
이번 포스팅은 Yolo 모델이 무엇이고, Yolov5모델에 대하여 포스팅을 하겠습니다.
포스팅을 하기 전 Yolov5에 대한 포스팅을 하는 이유는 이번 PEANUT(음식 인식 기능이 있는 당수치 예측 프로그램)과 인턴중 Yolo모델을 많이 다루기 때문에 직접 공부를 하고, 테스트를 진행해보고 직접 커스텀 데이터를 학습하여 API로 만들예정입니다.
이미지 분류
객체인식을 알아보기 전 이미지 분류(Image Classification)에 대해 간단히 알아보겠습니다. 이미지 분류(Image Classification)는 DNN에 입력으로 이미지를 넣으면 해당하는 클래스를 분류하는 문제를 이미지 분류(Image Classification)라고 부릅니다.
다음 그림과 같이 주요 타겟으로 하는 전체 클래스에 대한 확률 값들을 출력합니다.

이미지 분류(Image Classification) 분야는 최근에 AutoML로 얻은 architecture가 사람이 고안한 architecture의 정확도를 넘기기도 하였으며, 상당한 수의 연구가 진행이 되고있는 분야입니다.

현재에도 굉장히 많은 논문이 쏟아져 나오는 상태입니다.
객체 인식이란?

객체 인식(Object Detection)이란 컴퓨터 비전의 하위 분야 중 하나입니다. 이미지 및 비디오의 정보를 유의미한 특정 객체를 감지하는 작업을 진행합니다. 객체 감지중에서 예를 들면 얼굴인식, 비디오 추적, 사람 수 카운팅등등 다양한 분야에서 사용됩니다. 특히 최근에는 자율 주행 자동차와 의료계통에서도 많이 사용되고 있습니다.
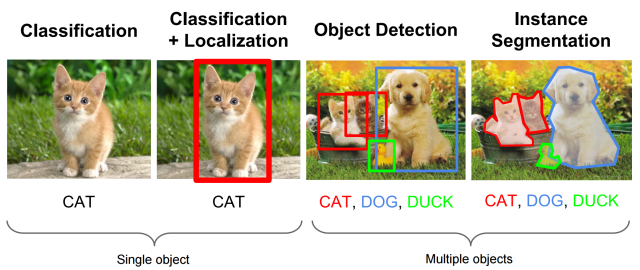
객체 인식에서는 사진이나 비디오에 어떤 물체가 있는지 분류(Classification)하고 나서 분류된 객체가 어디에 위치하는지 바운딩 박스(Bounding box)를 통해서 위치를 파악하여 객체를 감지합니다. 사진이나 비디오에는 객체가 하나만 존재할 수도 있고, 여러 객체가 존재 할 수도 있습니다. 하나의 객체를 Single Object, 여러 객체는 Multiple Object라고 합니다. 즉,
객체 인식은 Multipled label Classification + Bounding Box Regression 라고 정의할 수 있습니다.
Yolo model 이란?
YOLO(You Only Look Once)는 객체 인식(Object detection) Framework 중 하나입니다. 이미지를 한 번만 보는 1 - stage detector 방식을 사용하고, 이를 바탕으로 객체의 종류와 위치를 추측하는 딥러닝 기반의 물체인식 알고리즘입니다.
Yolo 특징
- 단일 신경망 구조 사용 -> 구성이 간단하고 빠릅니다.
- 주변 정보까지 학습 -> 이미지 전체를 처리하기 때문에 Background Error가 낮습니다.
- 입력 파일을 받으면 하나의 CNN(convolution network)이 이미지 내에서 찾고자 하는 객체의 bounding box의 위치 정보(x,y,w,h)의 감소가 bounding box의 class확률을 동시에 계산합니다.
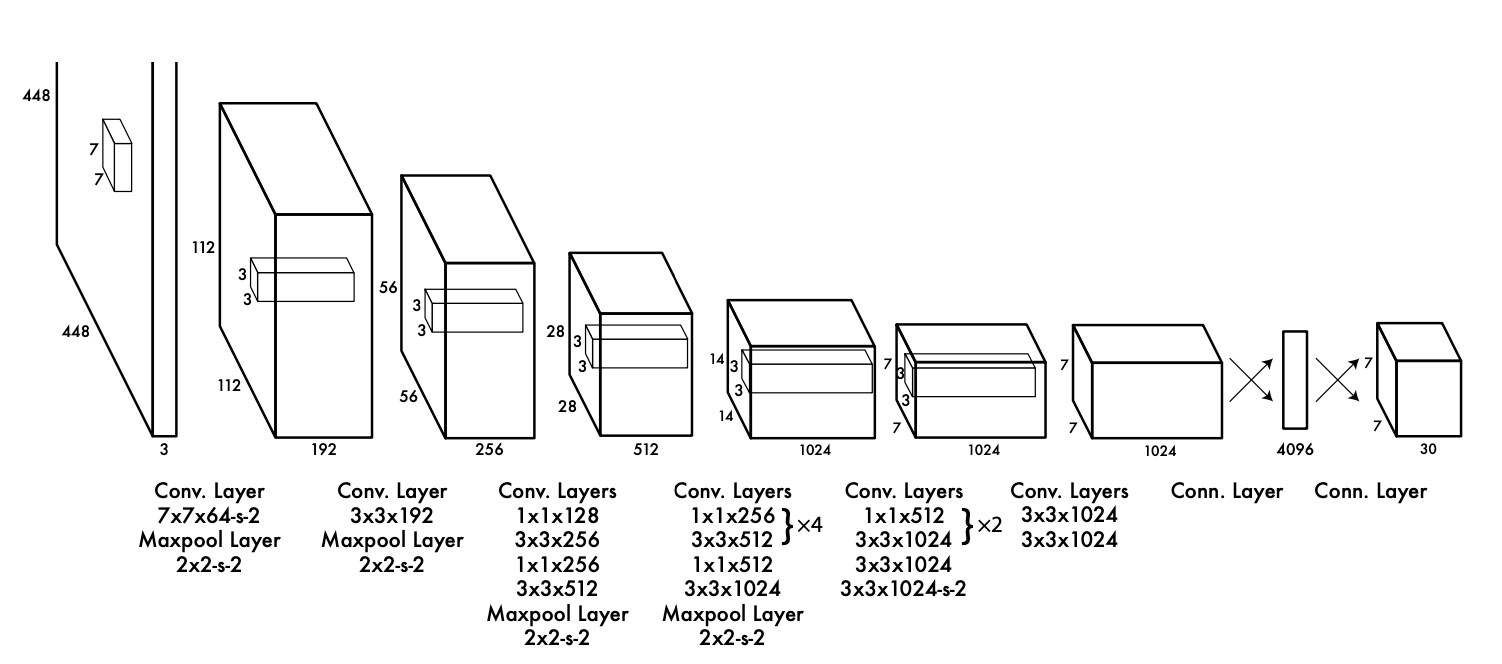
YOLO model의 Network Design
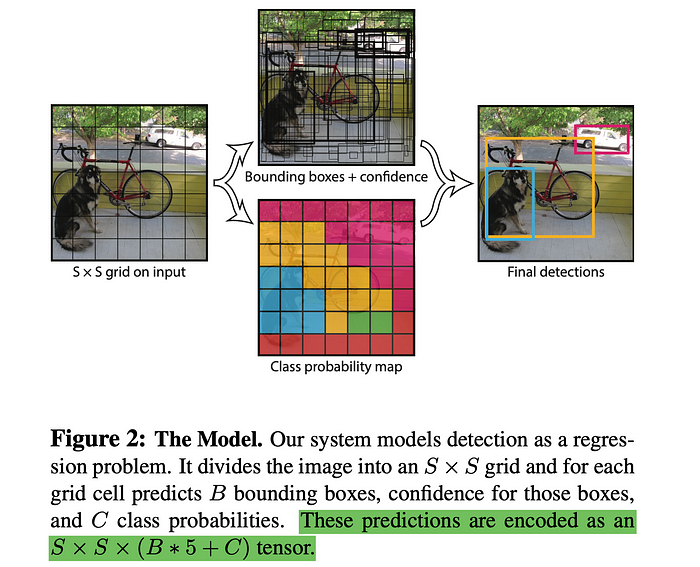
Yolo논문에서는 CNN을 이용하여 (448 x 448)크기의 이미지를 (7x7)크기의 feature map을 추출합니다. 위에 사진 처럼 input image를 S x S 크기의 Grid 영역으로 나눠줍니다.
위 그림에서 격자 1개에 해당하는 것이 grid 영역 1개입니다.각 grid 셀은 B개의 bounding box를 예측합니다. 그 box에 대한 confidence score를 같이 예측하며 계산합니다. confidence score는 박스 안에 실제로 객체가 얼마나 존재하는지 계산합니다. Confidence 는 형식적으로 Pr(Object) * IOU(intersection over union) 라고 정의합니다. IOU란 정답 box와 예측 box의 교집합 크기 / 합집합 크기 입니다.
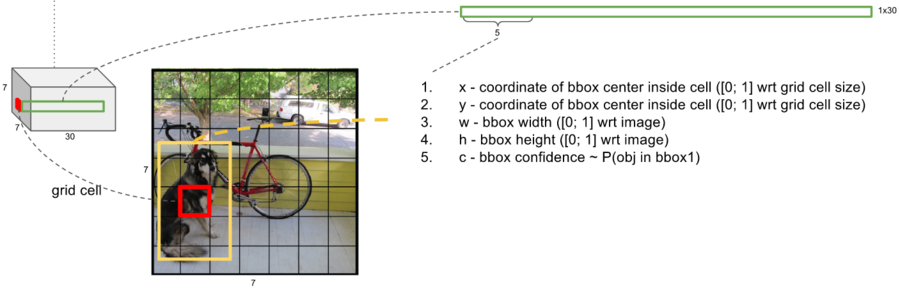
빨간색 박스는 7*7사이즈의 그리드 1개이며, 하나의 이미지 내에서 개의 일부분에 해당합니다.
노란색 박스는 빨간색 그리드 셀에서 예측한 경계 박스입니다.
위 그림을 보면 x,y 는 셀 내부 bbox의 중심 좌표이고, w,h는 bbox의 세로와 가로입니다.
이를 통해 confidnece를 얻습니다. 해당 이미지가 네트워크를 통과하게 되면 중앙의 2개 데이터를 얻게 됩니다. 그리드 셀이 7*7 = 49 개이므로, 총 98개의 데이터(경계박스)가 만들어집니다.
해당 경계박스를 통해 경계박스 내부에 원하는 객체가 있을 것이라 판단하면 bounding box를 굵게 그려줍니다. 해당 확률에 근거하여 bounding box를 여러개 만드는데, 이때 ROI 혹은 오브젝트 후보라고 할 수 있는 경계박스를 threshhold보다 작으면 지우게 됩니다. 해당 defalut값은 0.5로 설정되어있습니다.
이후 다시 남은 bounding box를 제거하기위해 NMS(Non-maximal suppresiion 비 최대값 억제) 알고리즘을 사용하는데 이때 중복이 되는 경계박스들을 제거해 오직 하나의 경계 박스만 남기게 합니다. 즉 신뢰도가 제일 높은 것 하나만 남기고 모두 지운다고 생각하시면 됩니다.
- NMS를 적용한 이미지

Yolov5
여러 종류의 Yolo 모델이 있지만, 이번 프로젝트에서 사용하게 될 Yolov5을 알아보겠습니다.
YoloV5를 선택한 이유는 일반적인 환경에서 최소한의 라벨링으로 detection을 할수 있게 설계가 되었기 때문입니다.
YoloV5는 2020년 6월 출시했습니다. Yolov4에 비해 낮은 용량과 빠른 속도를 가지고 있고, Yolov4와 같은 CSPNet기반의 backbone을 Pytorch로 구현하여 설계하여 사용했습니다. 기존에 구현한 Darknet(C언어 기반)이 아닌 Pytorch로 구현하였기 때문에, 이전 버전들과 다르다고 볼 수 있습니다.
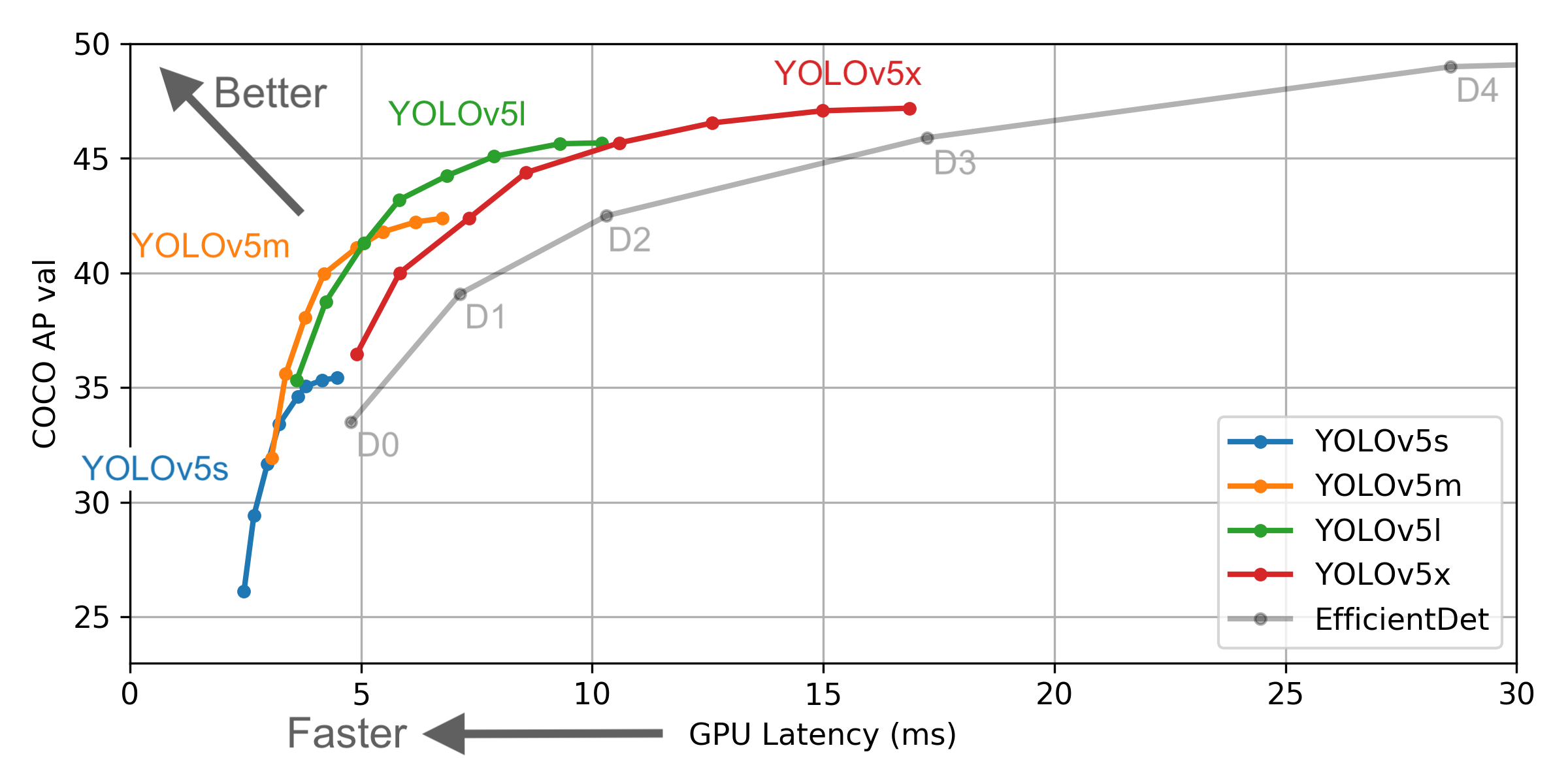
Yolov5의 4가지의 model
Yolov5s, Yolov5m, Yolov5l, Yolov5x 모델로 나눠집니다. 해당 모델은 성능과 시간에 비례헤 나뉘어져 있습니다. s가 제일 가벼운 모델(성능이 낮음)이며 프레임수가 가장 높고, x가 제일 무거운 모델(성능이 좋음)이며 프레임수가 가장 낮습니다.
Head에 Neck 부분이 같이 존재하며, 마지막 Detect Layer가 Head를 담당합니다. 위 그림은 Yolov5 의 architecture입니다.
YoloV5의 아키텍쳐는 최대한 일반적인 환경에서 최소한의 라벨리으로 detection을 할수 있게 설계가 되었습니다.
참고
