
소스 코드와 명령어
고급 언어와 저급 언어
프로그래밍 언어는 컴퓨터가 이해하는 언어가 아닌 사람이 이해하고 작성하기 쉽게 만들어진 언어이다. 이렇게 사람을 위한 언어를 고급 언어(high-level programming language)라고 한다. 흔히 알고 있는 대부분의 프로그래밍 언어가 고급 언어에 속한다.
반대로 컴퓨터가 직접 이해하고 실행할 수 있는 언어를 저급 언어(low-level programming language)라고 한다. 저급 언어는 명령어로 이루어져 있다. 컴퓨터가 이해하고 실행할 수 있는 언어는 오직 저급 언어 뿐이다. 그래서 고급 언어로 작성된 소스 코드가 실행되려면 반드시 저급 언어, 즉 명령어로 변환되어야 한다.
저급 언어에는 기계어와 어셈블리어가 있다.
기계어(machine code): 0과 1의 명령어 비트로 이루어진 언어. 즉, 0과 1로 이루어진 명령어 모음어셈블리어(assembly language): 0과 1로 표현된 명령어(기계어)를 읽기 편한 형태로 번역한 언어
고급 언어는 사람이 읽고 쓰기 편한 것은 물론이고, 더 나은 가독성, 변수나 함수 같은 편리한 문법을 제공하기 때문에 어떤 복잡한 프로그램도 구현할 수 있다.
개발자가 어셈블리어 같은 저급 언어로 복잡한 프로그램을 만들기 쉽지 않다. 그러나 하드웨어와 밀접하게 맞닿아 있는 프로그램을 개발하는 임베디드 개발자, 게임 개발자, 정보 보안 분야 등의 개발자는 어셈블리어를 많이 이용한다.
이러한 분야의 개발자들에게 어셈블리어란 ‘작성의 대상’일 뿐만 아니라 매우 중요한 ‘관찰의 대상’이기도 하다. 어셈블리어를 읽으면 컴퓨터가 프로그래밍을 어떤 과정으로 실행하는지, 즉 프로그램이 어떤 절차로 작동하는지를 가장 근본적인 단계에서 하나하나 추적하고 관찰할 수 있기 때문이다.
컴파일 언어와 인터프리터 언어
고급 언어는 어떻게 저급 언어로 변환될까?
컴파일 언어
- 컴파일러에 의해 소스 코드 전체가 저급 언어로 변환되어 실행되는 고급 언어
컴파일(compile): 컴파일 언어로 작성된 코드 전체가 저급 언어로 변화되는 과정컴파일러(compiler): 컴파일을 수행해 주는 도구- 소스 코드 전체를 훑어 문법적인 오류가 있는지, 실행 가능한 코드인지, 불필요한 코드는 없는지 등을 따지며 소스 코드를 처음부터 끝까지 저급 언어로 컴파일한다. 이때 컴파일러가 소스 코드 내에서 오류를 하나라도 발견하면 해당 소스 코드는 컴파일에 실패한다.
인터프리터 언어
- 인터프리터에 의해 소스 코드가 한 줄씩 실행되는 고급 언어
인터프리터(interpreter): 소스 코드를 한 줄씩 저급 언어로 변환하여 실행해 주는 도구- 소스 코드를 한 줄씩 실행하기 때문에 N번째 줄에 문법 오류가 있더라도 N-1번째 줄까지는 올바르게 수행한다.
컴파일 언어와 인터프리터 언어를 칼로 자르듯이 구분될까?
현대의 많은 프로그래밍 언어 중에는 컴파일 언어와 인터프리터 언어 간의 경계가 모호한 경우가 많다. 하나의 프로그래밍 언어가 반드시 둘 중 하나의 방식만으로 작동한다고 생각하는 것은 오개념이다.
이 둘을 칼로 자르듯 구분하기보다는 ‘고급 언어가 저급 언어로 변환되는 대표적인 방법에는 컴파일 방식과 인터프리트 방식이 있다’ 정도로만 이해하는 것이 좋다.
목적 파일과 실행 파일
목적 코드로 이루어진 파일을 목적 파일이라고 부르고, 실행 코드로 이루어진 파일을 실행 파일이라고 부른다. 윈도우의 .exe 확장자를 가진 파일이 대표적인 실행 파일이다.
목적 코드가 실행 파일이 되기 위해서는 링킹(linking)이라는 작업을 거쳐야 한다.
C언어에서 목적 파일은 “*.o” 확장자를 가진다. “main.o” 목적 파일은 저급 언어니까 바로 실행될 수 있을까? 실행할 수 없다. “main.o”는 “main.c” 내용이 그대로 저급 언어로 변환된 파일일 뿐 외부의 기능을 어떻게 실행하는지 알지 못하기 때문이다.
따라서 “main.o”가 실행되려면 “main.o”에 없는 외부 기능들 기능을 “main.o”와 연결 짓는 작업이 필요하다. 이러한 연결 작업이 링킹(linking)이다. 링킹 작업까지 거치면 비로서 하나의 실행 파일이 된다.
명령어의 구조
연산 코드와 오퍼랜드
연산 코드(operation code), 연산자: 명령어가 수행할 연산오퍼랜드(operand), 피연산자: 연산에 사용할 데이터 또는 연산에 사용할 데이터가 저장된 위치
하나의 명령어는 아래 그림과 같이 연산 코드가 담기는 영역인 연산 코드 필드와 오퍼랜드가 담기는 영역인 오퍼랜드 필드로 구성된다.

오퍼랜드
오퍼랜드 필드에는 숫자와 문자 등을 나타내는 데이터 또는 메모리나 레지스터 주소가 올 수 있다. 다만 오퍼랜드 필드에는 숫자나 문자와 같이 연산에 사용할 데이터를 직접 명시하기보다는, 많은 경우 연산에 사용할 데이터가 저장되는 위치, 즉 메모리 주소나 레지스터 이름이 담긴다. 그래서 오퍼랜드 필드를 주소 필드라고 부르기도 한다.
오퍼랜드는 명렁어 안에 하나도 없을 수도 있고, 한 개, 두 개, 세 개등 여러 개가 있을 수 있다. 오퍼랜드 개수의 따라 0-주소 명령어, 1-주소 명령어, 2-주소 명령어, 3-주소 명령어 등이라고 부른다.
연산 코드
가장 기본적인 연산 코드 유형은 크게 네 가지로 나눌 수 있다.
- 데이터 전송
- 산술/논리 연산
- 제어 흐름 변경
- 입출력 제어
이 네 가지 유형 각각에 해당하는 대표적인 연산 코드는 아래와 같다. 연산 코드의 종류와 생김새는 CPU에 따라 다르다.




주소 지정 방식
왜 오퍼랜드 필드에 메모리나 레즈스터의 주소를 담는가? <연산 코드, 연산 코드에 사용될 데이터> 형식으로 명령어를 구성하면 되지 않는가?
→ 명령어 길이 때문.
하나의 명령어가 n비트로 구성되어 있고 그 중 연산 코드 필드가 m비트라면 1-주소 명렁어라고 해도 오퍼랜드 필드에 n-m 비트 밖에 할당하지 못한다.
만약 오퍼랜드 필드 안에 메모리 주소가 담긴다면 표현할 수 있는 데이터의 크기는 하나의 메모리 주소에 저장할 수 있는 공간만큼 커진다.
유효 주소(effective address): 연산 코드에 사용할 데이터가 저장된 위치, 즉 연산의 대상이 되는 데이터가 저장된 위치주소 지정 방식(addressing mode): 오퍼랜드 필드에 데이터가 저장된 위치를 명시할 때 연산에 사용할 데이터 위치를 찾는 방법
즉시 주소 지정 방식
- immerdiate addressing mode
- 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시
- 표현할 수 있는 데이터의 크기가 작아진다.
- 연산에 사용할 데이터를 메모리나 레지스터로부터 찾는 과정이 없기 때문에 이하 설명할 주소 지정 방식들보다 빠르다.

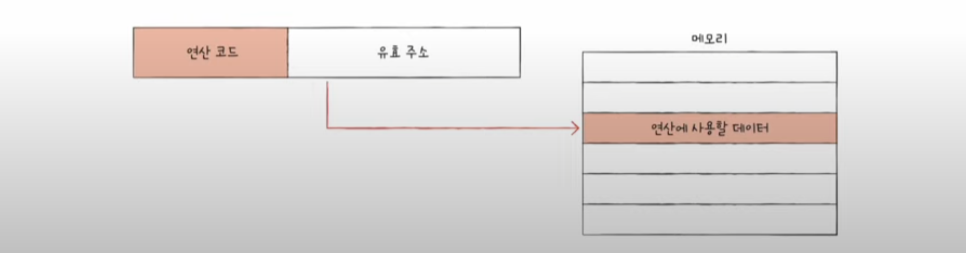
직접 주소 지정 방식
- direct addressing mode
- 오퍼랜드 필드에 유효 주소를 직접적으로 명시
- 데어터의 크기는 즉시 주소 지정 방식보다 더 커졌다.
- 표현할 수 있는 오퍼랜드 필드의 길이가 연산 코드의 길이만큼 짧아져 표현할 수 있는 유효 주소에 제한이 생길 수 있다.
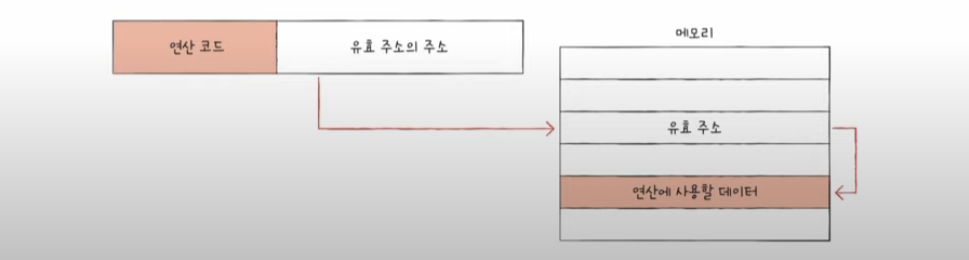
간접 주소 지정 방식
- indircet addressing mode
- 유효 주소의 주소를 오퍼랜드 필드에 명시
- 직접 주소 지정 방식보다 표현할 수 있는 유효 주소의 범위가 더 넓어졌다.
- 두 번의 메모리 접근이 필요하여 위의 방법들보다 느리며 메모리를 더 차지한다.
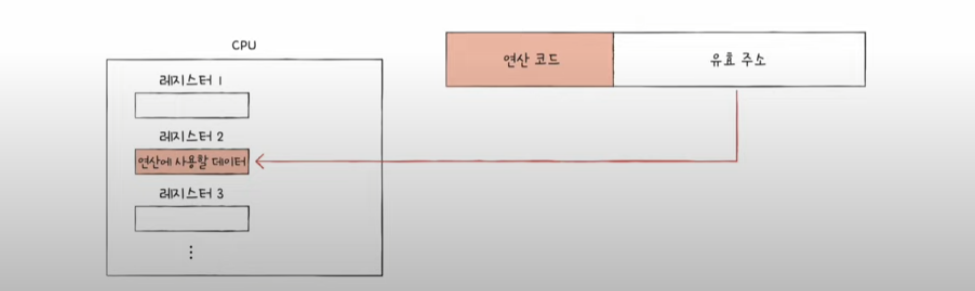
레지스터 주소 지정 방식
- register addressing mode
- 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시
- CPU 외부에 있는 메모리에 접근하는 것보다 내부에 있는 레지스터에 접근하는 것이 더 빠르므로 직접 주소 지정 방식보다 더 빠르게 데이터에 접근할 수 있다.
- 직접 주소 지정 방식과 비슷한 문제를 공유 → 표현할 수 있는 레지스터 크기에 제한이 생길 수 있다.
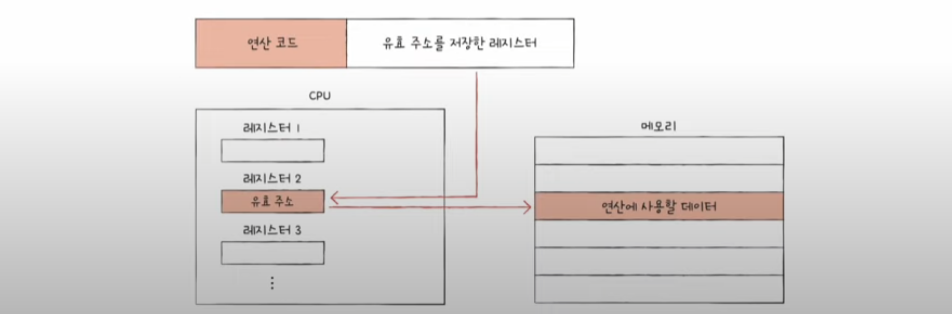
레지스터 간접 주소 지정 방식
- register indirect addressing mode
- 연산에 사용할 데이터를 메모리에 저장하고, 그 주소(유효 주소)를 저장한 레지스터를 오퍼랜드 필드에 명시
- 메모리에 접근하는 횟수가 한 번이다.
- CPU 내부에 있는 레지스터에 접근하므로 간접 주소 지정 방식보다 빠르다.
스택과 큐
- 스택(stack)
- 한쪽 끝이 막혀 있는 통과 같은 저장 공간
LIFO(Last In First Out): 나중에 저장한 데이터를 가장 먼저 빼내는 데이터 관리 방식PUSH: 새로운 데이터를 저장하는 명령어POP: 저장된 데이터를 꺼내는 명령어
- 큐(Queue)
- 양쪽이 뚫려 있는 통과 같은 저장 공간
FIFO(First In First Out): 가장 먼저 저장된 데이터부터 빼내는 데이터 관리 방식메모리 주소나 레지스터 이름이 담긴다. 그래서 오퍼랜드 필드를주소 필드라고 부르기도 한다.
참고
