Word Vectors
우리는 NLP task에 단어를 입력으로 사용한다. NLP task를 수행하기 위해서는 단어간의 유사성과 차별성을 파악/적용할 수있어야 한다. 영어에는 1300만 개의 단어가 있고 서로 연관성이 있는 단어들이 많다. 단어들을 벡터로 표현하고 그 공간안에서 유사성을 내포할 수 있는 N 차원 벡터 공간이 존재할 것이다(N << 13 million).
1. One-hot encoded Vector
 각각의 단어를 |V|(Vocabulary 수) 차원의 벡터 공간에 하나의 차원의 원소만을 1로 가지고 나머지 차원의 값은 0인 벡터로 나타내는 방법이 있다. 즉, 단어의 개수만큼의 벡터 차원이 있어야 한다.
각각의 단어를 |V|(Vocabulary 수) 차원의 벡터 공간에 하나의 차원의 원소만을 1로 가지고 나머지 차원의 값은 0인 벡터로 나타내는 방법이 있다. 즉, 단어의 개수만큼의 벡터 차원이 있어야 한다.
문제점 :
- word vector가 모두 orthogonal하기에 단어간의 유사성을 내포할 수 없다.
- 단어를 나타내기 위해 사용하는 벡터의 크기가 너무 크고 정보의 밀도가 낮다
유사성을 내포할 수 있는 더 작은 차원의 벡터 공간에 단어를 나타내야 한다. 또한 벡터들이 스스로 유사성을 학습/유포할 수 있도록 해야한다.
2. SVD based Methods
Distributional Semantics : 단어의 의미는 같이 등장하는 문맥 단어를 통해 결정할 수 있다
아이디어 : 단어 w가 문장에서 등장할 때 고정된 사이즈의 윈도우 안에 등장하는 단어를 문맥으로 정의하고 많은 양의 문장 속 w 단어 문맥을 통해 w의 vector representation을 구한다.
Word Document Matrix
"유사한 단어들은 같은 문서에 자주 등장할 것이다"라는 추측을 통해 word-document matrix X가 만들어진다. 많은 양의 문서를 순차적으로 분석하면서 단어간 같이 등장하는 횟수를 matrix로 만든다.
word i 가 document j에 등장할 때마다 X~ij
Applying SVD to Cooccurrence Matrix
X에 SVD를 적용한다. 고유값(Singular Value)를
SVD란?
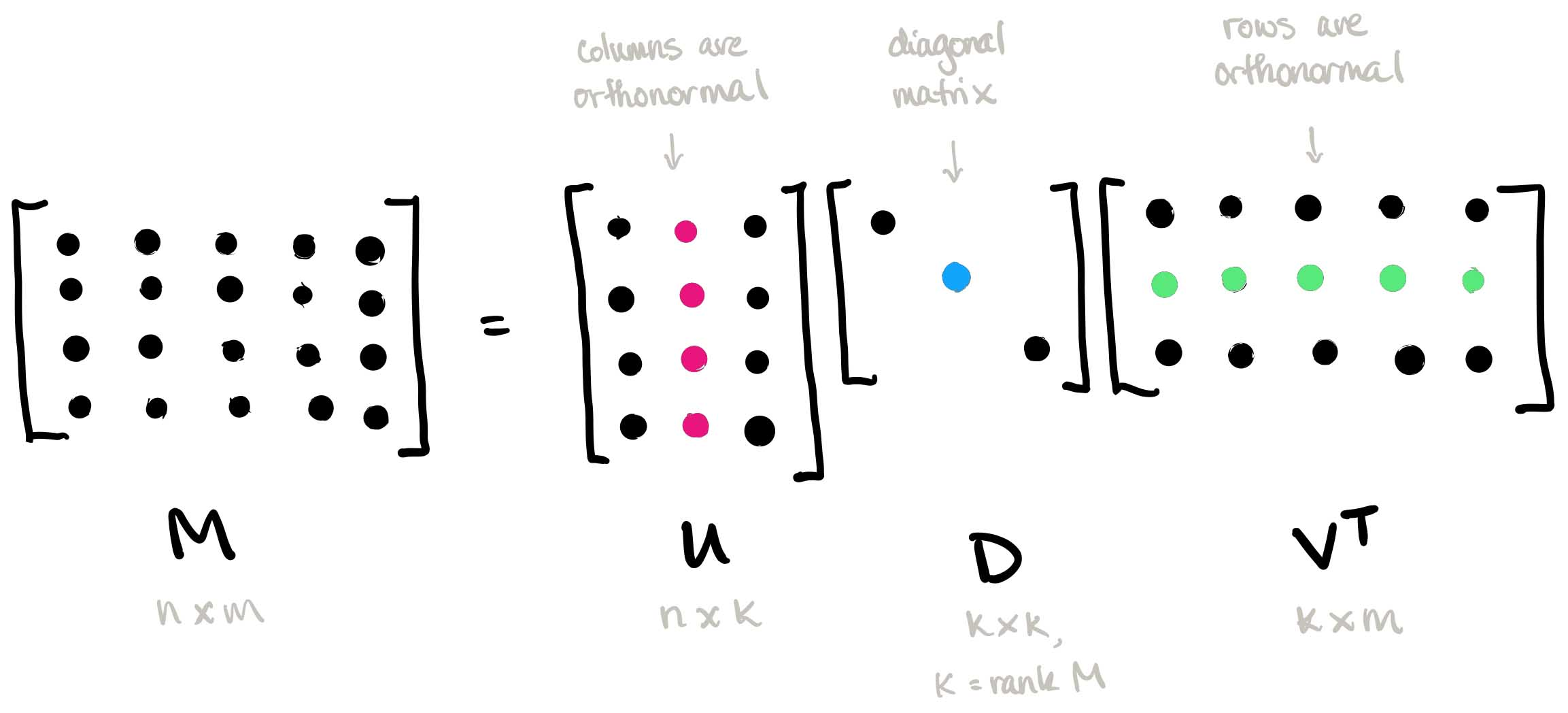
모든 행렬 M은 다음과 같이 쪼개질 수 있다. 행렬을 다음과 같이 쪼개는 것을 M에 SVD를 적용한다고 한다.
M=UDV
행렬 D의 대각선에 있는 음이 아닌 값들을 Singular Value라고 부르고 대각선 원소의 개수 k가 M의 Rank와 같다. 또한 U와 V는 각각 K개의 열과 행을 가지고 있고 Left Singular Vector와 Right Singular Vector라고 불린다. 주로 D에서 각 대각선에 있는 고유값들은 1행부터 내림차순으로 값이 크며 담고 있는 정보의 양이 많아 그 중요도도 크다.
k < |V|인 K개의 Singular vector를 선택하여 U,D,V를 나타내기 위해 필요한 차원을 줄일 수 있다.
문제점
- 새로운 단어들이 추가되면 단어 행렬의 차원이 변한다.
- 대부분의 단어들은 서로 같이 등장하지 않기 때문에 행렬이 밀도가 낮고 0인 값들이 많다.
- SVD를 연산하기 위해서 mXn Matrix일때 O(mn^2)이 필요함
- 각 단어 자체의 출연 빈도의 불균형을 맞춰줄 방법이 필요하다
해결책
- "the", "he", "has" 등의 기능적인 역할을 하는 단어들은 무시하고 cooccurence matrix를 만든다
- 단어와 단어 사이의 떨어진 정도를 고려하여 가중치가 다르게 하여 cooccurrence matrix를 만든다
- Pearson Correlation을 통해 음의 카운팅도 도입한다
3. Word2Vec
새로운 접근 : 전체 데이터셋에 대한 정보를 저장하는 것이 아니라 반복적인 학습으로 점차 문맥 속에서 각 단어의 출연 확률을 익히게 한다
Iteration based method로 알려진 Word2Vec은 충분히 많은 데이터가 주어진다면 그 단어의 의미, 단어간의 관계, 문맥등을 벡터 공간상 하나의 점으로 학습시킬 수 있다.
Word Vector를 학습하기 위한 알고리즘은 크게 2가지가 있다 : 1) CBOW 2) Skip-gram
CBOW
CBOW 모델은 문맥 단어를 통해 타겟 단어/ 중심 단어를 예측하는 모델이다. 타켓 단어 주위로 윈도우가 있고 이 윈도우 안에 있는 단어들을 문맥 단어라고 가정한다. 모델에 문맥 단어들을 입력으로 넣었을 때 목표 단어가 나오도록 모델의 hidden layer의 weight matrix를 학습시킨다. "Have a great day"라는 문장이 있을 경우
Skip-gram
Skip-gram은 중심 단어를 기준으로 문맥 단어의 확률 분포를 찾는 알고리즘이다.
