
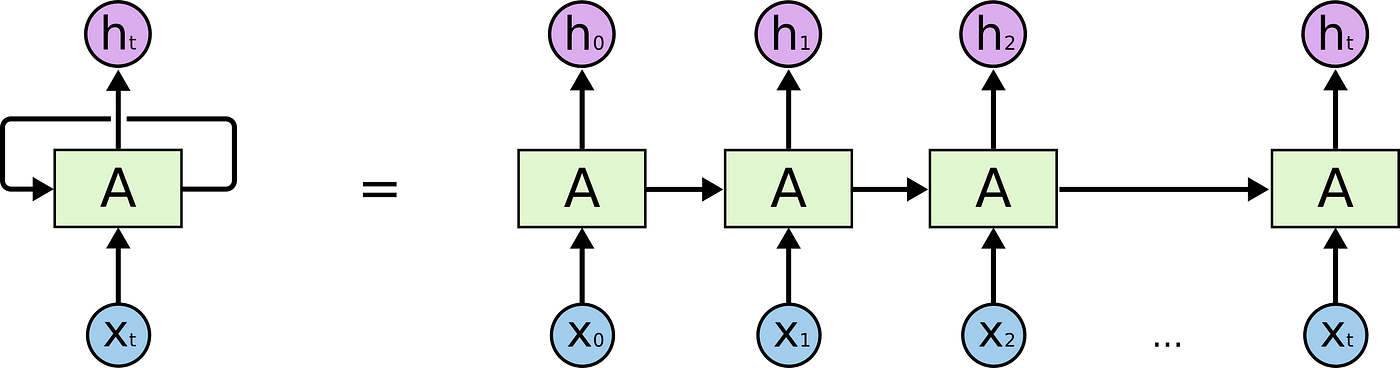
순환신경망이란 ?
- 순차 데이터 (Sequential data) 를 이용하는 인공신경망 유형
- 이를 위해서는 기억 (Memory) 을 처리하는 설계가 필요
- 은닉층 출력이 기억을 저장하도록 하고, 기억은 새로운 입력으로도 활용이 가능 (즉, 은닉층에 대해 재귀적 구조)
💡 순차 데이터란 ?
‘어떤 순서를 가진 데이터’ 로 순서가 변경될 경우 데이터의 특성을 잃어버리는 데이터
구조
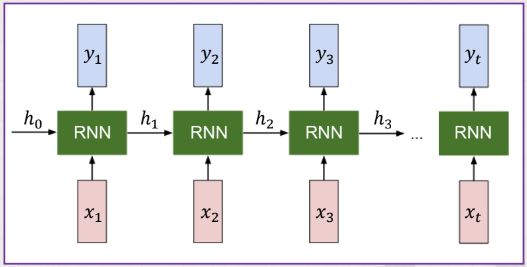
1. 입력층
- / 출력 : / ( : 가중치, : 편향, : 활성함수)
2. 은닉층
3. 출력층
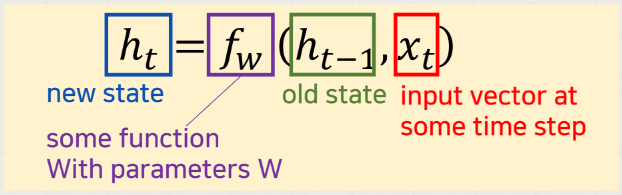
⚠️ 기울기 소실/폭발 문제
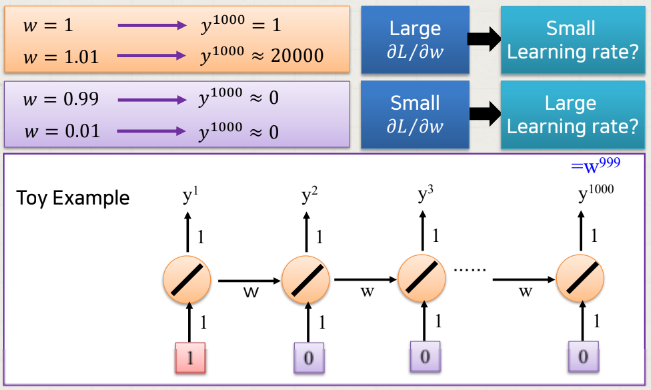
역전파 과정에서 RNN의 활성화 함수인 tanh의 미분값을 전달하게 되는데, 역전파를 계속 거치면서 Hidden-state 벡터에는 역전파 정보가 거의 전달되지 않는 문제를 기울기 소실 (Vanishing Gradient) 이라고 한다.
반대로 시퀀스 앞쪽에 있는 hidden-state 벡터에 역전파 정보가 과하게 전달되는 문제를 기울기 폭발(Exploding Gradient)라고 한다.
즉, 입력 데이터에 w (기울기) 가 계속 곱해지고 다음으로 넘겨지고 이런 과정이 반복되는데, w가 0에 가까우면 기울기 소실, 1보다 크면 기울기 폭발 문제가 일어날 수 있다.
LSTM (Long Short-Term Memory)
⚠️ RNN의 한계
기울기 소실 문제 = 순차 데이터의 장기 의존성을 반영하기 어려움 !
(즉, 입력과 출력 값 사이의 거리가 멀면 두 단어가 밀접하게 관련돼도 연관이 적다고 판단)
-> 이를 해결하기 위해 LSTM, GRU 제안
구조
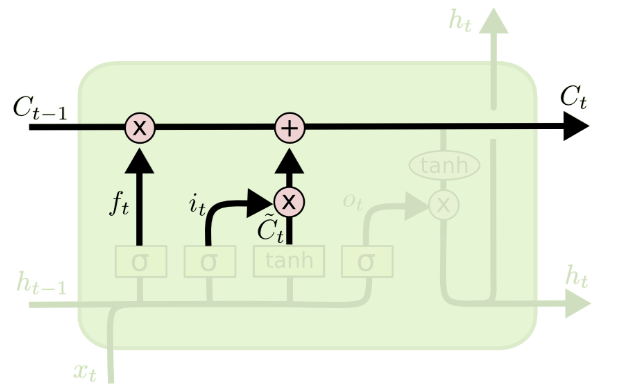
전체 구조는 RNN과 동일하고, 정보 흐름 제어를 위한 게이트 장치를 활용한다.
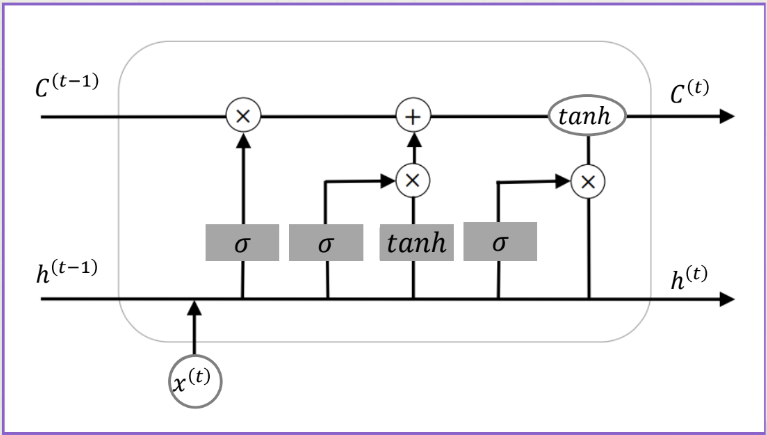
1. Forget gate ()
: 어떤 정보를 폐기할지 결정하는 관문
(과거 정보를 얼마나 유지할 것인가?)
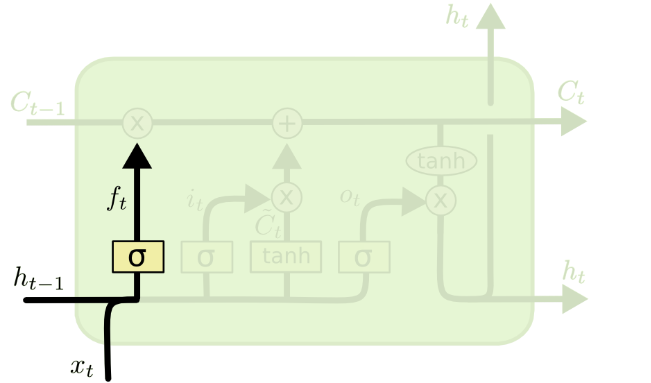
-
이전 은닉 상태와현재의 새로운 입력을 고려해 활성화 함수는시그모이드를 적용해,셀 상태의 각 요소에 대해0~1사이 값을 출력
(0에 가까울수록 많은 정보를 잊은 것) -
출력은 셀 상태 의 차원과 같은 벡터 로 요약되며, 다음과 같이 표현됨. ( : 시그모이드 함수)
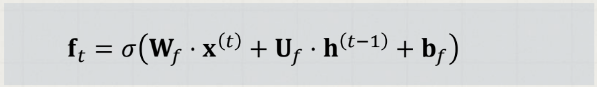
2. Input gate ()
: 새로운 입력 의 어떤 정보를 저장할 지 결정하는 관문
(새로 입력된 정보는 얼마나 활용할 것인가?)
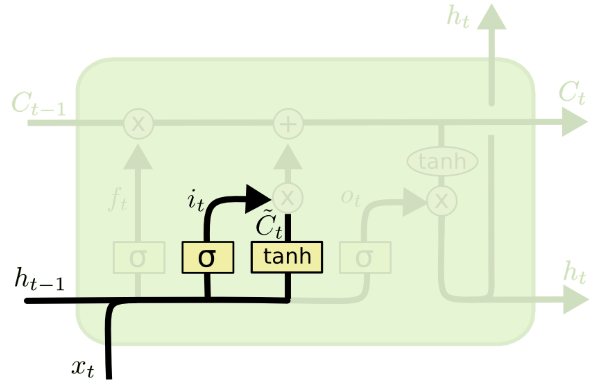
forget gate와 유사하게 이전 은닉 상태와 현재 입력을 고려하는데, 특이한 점은 각 다른 가중치와 활성함수를 이용한다는 것이다.
들어오는 새로운 정보 중 어떤 것을 셀 상태에 저장할 것인지를 정하기 위해 먼저 sigmoid layer를 거처 어떤 값을 업데이트할 것인지를 정한 후, tanh layer에서 새로운 후보 Vector를 만든다.
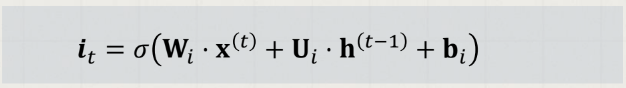
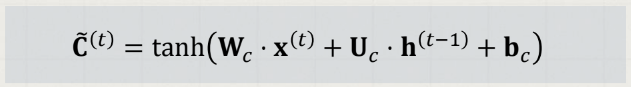
이전 gate에서 버릴 정보들과 업데이트할 정보들을 정했다면, 새로운 셀 상태로 업데이트를 진행한다. ( : Hadamard 곱, element-wise 곱)
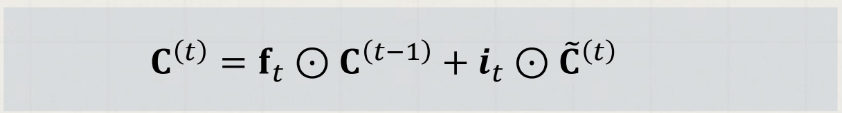
즉, 은 이전 시점의 셀 정보를 얼마나 유지할지를 나타내고, 는 현재 기억할 정보를 나타낸다. 이 두 정보를 바탕으로 셀 상태를 업데이트 하는 것이다.
3. Output gate ()
: 다음 위치로 보낼 은닉 상태 를 생성한다.
(두 정보를 계산하여 나온 출력 정보를 얼마나 넘겨줄 것인가?)
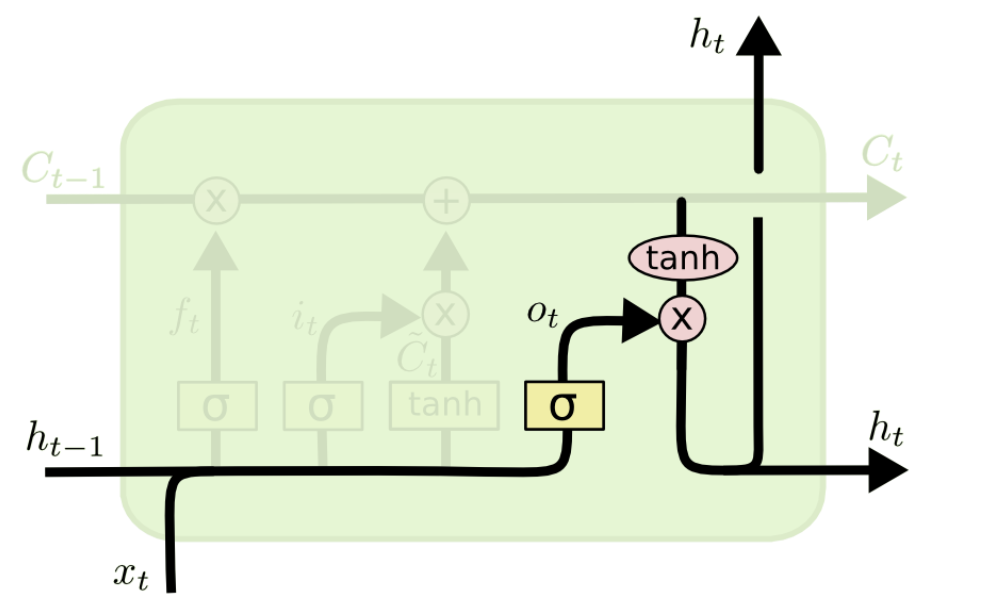
이전 은닉 상태와 현재 입력을 고려하는데, 각 다른 가중치와 활성함수를 이용한다.
먼저 sigmoid layer에 input data를 넣어 output 정보를 정한다.
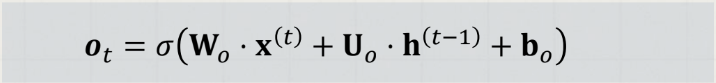
그리고 셀 상태를 tanh layer에 넣어 sigmoid layer의 output ()과 곱하여 은닉 상태를 계산한다.

즉, t 번째 위치에서는 아래와 같다.
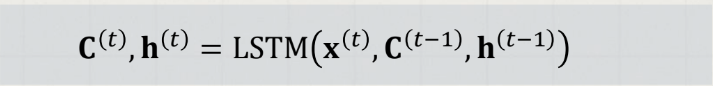
GRU (Gated Recurrent Unit)
- LSTM 의 변형
- Forget gate + Input gate ->
Update gate로 결합 (이전의 정보를 얼마나 통과시킬지 결정) Reset gate도 추가 (이전 hidden state의 정보를 얼마나 잊을 지 결정)
