개요
Meena는 멀티턴 오픈 도메인 챗봇으로, 공개되어있는 소셜 데이터들을 수집하여 end-to-end로 만든 챗봇입니다. Meena는 다음 토큰을 예측하는 방식으로 학습하여 perplexity를 최소화 하도록 학습하였습니다. 크기는 2.6B개의 파라미터를 가지는 네트워크를 학습했다고 합니다.
당시 Meena도 큰 모델로 여겨졌는데, 최근 GPT-3와 같은 모델의 경우 가장 큰모델이 175B의 파라미터를 가지는것을 보면 최근 추세가 확실히 큰 모델로 가는 경향이 있는것을 알수 있습니다.
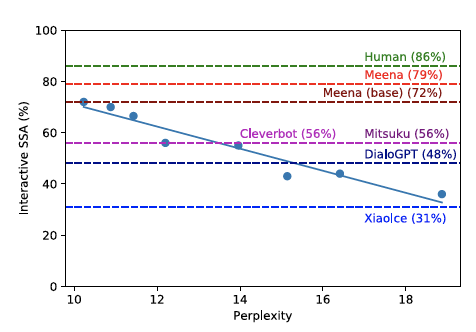
위 내용 더하여 Meena는 새로운 평가 방법을 제안합니다. SSA(Sensibleness and Specificity Average) 라는 새로운 평가 방법 입니다.얼마나 대화가 구체적이고 감성적인지 평가하는 지표로 최근에는 이루다와 같은 챗봇의 평가지표로도 사용되었습니다.
위의 SSA 지표와 Perplexity와 큰 상관관계를 가지는것을 발견했습니다. 즉 낮은 Perplexity를 가진 모델의 경우 SSA 점수도 높은 것을 알수 있습니다.
Meena 살펴보기
최근 end-to-end 대화 모델의 경우 크게 2가지 카테고리를 가집니다. 한 경우는 사람이 디자인한 컴포넌트로 구성된 복잡한 모델이고, 다른 경우는 거대한 신경망을 이용한 모델입니다.
Meena의 경우 단순하게 보다 큰 모델을 학습시키고자 하였습니다. 더 많은 학습데이터와 더 많은 파라미터를 이용했습니다. 저자들은 Meena를 통해 큰 모델이 오픈 도메인 분야에서 사람과 같은 답변을 생성할수 있다는 것을 보였습니다.
학습 데이터
Meeena의 학습데이터는 인터넷 상에서 여러 사람들이 대화한 메세지 트리를 수집하여 학습 데이터로 사용했습니다.
학습 데이터에 사용된 메세지는 아래과 같이 몇가지 기준을 가지고 필터링 하였습니다.

전체적인 학습데이터는 341GB 크기의 텍스트 데이터를 사용했습니다. 이전 모델인 GPT-2가 40GB의 데이터를 사용한 것과 비교해 보았을때, 큰 차이를 가지는 데이터를 사용한것으로 보입니다.
Vocab과 Tokenizer
Meena에서는 Sentencepiece library를 이용해 8k의 vocab을 사용했습니다. 8k가 다른 모델들에 비해 사용되는 수가 적지만 저자들은 경험적으로 8K개의 vocab으로도 충분히 문장을 생성해내는데 이상 없다고 합니다.
모델 구조
Meena에서 사용한 Transformer 모델은 Evolved Transformer입니다. 기존의 인코더만 사용한 모델, 디코더만 사용한 모델에서 벗어나 1개의 인코더블록과 13개의 디코더블록을 이용해 모델을 만들었습니다.
가장 뛰어난 성능을 가진 모델의 경우 10.2 perplexity를 가지며, 바닐라 트랜스포머를 사용한 경우 10.7 perplexity를 가집니다. 학습을 위한 스텝을 동일하게 738K 스텝을 학습했습니다.
2560 hidden size와 32 attention head를 사용했고, 토큰 길이는 기존의 GPT계열이 1024나 2048 토큰, BERT 계열이 512 토큰을 사용한것과 다르게 128 토큰을 사용했습니다.
학습 디테일
Meena의 학습은 2048개의 TPU 코어를 가진 TPU-v3 Pod를 이용해 30일 간 학습했다고 합니다. 341GB의 데이터 크기에도 불구하고 2.6B 크기의 모델은 데이터에 대해 오버피팅 할수 있다고 합니다. 그래서 0.1 dropout을 어텐션 부분과 feedfoward 부분에 적용했습니다. 그리고 메모리를 절약하기 위해 Adafactor optimizer를 사용하고 초기화를 0.01로 했습니다.
문장 생성을 위한 디코딩 방법
디코더 모델의 경우 다양한 디코딩 방법을 사용하게 됩니다. Meena에서는 낮은 Perplexity를 가진 모델을 가지고 단순한 샘플링(Sampling) 방법과 랭크 디코딩(Rank Decoding) 방식을 통해 다양하면서도 높은 수준의 답변을 생성하는것을 보였습니다.
Sample & Rank 문장 생성 방법
첫번째로, 개의 독립적인 후보들을 랜덤 샘플링(Plain Random Sampling)을 통해 샘플링합니다. 샘플링 시에는 temperature $T$를 사용해 샘플링을 합니다.
두번째는, 위에서 샘플링된 후보들 중에서 가장 높은 확률 값을 지는 후보를 선택하게 됩니다.
빔서치를 이용한 문장 생성의 경우 반복적이면서 흥미롭지 않은 답변을 생성하며, Sample & Rank 방식을 사용해 문장을 생성하는 경우 흥미롭고 다양한 답변을 생성하는 것을 볼 수 있습니다.

따라서 중요한 것은 모델이 낮은 Perplexity을 가지는 고, 높은 Temperature 값을 이용해 다음 토큰을 생성하는게 보다 사람다운 답변을 생성하는데 중요한 것임을 알 수 있습니다.

Meena에서 사용한 Decoding 설정
Temperature 란?
Temperature 는 하이퍼 파라미터의 한 종류 입니다. 문장 생성에서 다음 토큰을 생성하고자할때, 다음 토큰들의 확률 분포 를 regulation 하는 하이퍼파라미터입니다.
적용하는 방법으로는 Softmax 전에 모델의 결과 값으로 나온 logit 를 로 나누어 줍니다.
Temperature값에 따른 특성
- 의 경우, 값들이 수정 되지 않습니다.
- 값이 큰 경우 문맥적으로 희귀한 토큰을 선호.
- 값이 작은 경우 일반적으로 많이 사용하는 단어들이 선택되게 됩니다. 이러한 경우 안전한 문장을 생성하지만 구체적이지 못한 결과를 보입니다.
결과 및 마무리
Meena 에서는 기존과는 다른 평가 지표인 SSA를 소개하였습니다. 모델이 조금 더 인간 다우면서도 구체적이고 적절한 답변을 생성하는지에 대한 평가 지표로 사용했습니다.
SSA는 나아가 유머나 다른 인간적인 평가지표들에 대한 추가가 필요할 것으로 보입니다.
그리고 인코더와 디코더를 결합한 모델 구조, Beam Search대신 Top-K와 Temperature를 사용해 문장을 생성한 부분 등에서 인상적이었던 논문이었습니다.
