LeetCode 219 Contains Duplicate II 풀러가기
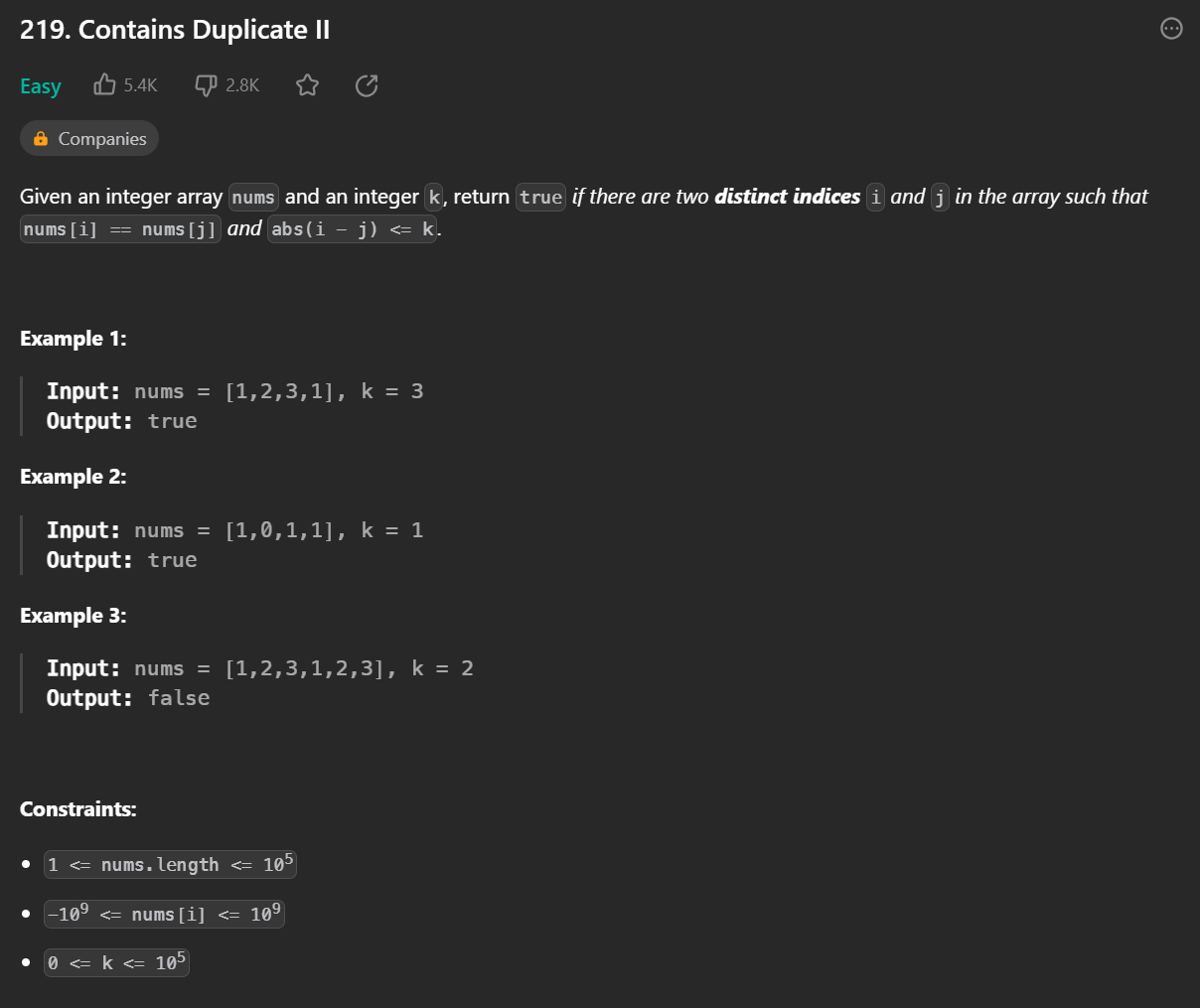
문제
배열 nums와 숫자 k가 주어진다.
다음 조건을 만족하는 i, j 가 있다면 true를, 없다면 false를 반환 하세요.
- nums[i]==nums[j]
- abs(i-j) <= k (abs는 절댓값 함수이다)
문제 분석
첫번쨰 시도
nums[i] 값을 key로 갖는 map을 만들어,
이미 값이 있는 경우라면 aba 계산 후 k보다 작거나 같다면 true를 리턴하고
위의 경우에 속하지 않으면 현재 index로 value 값을 갱신하는 함수를 만들었다.
현재 index로 갱신하는 이유는 (i-j) 절댓값이 k보다 커서 정답이 아니였는데, index를 증가하면서 계산할텐데 갱신하지 않으면 이 값의 차이가 더 늘어나기 때문이다.
값을 갱신하여 거리를 줄일 수 있도록 한 것이다.
코드
class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
Map<Integer, Integer> map = new HashMap<>();
for(int i=0; i<nums.length; i++){
if(map.containsKey(nums[i]) && Math.abs(map.get(nums[i])-i) <= k)return true;
else map.put(nums[i],i);
}
return false;
}
}결과 : 성공

Rumtime

Memory

결과는 성공했다! 시간을 매우 짧아서 다행이였지만, 메모리 낭비가 있었다.
두번째 시도(메모리 개선)
메모리가 늘어난 이유를 고민했을 때 map에서 필요없는 데이터들이 삭제되지 않고 계속 존재하기 때문이라고 생각했다.
그래서 abs(i-j)<=k에 해당할 수 없는 index를 지우기로 했다.
map.remove(nums[i-k])를 하여 해당인덱스에 k만큼 떨어진 숫자를 제거했다.
왜냐하면 i-k인덱스는 다음 for 문에서는 비교하는 i와의 거리가 k+1로 변해서 abs(i-j)<=k를 만족할 수 없기 때문이다.
코드
class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
Map<Integer, Integer> map = new HashMap<>();
for(int i=0; i<nums.length; i++){
if(map.containsKey(nums[i])&& Math.abs(map.get(nums[i])-i) <= k)return true;
else map.put(nums[i],i);
if(i >= k && map.containsKey(nums[i-k]))map.remove(nums[i-k]);
}
return false;
}
}결과 : 성공

Runtime

Memory

메모리가 무척 개선되어서 놀랐다.
그러나 시간이 많이 늘어나서 어떤 것이 더 좋다고 뚜렷하게 말할 수는 없을 거 같다.
다른분의 코드
내가 푼 방법 말고도 다른 방법이 있는지 다른 코드를 찾아보았다.
set을 사용해서 문제를 푸신 분도 있었다.
class Solution {
public boolean containsNearbyDuplicate(int[] nums, int k) {
HashSet<Integer> set = new HashSet<>();
for (int i = 0; i < nums.length; i++) {
if (set.contains(nums[i])) {
return true;
}
set.add(nums[i]);
if (set.size() > k) {
set.remove(nums[i - k]);
}
}
return false;
}
}결과

비교
세가지 경우를 다 비교해보았을 때, 제일 처음에 푼, HashMap을 사용해서 풀면 가장 빠르게 풀 수 있었다.
