NLP
1.나만의 언어모델 만들기 - 개요

최근 자연어 처리 분야에서 Transformer 등장 이후 다양한 BERT, GPT, ELECTRA 등의 다양한 언어모델들이 나오면서 뛰어난 성능을 보이고 있다. 대부분 구글이나 OpenAI 와 같은 회사들의 경우, 고성능의 컴퓨팅 자원을 바탕으로 매우 큰 파라미터들을
2.나만의 언어모델 만들기 - Wordpiece Tokenizer 만들기

말뭉치 데이터(Corpus)를 바탕으로 언어모델을 만드려고 할때, 말뭉치 데이터를 언어모델에 학습시키기 위해서는 우리가 사용하는 자연어를 벡터로 변환하는 과정이 필요하다. 자연어를 벡터로 변환하기 위해서는 자연어를 토큰화 하고, 토큰화된 단어들에 인덱스를 부여해서,
3.나만의 언어모델 만들기 - BERT Pretrained Language Model (Masked Language Model) 만들기
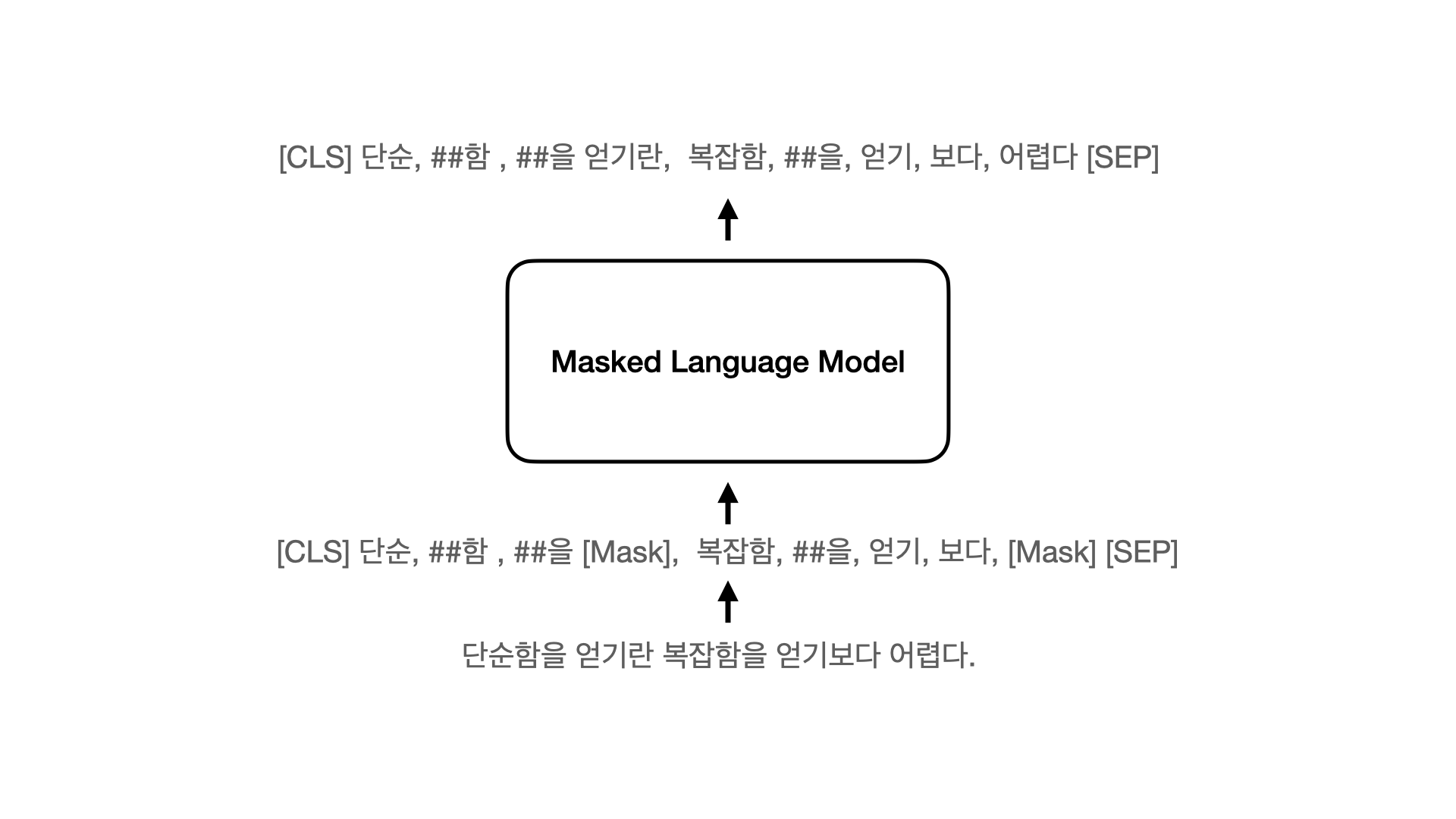
최근 자연어처리에서 많이 사용되는 대표적인 언어모델로 BERT, GPT, ELECTRA가 있습니다. 단계별로 언어모델을 학습하는 과정 학습해보고, Colab 환경에서 직접 학습 시켜보고자 합니다. https://github.com/nawnoes/reformer
4.나만의 언어모델 만들기 - GPT-2 (Autoregressive Language Model) 만들기

이전 포스트에서 Reformer의 Encoder를 이용한 이용한 BERT 스타일의 Masked Language Model을 만들었습니다. 동일하게 Reformer의 Decoder를 이용해 대표적인 Decoder 언어모델인 GPT-2를 Pretraing 시켜보고자 합니다
5.나만의 언어모델 만들기 - korquad 1.0 제출하기

학습시킨 Language Model의 성능 측정을 Korquad 1.0으로 진행하고, 리더보드에 업로드 하기 위해 제출해보도록 한다.korquad 1.0 제출 부분들어오면 아래와 같은 화면이 보인다. CodaLab 계정 만들고, 튜토리얼 숙지. 확인해보니 이전에 만들어
6.심리상담 챗봇 만들기 - React Native를 이용한 챗봇 앱 만들기

심리상담 데이터 세트와 챗봇 데이터 세트를 이용해 학습한 한국어 언어모델들을 이용하여 심리 상담 챗봇을 만들어본다. 이 포스트에서는 react native와 expo를 이용해 채팅 앱을 만들어 본다. react native와 expo는 기본적으로 설치 되어 있는것을
7.심리상담 챗봇 만들기 - KoELECTRA, KoBERT를 이용한 심리상담 대화 인텐트 분류

작성중...🏃♂️
8.Reformer, The Efficient Transformer

Illustrating the Reformer를 보며 정리.리포머 모델을 2020년에 발표된 모델로 기존 트랜스포머 구조를 개선한 모델이다. Local Sensitve Hashing과 Reversible residual network를 이용해 이전 트랜스 포머 보다 더
9.Reformer: LSH Attention
Q와 K 매트릭스의 LSH 해시를 찾는다같은 LSH를 거쳐서 같은 버켓 안에 있는 $k$와 $q$에 대해서 아래 어텐션을 계산한다.충분히 가까운 항목들이 다른 버켓에 빠지지 않도록, LSH를 여러번 반복한다.LSH로 query, key들에 대해 버켓팅버켓에 따라 정렬청
10.Reformer: Reversible Transformer
Illustrating the Reformer를 보며 정리.트랜스포머에서 인코더와 디코더 레이어를 여러개를 쌓을 때, Residual Network에서 역전파를 위해 그래디언트 값들을 저장하고 있다. 이때 저장하고 있는 값들이 매우 많아, 큰 트랜스포머 모델을 사용할
11.Reformer: Chunking
Illustrating the Reformer를 보며 정리.리포머는 피드포워드 레이어의 4K 이상 갈수 있는 고차원 벡터들의 메모리를 줄인다. 피드포워드레이어의 각 부분은 위치와 관계없이 독립적이기 때문에 청크 단위로 잘라서 계산이 가능하다. 따라서 메모리에 올라갈때,
12.GPT-3: 들어가기 전에

GPT-3 들어가기 전에
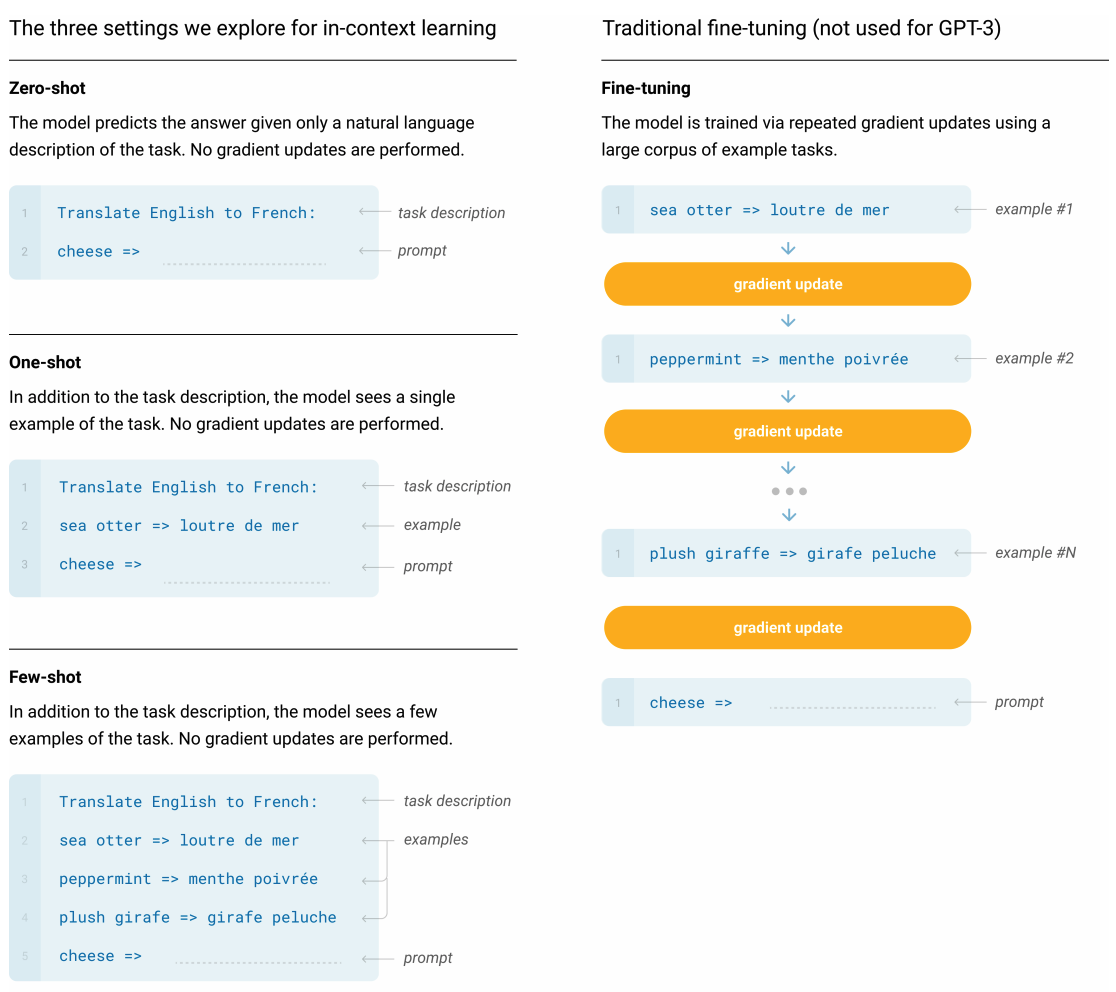
13.GPT-3: 사전학습과 파인튜닝 패러다임을 넘어서
GPT-3, 사전학습과 파인튜닝 패러다임을 넘어서
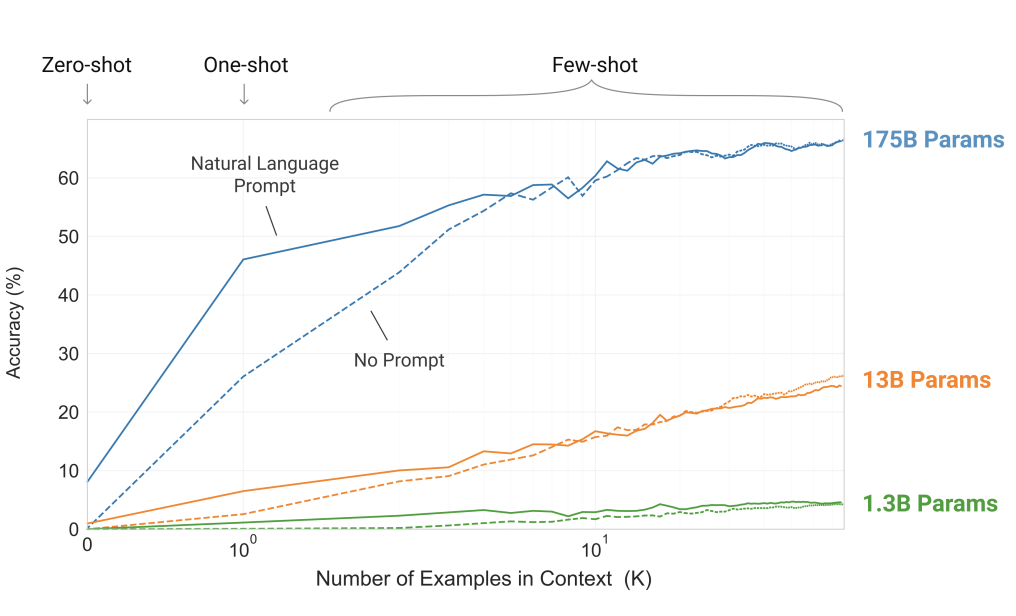
14.GPT-3: GPT-3가 보이고 싶은 것
GPT-3는 175억개의 파라미터를 `autoregressive language model` 방식으로 학습하므로써 큰 모델이 in-context learning을 하고, zero, one, few-shot 학습을 통해 파인튜닝만큼의 성능을 실험해보고자 했다.
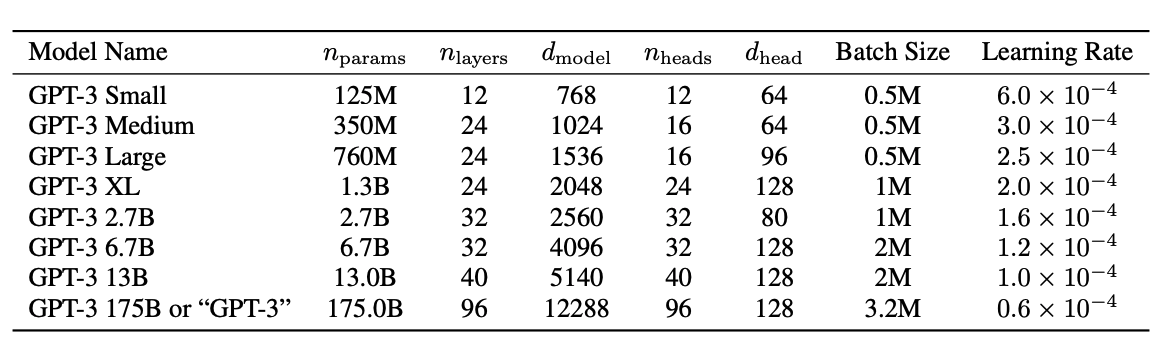
15.GPT-3: 모델
GPT-3의 접근 방법은 기존의 GPT-2의 모델, 학습데이터, 학습 방법 등에서 유사하다. 거기서 확장하여, 모델의 사이즈와 데이터의 사이즈를 확대했으며, 데이터의 다양성을 증가했고, 학습 길이도 증가시켰다.
16.HuggingFace generate 함수 사용해서 문장 생성하기

how to generate text 를 보며 정리 huggingface의 transformer 라이브러리를 보면 GPT2 부분에 generate 함수가 있다. 이 generate 함수를 이용해서 문장 생성 하는데 보다 적은 노력으로 훌륭한 문장을 생성할 수 있다.
17.트랜스포머 기반 자연어처리 모델 간략하게 훑어보기
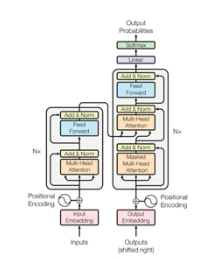
허깅페이스 블로그들을 둘러보다 트랜스포머 모델들에 대해 정리한 글을 찾아 보면서 정리해보도록한다.하이레벨 관점에서 모델들의 차이점을 다루고자 한다. hugging face model 페이지에서 사전 학습된 파일들을 찾아서 테스트 해볼수 있다.허킹갓 페이스..허깅페이스
18.GPT-2 문장 생성 시, 왜 중복이 발생할까

NLP 논문 리뷰 - The Curious case of Neural Text Degeneration을 정리하며 작성.koGPT-2로 학습 시킨 후 문장을 생성할 때, gready search를 통해서 문장을 생성했는데, 문장 생성이 조금 지나면 중복된 문장이 생성이
19.Top-p Sampling (aka. Nucleus Sampling)
How to sample from language models 을 보며 정리GPT-2로 텍스트를 생성하다보면, 랜덤 샘플링이나 Top-k 샘플링 등을 사용해도 문맥이 잘 맞지 않는다고 생각이 된다. 추가로 다른 방법 중 Top-p, Nucleus 샘플링을 찾을 수 있다
20.Beam Search in NLP
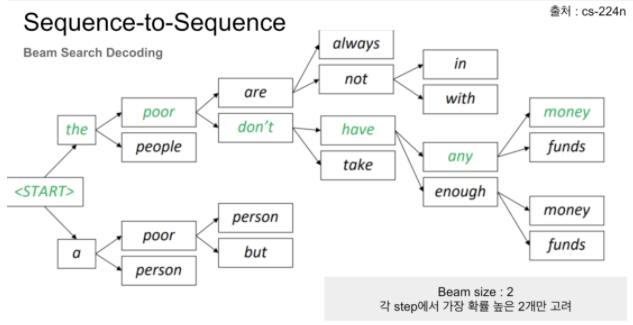
텍스트 생성 문제에 대해서 Greedy Search와 Beam Search을 어떻게 사용하는지 How to Implement a Beam Search Decoder for Natural Language Processing블로그를 보고 정리캡션 생성, 요약, 기계 번역은
21.데이터전처리 - 영어 위키피디아 덤프 텍스트 데이터 얻기
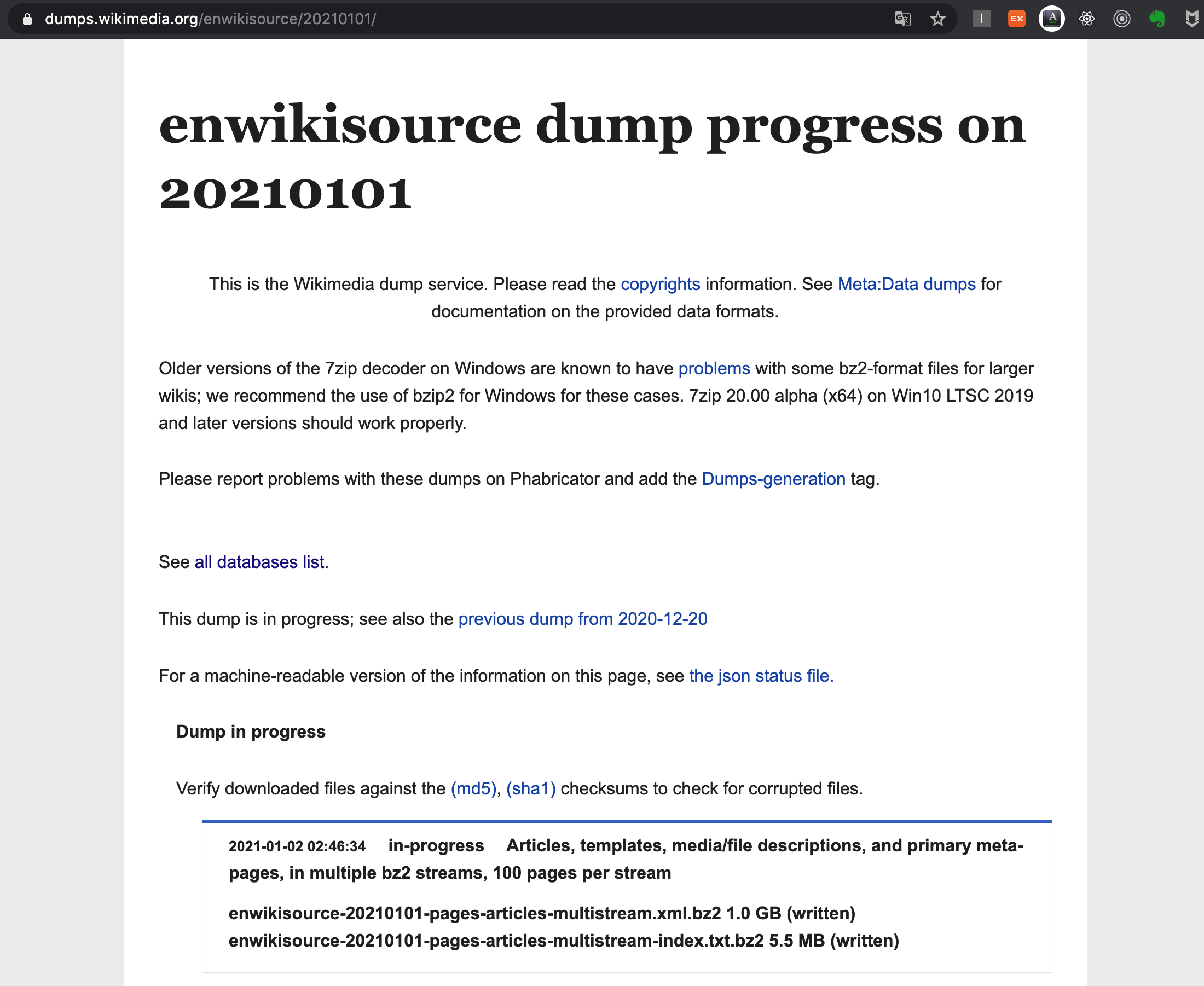
영어 위키피디아 plain text를 얻기 위한 WikiExtractorapertium/WikiExtractor의 경우 문서의 제목 아래에 <pages>와 같은 태그들이 보여 영어 위키피디아의 plain text를 얻는데 불편함이 있었다. 을 사용하여 html 태
22.데이터전처리 - 나무위키 덤프 텍스트 데이터 얻기
파이썬으로 나무위키 JSON 덤프 데이터 파싱하기 이용하여 만든 Namuwiki Extractor 📦Github: nawnoes/NamuwikiExtractor명령형으로 사용가능하게 변경색상코드 제외 정규식 추가kss를 이용한 문장 나누기 추가나무위키 덤프 다운로드
23.Hopfield Network is all you need 살펴보기
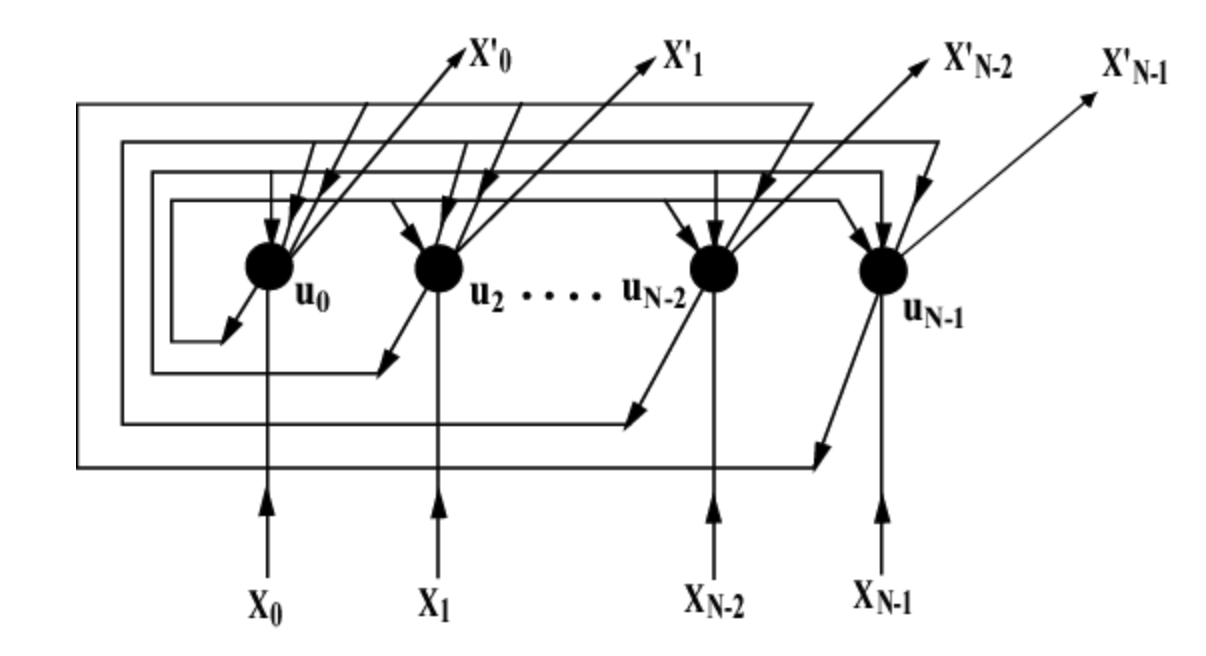
최근 트랜스포머를 사용하다 보니 모델의 크기나 몇가지 제한 사항들을 느끼면서 새로운 모델들을 보고 다른 가능성들이 있는지 살펴보고 싶었습니다. 얼마 전에 페이스북을 게시물을 보다가 홉필드 네트워크가 몇개 안되는 뉴런을 가지고 자율주행하는 게시물을 본 기억이 났고, 인상
24.Transformer로 한국어-영어 기계번역 모델 만들기
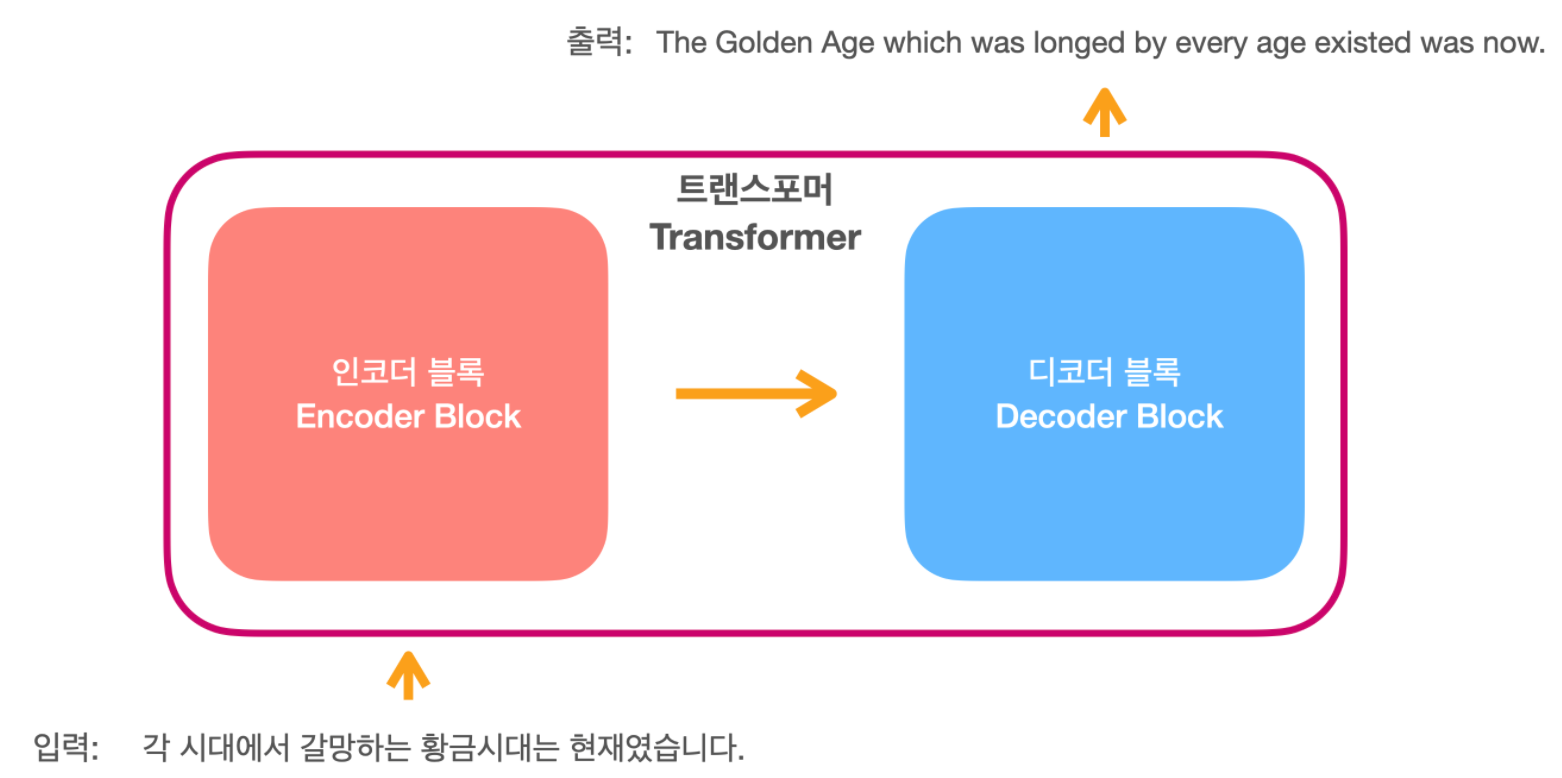
최근에 여러가지 자연어처리 모델들을 다루면서 트랜스포머 기반의 모델들인 BERT, GPT, ELECTRA 등과 같이 다양한 사용하게 되는데, 모델들을 사용하게 되면서 트랜스포머 모델 자체에 대한 직접 구현을 해보고 싶다는 생각을 가지게 되었습니다. 기존에 트랜스포머
25.Performer - RETHINKING ATTENTION WITH PERFORMERS
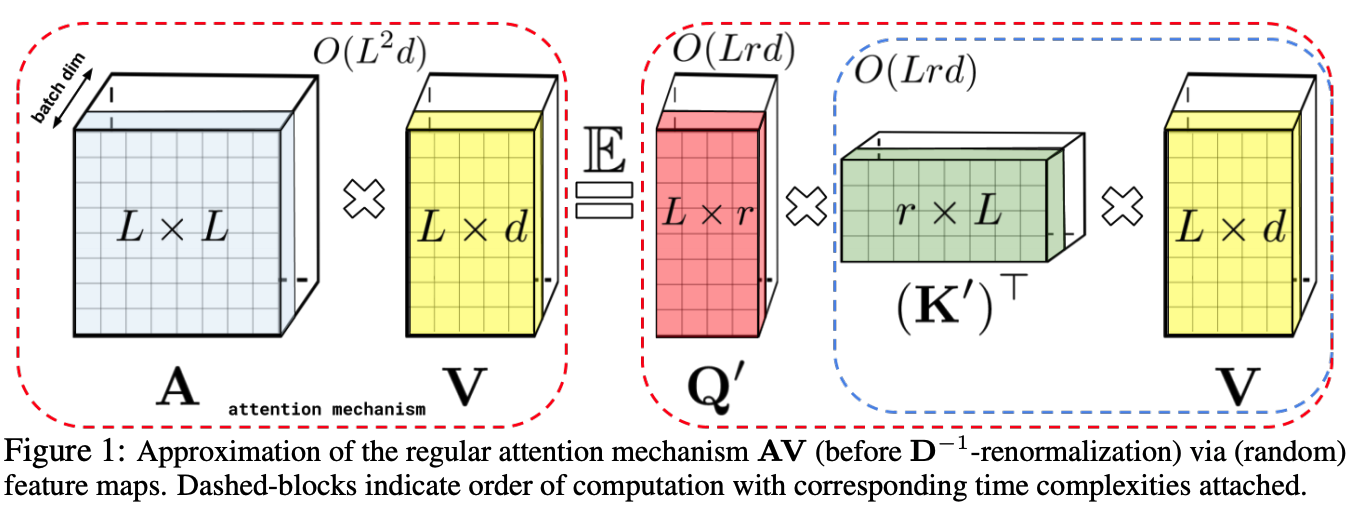
Perforemr 논문에 대해 간략하게 살펴보고자 합니다. performer는 기존의 트랜스포머가 self-attention 계산시에 제곱의 시간 및 공간 복잡도를 가지는 것을 선형으로 변형하여, 트랜스포머의 소프트맥스 어텐션 커널에 근접하고자 하였습니다. Perfor
26.Gradient Accumulation, 큰 모델 학습시 어떻게 배치 사이즈를 늘릴수 있을까?
최근에 파이토치로 모델을 학습하는 경우 단일 GPU로 학습하는 경우 메모리에 제한이 있어 큰 배치사이즈를 가지지 못하는 문제가 있습니다. 모델의 성능향상을 위해 어떻게 하면 더 큰 배치사이즈로 학습할 수 있을지 찾아보다 적용할 만한 부분이 있어 찾아보고 간략하게 정리하
27.Nvidia Apex를 이용한 모델 학습 최적화
Language Model Pretraining을 Colab에서 하다 보면, 학습시간도 단축하고 싶고, 배치 사이즈도 늘려서 학습하고 싶다는 생각이 들게 됩니다.자료를 찾아보다가 위와 같은 문제를 단 몇줄의 코드로 해결해주는 Nvidia의 APEX에 대해 정리
28.사람처럼 대화하는 오픈-도메인 챗봇을 향해, Google Meena
Meena는 멀티턴 오픈 도메인 챗봇으로, 공개되어있는 소셜 데이터들을 수집하여 end-to-end로 만든 챗봇입니다. Meena는 다음 토큰을 예측하는 방식으로 학습하여 perplexity를 최소화 하도록 학습하였습니다. 크기는 2.6B개의 파라미터를 가지는 네트워크
29.10배 더 크고 10배 더 빠른 딥러닝 모델 학습, DeepSpeed
더 크고, 더 빠른 모델을 향해, DeepSpeed.최근에는 모델의 크기들이 점점 더 커지고 단일 GPU에서 학습하기 어려운 환경이 되어갑니다.어디서는 몇백개의 GPU와 TPU를 이용해 자유롭고 빠르게 학습하는 반면 개인 딥러너들은 갈수록 따라잡기 어려워지는 현실.하
30.BlenderBot 2.0: 장기 기억 메모리와 인터넷 검색을 활용한 오픈소스 챗봇
BlenderFackbookAI BlenderBot2.0 글에 대한 정리코드: blenderbot2Facebook에서 만든 장기 기억 메모리와 인터넷 검색을 사용하는 오픈소스 챗봇으로 blender의 두번째 버전이다. 소스와 데이터를 공개했다. 소스: facebookr
31.BigBird, Block Sparse Attention
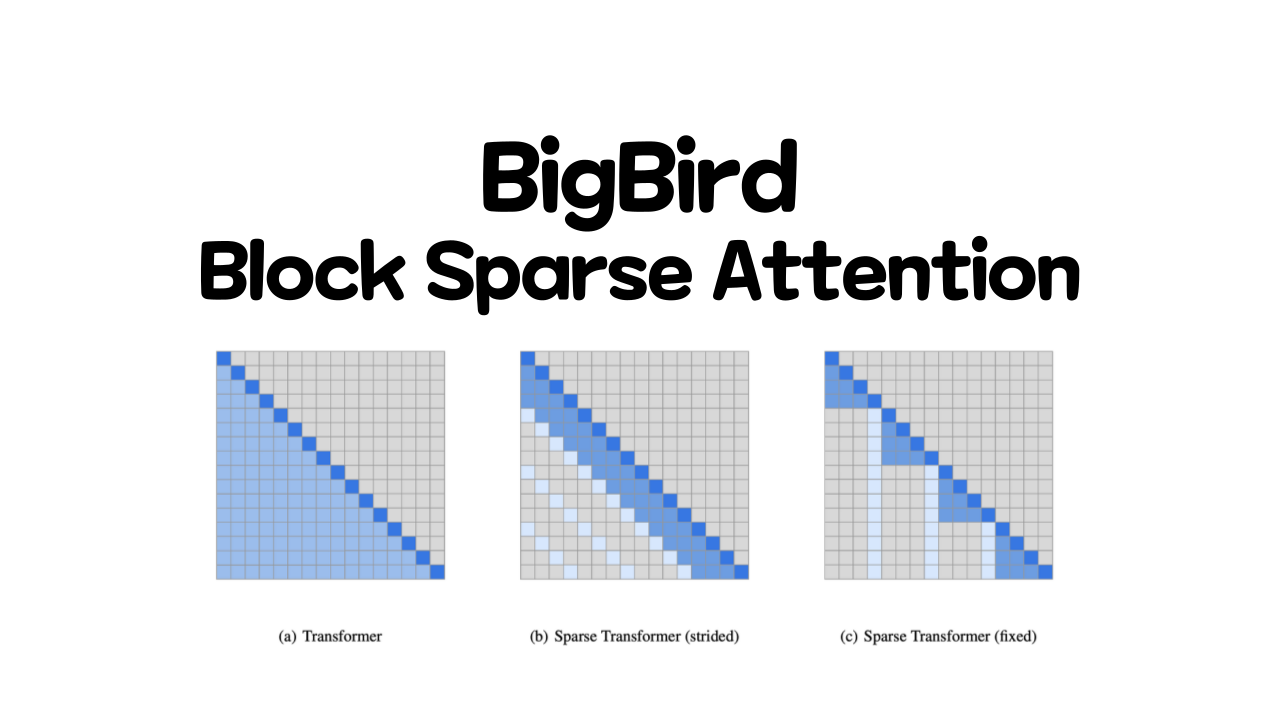
BigBird, Block Sparse Attention
32.ReZero is All You Need, 뉴럴네트워크를 더 깊고 빠르게 학습하는 방법

딥 뉴럴 네트워크는 여러 분야에 걸쳐서 많은 성능 향상을 가져왔지만 종종 기울기가 사라지거나 과도하게 커지거나 하는 문제가 발생한다. 특히 12 레이어를 초과하고 많은 데이터셋과 컴퓨팅 자원이 필요한 트랜스포머 모델들도 이런한 문제에서 예외는 아니며, 저자들은 비효율적
33.Billion 단위의 언어모델을 학습시키기 위한 방법: Megatron-LM

최근 언어모델에서는 큰 트랜스포머 모델을 학습하는게 중요하다. 그러나 매우 큰 모델을 학습하는데는 많은 제약사항들이 따른다.Megatron-LM 논문에서는 매우 큰 트랜스포머 모델을 학습하기 위한 테크닉들을 보인다. intra-layer model 병렬화를 이용해 쉽
34.Pytorch wandb (Weight & Biases) 적용

Pytorch Wandb (Weight & Biases) 적용 딥러닝 모델을 학습하다가 보면 Loss나 필요한 Metric, 평가지표들을 그래프로 시각화해서 보는 방법이 필요하다. 많이 사용하는 방법으로는 텐서보드나 파이썬에서 제공하는 모듈들을 사용해 표현 하는 방법들
35.DeepSpeed Pipeline Parallelism
딥스피드에서 사용하는 Pipeline Parallelism에 대해 정리https://www.deepspeed.ai/tutorials/pipeline/ 문서 참조딥스피드 v0.3에서부터 pipeline paraelleism을 지원한다. Pipeline Paral
36.WebGPT: Browser-assisted question-answering with human feedback

OpenAI 에서 최근에 발표한 새로운 버전의 GPT. 텍스트 베이스의 웹 브라우징 환경을 통해서 GPT3를 파인튜닝 하고, 긴 맥락을 가진 질문에 대해서 답을 할수 있는 모델을 제안했다. 이러한 과정에서 이미테이션 러닝이나 강화학습의 개념을 사용였다. 모델의 평가는
37.Faiss 시작하기

최근에 DPR, RAG, RETRO, FiD 등을 보면서 Retrieval에 대한 내용들이 많이 나온다. faiss에 대해 살펴보고자 한다.faiss getting started 참고faiss는 facebook research에서 개발한, dense vector들의 클
38.RETRO: Improving language models by retrieving from trillions of tokens

Trillion단위의 토큰 데이터 베이스로 구성된 retrieval system을 이용한 언어 모델.Retrieval-Enhanced Transformer(RETRO)를 사용.25배 적은 파라미터(7B)로 GPT-3와 Jurassic-1과 비슷한 성능을 얻었다.Ret
39.UL2, Unifying Language Learning Paradigms

현재까지의 언어모델들은 특정한 유형에 맞춰져 있다. 하지만 어떤 구조가 가장 적합한지, 어떤 세팅이 되어야 하는지 아직 정해진 것들이나 업계 전반에 합의된 것은 없다. 이 논문에서 pretraining을 위한 통합된 프레임워크를 보이고자 한다.
40.What Language Model to Train if You Have One Million GPU Hours?

100만 A100 GPU 시간을 사용할수 있을때 100B+의 모델을 학습하기 위한 가장 좋은 구조와 학습 세팅은 무엇인가?
41.ALiBi Postion Embedding

매우 간단하면서도 쉽게 적용가능한 Ralative position embedding의 한 종류인 ALiBi
42.AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2seq Model

Amazon에서 공개한 20B encoder-decoder model
43.Deepmind Sparraw: Improving alignment of dialogue agents via targeted human judgements

외부 정보를 활용하는 대화모델인 Sparrow를 공개했다. Sparrow는 prompted language model 베이스라인과 비교해서 보다 정확하고 무해하며 사람에게 도움이 되는 대화 에이전트이다. Sparrow는 human feedback으로부터 강화학습을 적용