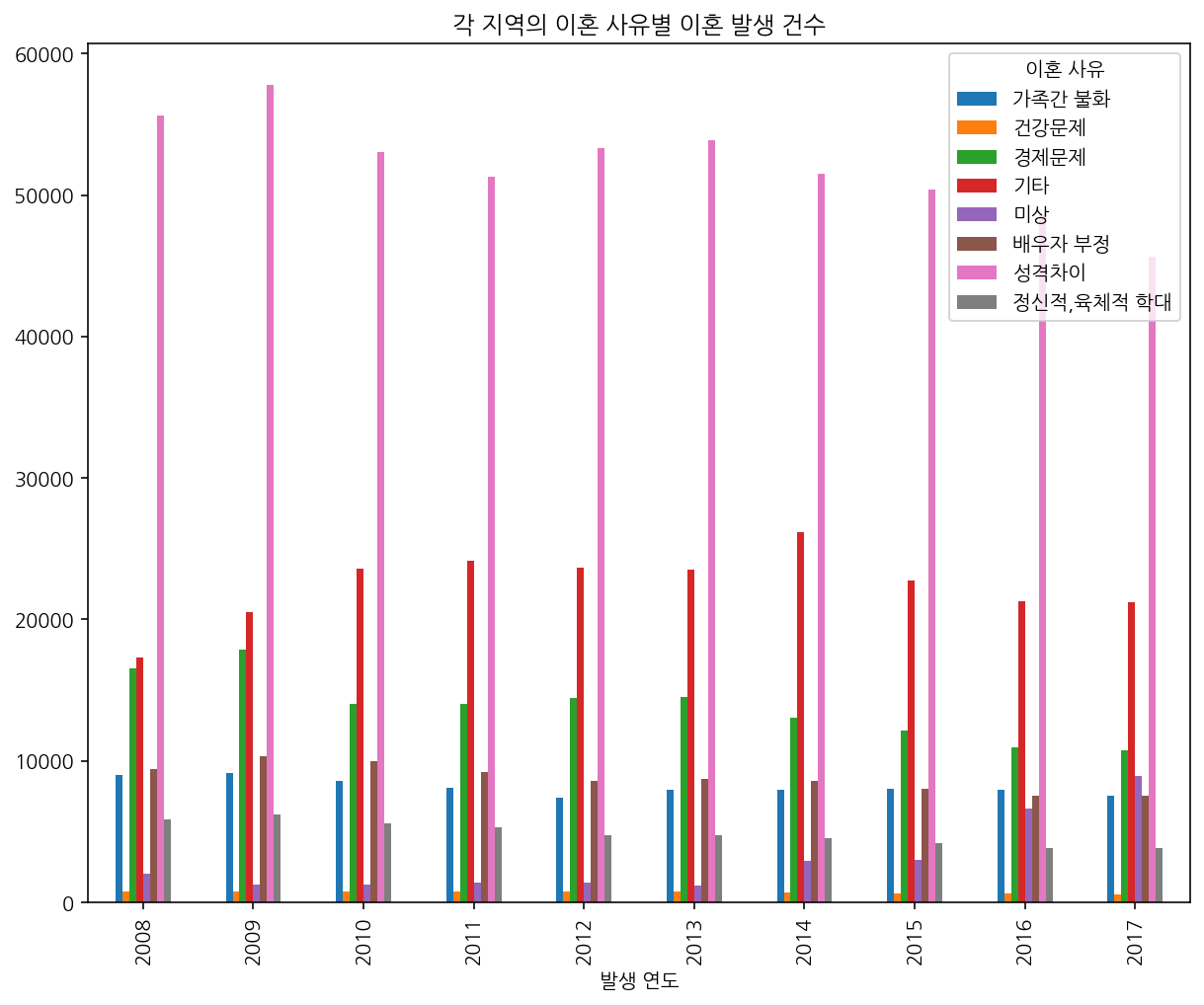
위에서 이미 수치로 확인했지만 시각화를 해보니 더 쉽게 알 수 있다.
과거에는 이혼에 보수적이었으니 최근에 가까워질 수록 성격 차이로 이혼하는 경우가 많아질 것이라는 가설은 틀렸다. 오히려 감소하는 추세이다. 그리고 plot title 이상하게 적었다는 것도 지금 알아챘다. 허허
한 가지 확실한 건 성격 차이로 이혼하는 비율이 월등히 높다는 것인데, 지역 별로 나눠서 살펴봐도 똑같았다.
ndf.pivot_table(index = '지역', columns = '이혼 사유',
values = '발생 건수', aggfunc = 'sum').plot.bar(figsize=(10,4), title='각 지역의 이혼 사유별 이혼 발생 건수')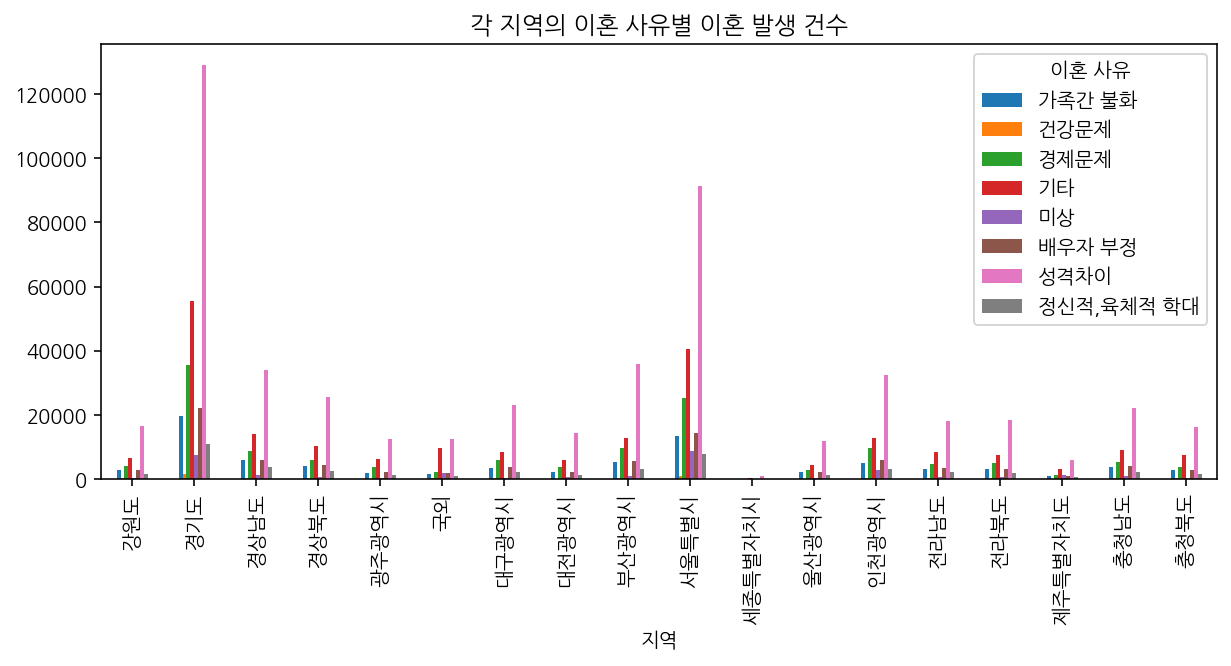
외에도 이혼 사유에 '기타'와 '미상'이 높아진 걸로 미루어보아 최근에는 사생활 보호를 위해 사유를 명확히 밝히지 않은 건가? 정도의 추측이 가능했다.
통계 설명자료에 의하면 이혼 신고서에 작성된 사유가 이혼 사유로 수집되었기 때문이다. 하지만 여러 사유가 중첩되어서 기타나 미상이 된 것일 수도 있으므로 확신할 수는 없다.
쓰면서 생각난 건데 오히려 보수적인 점이 이혼 사유에 작용한 것 아닐까 싶다. 배우자의 부정이나 학대가 있었지만 이혼 신고서 상으로는 성격 차이 때문에 이혼했다고 기입하는 식의.... 이것도 어디까지나 추측이다.
6. 결론
분석한다고 해서 모두 유의미한 분석이 되는 건 아니다.
슬픈 결말이다. 외부 상황(해당 시기의 사건, 이를테면 경제 위기 등)과 이혼율 사이의 인과관계를 파악해 분석하는 건 감당 가능한 스케일이 아니고. 이혼 데이터를 잘 아는 것도 아니고. 재미는 있었지만 분석 결과 면에서는 아쉬움이 남는다.
미드 프로젝트에서는 재밌는 데이터보단 도메인 지식이 있는 데이터로 분석을 진행해야겠다.
기록 끝~.~
