RAG 처음부터 고도화까지 — 2편: Indexing 최적화 (청킹 + 임베딩 + 메타데이터)
시리즈 「RAG 처음부터 고도화까지」 — 2부.
1편: 개요 + 5개 축 을 먼저.
이번 글의 목표
5개 축 중 ① 청킹 + ② 임베딩 (Indexing 단계) 의 정교화. 이 두 축은 RAG 가 시작도 하기 전에 결정되는 부분이라, 잘못 잡으면 이후 모든 retrieval/reranker 가 회복 불가능한 손해를 봅니다.
다룰 것:
- 청킹 전략 6종 + 각 트레이드오프
- Small-to-Big (parent-child) — 가장 자주 쓰는 패턴
- Sentence Window / Auto-Merging — 같은 가족
- Multi-vector indexing — 한 청크에 여러 표현 임베딩
- 임베딩 모델 선택 가이드
- 메타데이터 — 무조건 박아두자
1. 청킹 전략 — 종류와 트레이드오프
청킹은 문서를 검색 단위로 자르는 일. 단위가 너무 크면 한 벡터에 여러 의미가 섞여 검색 정밀도가 떨어지고, 너무 작으면 검색은 정확하지만 LLM 에게 문맥이 부족합니다.
1.1. Fixed-size
500자씩 자르고 50자 overlap가장 쉽고 가장 안 좋은 방법. 문장 한가운데 잘리는 일이 흔하고, 문단/섹션 경계 무시.
적합한 곳: 거의 없음. 첫 PoC 용.
1.2. Sentence
문장 단위로 자르고 N문장씩 묶기문장 경계는 살아남지만, 의미 단위(문단/섹션)는 깨짐.
적합한 곳: 짧은 답변이 많은 도메인 (FAQ, 일문일답).
1.3. Recursive (구조 기반)
큰 단위(섹션) 시도 → 너무 길면 문단 → 그래도 길면 문장 → 그래도 길면 단어LangChain 의 RecursiveCharacterTextSplitter 가 대표. Markdown / HTML / 코드는 헤더·태그 기준으로 더 정교한 splitter (MarkdownHeaderTextSplitter 등) 가 있음.
적합한 곳: 사실상 일반 텍스트의 디폴트. 첫 시도는 이거.
1.4. Semantic (Context-Aware Partitioning)
# 의사코드
sentences = split_into_sentences(doc)
embeds = embedder.encode(sentences)
boundaries = []
for i in range(1, len(sentences)):
sim = cosine(embeds[i], embeds[i-1])
if sim < THRESHOLD: # 의미가 멀어진 지점 = chunk 경계
boundaries.append(i)문장간 임베딩 유사도가 갑자기 떨어지는 지점을 경계로. 고정 크기 청킹의 임의 절단 문제를 해결합니다. 2026 년 enterprise RAG 에서 dominant 패턴.
적합한 곳: 주제가 자주 바뀌는 긴 문서 (백서, 사설, 다중 토픽 보고서).
1.5. Proposition-based
원문 한 단락 → LLM이 "원자적 사실문 N개" 로 분해
"RAG 는 검색 + 생성을 결합한다."
"벡터 DB 는 답을 만들지 않는다."
...
→ 각 명제 자체를 청크로 임베딩명제 단위로 의미가 명확해서 검색 정밀도가 매우 높아짐. 비용: LLM 호출이 ingest 단계에 폭증.
적합한 곳: 사실 위주 도메인 (의료·법률·표준 문서).
1.6. Structure-aware
PDF·DOCX·HTML 의 구조를 그대로 활용:
- 헤더 → chunk 시작
- 표 → 표 단위로 한 chunk
- 코드 블록 → 코드 단위로 한 chunk
라이브러리 (Unstructured, LlamaIndex Pipeline) 가 이런 단계를 일부 자동화. PDF 면 PyMuPDF + 헤더 감지 / DOCX 면 python-docx / HTML 이면 BeautifulSoup.
적합한 곳: 구조가 살아있는 문서 — 사내 매뉴얼, 기술 문서, 보고서.
1.7. 청크 사이즈 가이드라인
| 문서 종류 | 권장 크기 | overlap |
|---|---|---|
| 단답 FAQ | 200~400 토큰 | 0~20 |
| 일반 사내 문서 | 400~800 토큰 | 50~100 |
| 학술/장문 | 800~1500 토큰 | 100~200 |
| 표·코드 위주 | 구조 단위로 (사이즈 무시) | 0 |
임베딩 모델의
max_seq_length도 고려. e5-small 은 512 토큰까지. 그 이상은 잘려서 임베딩 됨.
2. Small-to-Big — 가장 자주 쓰이는 패턴
위 청킹 전략에 공통된 딜레마: 검색 정밀도와 답변 컨텍스트가 trade-off 입니다.
- 작은 청크 → 검색 정밀 ↑, 컨텍스트 부족 ↓
- 큰 청크 → 컨텍스트 충분 ↑, 검색 정밀도 ↓
해결: 검색은 작은 청크로, 답변은 큰 부모로. 흔히 Small-to-Big 또는 Parent-Child 패턴.
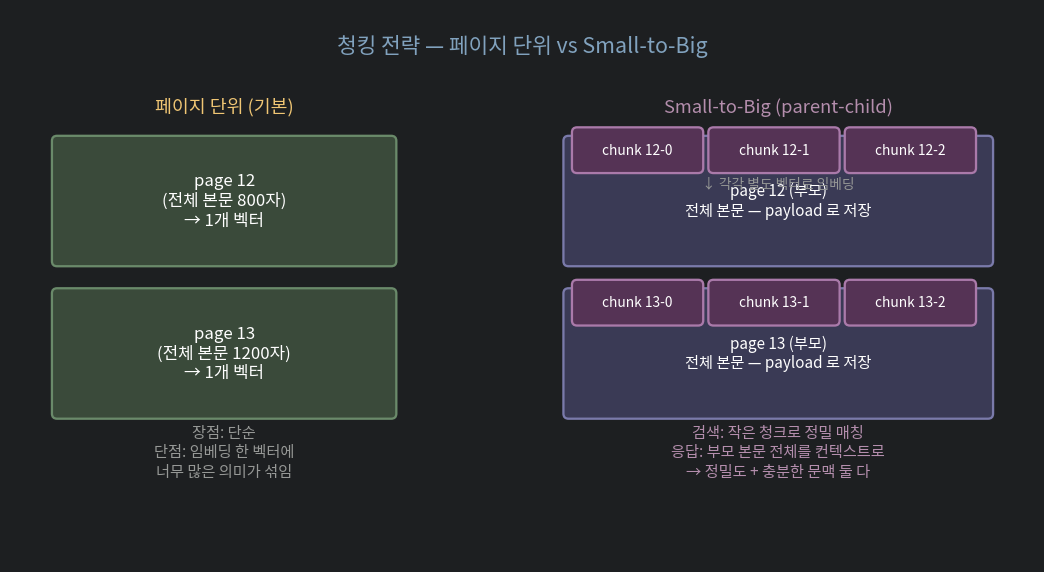
구현 골격:
chunks = []
for page in document.pages:
paragraphs = split_paragraphs(page.text)
for j, para in enumerate(paragraphs):
chunks.append({
"chunk_id": f"{page.num}-{j}",
"text": para, # ★ 검색·임베딩 단위 (작은 청크)
"parent_text": page.text, # ★ 답변 시 보낼 부모 본문
"page": page.num,
})
# Qdrant 적재: text 만 임베딩, parent_text 는 payload로검색 시:
hits = qdrant.search(q_vec, top_k=5)
# 답변 시 부모(page) 중복 제거
seen, ctx = set(), []
for h in hits:
if h.payload["page"] in seen: continue
seen.add(h.payload["page"])
ctx.append(h.payload["parent_text"])
prompt = "...\n근거:\n" + "\n\n".join(ctx) + f"\n질문: {q}"이 한 패턴만으로도 RAGAS context_recall 이 0.55 → 0.78 까지 올라가는 게 흔합니다.
2.1. 가족 패턴 — Sentence Window / Auto-Merging
같은 아이디어의 변형:
- Sentence Window — 검색은 1~3문장 단위, 답변 시 그 앞뒤 N개 문장 동봉
- Auto-Merging — 작은 청크 여러 개가 같은 부모에서 매치되면 부모 전체로 자동 merge
세 패턴 다 본질이 같음: 검색 단위와 답변 단위를 분리.
3. Multi-Vector Indexing — 한 청크에 여러 표현
청크 본문 자체로만 임베딩하면, "본문에는 안 나오지만 이 청크가 답할 수 있는 질문" 은 잘 못 찾습니다. 같은 청크를 여러 다른 표현으로 동시에 임베딩 합니다.
3.1. Summary 임베딩
for c in chunks:
summary = llm.summarize(c.text, max_words=30)
qdrant.upsert(
embedder.encode(summary),
payload={"text": c.text, "kind": "summary"})긴 청크의 핵심을 LLM 이 요약. 검색 시 요약 임베딩이 먼저 매치 → 본문 회수.
3.2. Hypothetical Questions 임베딩
for c in chunks:
questions = llm.generate("이 본문에 대해 사용자가 할 만한 질문 3개를 만들어라.", c.text)
for q in questions:
qdrant.upsert(
embedder.encode(q),
payload={"text": c.text, "kind": "q"})질문 ↔ 질문 매칭이 질문 ↔ 본문 매칭보다 임베딩 유사도가 훨씬 높습니다. 사용자가 던질 질문을 LLM 이 미리 예측해서 임베딩 인덱스에 박아둠.
3.3. 컴비네이션
컬렉션 1: chunk.text 자체 임베딩
컬렉션 2: chunk.summary 임베딩
컬렉션 3: chunk.hypothetical_questions 임베딩검색은 세 컬렉션 동시 → 결과 합쳐서 dedupe by chunk_id. 비용은 ingest LLM 호출이 청크 수만큼 늘어남, 대신 retrieval 정확도가 큰 폭으로 개선.
한 번 indexing 비용을 들이고, 매 query 에 두고두고 효과를 본다 — 비대칭 비용 / 효과의 좋은 사례.
4. 임베딩 모델 선택
| 모델 | 차원 | 크기 | 특징 |
|---|---|---|---|
intfloat/multilingual-e5-small | 384 | ~470MB | 다국어 · 작고 빠름 · 한국어 OK |
intfloat/multilingual-e5-base | 768 | ~1.1GB | 위 + 정확도 ↑ |
intfloat/multilingual-e5-large | 1024 | ~2.2GB | 정확도 ↑↑ · 메모리 ↑↑ |
BAAI/bge-m3 | 1024 | ~2.3GB | 다국어 최강급 · dense + sparse + multi-vec 동시 |
Cohere embed-multilingual-v3.0 | 1024 | API | API 호출 · 외부 의존 |
text-embedding-3-small (OpenAI) | 1536 | API | 비용 발생 · 외부 의존 |
jinaai/jina-embeddings-v3 | 1024 | ~3GB | 매트료시카 (차원 가변) |
4.1. 선택 기준
- 로컬 / 한국어 위주 →
multilingual-e5-small로 시작, 정확도 부족하면e5-base또는bge-m3 - 다국어 + 검색 정확도가 결정적 →
bge-m3(Part 3 의 hybrid 와 자연스럽게 짝지음) - 외부 API OK · 운영 단순화 우선 →
Cohere embed-v3또는OpenAI text-embedding-3-large
4.2. 도메인 fine-tuning
오픈모델 (e5, bge, gte) 은 본인 도메인 데이터로 fine-tune 가능. sentence-transformers + contrastive loss + (질문, 정답 청크) 쌍 1만 개만 있으면 base 모델 위에 1~2시간 LoRA 학습으로도 보통 5~10% 검색 정확도가 오릅니다.
도메인 약어/은어가 많은 사내 RAG 에서 ROI 가 가장 높은 투자.
4.3. passage: / query: prefix
e5 류 임베딩 모델은 학습 규약상 prefix 가 필수:
embedder.encode([f"passage: {doc}" for doc in docs]) # 저장(문서)
embedder.encode([f"query: {question}"]) # 검색(질문)붙이지 않으면 검색 정확도 5~15% 떨어짐. 모델별 README 확인 필수 — bge 는 안 씀, e5 는 씀.
5. 메타데이터 — 그냥 다 박아두자
청크 payload 에 메타데이터를 풍부하게 박아두면 이후의 모든 기능이 그 위에서 굴러갑니다.
payload = {
"text": chunk_text,
"parent_text": full_section,
"page": 24,
"section": "3.2 Layer 렌더링",
"doc_id": "XDL3.0_guide_2026q2",
"doc_type": "manual", # manual / spec / faq / release_note
"author": "platform_team",
"created_at": "2026-04-15",
"language": "ko",
"version": "3.0",
"tags": ["layer", "rendering"],
}이게 있으면:
- 필터링 —
WHERE doc_type='manual' AND created_at > '2026-01-01' - 다중 컬렉션 라우팅 — 사용자 권한별로 가시 영역 분리
- 시간 가중치 — 최신 문서에 보너스
- 출처 표기 — 답변과 함께
(매뉴얼 3.0 §3.2, page 24, platform_team)표시 - 운영 디버깅 — 잘못 답한 케이스의 원인 청크 즉시 찾기
메타데이터는 운영 RAG 의 의외의 핵심. 한 번 안 박아두면 나중에 다시 인덱싱해야 합니다. 그러니까 첫날부터 풍부하게.
5.1. Self-Querying — 메타데이터로 자동 필터
LLM 이 사용자 질문을 분석해서 적절한 필터를 자동 생성:
사용자: "2026년 1분기 매뉴얼에서 Layer 정의 알려줘"
↓
LLM이 만든 검색 필터:
vector_query: "Layer 정의"
filter: doc_type='manual' AND created_at BETWEEN '2026-01-01' AND '2026-03-31'LangChain SelfQueryRetriever, LlamaIndex AutoRetriever 가 이 패턴.
6. 이 글에서 챙겨갈 것
| 결정 | 디폴트 추천 |
|---|---|
| 청킹 전략 | Recursive (텍스트) + Small-to-Big |
| 청크 크기 | 400~800 토큰, overlap 50~100 |
| 임베딩 모델 | 한국어 위주면 multilingual-e5-small → 부족하면 bge-m3 |
| Multi-vector? | hypothetical questions 한 번 추가 — 비용 대비 가성비 우수 |
| 메타데이터 | 가능한 한 풍부하게. doc_id / version / created_at / type 은 무조건 |
