Global Vectors for Word Representation (GloVe)
이전 모델과의 비교
참고 사항
Word Embedding = Word Vector : 단어를 밀집 벡터 형태로(Dense Vector) 나타내는 것을 말한다. Word Embedding 방식은 여러개가 있다 LSA, Word2Vec, GloVe...etc
Matrix Factorization : Matrix를 인수분해하는 방식이다. SVD도 이것의 일종으로 하나의 큰 행렬을 작은 행렬로 쪼개는 기법이다
corpus : 언어 연구를 위하여 컴퓨터가 텍스트를 가공·처리·분석할 수 있는 형태로 모아 놓은 자료의 집합
Word Embedding(Word Vector)를 구하는 방식에는 크게 두가지가 있다. 첫번째는 단어간의 발생 횟수 통계에 근거하고 matrix-factorization에 의존한다. 비록 전체 데이터에 대한 글로벌 통계 정보를 내포하고 있어 단어의 유사성 검사에는 종종 쓰이지만 word analogy, indicating a sub-optimal vector space structure와 같은 작업에는 성능이 안 좋다. 두번째 방식은 전체 데이터셋이 아닌 작은 윈도우를 이용하여 word vector를 인근의 로컬 윈도우의 문맥 단어만을 이용하여 예측하도록 한다. 이 방식은 단어의 유사성을 뛰어넘어 복잡한 언어적 패턴을 파악하는 것이 가능하지만 반대로 데이터 전체에 대하여 동시 출연 단어 통계(global co-occurrence statistics) 파악을 하는데 어려움을 겪는다.
그러나 GloVe는 global word-word co-occurrence 통계로 학습된 weighted least square model(Weighted Linear Regression이라고도 불림)으로 구성되어 있다. 이 모델은 언어적으로 의미있는 word vector subspace(word vector의 부분 공간)을 생성한다. 이 모델을 통해 우수한 성능의 단어 유추(word analogy)와 단어 유사성 작업을 수행할 수 있다.
Co-occurrence Matrix
X가 동시 출연 단어 통계 행렬(word-word co-occurrence matrix)이라고 할때 Xij가 단어 j가 단어 i의 문맥(윈도우 내)에 출연하는 횟수를 나타낸다.
Xi=∑kXik이 임의의 단어 k가 단어 i의 문맥에 출연하는 횟수를 나타낸 것이다.
마지막으로 Pij = P(wi/wi) = Xij/Xi 를 단어 j가 단어 i의 문맥 내에서 출연할 확률을 나타낸다.
동시 출연 단어 통계 행렬을 채우기 위해서는 전체 문장 데이터셋을 1회 통과시켜 통계를 구해야한다. 데이터셋의 크기가 큰 경우 이것을 계산하는 것이 컴퓨팅 비용이 많이 드는 것이 사실이지만 한번만 계산해주면 되는 점은 다행이라고 할 수 있다.
Least square Objective
Skip-gram 모델에서 보았다시피 단어 j가 단어i의 문맥 안에 출연할 확률을 Qij를 softmax를 통해 계산하는 것을 기억해 보자.
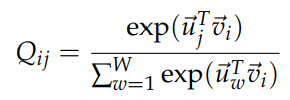
학습 과정은 비록 on-line, stochastic 하게 진행되지만(전체 데이터셋이 아니라 데이터 한개에 대해 매번 Loss 계산) global cross-entropy loss는 다음과 같이 계산되는 것이 가능하다.
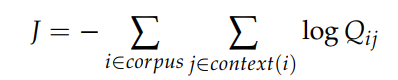
말뭉치(corpus)에서 같은 단어 i와 j가 여러번 출연하는 것도 가능하기 때문에 같은 단어를 묶어서 Loss를 표현하는 것이 더 효율적이다.
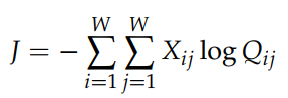
이때 X는 동시 출연 단어 통계 행렬이다. Cross-entropy loss의 크나큰 단점 하나는 Q의 분포가 올바르게 정규화가 되어야 한다는 점이다. 정규화가 이루어지기 위해서는 전체 단어(entire vocabulary space)에 대하여 합산을 하는 비싼 계산 과정이 필요하다. 따라서 우리는 least-square objective(최소제곱 목적함수)를 사용하여 P& Q의 정규화 인수를 제거한다.
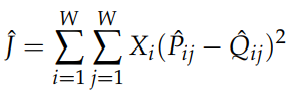
Pij=Xij 이고 Qij=exp(uTjvi)인 정규화되지 않은 분포를 나타낸다. 위와 같은 분포를 사용하는 것은 새로운 문제가 발생한다.
- -Xij 이 큰 값을 가질때가 있고 이것을 최적화를 하는데 어려움이 있다.
-> (log P hat - log Q hat)2의 최소값을 찾으면 error를 효과적으로 계산을 할 수 있다.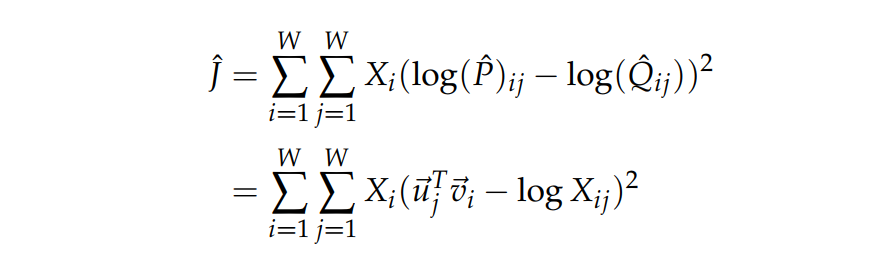
여기서 또 다른 문제가 있다. - 가중치 Xi가 최적화된 가중치라는 보장이 없다.
-> 문맥 단어에 더 상관성이 있도록 조정할 수 있는 가중치 함수를 사용한다
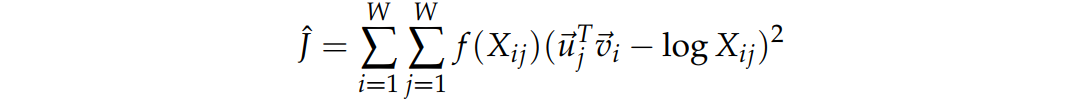
결론
GloVe 모델이 Global statistical information(전체 데이터에 대한 동시 출연 단어 통계 X)의 0이 아닌 원소에 대해서만 학습을 하기에 효과적이며 언어적으로 의미있는 벡터 공간을(Vector space with meaningful sub-structure) 생성할 수 있다. 또한 word2vec에 비해 같은 말뭉치(corpus), 단어 공간, 윈도우 크기, 학습 시간이 주어졌을 때 word analogy task에서 뛰어난 성능을 보인다.
Evaluation of Word Vectors
Word2Vec 혹은 GloVe 모델로 만들어진 자연어 벡터는 정량적으로 그 퀄리티를 평가할 수 있을까?
Intrinsic Evaluation
Intrinsic evaluation은 단어 벡터가 특정 작업의 중간 과정 작업(ex Analogy completion)의 성능을 평가하는 방식이다. 이 subtask는 대체로 간단하고 빠르게 계산할 수 있다. Intrinsic evaluation은 특정 작업을 수행하는 성능을 나타낼 수 있는 숫자를 반환한다.
- Intrinsic 방식을 통해 우리는 subsystem에 대해 이해할 수 있다
- Intrinsic 방식은 실제하고자 하는 작업(real task)와 평가에 쓰이는 subtask의 양의 상관 관계가 있어야 평가 지표표가 우수한 성능으로 이어진다.
자주 사용되는 Intrinsic Evaluation 방식 중 하나는 word vector analogy를 완성하는 성능을 측정하는 것이다. 이것은 a단어와 b단어의 관계를 통해 c와 이런 관계에 놓여있는 단어를 찾아내는 작업이다. Intrinsic Evaluation은 단어 벡터의 cosine similarity를 최대로 만들어주는 단어를 찾아낸다.
a : b:: c : ?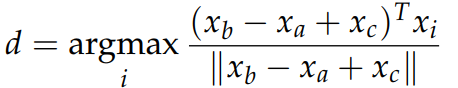
Extinsic Evaluation
Extrinsic evaluation은 실제 NLP 작업을 통해 단어 벡터의 성능을 평가하는 방식이다. 단어 벡터의 정확도를 평가하는데에 시간이 오래 걸릴 수 있다. 또한 문제점이 발견되었을 때 subsystem 자체 문제인지 subsystem 간의 interaction 문제인지 명확하게 알기 어렵다는 단점이 있다. 만약 하나의 subsystem을 다른 subsystem으로 바꿔서 extrinsic evalution 값이 개선된다면 전체 성능의 개선으로 이어진다.(Intrinsic Evaluation에서는 보장되지 않음)
일반적으로 머신러닝을 트레이닝할 때 입력 데이터와 정답 레이블은 고정시켜놓고 가중치를 최적화시켜 모델의 출력이 정답 레이블에 근접하도록 학습을 진행한다. 그러나 NLP에서는 extrinsic task를 위한 학습을 진행할 때는 입력 단어 벡터를 재학습을 시킨다. Extrinsic task에 사용하는 단어 벡터는 간단한 intrinsic task로 초기화된 단어 벡터들이다. Intrinsic task로 초기화된 단어 벡터들이 extrinsic task에서 더 좋은 성능을 발휘하기 위해 재학습을 시키게 되는 것이다. 단, extrinsic task를 통해 단어 벡터를 재학습시키는 경우에 대부분의 단어를 커버할 수 있을만큼 많은 양의 학습 데이터가 필요하다. 그 이유는 적은 양의 데이터로 학습을 시킬 경우 단어 벡터 공간 상에서 원하지 않는 위치로 벡터가 이동될 수 있기 때문이다.
