Masked Language Model 학습
최근 자연어처리에서 많이 사용되는 대표적인 언어모델로 BERT, GPT, ELECTRA가 있습니다. 단계별로 언어모델을 학습하는 과정 학습해보고, Colab 환경에서 직접 학습 시켜보고자 합니다.
언어모델이란?
언어모델이란 주어진 문장, 단어를 바탕으로 단어에 확률을 부여하는 모델을 말합니다.
MLM(Masked Language Model) 이란?
마스킹된 언어모델로, 입력으로 사용하는 문장의 토큰중 15%의 확률로 선택된 토큰을 [MASK] 토큰으로 변환시키고, 언어모델을 통해 변환되기전 [MASK] 토큰을 예측하는 언어모델입니다.
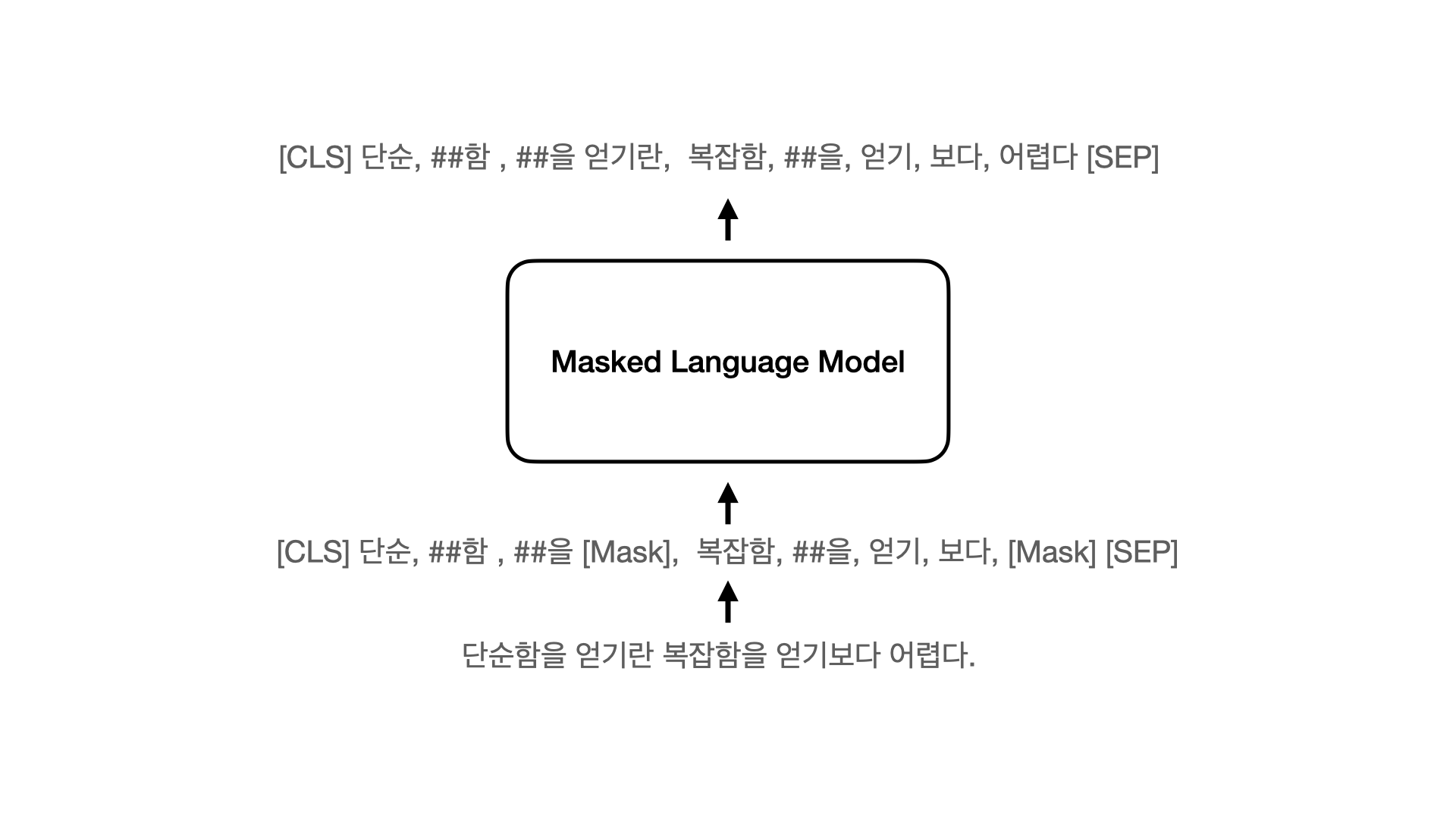
마스킹 과정
처음에 MLM의 개념을 본다면 다소 구현하는데 의아함이 들기도 하고 그 과정이 명확하게 이해가기 어려운 부분이 있습니다
아래의 함수를 통해 들어온 입력에 대해서 mlm_probability에 따라 [MASK]로 변환할 토큰을 선택합니다. 선택된 토큰중 80%는 [MASK]토큰으로 변환하고 10%는 랜덤 토큰으로 변경하며, 10%는 변환하지 않습니다.
def mask_tokens(self, inputs: torch.Tensor, mlm_probability=0.15, pad=True):
labels = inputs.clone()
# mlm_probability은 15%로 BERT에섯 사용하는 확률
probability_matrix = torch.full(labels.shape, mlm_probability)
special_tokens_mask = [
self.tokenizer.get_special_tokens_mask(val, already_has_special_tokens=True) for val in labels.tolist()
]
probability_matrix.masked_fill_(torch.tensor(special_tokens_mask, dtype=torch.bool), value=0.0)
if self.tokenizer._pad_token is not None:
padding_mask = labels.eq(self.tokenizer.pad_token_id)
probability_matrix.masked_fill_(padding_mask, value=0.0)
masked_indices = torch.bernoulli(probability_matrix).bool()
labels[~masked_indices] = -100 # We only compute loss on masked tokens
# 80% of the time, we replace masked input tokens with tokenizer.mask_token ([MASK])
indices_replaced = torch.bernoulli(torch.full(labels.shape, 0.8)).bool() & masked_indices
inputs[indices_replaced] = self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token)
# 10% of the time, we replace masked input tokens with random word
indices_random = torch.bernoulli(torch.full(labels.shape, 0.5)).bool() & masked_indices & ~indices_replaced
random_words = torch.randint(len(self.tokenizer), labels.shape, dtype=torch.long)
inputs[indices_random] = random_words[indices_random]
return inputs, labelsVocab & Tokenize
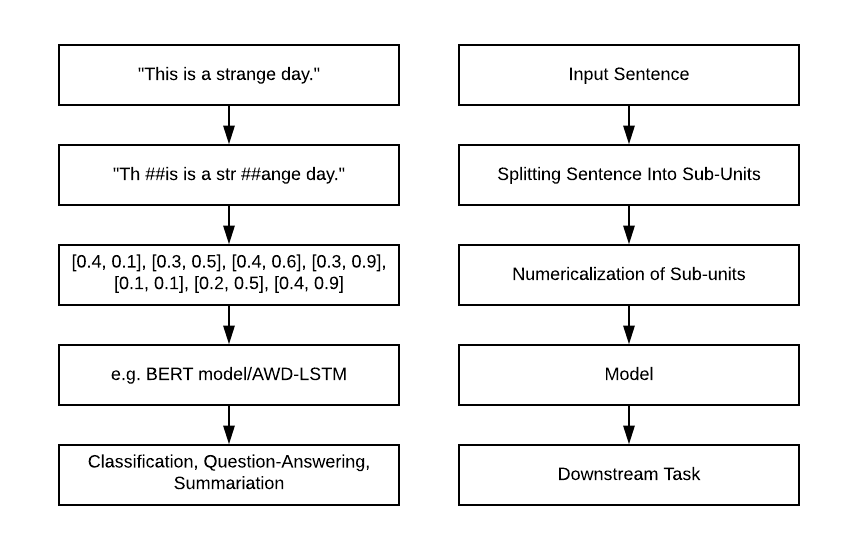
이전 포스트에서 워드피스 기반의 버트 토크나이저를 만들어보았습니다. 토크나이저는 자연어를 토큰으로 나누는데 중요한 역할을 합니다. 그중 워드피스 토크나이저의 경우 Subword 기반의 토크나이저인 Byte Pair Encoding의 한 종류입니다. 이 포스트에서 앞에서 만든 토크나이저를 사용하며, 다른 토크나이저를 사용해도 무방합니다.
Data - Kowiki
사전 학습 시키고자 하는 데이터를 준비합니다. 제가 언어모델을 학습하기 위해 사용하는 데이터는 한국어 위키피디아 데이터를 사용했습니다.
KoWiki 데이터 예시
시작토큰을 [CLS]로, 문장별 구분을 [SEP]를 사용해 최대 512 토큰의 개수로 데이터를 만들었습니다. 버트의 경우 2문장을 사용하여, pretraining 데이터를 준비했지만, 그와는 조금 다르게 긴문단에 대해서 학습해보았습니다.
[CLS] 수학은 숫자 세기, 계산, 측정 및 물리적 대상의 모양과 움직임을 추상화하고, 이에 논리적 추론을 적용하여 나타났다.이런 기본 개념들은 고대 이집트, 메소포타미아, 고대 인도, 고대 중국 및 고대 그리스의 수학책에서 찾아볼 수 있다. [SEP] 그리고, 유클리드의 원론에서는 엄밀한 논증이 발견된다. [SEP] 이런 발전은 그 뒤로도 계속되어, 16세기의 르네상스에 이르러서는 수학적 발전과 과학적 방법들의 상호 작용이 일어나, 혁명적인 연구들이 진행되며 인류 문명에 큰 영향을 미치게 되었다. [SEP] 그리고, 이는 현재까지도 계속되고 있다. [SEP] 오늘날 수학은 자연과학, 공학, 의학뿐만 아니라, 경제학 등의 사회과학에서도 중요한 도구로서도 사용된다. [SEP] 수학을 이런 분야들에 적용한 응용수학은 그 결과로써 수학 자체의 발전을 이끌고 새로운 분야들을 낳았다. [SEP] 응용이 아닌 수학 자체의 아름다움과 재미를 추구하며 연구하는 것을 순수수학이라 하는데, 긴 시간이 지난 뒤에 순수수학적 연구를 다른 분야에 응용할 방법이 발견된 경우도 많았다고 한다. [SEP] 대부분 자료를 보면, "mathematics"는 "수리적인"이라는 뜻을 가진 라틴어 mathmaticus와 그리스어 mathematikos에서 유래되었거나, "학식있는"을 뜻하는 mathema와 "배우다"를 뜻하는 manthanein에서 유래되었다고 한다. [SEP] 줄여서 "math"라고 표현하기도 한다. [SEP] 수학은 기원전 600년 경에 살았던 탈레스로부터 시작됐다. [SEP] 하지만 탈레스가 태어나기 전에도 수학을 연구한 사람이 있을 수도 있기 때문에, 인류의 역사와 더불어 시작되었다고 할 수 있다. [SEP] 교역•분배•과세 등의 인류의 사회 생활에 필요한 모든 계산을 수학이 담당해 왔고, 농경 생활에 필수적인 천문 관측과 달력의 제정, 토지의 측량 또한 수학이 직접적으로 관여한 분야이다. 고대 수학을 크게 발전시킨 나라로는 이집트, 인도, 그리스, 중국 등이 있다. [SEP] 그 중에서도 그리스는 처음으로 수학의 방정식에서 변수를 문자로 쓴 나라이다. [SEP] 한국의 수학은 약 1,500년 전부터 기록으로 보이기 시작한다. [SEP] 신라 시대에 수학을 가르쳤으며, 탈레스가 최초로 발견한 일식과 월식을 예측할 정도로 발달했다. [SEP]
[CLS] 조선 시대에 훈민정음을 창제한 세종 대왕은 집현전 학자들에게 수학 연구를 명하는 등, 조선의 수학 수준을 향상시키기 위해서 많은 노력을 기울였다.하지만 임진왜란으로 많은 서적들이 불타고, 천문학 분야에서 큰 손실을 입었다. [SEP] 조선 후기의 한국의 수학은 실학자들을 중심으로 다시 발전하였고, 새로운 결과도 성취되었다. [SEP] 수학의 각 분야들은 상업에 필요한 계산을 하기 위해, 숫자들의 관계를 이해하기 위해, 토지를 측량하기 위해, 그리고 천문학적 사건들을 예견하기 위해 발전되어왔다. [SEP] 이 네 가지 목적은 대략적으로 수학이 다루는 대상인 양, 구조, 공간 및 변화에 대응되며, 이들을 다루는 수학의 분야를 각각 산술, 대수학, 기하학, 해석학이라 한다. [SEP] 또한 이 밖에도 근대 이후에 나타난 수학기초론과 이산수학 및 응용수학 등이 있다. [SEP] 산술은 자연수와 정수 및 이에 대한 사칙연산에 대한 연구로서 시작했다. [SEP] 수론은 이런 주제들을 보다 깊게 다루는 학문으로, 그 결과로는 페르마의 마지막 정리 등이 유명하다. [SEP] 또한 쌍둥이 소수 추측과 골드바흐 추측 등을 비롯해 오랜 세월 동안 해결되지 않고 남아있는 문제들도 여럿 있다. [SEP] 수의 체계가 보다 발전하면서, 정수의 집합을 유리수의 집합의 부분집합으로 여기게 되었다. [SEP] 또한 유리수의 집합은 실수의 집합의 부분집합이며, 이는 또다시 복소수 집합의 일부분으로 볼 수 있다. [SEP] 여기에서 더 나아가면 사원수와 팔원수 등의 개념을 생각할 수도 있다. [SEP] 이와는 약간 다른 방향으로, 자연수를 무한대까지 세어나간다는 개념을 형식화하여 순서수의 개념을 얻으며, 집합의 크기 비교를 이용하여 무한대를 다루기 위한 또다른 방법으로는 기수의 개념도 있다. [SEP] 수 대신 문자를 써서 문제해결을 쉽게 하는 것과, 마찬가지로 수학적 법칙을 일반적이고 간명하게 나타내는 것을 포함한다. [SEP] 고전대수학은 대수방정식 및 연립방정식의 해법에서 시작하여 군, 환, 체 등의 추상대수학을 거쳐 현대에 와서는 대수계의 구조를 보는 것을 중심으로 하는 선형대수학으로 전개되었다. [SEP] 수의 집합이나 함수와 같은 많은 수학적 대상들은 내재적인 구조를 보인다. [SEP] Reformer
2020년에 발표 된 모델로, LSH(Local Sensitive Hashing), RevNet(Reversivle Residual Network), Chunked Feed Forward Layer, Axial Positional Encodings을 통해서 트랜스포머의 메모리 문제를 개선하고자 시도한 모델입니다.
이 글에서는 lucidrains/reformer-pytorch 을 이용해 언어모델을 학습하고자 합니다
Transformer의 단점
attention 계산: 길이 L을 가진 문장의 어텐션을 계산할 때, O(L^2) 의 메모리와 시간 복잡도를 가진다.많은 수의 레이어: N개의 레이어틑 N배의 많은 메모리를 사용한다. 그리고 각각의 레이어는 역전파 계산을 위해 그 값들을 저장해둔다.Feed Forward 레이어의 크기: Feed Forward 레이어가 Attention의 Activation 깊이 보다 더 클 수 있다.
Reformer
LSH(Local Sensitive Hashing): Dot-Product 사용하는 기존의 어텐션을 locality-sensitive hashing을 사용해 대체하면 기존의 을 로 개선RevNet: 트랜스포머에서는 Residual Network에서 backpropagation를 위해 gradient 값을 저장하고 있다. reversible residual network을 이용하여
메모리 문제를 계산 문제로 바꾸어 메모리를 문제를 개선Chunk: Feed Forward layer의 각 부분은 위치와 관계 없이 독립적이기 때문에 청크 단위로 잘라서 계산할 수 있다. 이 점을 이용하여 메모리에 올릴 때 청크 단위로 메모리에 올려, 메모리 효율을 개선.Axial Positional Encoding: 매우 큰 input sequence에 대해서도 positional encoding을 사용할 수 있게 하는 방법.
Masked Language Model Pretraining
MLM을 Pretraining 하는 과정에 대해 설명합니다.
모델설정
- 모델의 토큰 길이 : max_len = 512
- 학습을 위한 배치사이즈: batch_size = 128
- 모델의 dimension : dim = 512
- 인코더 레이어 수 : depth = 6
- 멀티헤드어텐션 헤드수 :heads = 8
Pretraining 코드
학습을 위한 config와 tokenizer, dataset을 불러오고 ReformerLM을 통해 모델을 불러옵니다. 그후 ReformerTrainer를 이용해서 MLM을 Pretraining 합니다.
def main():
torch.manual_seed(9)
# Config
config = ModelConfig(config_path='../config/mlm/mlm-pretrain-small.json').get_config()
# Tokenizer
tokenizer = BertTokenizer(vocab_file=config.vocab_path, do_lower_case=False)
# dataset = NamuWikiDataset(tokenizer, max_len, path=mini_data_path)
dataset = DatasetForMLM(tokenizer, config.max_seq_len, path=config.data_path)
# Model
model = ReformerLM(
num_tokens=tokenizer.vocab_size,
dim=config.dim,
depth=config.depth,
heads=config.n_head,
max_seq_len=config.max_seq_len,
causal=False # auto-regressive 학습을 위한 설정
)
trainer = ReformerTrainer(dataset, model, tokenizer,model_name=config.model_name, checkpoint_path=config.checkpoint_path,max_len=config.max_seq_len, train_batch_size=config.batch_size,
eval_batch_size=config.batch_size)
train_dataloader, eval_dataloader = trainer.build_dataloaders(train_test_split=0.1)
trainer.train(epochs=config.epochs,
train_dataloader=train_dataloader,
eval_dataloader=eval_dataloader,
log_steps=config.log_steps,
ckpt_steps=config.ckpt_steps,
gradient_accumulation_steps=config.gradient_accumulation_steps)Loss 계산
ReformerLM을 통해 나온 output 값을 CrossEntropyLoss를 사용해서, 마스킹된 토큰에 대해서만 Loss를 계산합니다. 마스킹된 토큰에 대해서만 Loss를 계산 하기 때문에 이후 ELECTRA와 같은 모델에서는 다른 방법을 시도하기도 합니다.
loss_fn = nn.CrossEntropyLoss()
# Reformer MLM output
output = self.model(inputs, input_mask=inputs_mask)
# only calculating loss on masked tokens
loss_mx = labels != -100
output = output[loss_mx].view(-1, self.tokenizer.vocab_size)
labels = labels[loss_mx].view(-1)
loss = loss_fn(output, labels)학습결과
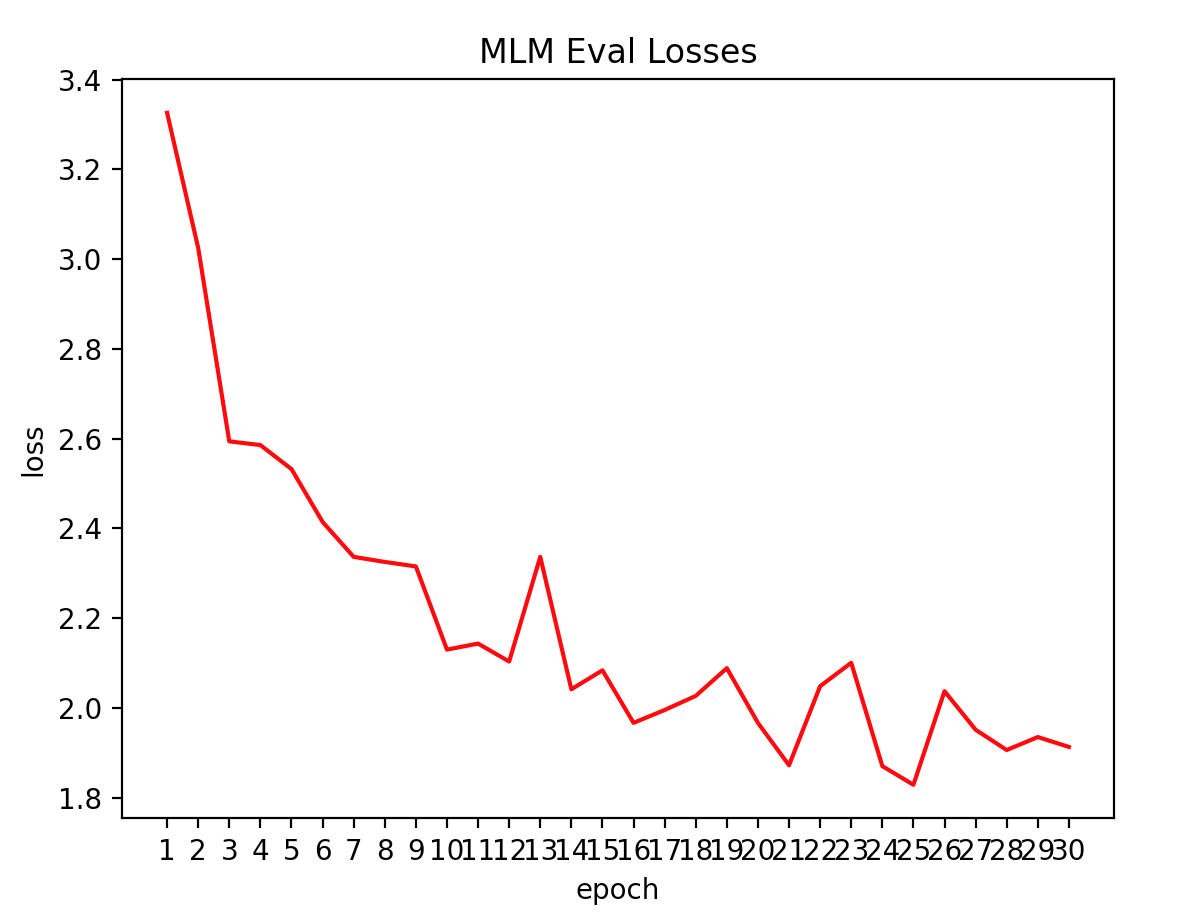
평가 데이터에 대해 Loss가 떨어지는것을 볼수 있습니다.
Korquad 테스트
학습된 언어모델이 어느정도 성능을 가졌는지 평가하기 위해 Korquad1.0에 대해 파인 튜닝해봅니다.
KorQuAD 1.0은 한국어 Machine Reading Comprehension을 위해 만든 데이터셋입니다. 모든 질의에 대한 답변은 해당 Wikipedia article 문단의 일부 하위 영역으로 이루어집니다. Stanford Question Answering Dataset(SQuAD) v1.0과 동일한 방식으로 구성되었습니다.
MRC Model
class ReformerMRCModel(nn.Module):
def __init__(self, num_tokens, dim, depth, max_seq_len, heads, num_labels=2, causal=False):
super().__init__()
self.reformer = ReformerLM(
num_tokens= num_tokens,
dim= dim,
depth= depth,
heads= heads,
max_seq_len= max_seq_len,
causal= causal, # auto-regressive 학습을 위한 설정
return_embeddings=True # reformer 임베딩을 받기 위한 설정
)
self.mrc_head = ReformerMRCHead(dim, num_labels)
def forward(self,
input_ids=None,
start_positions=None,
end_positions=None,
**kwargs):
# 1. reformer의 출력
outputs = self.reformer(input_ids,**kwargs)
# 2. mrc head 출력
logits = self.mrc_head(outputs)
start_logits, end_logits = logits.split(1, dim=-1)
start_logits = start_logits.squeeze(-1)
end_logits = end_logits.squeeze(-1)
if start_positions is not None and end_positions is not None:
if len(start_positions.size()) > 1:
start_positions = start_positions.squeeze(-1)
if len(end_positions.size()) > 1:
end_positions = end_positions.squeeze(-1)
# sometimes the start/end positions are outside our model inputs, we ignore these terms
ignored_index = start_logits.size(1)
start_positions.clamp_(0, ignored_index)
end_positions.clamp_(0, ignored_index)
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
start_loss = loss_fct(start_logits, start_positions)
end_loss = loss_fct(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2
return total_loss
else:
return start_logits, end_logits파인튜닝 결과
목표로 했던 KoBERT에 비해 조금 부족한 성능을 보이지만, 12 레이어 모델 대비 6 레이어 모델로 괜찮은 성능을 보이는것까지 테스트 했습니다.
| model | exact_match | f1 score |
|---|---|---|
| reformer-bert-small | 52.1 | 79.02 |
| KoBERT | 51.75 | 79.15 |
마치며
위 과정을 통해 Masked Language Model을 직접 구현 및 학습시켜보면서 언어모델의 동작과 원리를 이해할수 있었습니다. 나아가 부족했던 부분들에 대해 개선하면서 더 나은 방법의 언어 모델을 모색할 수 있을것으로 생각합니다.
