RAG 처음부터 고도화까지 — 6편: Agentic 심화 (ReAct 가드 · Tool-chain · Multi-Agent · Reflection · Memory)
시리즈 「RAG 처음부터 고도화까지」 — 6부.
1~5편 까지 본 상태.
이번 글의 목표
5편 마지막에서 Agentic RAG / ReAct 를 짧게 다뤘습니다. 이번 편은 그 위로 한 단계 — Tool-chain 설계, Multi-Agent 분리, Reflection (자기 비판), 메모리 (대화형) 까지.
운영에서 자주 부딪히는 질문들:
- ReAct 루프가 무한히 도는데 어떻게 막나
- 도구 N개가 서로 의존성 있는데 어떻게 묶나
- 한 LLM 이 다 하지 말고 역할 분리하면 정말 좋아지나
- 답변 후 자기 검토를 LLM 이 직접 하게 만들 수 있나
- 대화가 길어지면 컨텍스트 폭발하는데 메모리는 어떻게 굴리나
다룰 것:
- ReAct 루프 — 운영 가드들
- Tool-chain 설계 — 의존성 DAG · 병렬 호출 · 재시도/timeout
- Multi-Agent — Planner · Retriever · Reasoner · Critic 분리
- Reflection / Self-Refine — 답변 다듬기
- 대화형 RAG 의 3-tier 메모리
1. ReAct 루프 — 운영 가드 5개
5편의 기본 ReAct 패턴:
for turn in range(MAX_LLM_CALLS):
resp = llm.chat(messages, tools=TOOLS)
if not resp.tool_calls:
break
for tc in resp.tool_calls:
result = run_tool(tc.name, tc.args)
messages.append(tool_message(result))이대로만 두면 운영 환경에서 다음 케이스에 깨집니다:
1.1. 무한 루프 — 같은 도구 반복
LLM 이 같은 도구를 같은 인자로 계속 부르는 경우. 도구 결과를 잘못 해석하거나, 자기 추론에 confidence 가 부족할 때.
가드: 호출 시그니처 해시로 중복 감지.
import hashlib, json
seen_calls = set()
for tc in resp.tool_calls:
sig = hashlib.sha1(
(tc.name + json.dumps(tc.args, sort_keys=True)).encode()
).hexdigest()
if sig in seen_calls:
# 같은 호출 두 번째 — 강제 종료 또는 LLM에게 알려줌
messages.append({
"role":"tool", "tool_call_id":tc.id,
"content": "ERROR: 같은 도구를 같은 인자로 이미 호출했음. "
"다른 접근을 시도하거나 지금 가진 정보로 답하라."})
continue
seen_calls.add(sig)
...1.2. 잘못된 도구 호출
LLM 이 존재하지 않는 도구를 부르거나 필수 인자를 빠뜨림.
가드: dispatch 시 검증.
DISPATCH = {"rag_search": ..., "read_page": ..., "calc": ...}
def run_tool(name, args):
if name not in DISPATCH:
return {"error": f"unknown tool '{name}'. "
f"available: {list(DISPATCH.keys())}"}
try:
return DISPATCH[name](args)
except (TypeError, ValueError) as e:
return {"error": f"{name} 호출 실패: {e}"}에러 메시지를 도구 결과로 LLM 에 다시 주입하면 LLM 이 자율적으로 정정합니다. 절대 raise 하지 마세요 — agent 가 죽음.
1.3. 지연 / Timeout
도구가 외부 API 호출이면 hang 가능. 매 도구 호출에 timeout.
import concurrent.futures
def run_tool_with_timeout(name, args, timeout=10):
with concurrent.futures.ThreadPoolExecutor() as ex:
try:
return ex.submit(DISPATCH[name], args).result(timeout=timeout)
except concurrent.futures.TimeoutError:
return {"error": f"{name} timeout {timeout}s"}1.4. 비용 budget
LLM 호출도 도구 호출도 다 돈입니다. 한 질문당 토큰 / 호출 budget 을 두고 초과 시 강제 종료.
budget = {"max_llm_calls": 8, "max_tool_calls": 16, "max_input_tokens": 50000}
spent = {"llm": 0, "tools": 0, "tokens": 0}
for turn in range(budget["max_llm_calls"]):
if spent["llm"] >= budget["max_llm_calls"]: break
if spent["tokens"] >= budget["max_input_tokens"]: break
...1.5. 안전한 도구 격리
도구가 임의 코드 실행 (eval, subprocess) 같은 거면 샌드박스 필수. calc 같은 단순 계산기도 eval 절대 안 됩니다:
def tool_calc(expr):
# 위험: eval 그대로 쓰지 말 것
if not all(c in "0123456789+-*/().% " for c in expr):
return {"error": "unsafe expression"}
return {"result": eval(expr)} # 위 가드 통과 후에만진짜 안전하게 가려면 simpleeval 라이브러리.
2. Tool-chain 설계 — 의존성 그래프
도구가 한두 개면 위처럼 평탄한 루프로 충분. 도구 6~10개 + 의존성 (A 결과를 B 가 인자로) 이면 다른 설계가 필요합니다.
2.1. 도구 카탈로그 설계 원칙
| 원칙 | 의미 |
|---|---|
| single purpose | 한 도구 = 한 가지 일. search_and_summarize 보다 search + summarize 둘로 |
| idempotent | 같은 입력 → 같은 출력. side-effect 있는 도구는 명시 |
| stateless | 도구가 LLM 사이에 상태 안 가짐. 필요하면 결과를 명시적으로 LLM에 반환 |
| typed I/O | 인자/결과 스키마를 JSON Schema 로 정확히 — LLM 이 모호하지 않게 |
| costly_warning | 비용 큰 도구는 description 에 명시 ("외부 API, 1회 ~50ms / $0.001") |
2.2. 병렬 호출
LLM 응답이 한 번에 여러 tool_calls 를 돌려줄 수 있습니다. 의존성 없는 것끼리는 병렬 실행:
import asyncio
async def run_one(tc):
args = json.loads(tc.function.arguments)
return tc.id, await DISPATCH_ASYNC[tc.function.name](args)
results = await asyncio.gather(*[run_one(tc) for tc in resp.tool_calls])
for tc_id, result in results:
messages.append({"role":"tool", "tool_call_id":tc_id,
"content": json.dumps(result, ensure_ascii=False)})OpenAI / Anthropic 둘 다 LLM 이 의존성 없는 호출을 알아서 한 응답에 묶어줍니다 — 우리는 그걸 병렬로 돌리면 됨.
2.3. 도구 결과 크기 관리
도구 결과 (rag_search 가 청크 10개) 가 컨텍스트에 누적되면 토큰 폭발. 해결:
- 도구 결과에 요약 / 첫 N자만 반환
- LLM 이 필요하면
read_page(page)같은 추가 도구로 전체 가져오게
def tool_rag_search(query, k=5):
hits = retriever.search(query, k=k)
return [{
"page": h.payload["page"],
"score": round(h.score, 3),
"snippet": h.payload["text"][:200], # ← 200자만
} for h in hits]LLM 이 snippet 만 보고 어느 페이지가 답에 필요한지 판단 → read_page 로 전체 호출. 2단계 retrieval = 적은 토큰.
3. Multi-Agent — 역할 분리
한 LLM 이 모든 걸 하지 않고 역할별로 다른 호출 / 다른 프롬프트 로 분리. 2026 년 dominant 패턴.
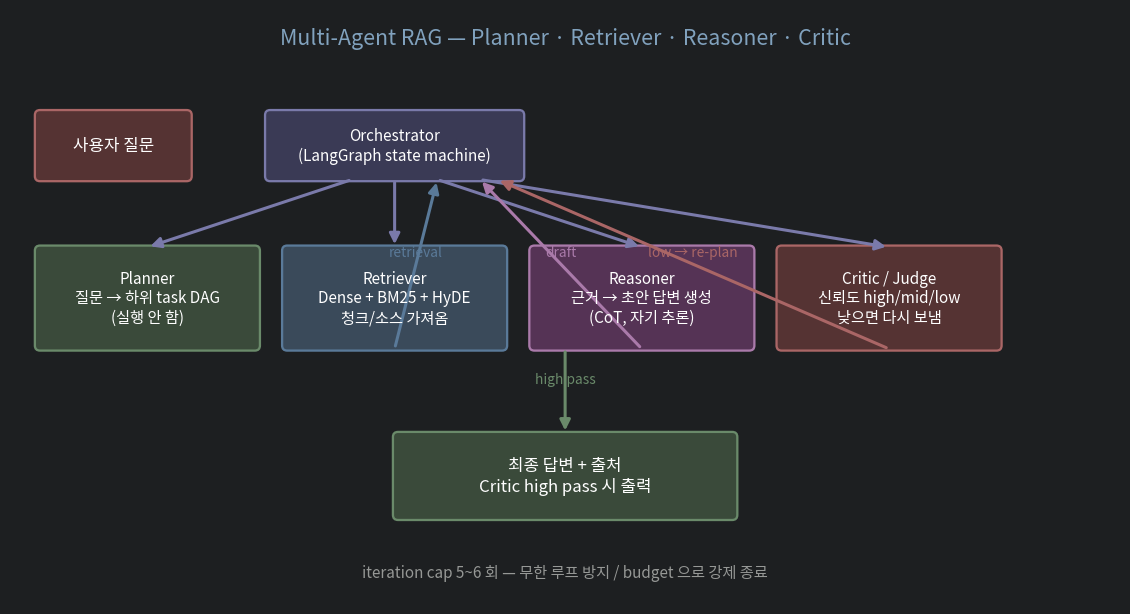
표준 구성:
| Agent | 역할 |
|---|---|
| Planner | 사용자 goal → 하위 task DAG. 실행 안 함 |
| Retriever | 한 task 받아 Dense+BM25+HyDE 로 청크/소스 회수 |
| Reasoner | 모은 근거 → 초안 답변. CoT 추론, citation 박기 |
| Critic / Judge | 초안 + 근거 받아 신뢰도 high/mid/low 판정 |
흐름:
사용자 → Planner → tasks
↓
for each task:
Retriever → 근거
Reasoner → 초안
Critic → high / mid / low
├ high → 출력
├ mid → Retriever 재호출 (query rewrite)
└ low → Planner 재호출 (다른 plan)iteration cap 5~6 회 권장.
3.1. 왜 분리하나
- 각 agent 프롬프트를 짧게 — system prompt 가 task-specific, LLM 출력 일관성 ↑
- 다른 모델 섞기 — Planner / Critic 은 작은 모델 (cheap), Reasoner 만 큰 모델
- 로그/디버그 — 어느 단계에서 잘못됐는지 트레이스 명확
3.2. LangGraph 로 구현 — 상태 머신
LangGraph 가 다중 agent 의 state machine 을 다루는 표준 라이브러리. 노드 = agent, 엣지 = 다음 step.
from langgraph.graph import StateGraph
class State(TypedDict):
question: str
tasks: list
retrieved: list
draft: str
critic_score: str # high / mid / low
iter: int
graph = StateGraph(State)
graph.add_node("planner", planner_agent)
graph.add_node("retriever", retriever_agent)
graph.add_node("reasoner", reasoner_agent)
graph.add_node("critic", critic_agent)
graph.add_edge("planner", "retriever")
graph.add_edge("retriever", "reasoner")
graph.add_edge("reasoner", "critic")
graph.add_conditional_edges("critic",
lambda s: "end" if s["critic_score"]=="high" or s["iter"]>=6 else
"retriever" if s["critic_score"]=="mid" else "planner")복잡한 분기를 텍스트가 아닌 그래프로 정의 → 디버깅 시 어느 노드가 잘못됐는지 명확.
3.3. Supervisor 패턴
위는 노드들이 정해진 순서로. Supervisor 패턴 은 한 LLM (supervisor) 이 "다음에 누구를 부를지" 를 동적으로 결정합니다:
사용자 → Supervisor (LLM)
├ 어떤 agent 부르지? → Retriever / Reasoner / Tool / End
├ agent 결과 → 다시 Supervisor
...
└ End → 최종 답변자유도 높음, 그만큼 통제도 어려움. 답변 latency 가 비싸짐 (Supervisor 매 step 호출). 본인 도메인이 분기가 예측 가능하면 정적 그래프, 자유 추론이 필요하면 Supervisor 가 일반적 권장.
4. Reflection / Self-Refine — 답변 다듬기
초안을 한 번 만들고, 다른 prompt 로 다시 평가/수정 하는 패턴. Multi-Agent 의 Critic 과 비슷하지만, agent 분리 없이 단일 LLM 안에서 2-3 step 으로 짧게.
# Step 1: 초안
draft = llm.chat(rag_prompt(q, hits))
# Step 2: 자기 비판
critique = llm.chat(
f"답변: {draft}\n근거:\n{contexts}\n\n"
"위 답변의 문제점 3개를 bullet 으로 적어라. "
"근거가 약한 부분, 출처 표기 누락, 환각 가능성 위주."
)
# Step 3: 수정
refined = llm.chat(
f"원 답변: {draft}\n비판: {critique}\n근거:\n{contexts}\n\n"
"비판을 반영해 답변을 수정해라. 변경 사항을 답변 끝에 (수정: ...) 로 명시."
)
return refined비용은 LLM 호출 ×3. 답변 품질 큰 폭 개선 — 특히 환각 감소.
언제 쓰나: 의료/법률/재무처럼 정확성이 결정적인 도메인. 일반 챗봇에는 과함.
4.1. Iterative Refinement
step 한 번이 아니라 반복:
draft = initial_draft
for i in range(MAX_REFINE):
critique = llm.chat(critique_prompt(draft))
if "문제 없음" in critique:
break
draft = llm.chat(refine_prompt(draft, critique))MAX_REFINE = 2~3 가 보통. 그 이상은 LLM 이 의미 없는 변경만 반복.
5. 대화형 RAG 의 메모리
여기까지는 single-turn (질문 1회 → 답 1회). 챗봇처럼 여러 turn 이어지는 대화 면 추가 설계가 필요.
문제:
- 단순히 모든 turn 을 context 에 누적하면 토큰 폭발
- "아까 그거 더 자세히" 같은 anaphora (대명사 참조) 가 잘못 해석되면 검색 실패
해결: 3-tier 메모리.
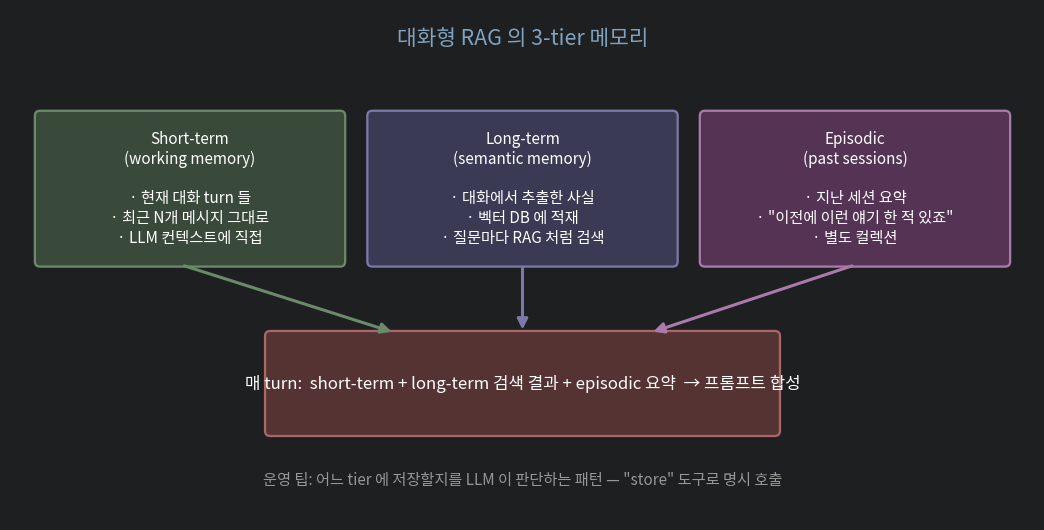
5.1. Short-term (working memory)
최근 N개 message 를 그대로. 보통 8~16 turn.
recent = messages[-16:] # 최근 16개너무 많으면 summarize-and-drop: N+1번째 도달 시 처음 N/2 개를 LLM 으로 요약해 한 system 메시지에 응축.
5.2. Long-term (semantic memory)
대화에서 나온 사실/선호/과제 를 추출해 벡터 DB 에 저장.
# 매 turn 종료 시
mem_extract = llm.chat(
f"대화:\n{recent_turns}\n"
"위 대화에서 나중에 기억해야 할 사실/선호 1~3개를 추출. 없으면 빈 줄."
)
if mem_extract.strip():
for fact in parse_facts(mem_extract):
vec = embedder.encode(fact)
memory_db.upsert(vec, payload={
"fact": fact,
"user_id": user_id,
"timestamp": now(),
})매 turn 시작 시 long-term 도 검색:
mem_hits = memory_db.search(embedder.encode(question), top_k=5,
filter={"user_id": user_id})
mem_context = "\n".join(f"- {h.payload['fact']}" for h in mem_hits)mem-GPT, ChatGPT memory feature 가 다 이 패턴.
5.3. Episodic (past sessions)
긴 대화의 끝에 session 전체를 한 줄 요약 으로 별도 컬렉션에 저장. 새 세션에서 "이전에 이런 얘기 한 적 있는데" 가 자연스럽게 가능.
session_summary = llm.chat(
f"다음 대화 전체를 3문장으로 요약하라. 다룬 토픽, 결론, 후속 과제.\n{full_chat}"
)
episodic_db.upsert(embedder.encode(session_summary), payload={
"summary": session_summary,
"user_id": user_id,
"session_id": session_id,
"start": session_start,
})질문이 들어오면 episodic 도 같이 검색해서 "이전 대화 컨텍스트" 로 살짝 끼움.
5.4. 메모리 쓰기 결정
매 turn 마다 위 작업 다 돌리면 비용 큼. LLM 이 store 도구를 명시적으로 부르는 패턴이 더 깔끔:
TOOLS += [{
"type": "function",
"function": {
"name": "remember",
"description": "사용자가 나중에도 기억해야 할 사실을 long-term 메모리에 저장.",
"parameters": {"type":"object","properties":{
"fact": {"type":"string"}
},"required":["fact"]},
},
}]LLM 이 "이건 기억해 둘 만하다" 판단 시 능동적으로 호출. 이게 mem-GPT 의 핵심.
6. 운영 체크리스트
| 항목 | 권장 디폴트 |
|---|---|
| ReAct max_llm_calls | 8 |
| ReAct max_tool_calls | 16 |
| 도구 timeout | 10s (외부 API 면 30s) |
| 같은 도구 동일 인자 반복 감지 | 활성 |
| Multi-Agent iteration cap | 5~6 |
| Reasoner 모델 | 큰 LLM (Gemma-31B, GPT-4o-mini) |
| Planner/Critic 모델 | 작은 LLM (Gemma-9B, GPT-4o-mini, Claude Haiku) |
| Reflection 횟수 | 0~3 회 (도메인별) |
| 대화 short-term 길이 | 16 turn |
| Long-term 메모리 검색 top_k | 5 |
참고
- ReAct (Yao et al., 2022): arXiv:2210.03629
- Self-Refine (Madaan et al., 2023): arXiv:2303.17651
- Reflexion (Shinn et al., 2023): arXiv:2303.11366
- MemGPT (Packer et al., 2023): arXiv:2310.08560
- Vinod Rane, Next-Generation Agentic RAG with LangGraph (2026): link
- MarsDevs, Agentic RAG: The 2026 Production Guide: link
- lifetideshub, LangGraph Multi-Agent Orchestration — Official Guide 2026: link
