GPT-3가 보이고 싶은 것
큰 모델을 in-context-learning을 하고, 다양한 태스크들에 대해 적은 수의 데이터만을 가지고 학습하는 능력을 가졌다고 가정하였다. GPT-3는 175억개의 파라미터를 autoregressive language model 방식으로 학습하므로써 큰 모델이 in-context learning을 하고, zero, one, few-shot 학습을 통해 파인튜닝만큼의 성능을 실험해보고자 했다. 즉 사전학습 후에 파인튜닝을 하는 최근 흐름과 달리 더 큰 모델을 통해 zero,one,few-shot의 가능성을 보이고자 한것 같다.
GPT-3의 경우 24개가 넘은 nlp 태스크들에 대해서 성능을 평가하고, 그 뿐만 아니라 학습에서 직접적으로 포함 되지 않은 태스크들에 대해서 얼마나 빠르게 적용될 수 있는지 테스트 하기 위해 여러 새로운 태스크들도 테스트 했다.
GPT-3의 경우 3가지 조건 아래서 평가를 시행했다. NLP 태스크를 테스트하는데 있어서 어느정도 규모의 데이터로 학습하고 평가를 할것인가에 대한 부분을 나타낸다.
- few-shot learning: 10~ 100개 정도 예시를 사용
- one-shot learning: 단 1개의 예시 사용.
- zero-shot learning: 단 하나의 예시 없이 언어 모델을 바로 NLP 태스크에 테스트
GPT-3로 파인튜닝을 통해 학습할 수도 있지만 이것을 미래에 맡겨둔다고 한다..
자연어처리 태스크에서 GPT-3는 zero-shot과 one-shot 학습에서 좋은 성능을 얻었으며, few-shot 학습에서는 때때로 SOTA에 비교해도 경쟁력을 가지는 경우도 있었다.
GPT-3는 one-shot, few-shot 학습에서 GPT-3가 적은 수의 데이터에 대해서도 얼마나 빠르게 학습할 수 있는지 테스트 하기 위한 태스크 또는 즉석 추론에서 능숙함을 보여준다. 이때 즉석 추론이단 단 한번 나타난 단어를 보고 그 이후에 문장에서 새로운 단어를 사용하는것과 산수를 하는것을 말한다. 그리고 GPT-3는 사람이 구분하기 어려울만큼 뉴스 기사를 잘 생성해 낸다.
동시에 GPT-3 모델의 크기에도 불구하고 few-shot 학습이 잘 동작하지 않는곳이 있다. 예를들면 NLI(Natural Language Inference), Reading Comprehension등에서 부족한 부분을 보인다. GPT-3의 강점과 약점을 보이면서 few-shot 학습에 대한 연구를 자극하길 원한다.
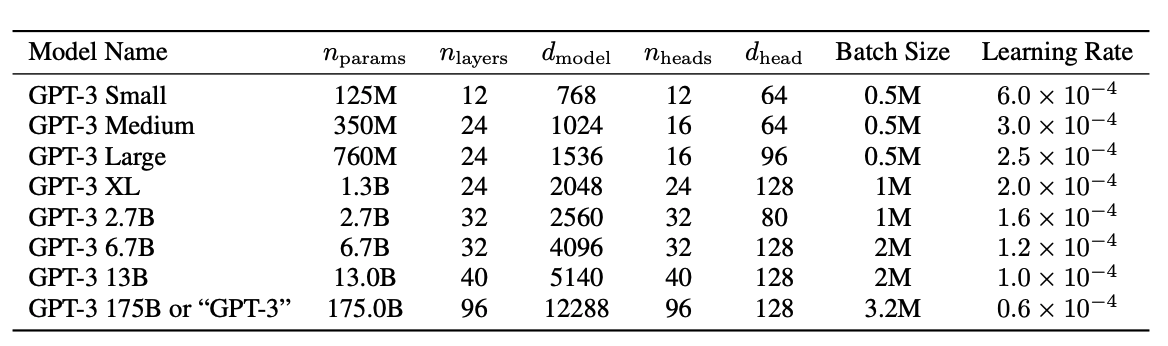
GPT-3는 125M 크기의 모델부터 13B의 모델까지 학습시켜 테스트 했으며, 각각 zero, one, few shot 세팅에 대해 비교하였다.
대체적으로 모델의 크기가 커질수록 제로샷, 원샷, 퓨샷 학습방법에 대해서 성능이 종종 오르는 패턴을 볼수 있고, 이것으로 볼때 큰 모델이 더 숙련된 meta-learner로 판단된다.
이후에는 GPT-3가 접근한 방법과 메소드들을 다루고 GPT-3가 보여주는 능력의 범위를 고려하여, 편향, 공정, 사회적 영향들에 대해 논하고, 우려들에 대해 분석해본다.
