0과 1로 숫자를 표현하는 방법
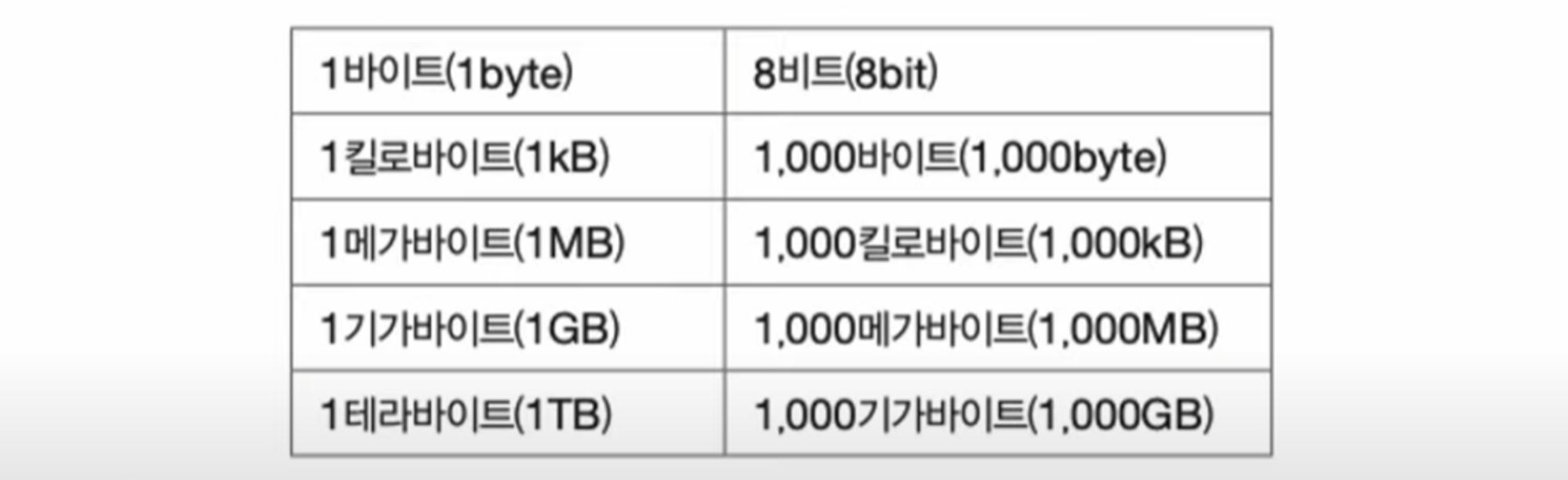
정보 단위
비트(bit): 0과 1을 나타내는 가장 작은 정보 단위- n비트는 2^n가지 정보를 표현할 수 있음
바이트(byte): 여덟 개의 비트를 묶은 단위- 1바이트는 8비트이므로 2^8(256)개의 정보를 표현할 수 있음
워드(word): CPU가 한 번에 처리할 수 있는 데이터 크기- 워드의 절반 크기를 하프 워드, 1배 크기를 워드, 2배 크기를 더블 워드라고 부름
- 현대 컴퓨터의 워드 크기는 대부분 32비트 또는 64비트임
이진법
이진법(binary): 수학에서 0과 1만으로 모든 숫자를 표현하는 방법- 이진법으로 표현한 수를 이진수, 십진법으로 표현한 수를 십진수라고 부른다.
- 이진수 끝에 아래첨자 (2)를 붙이거나 이진수 앞에 0b를 붙여서 표기한다.
이진수의 음수 표현
컴퓨터는 0과 1만 이해할 수 있기 때문에 마이너스 부호를 사용하지 않고 0과 1만으로 음수를 표현해야 한다. 이를 위한 방법 중 가장 널리 사용되는 것이 2의 보수(two’s complement)이다. 2의 보수는 어떤 수를 그보다 큰 2^n에서 뺀 값을 의미한다. 쉽게 표현하자면 모든 0과 1을 뒤집고, 거기에 1을 더한 값이라고 할 수 있다.
어떤 수의 2의 보수를 두 번 구해보면 자기 자신이 된다.
이진수만 봐서는 음수인지 양수인지 구분하기 어렵기 때문에 컴퓨터 내부에서 어떤 수를 다룰 때는 플래그(flag)를 사용한다.
2의 보수 표현의 한계
이진수의 음수를 표현하기 위해 2의 보수를 취하는 방식은 아직까지도 가장 널리 사용되는 방법이지만, 완벽한 방식은 아니다. 1000(2)와 같이 2^n의 수를 보수를 취하면 자기 자신이 되어버린다. 즉, n비트로는 -2^n과 2^n이라는 수를 동시에 표현할 수 없다.
십육진법
이진법은 0과 1만으로 모든 숫자를 표현하다 보니 숫자의 길이가 너무 길어진다는 단점이 있다.
십육진법(hexdecimal)은 수가 15를 넘어가는 시점에 자리 올림을 하는 숫자 표현 방식이다. 십진수 10, 11, 12, 13, 14, 15를 십육진법 체계에서는 각각 A, B, C, D, E, F로 표기한다.
이진수에 비해 더 적은 자리수로 더 많은 정보를 표현할 수 있다. 숫자 뒤에 아래첨자 (16)을 붙이거나 숫자 앞에 0x를 붙어 구분한다.
십육진법을 사용하는 주된 이유 중 하나는 이진수를 십육진수로, 십육진수를 이진수로 변환하기 쉽기 때문이다.
십육진수 → 이진수 변환
십육진수를 이루는 숫자 하나를 이진수로 표현하려면? → 4비트가 필요
십육진수 한 글자를 4비트의 이진수로 간주하여 쉽게 변환할 수 있다.
이진수 → 십육진수 변환
이진수 숫자를 네 개씩 끊고, 끊어 준 네 개의 숫자를 하나의 십육진수로 변환한 뒤 그대로 이어 붙이면 된다.
0과 1로 문자를 표현하는 방법
문자 집합과 인코딩
문자 집합(character set): 컴퓨터가 인식하고 표현할 수 있는 문자의 모음문자 인코딩(character encoding): 문자를 컴퓨터가 이해할 수 있도록 0과 1로 변환하는 과정문자 디코딩(character decoding): 0과 1로 이루어진 문자 코드를 사람이 이해할 수 있는 문자로 변환하는 과정
아스키 코드
- 아스키(ASCII; American Standard Code for Information Interchange)
- 초창기 문자 집합 중 하나이다.
- 영어 알파벳과 아라비아 숫자, 그리고 일부 특수 문자를 포함한다.
- 아스키에 속한 문자들은 각각 7비트로 표현된다. 즉, 총 128개의 문자가 표현된다.
- 실제로 아스키 문자는 8비트(1바이트)를 사용한다. 하지만 8비트 중 1비트는 패리티 비트(parity bit)라고 불리는 오류 검출을 위해 사용되는 비트이다.
- 영어권 외의 국가들은 자신들의 언어를 0과 1로 표현할 수 있는 고유한 문자 집합과 인코딩 방식의 필요성이 대두되었다.
EUC-KR
한글 인코딩에는 두 가지 방시그 완성형(한글 완성형 인코딩)과 조합형(한글 조합형 인코딩)이 존재한다.
완성형 인코딩 방식은 초성, 중성, 종성의 조합으로 이루어진 완성된 하나의 글자에 고유한 코드를 부여하는 인코딩 방식이다.
조합형 인코딩 방식은 초성을 위한 비트열, 중성을 위한 비트열, 종성을 위한 비트열을 할당하여 그것들의 조합으로 하나의 글자 코드를 완성하는 인코딩 방식이다. 다시 말해 초성, 중성, 종성에 해당하는 코드를 합하여 하나의 글자 코드를 만드는 인코딩 방식이다.
ECU-KR은 대표적인 완성형 인코딩 방식으로 초성, 중성, 종성이 모두 결합된 한글 단어에 2바이트 크기의 코드를 부여한다.
총 2,350개 정도의 한글 단어를 표현할 수 있는데, 이는 모든 한글 조합을 표현할 수 없다. 때문에 웹사이트 한글이 깨진다던지, 관공서에서 피해를 받는 사람이 생기는 등의 문제가 발생했다.
유니코드와 UTF-8
유니코드(Unicode)문자 집합- EUC-KR보다 훨씬 다양한 한글을 포함하여 대부분 나라의 문자, 특수문자, 화살표나 이모티콘까지도 코드로 표현할 수 있는 통일된 문자 집합이다.
- 현대 문자를 표현할 때 가장 많이 사용되는 표준 문자 집합
- 유니코드 글자 부여된 값 앞에 U+D55C, U+AE00처럼 “U+”를 붙이는건 십육진수로 유니코드를 표현할 때 사용하는 표기이다.
- 유니코드는 글자에 부여된 값 자체를 인코딩된 값으로 삼지 않고 이 값을 다양한 방법으로 인코딩한다.
- UTF-8, UTF-16, UTF-32는 유니코드 문자에 부여된 값을 인코딩하는 방식이다.
UTF-8은 통상 1바이트부터 4바이트까지의 인코딩 결과를 만들어 낸다. 다시 말해 UTF-8로 인코딩한 값의 결과는 1바이트가 될 수도 2바이트, 3바이트, 4바이트가 될 수도 있다. UTF-8로 인코딩한 결과가 몇 바이트가 될지는 유니코드 문자에 부여된 값의 범위에 따라 결정된다.
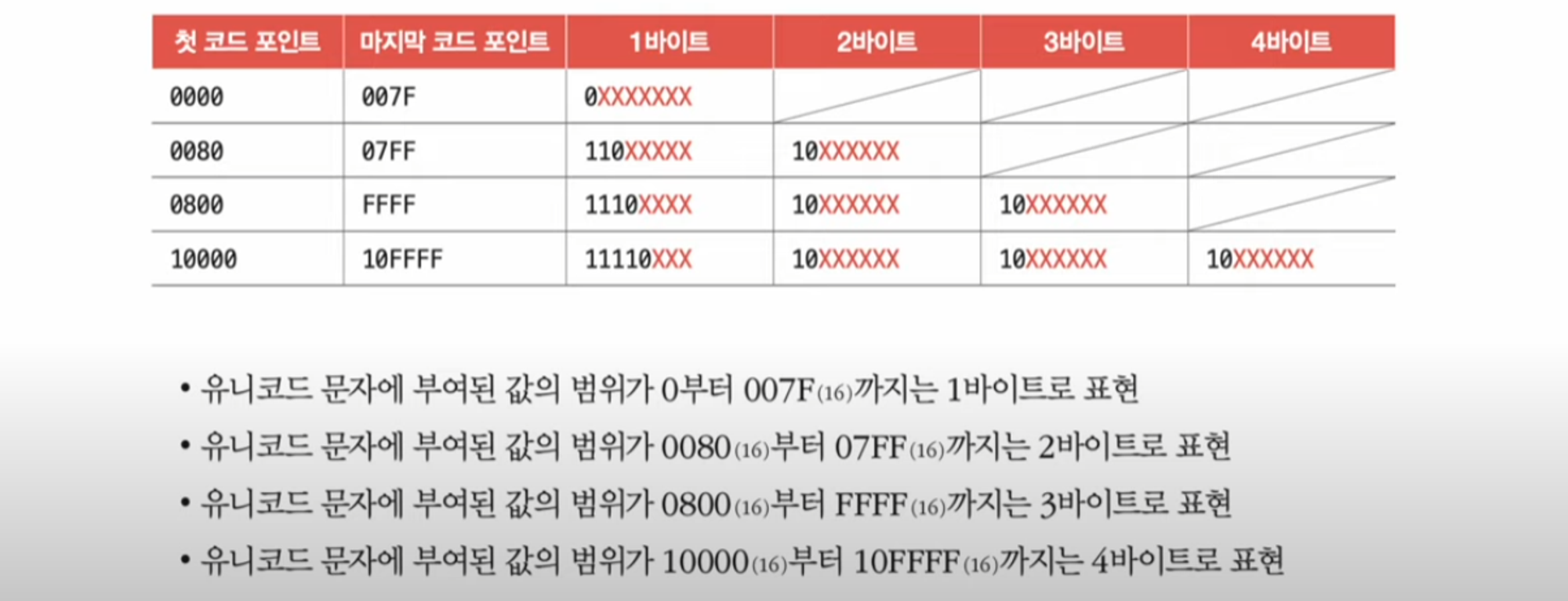
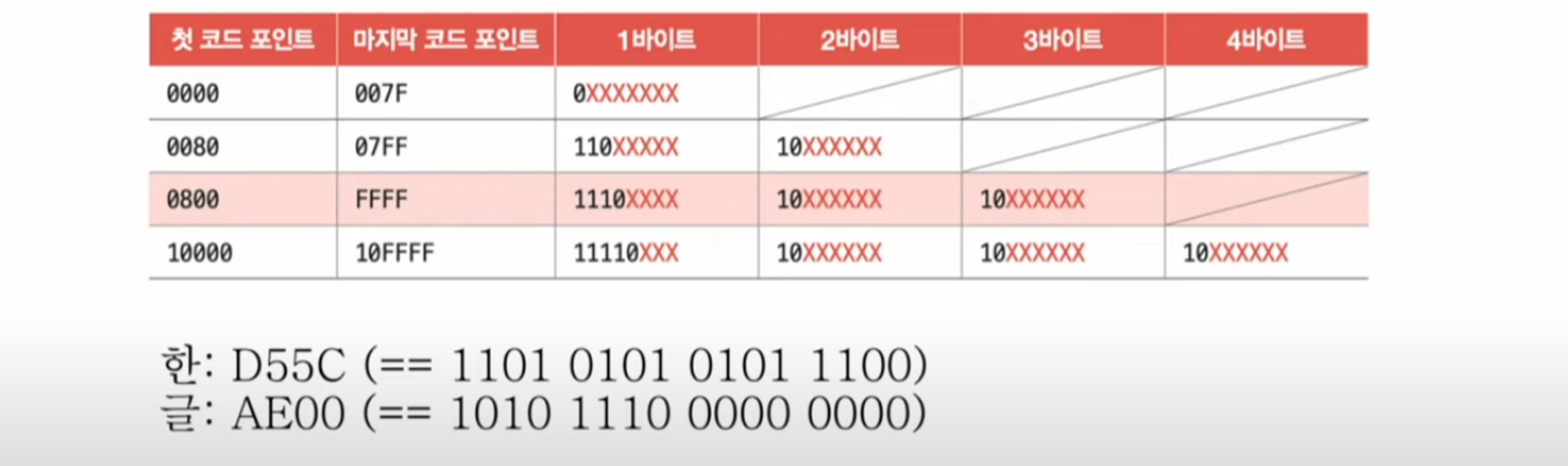
참고
