최근 재귀 함수에 대해 배우면서 브래드 크럼스 구현을 하게 되었다.
우연히 내가 현재 SQLD 준비 중이라, 계층 구조와 재귀 쿼리에 대해 알고 있었고 이를 활용하여 문제를 풀었다.
브래드 크럼스란?
브래드 크럼스는 현재 페이지의 계층 구조, 최상위에서부터 현재 페이지까지를 사용자의 링크 목록을 말한다.
예를 들어 현재 페이지2일 때, Home > 페이지 1 > 페이지 2 경로로 와야 페이지 2로 갈 수 있다는 의미이다.
참고한 사이트 : MDN Web Docs 'Breadcrumb (브레드크럼)'
구현 방법
Table
Name | Type | Nullable |
|---|---|---|
| id | int auto_increment | No |
| title | varchar(50) | No |
| context | text | No |
| parent_id | int | Yes |
쿼리
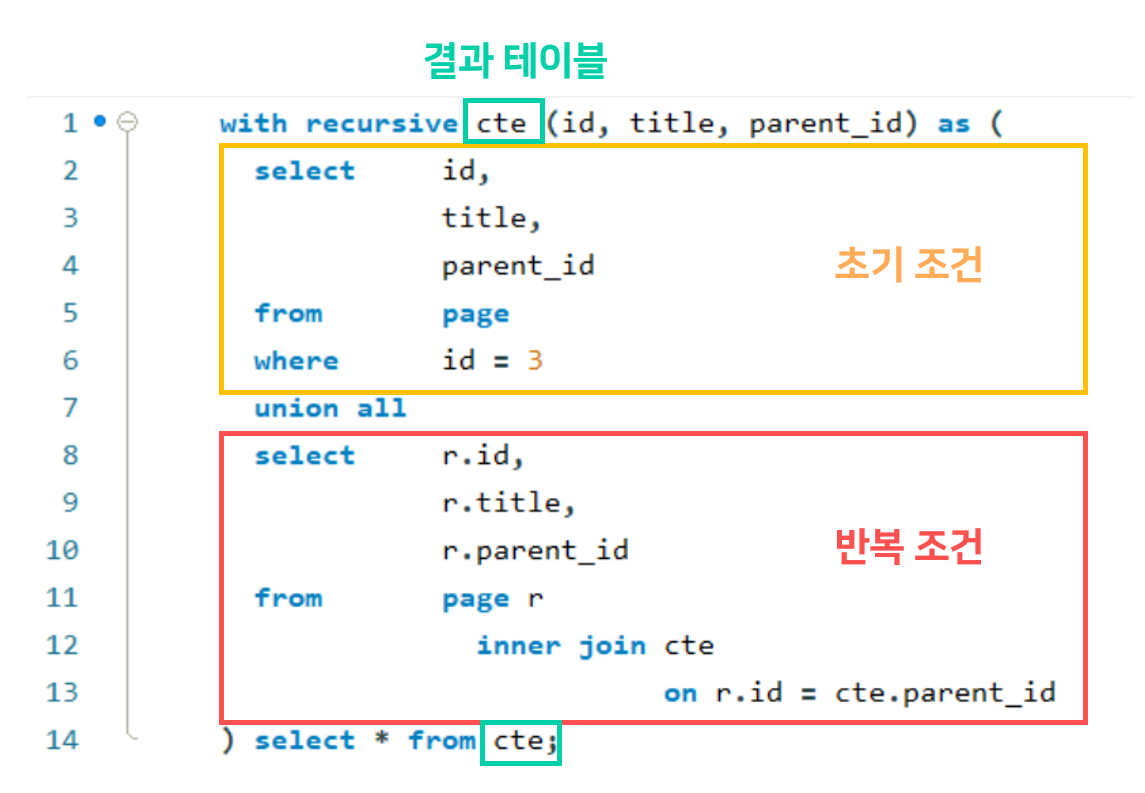
with recursive cte (id, title, parent_id) as (
select id,
title,
parent_id
from page
where id = ?
union all
select r.id,
r.title,
r.parent_id
from page r
inner join cte
on r.id = cte.parent_id
) select * from cte;
SELECT * FROM wanted.page;
예시
다음과 같은 테이블이 있을 때
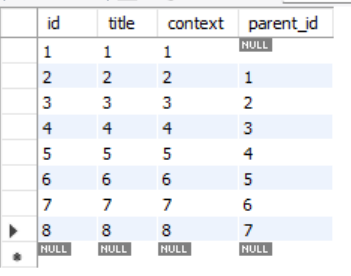
id가 3인 페이지의 부모를 알고 싶어 해당 쿼리를 실행 하면
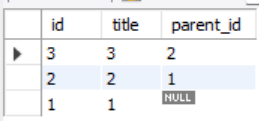
다음과 같이 결과가 뜬다.
쿼리 분석
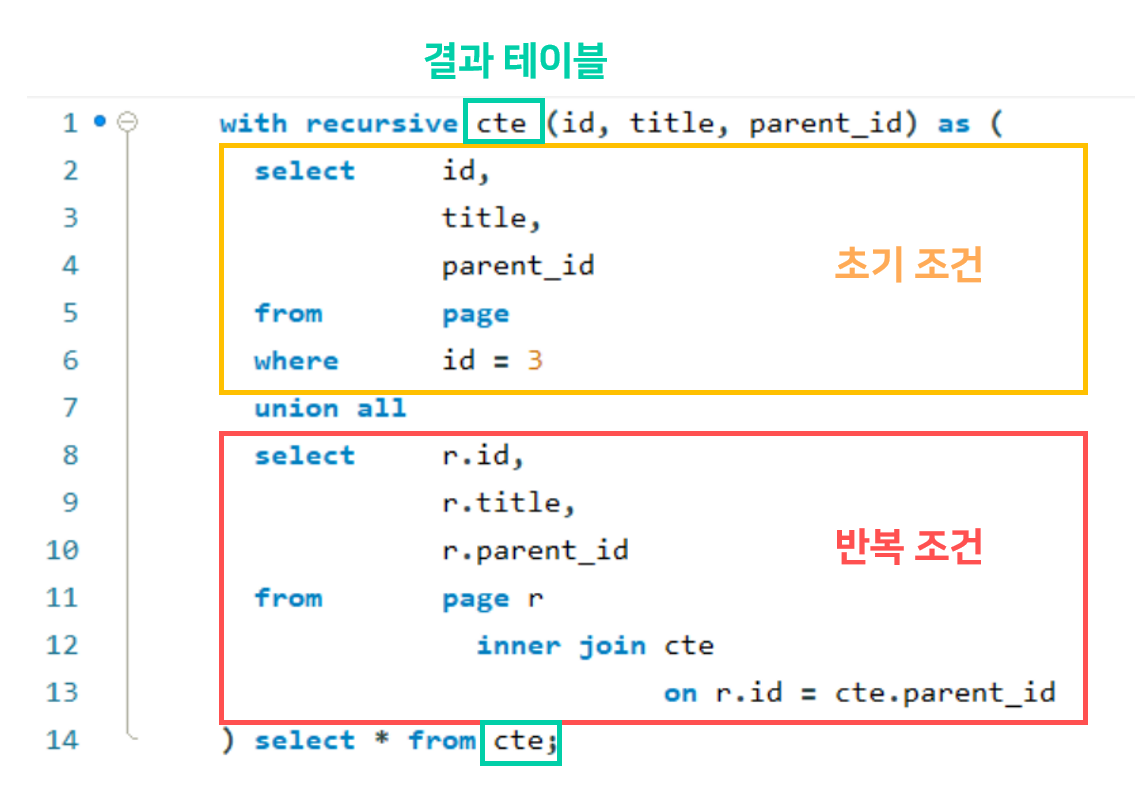
with recursive 가 반복하여 생성되는 테이블(cte)을 정의한다.
대부분 cte라고 한다하여서 그대로 두었다.
그 후, 처음 select 에 초기 조건을 준다. 이 테이블 기준으로 다른 테이블이 반복되면 합쳐진다.
union all 아래 select 문이 반복 조건이다.
나는 처음 select 된 row의 부모와 같은 id를 가진 row를 계속 더 해야하니, inner join cte on r.id = cte.parent_id라는 조건을 하였다.
원하는 비즈니스 로직에 맞춰서 반복문을 구현하면 될 것 같다.
이 모든 cte가 완성되어 더이상 join할 것이 없다면 종료되고, 마친다.
배운점
만약 재귀쿼리를 사용하지 않고, 브래드 크럼스를 만들어야 했다면. 백엔드 서버에서
select id, title, parent_id
from page
where id = ?위 쿼리를 while 문을 반복하며 null 일때까지 수행해야 한다. 그러면 계속해서 db 접근이 일어나고, 로직을 처리하는 데 시간이 오래들 것 같았다.
재귀쿼리를 사용하여 db 접근을 1번만 할 수 있도록 하여 속도 면에서 빠를 것 같다.
sql문을 사용하였지만 이번에 with recursive에 대해 처음 알았다. 부서 간의 관계, 친구 관계 등에서 잘 쓰면 좋을 쿼리 같았다.
