RAG 처음부터 고도화까지 — 1편: RAG가 뭐고, 성능은 어디서 결정되는가
시리즈 「RAG 처음부터 고도화까지」 — 5부작.
이 글은 1부. RAG가 뭔지, 어디서 성능이 결정되는지부터.
0. 왜 이 글을 쓰나
회사 안에서 RAG 시스템을 한 달 굴려보면 성능 차이가 어디서 나오는지 가 보입니다. 같은 LLM (Gemma·Qwen·GPT-4o) 을 써도, 누구는 RAGAS faithfulness 0.6 을 못 넘기고 누구는 0.85 를 찍습니다.
차이는 거의 LLM이 아니라 검색 쪽 에 있습니다. 청킹 / 임베딩 / 검색 / 재정렬 / 프롬프트 — 이 5개 축에서 합산된 격차가 답변 품질로 나옵니다.
이 시리즈에서 "같은 LLM에서도 RAG 성능을 두 배로 끌어올리는 기법들" 을 0부터 정리합니다. 코드 데모는 곁들이지만, 환경 셋업/배포 같은 무거운 인프라 얘기는 다른 곳에 양보합니다.
1. RAG가 뭔가
LLM 한 통의 문제 3가지:
- 지식 cutoff — 사내 문서·사내 약어·어제 작성된 PR 같은 건 모름
- 토큰 한도 — 100만 토큰까지 받는 모델도 PDF 50권 전체는 못 받음. 받아도 답변 품질 떨어짐
- 환각 — 모르는 걸 그럴듯하게 만들어 답함
RAG = Retrieval-Augmented Generation — "필요한 부분만 찾아서 LLM에게 보여주는" 접근.
사용자 질문 → 비슷한 문서 조각 N개 검색 → 그 조각들을 근거로 LLM이 답변이게 핵심 아이디어 한 줄. 나머지는 전부 이 한 줄을 어떻게 정교화하느냐 의 문제입니다.
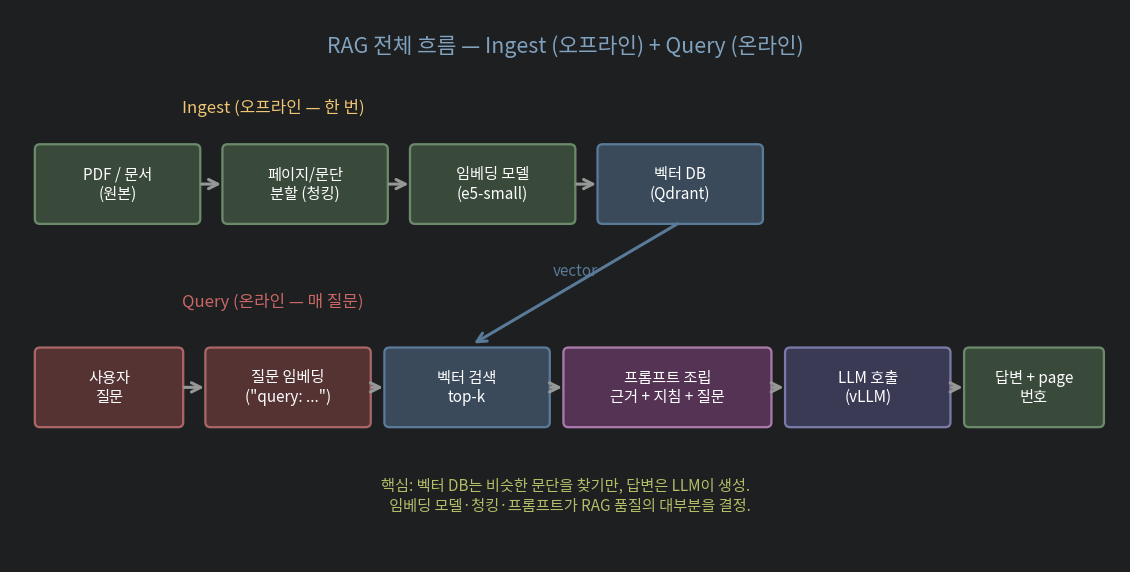
두 단계가 독립적:
- Ingest (오프라인 / 한 번) — 원본 문서를 잘라서 임베딩 → 벡터 DB 적재
- Query (온라인 / 매 질문) — 질문도 임베딩 → 비슷한 문단 검색 → 프롬프트 조립 → LLM 호출
2. 임베딩과 벡터 검색 — 기초만
이 시리즈를 보는 사람의 기준선:
- 임베딩 모델 은 텍스트를 N차원 실수 벡터(보통 384~1024차원) 로 매핑하는 모델. 학습 목표는 "의미가 가까우면 벡터도 가깝게".
- 벡터 DB 는 그 벡터들을 빠르게 검색하는 인덱스. 대표적으로 Qdrant, Milvus, Weaviate, pgvector. 정확한 KNN 대신 HNSW 같은 근사 알고리즘으로 millisecond 단위 검색.
- 검색 단위 는 cosine similarity / inner product. 정규화된 벡터끼리는 둘이 같음.
벡터 DB는 답을 만들지 않습니다. "질문 벡터와 비슷한 문서 벡터" 를 빠르게 가져올 뿐. 답은 LLM이 만듭니다.
3. 가장 단순한 RAG — 70줄
이 시리즈의 출발점은 이런 "naive RAG":
# 인덱싱
chunks = pdf.split_by_page()
vectors = embedder.encode(chunks)
qdrant.upsert(vectors, payloads=chunks)
# 질의
q_vec = embedder.encode(question)
hits = qdrant.search(q_vec, top_k=3)
context = "\n\n".join(h.text for h in hits)
prompt = f"근거:\n{context}\n\n질문: {question}\n\n근거만 사용해서 답해라."
answer = llm.chat(prompt)PoC 는 이거로 됩니다. 회사 PDF 한 권 정도면 어느 정도 답합니다.
그런데 운영 환경에서 다음 케이스에 약합니다:
- 질문이 짧고 모호함 — "레이어 그리는 순서?" 정도면 임베딩 유사도가 부정확
- 고유명사 / 식별자 — "NXImageView" 같은 토큰은 dense 임베딩이 잘 못 잡음 (BM25 가 강함)
- 페이지 하나가 너무 큼 — 800자 페이지 안에 5개 주제가 섞여 있으면 임베딩 한 벡터에 다 들어감
- 검색 결과가 약해도 LLM이 그럴듯하게 답함 — 환각
- 반복 질문 + 같은 페이지 반복 인용 — top-3 가 모두 page 24 의 다른 청크면 다양성 0
- 사용 중에 모르는 게 들어왔는데 LLM이 거짓말함 — 검색을 신뢰할지 의심할지 모름
이 6가지를 각각 잡는 게 시리즈의 나머지 부분입니다.
4. RAG 성능을 결정하는 5개 축

| 축 | 무엇 | 자주 쓰는 개선 기법 |
|---|---|---|
| ① 청킹 | 문서를 어떻게 자르나 | recursive · semantic · Small-to-Big · proposition |
| ② 임베딩 | 어떤 벡터로 매핑 | e5 / bge-m3 / Cohere · 도메인 fine-tune |
| ③ 검색 | 후보를 어떻게 가져오나 | Dense · BM25 · Hybrid · Query 변환 (HyDE) |
| ④ 재정렬 | 후보 중 무엇을 쓸까 | Cross-encoder · LLM-as-Reranker · MMR |
| ⑤ 생성 | 근거로 답을 짜기 | 프롬프트 · Self-RAG · CRAG · Adaptive |
업계에서 "임베딩·청킹·검색이 RAG 성능의 80% 를 만든다" 는 말이 있습니다. LLM 교체보다 보통 이 5축 중 어느 하나를 개선하는 게 효과가 큽니다.
같은 LLM·같은 PDF 에서 청킹 + 재정렬만 정교화해도 RAGAS faithfulness 가 0.6 → 0.85 까지 올라가는 사례를 흔히 봅니다.
5. 이 시리즈의 진행 순서
각 축을 한 편씩 다룹니다.
| Part | 다루는 축 | 핵심 기법 |
|---|---|---|
| 1. (지금 글) | 개요 | 문제 정의 + 5개 축 + 시리즈 로드맵 |
| 2 | ① 청킹 + ② 임베딩 | recursive · semantic · Small-to-Big · multi-vector · 메타데이터 |
| 3 | ③ 검색 + ④ 재정렬 | Multi-Query · HyDE · Hybrid+RRF · Cross-encoder · LLM Rerank · MMR |
| 4 | ⑤ 생성 + 평가 | 프롬프트 · Self-RAG · CRAG · Adaptive RAG · RAGAS |
| 5 | 고급 아키텍처 | Agentic RAG · GraphRAG · RAPTOR · semantic caching |
6. 본론 가기 전, 마음가짐 두 개
6.1. "더 큰 LLM" 이 답이 아니다
처음 RAG 만들고 답변이 약하면, 대부분 "LLM 을 GPT-4o 로 바꿔봐야지" 가 첫 시도가 됩니다. 보통은 효과가 작습니다.
검색이 잘못된 근거를 끌어와서 LLM 에 주면, GPT-4o 도 그 잘못된 근거 기반으로 답합니다. 모델은 검색 품질의 상한이 아니라 검색 품질에 종속됩니다.
6.2. 측정 안 하면 모른다
"이 청킹 전략이 더 좋아요" 같은 글이 인터넷에 많지만, 본인의 문서·본인의 질문에서 정말 그런지는 측정해 보기 전까진 모릅니다. 본 시리즈에서 RAGAS 같은 평가 도구를 별도 편으로 다룹니다.
측정 가능한 RAG 만 운영 가능한 RAG 입니다. "성능 끌어올린다" 는 이 시리즈의 모든 글이 결국 "RAGAS 4지표 중 어느 걸 올리는가" 로 환원됩니다.
