
AlexNet
- 딥러닝의 시초
- LeNet 에서는
tanh활성화 함수가 쓰였다면, AlexNet 에서는 처음으로 ReLU 활성화 함수가 사용됨 -> 수렴 속도 개선 - 2개의 GPU로 병렬 계산
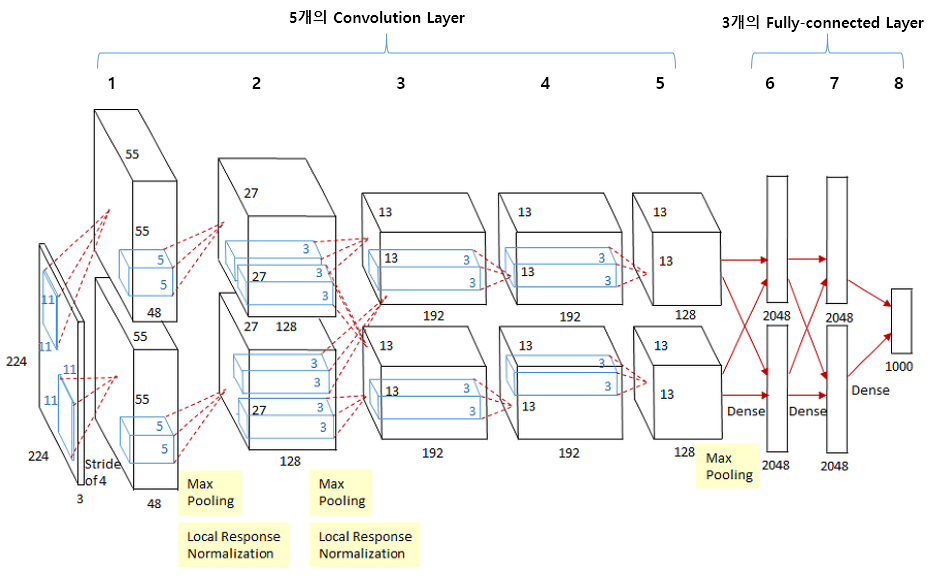
- Dropout 적용
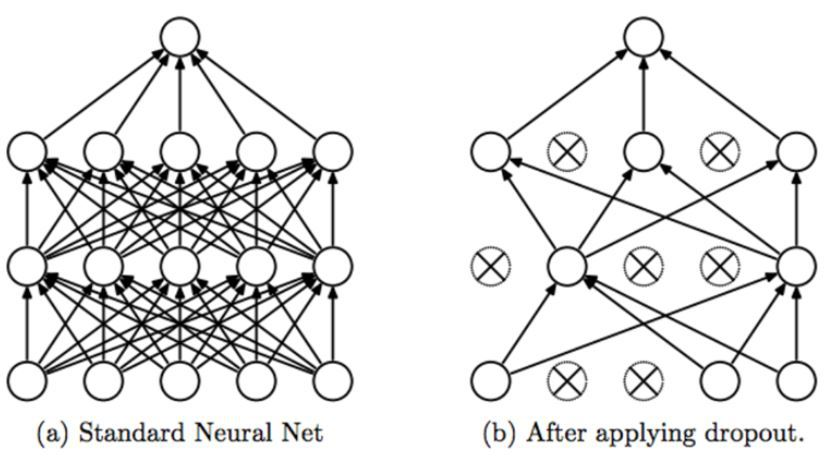
: Fully-Connected Layer의 뉴런 중 일부를 생략하면서 학습을 진행하는 것 -> 과적합 방지
VGGNet
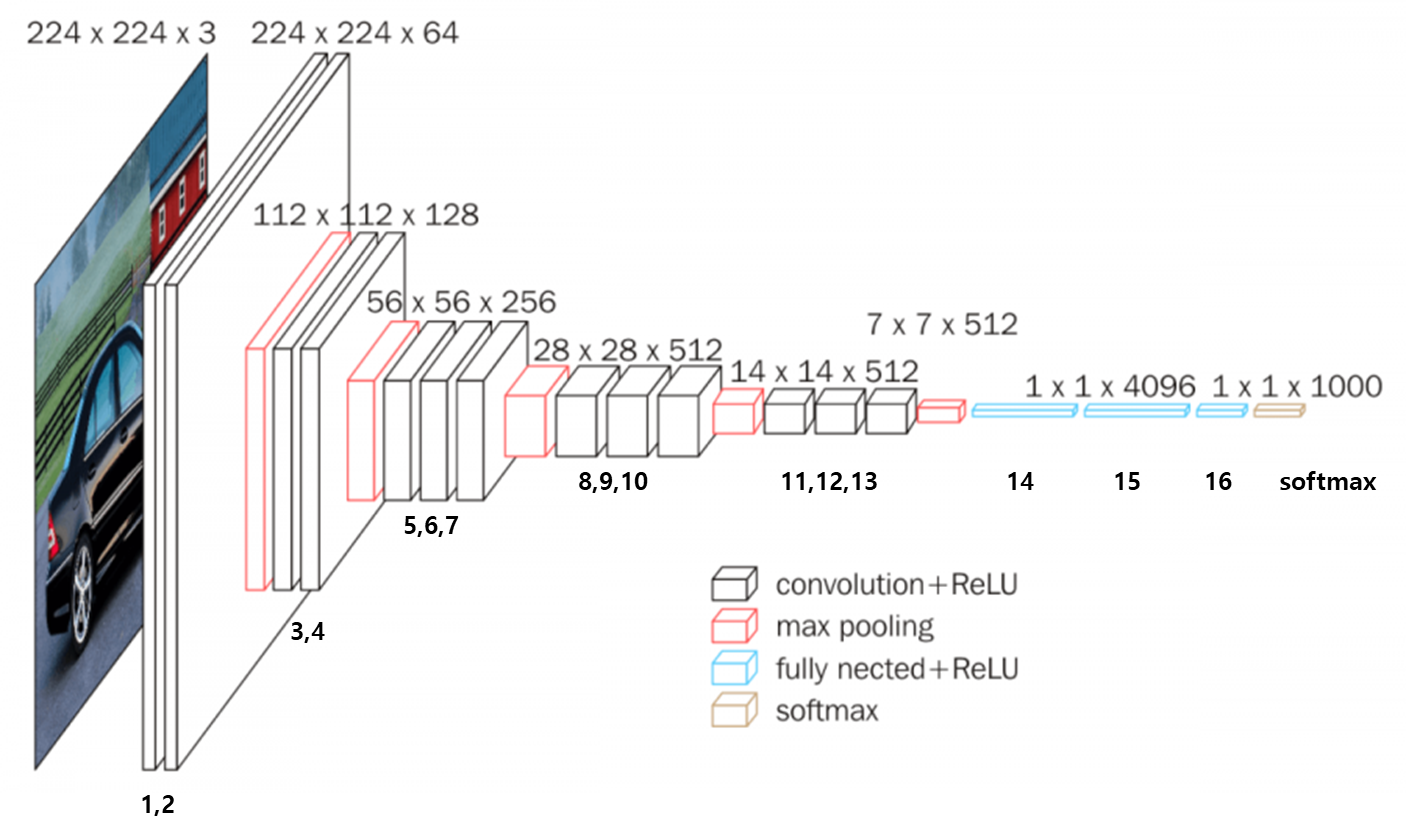
- AlexNet 보다 더 적은 수의, 크기가 작은 필터 활용
- AlexNet 보다 더 깊은 층 활용 (8개 -> 16 ~ 19개로 확장)
- ILSVRC 에서 처음으로 오류율 10% 이내 진입
- 3 * 3 CONV filters
ex) 3 3 CONV 층 3개 쌓으면 7 7 CONV 층 1개와 같은 수용 영역 가지면서더 적은 parmaters사용 - 더 많은 비선형성
- 더 깊은 신경망
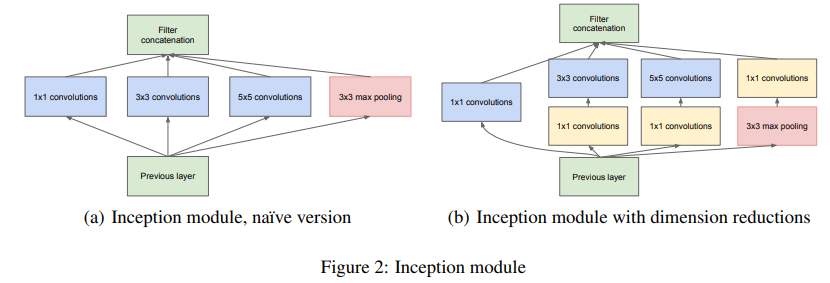
GoogLeNet
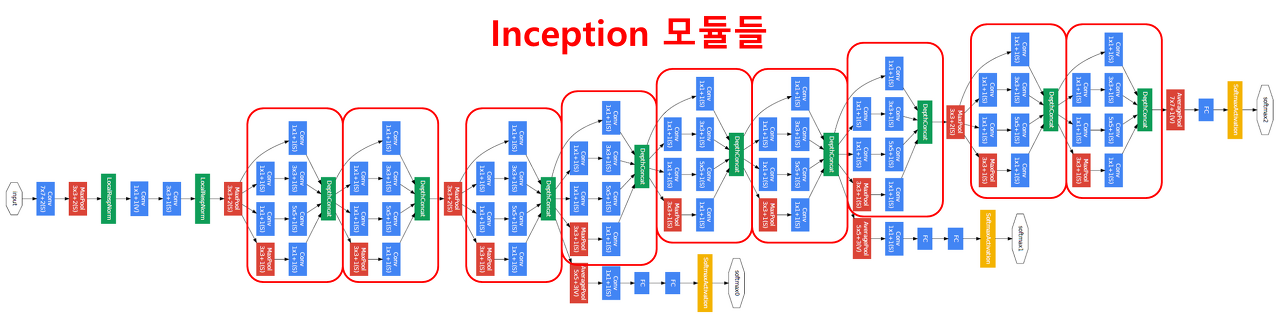
- VGGNet 보다 더 깊고 계산적으로 효율이 뛰어남.
- 22개의 층 사용, FC 층 제거
- 효율적인 Inception 모듈 설계 후 쌓아서 만든 구조 -> parameter 수를 AlexNet 대비 12배 줄임.
1 * 1 합성곱 필터: 연산량 줄이는 목적, 입력 데이터 채널 수를 줄일 수 있음.Bottleneck추가해 연산량 절반 이상 줄일 수 있음.
ResNet
- 152개 층 사용 -> 이전보다 매우 깊은 신경망 구조 설계
Residual block-> 잔차를 최소화 하고자 학습Residual Mapping: ResBlock 의 CONV 층을 통과한 값과 통과하지 않은 값의 합
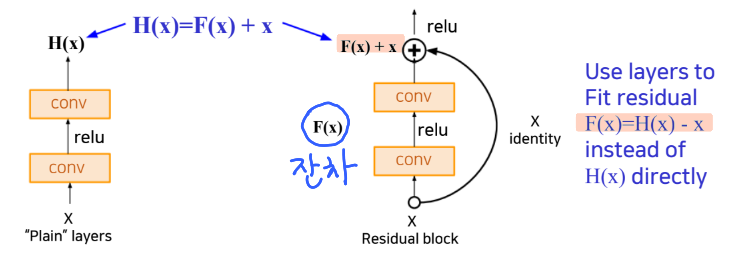
- 성능 Good
